[论文阅读] 人工智能 + 软件工程 | KnowledgeMind:基于MCTS的微服务故障定位新方案——告别LLM幻觉,提升根因分析准确率
KnowledgeMind:基于MCTS的微服务故障定位新方案——告别LLM幻觉,提升根因分析准确率
论文: The Multi-Agent Fault Localization System Based on Monte Carlo Tree Search Approach
一段话总结:
本文提出了KnowledgeMind,一种基于蒙特卡洛树搜索(MCTS) 和知识库奖励机制的创新LLM多智能体故障定位系统,用于微服务系统的根因分析(RCA)。该系统通过逐服务推理解决了现有LLM在RCA中存在的幻觉问题和上下文窗口长度限制,相比最先进(SOTA)的LLM RCA方法,根因定位准确率提升49.29%至128.35%,且对最大上下文窗口长度的需求仅为前者的十分之一。系统整合了多个智能体(如日志、指标、追踪、验证器等),并引入故障挖掘树约束搜索空间,在真实世界数据集上验证了其有效性。
研究背景
如今,像Netflix、阿里巴巴这样的大型企业都在使用微服务架构,就像把一台复杂的机器拆成了无数个小零件,每个零件(微服务)单独运作又相互配合。这种架构让开发更灵活、资源利用更高效,但也带来了大麻烦——故障定位太难了。
想象一下,一个网购平台突然崩了,可能是支付服务出问题,也可能是物流服务的故障影响了支付,还可能是服务器的CPU过载导致一连串服务罢工。微服务之间的依赖关系像一张密密麻麻的网,一个小故障可能顺着网线“传染”给一堆服务,工程师要在这张网里找到最初的“病毒源”,简直像在迷宫里找出口。
以前,工程师主要靠监控工具收集的指标(Metrics)、调用轨迹(Traces)和日志(Logs)来排查问题。但随着系统变大,这些数据成了“海量垃圾”,人工分析根本忙不过来。
后来,人们想用大语言模型(LLM)来帮忙。LLM挺擅长分析日志、理解代码,但它有两个大毛病:一是爱“瞎编”(幻觉),明明没根据却给出看似合理的结论;二是“记性不好”(上下文窗口有限),数据太多就记不住前面的内容。比如,LLM可能把“网络延迟”错判成“数据库崩溃”,或者因为日志太长,漏看了关键错误信息。
