深度学习-模型初始化与模型构造
模型初始化是神经网络训练过程中的关键步骤,其目标是为网络参数设置合理的初始值,从而加速训练过程并提高模型性能。
下面是三种有效的模型初始化方法:
将乘法操作转换为加法操作:在某些网络结构中,乘法操作可能会导致梯度消失或爆炸问题。通过将乘法操作转换为加法操作,可以稳定梯度流动,使训练过程更加平稳。
归一化技术:归一化是将输入数据或网络激活值调整到特定范围(如0到1或-1到1)的过程。常见的归一化方法包括批量归一化(Batch Normalization)和层归一化(Layer Normalization)。这些技术可以帮助加速网络的收敛,并提高模型的泛化能力。
合理的权重初始化和激活函数选择:选择合适的权重初始化方法(如He初始化或Xavier初始化)可以确保网络在训练初期的梯度流动稳定。同时,选择合适的激活函数(如ReLU、Leaky ReLU或Swish)可以引入非线性,帮助网络学习复杂的特征表示。

有上面三个方法,这里介绍第三种方法:选择合理的模型初始化权重(随机初始化的Xavier初始化)与激活函数。
1. Xavier初始化
Xavier初始化也称为Glorot初始化,因为发明人为Xavier Glorot。Xavier initialization是 Glorot 等人为了解决随机初始化的问题提出来的另一种初始化方法,旨在保持激活函数的方差在前向传播和反向传播过程中大致相同。
Xavier 初始化试图使得每一层的输出的方差接近于其输入的方差。从而避免梯度消失或梯度爆炸的问题。
Xavier 初始化使得每一层的输出的方差接近于其输入的方差,从而使得每一层的梯度的方差接近于 1。这样,每一层的参数更新的幅度就不会相差太大,从而加速收敛。

假设我们有一个简单的神经网络,包含一个输入层、一个隐藏层和一个输出层:
输入层有3个神经元。
隐藏层有2个神经元。
输出层有1个神经元。
Xavier初始化步骤
确定每层的输入和输出神经元数量
输入层到隐藏层:输入神经元数量(n_in)= 3,输出神经元数量(n_out)= 2。
隐藏层到输出层:输入神经元数量(n_in)= 2,输出神经元数量(n_out)= 1。
计算权重的方差
对于输入层到隐藏层的权重,使用Xavier正态初始化时,方差为:
Var(W)=n_in1=1/3对于隐藏层到输出层的权重,方差为:
Var(W)=n_in1=1/2
初始化权重矩阵
输入层到隐藏层的权重矩阵大小为 3×2(输入维度3,输出维度2)。
隐藏层到输出层的权重矩阵大小为 2×1(输入维度2,输出维度1)。
2. 模型构造
层:接受一组输入 + 生成相应的输出 + 由一组可调整参数(超参数)描述。
- 一个单层本身就是模型。
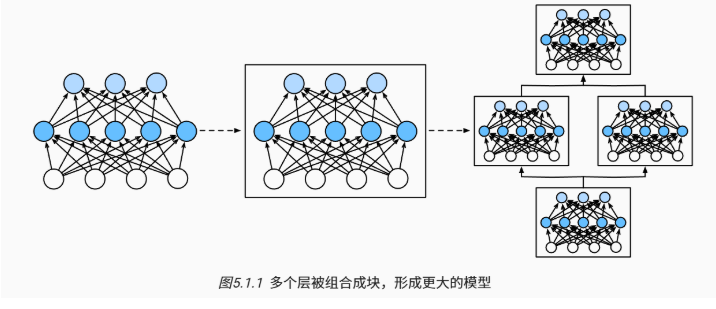
块:可以描述单个层、由多个层组成的组件或整个模型本身。
- 使用块进行抽象的一个好处是可以将一些块组合成更大的组件, 这一过程通常是递归的。
之前都是调用 nn.Sequential 实现的。可以把它理解为一个类似于 Python 的列表,用于封装一系列有序的网络层或模块,将它们组合成一个更复杂的网络结构。nn.Sequential 会按照添加的顺序依次执行其中的层或模块,其内部的层或模块会自动被正确地连接起来。
例子:
import torch
import torch.nn as nn# 定义一个包含多个层的模型
model = nn.Sequential(nn.Linear(10, 5), # 输入特征维度为 10,输出特征维度为 5 的线性层nn.ReLU(), # ReLU 激活函数nn.Linear(5, 2) # 输入特征维度为 5,输出特征维度为 2 的线性层
)# 输入数据
x = torch.randn(1, 10) # 假设输入数据的形状为 [1, 10]# 前向传播
output = model(x)
print(output)其中,上面的部分有:model[0]代表nn.Linear(10, 5),model[1]代表nn.ReLU(),model[0]代表nn.Linear(5, 2)。
在深度学习框架 PyTorch 中,层(自定义的网络层或模型组件)是继承了 nn.Module 类的一个类,主要包含 init 和 forward 两个部件。
init方法用于初始化层的参数和结构,定义该层包含的各种子模块(如卷积层、线性层等),可以设置一些可学习的参数以及固定的参数配置等。forward方法定义了输入数据在该层中的传播方式,即前向传播时对输入数据进行的操作和变换,以产生输出。
import torch
import torch.nn as nnclass MyLayer(nn.Module):def __init__(self):super().__init__()self.linear = nn.Linear(10, 5) # 初始化一个线性层作为子模块self.weight = nn.Parameter(torch.randn(5, 10)) # 定义一个可学习的参数def forward(self, x):x = self.linear(x)x = torch.matmul(x, self.weight)return x