而且,故障会“传播”。比如A服务故障导致B、C服务跟着出问题,LLM看到一堆异常服务,很容易把B或C当成罪魁祸首,其实A才是根源。 现有的LLM故障定位方法,比如mABC、RCAgent,要么把所有数据一股脑塞给LLM,要么推理过程不透明,结果忽对忽错,工程师根本不敢全信。
所以,我们急需一种能让LLM“靠谱”起来的方法:既能处理海量数据,又能避免瞎猜,还能理清故障传播的来龙去脉。
主要作者及单位信息
本文作者是Rui Ren,来自中国科学院计算技术研究所和中国科学院大学(北京)。
创新点
-
首个基于蒙特卡洛树搜索(MCTS)的多智能体故障定位系统:就像让一群“小侦探”(智能体)分工合作,用MCTS这种“步步推理”的方法找故障,而不是让LLM“一口吃成胖子”。
-
提出“故障挖掘树”:把复杂的服务依赖网剪成一棵“树”,规定好搜索路径,避免LLM在无数可能的故障路径里瞎逛,大大缩小了排查范围。
-
LLM与传统模型“强强联手”:日志、指标等数据先由传统算法(如ARIMA时序分析、GMM聚类)预处理,再交给LLM分析,既发挥了LLM的理解能力,又用传统模型弥补了它处理数据的短板。
-
知识库“实时纠错”:内置专家规则和历史案例,像个“错题本”,LLM推理时随时对照,减少瞎猜的可能。比如看到“error”日志,就知道要重点关注,不会当成普通警告。
研究方法和思路、实验方法
KnowledgeMind的“破案流程”
1. 准备工作:搭建“侦探团队”
- 异常报警智能体:第一个发现“案情”(系统异常)的人,负责判断要不要启动排查。
- 日志智能体:整理“口供”(日志)的专家。先用Drain工具提取日志模板,挑出含“error”“exception”的关键日志;如果日志太多,就用GMM聚类去重,或者对照知识库筛选,最后交给LLM总结。
- 指标智能体:分析“体检报告”(指标)的医生。用ARIMA算法预测正常指标,和实际值对比,找出“体温飙升”(SPIKE)或“血压骤降”(DIP)的异常,用自然语言告诉LLM。
- 追踪智能体:查“行动轨迹”(服务调用)的侦探。盯着服务之间的调用延迟和失败情况,判断是否有异常。
- 报警图智能体:画“关系图”的画师。根据服务依赖关系,把出问题的服务连成一棵“故障挖掘树”,还加个“虚拟根节点”,让所有排查都从这里开始,避免混乱。
- 验证器智能体:“评分裁判”。根据专家规则给每个可疑服务打分,比如日志和指标都异常的服务得分更高,分数范围0-10分。
- 知识库智能体:“案例库管理员”。存着过去的故障案例,遇到类似情况就调出来参考,能直接破案就不用再查了。
- 服务-容器智能体:“精确到门牌号”的定位员。确定故障是整个服务的问题,还是某个容器(Pod)的问题。
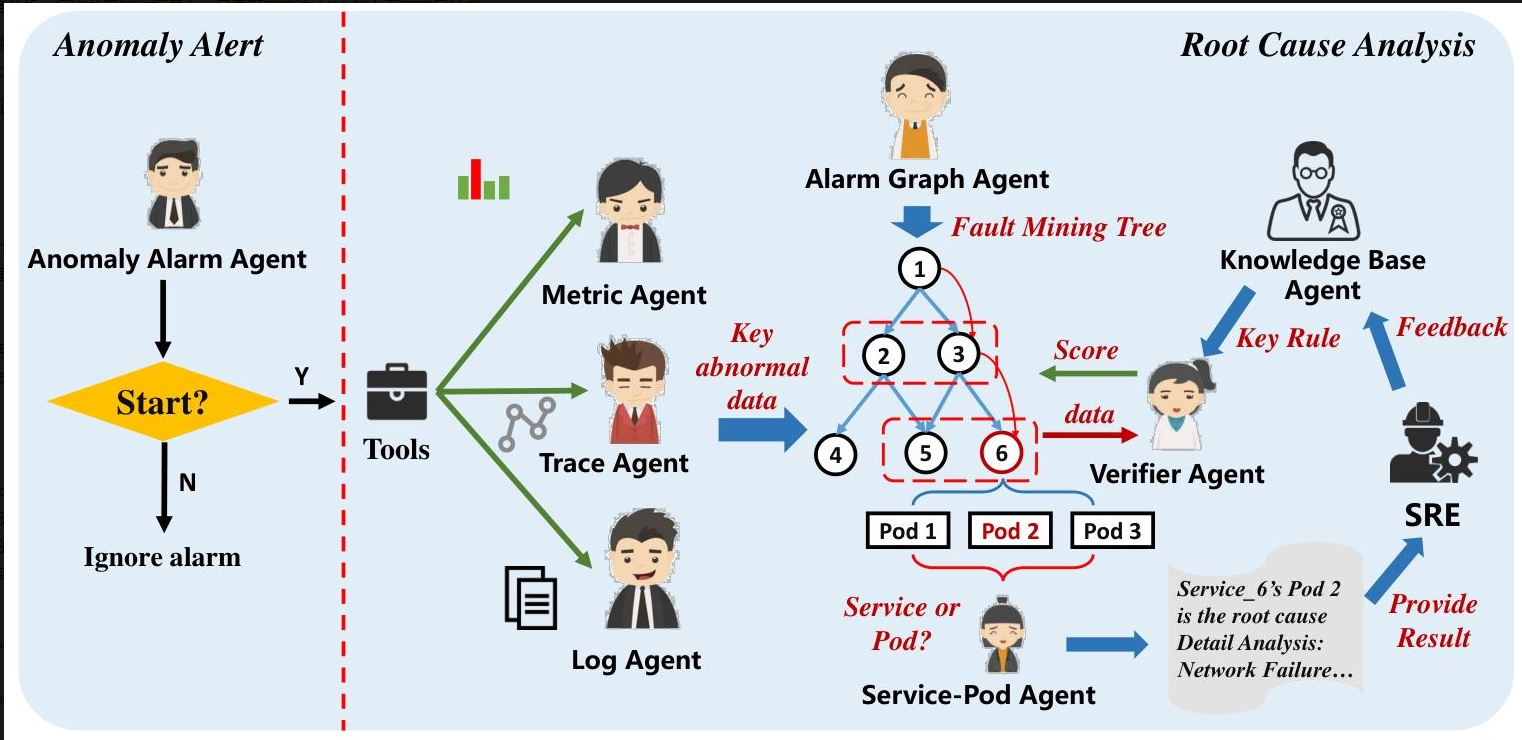
2. 核心推理:MCTS“步步排查”
就像玩迷宫游戏,从虚拟根节点出发,每次只查一层服务:
- 选择:按评分挑出最可疑的服务。
- 扩展:让日志、指标、追踪智能体收集这个服务的详细信息。
- 模拟:对照知识库,看有没有类似案例;如果没有,就查调用这个服务的其他服务,判断故障是否从这里传播出去。
- 回溯:更新所有节点的评分,重复多轮,最后找到被访问次数最多的“故障路径”。
实验方法
- 数据集:用了两个真实数据集,A来自某大型银行(43个服务,167个故障),B来自Trainticket平台(41个服务,165个故障),涵盖CPU过载、网络延迟等多种故障。
- 对比方法:和COT(思维链)、mABC、RCAgent等现有方法比,看谁的根因服务定位(FL@1)和根因类型定位(FT@k)更准。
- 消融实验:故意去掉某个智能体(如指标智能体),看性能下降多少,证明每个组件都有用。
主要贡献
-
准确率大幅提升:在两个数据集上,根因定位准确率比现有最好方法高49.29%到128.35%。比如在数据集A中,KnowledgeMind的FL@1(顶级根因服务准确率)达0.724,而mABC最高才0.485。
-
解决LLM“老毛病”:
- 幻觉少了:靠知识库和验证器评分,LLM瞎猜的情况减少。
- 上下文够了:逐服务分析,每次处理的数据量小,只需现有方法1/10的上下文窗口长度。
-
适应大规模系统:随着服务数量增加,现有方法的令牌消耗直线上升,而KnowledgeMind因为逐服务处理,令牌消耗稳定,适合超大型微服务系统。
-
推理过程透明:像破案记录一样,每一步分析都有依据,工程师能看懂、能纠错,不像黑箱模型那样“凭感觉”。
思维导图:
详细总结:
1. 引言
- 微服务架构因松耦合、灵活性高被Netflix、阿里巴巴等企业广泛采用,但也导致服务间交互复杂,故障定位难度增加(70%故障源于代码变更)。
- 故障定位依赖Metrics(指标)、Traces(追踪)、Logs(日志) 三类数据,但现有方法难以应对大规模系统的复杂性。
- LLM在代码解析、日志分析等方面具有优势,但现有框架(如ReAct、CoT)存在幻觉、上下文窗口限制、故障传播误判等问题。
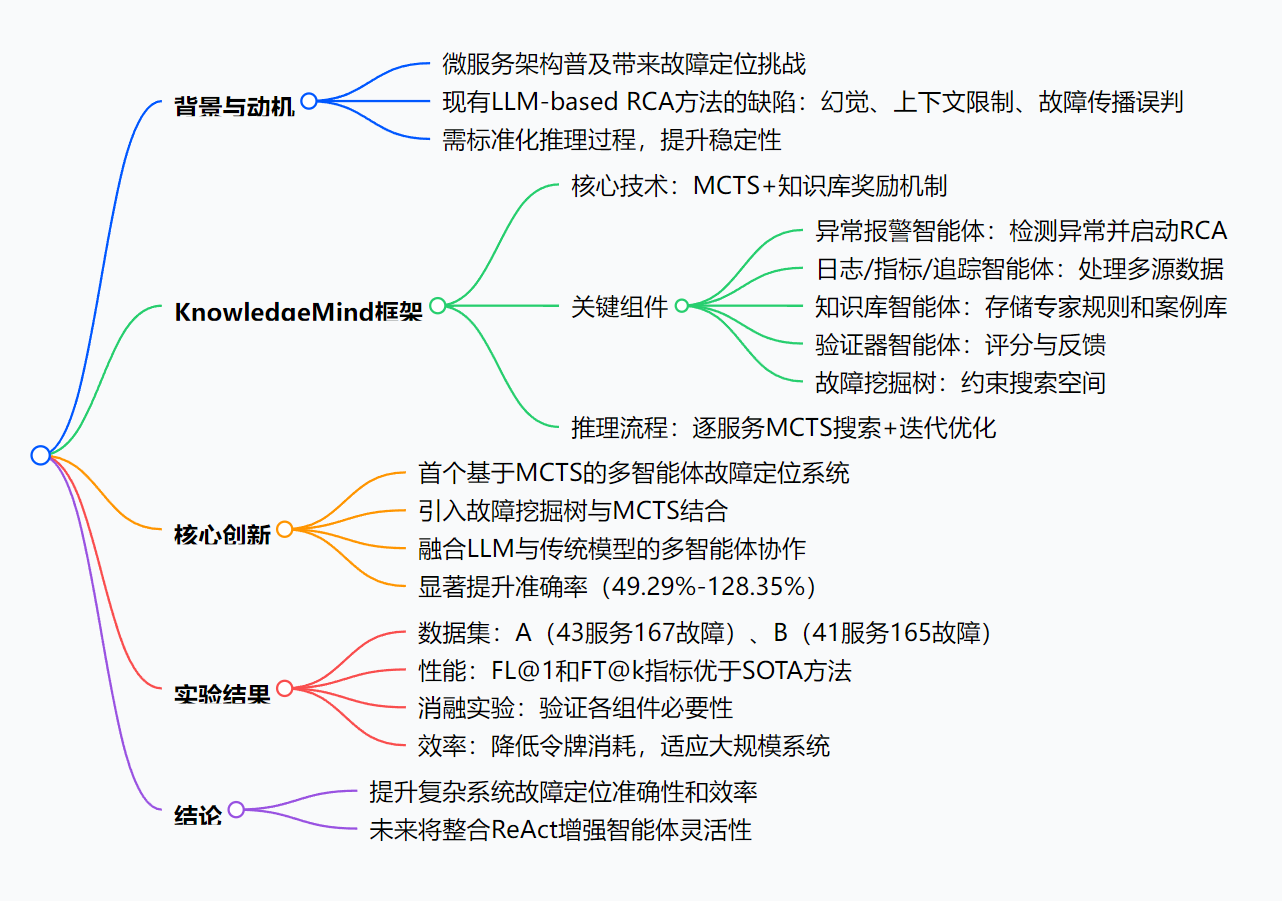
2. 背景与动机
- 现有LLM-based RCA方法缺陷:
- 挑战1:LLM的无约束随机分析与幻觉,导致分析结果与实际场景无关。
- 挑战2:故障传播导致多服务异常,LLM易产生多个看似合理的错误结果。
- 现有方法(如mABC、RCAgent)推理过程不透明,结果稳定性差。
- 动机:需构建白盒化、标准化的推理过程,结合知识驱动和MCTS提升RCA准确性。
3. KnowledgeMind框架
- 核心设计:基于MCTS和知识库奖励机制的多智能体系统,通过逐服务推理降低上下文依赖,减少幻觉。
- 关键组件:
- 异常报警智能体:检测系统异常,决定是否启动RCA。
- 日志智能体:用Drain提取模板、GMM聚类等方法过滤日志,减少令牌消耗。
- 指标智能体:结合ARIMA、LSTM等算法分析时序数据,识别异常(如SPIKE/DIP)。
- 追踪智能体:分析服务调用延迟和失败状态。
- 知识库智能体:存储专家规则和案例库,加速MCTS搜索(匹配相似案例可终止搜索)。
- 报警图智能体:构建故障挖掘树(基于服务依赖,含虚拟根节点),约束搜索空间。
- 验证器智能体:结合专家规则对服务异常评分(0-10分),指导MCTS迭代。
- 服务-容器智能体:细化故障到服务级或容器级。
- 推理流程:基于故障挖掘树的MCTS逐服务搜索→验证器评分→回溯更新→迭代确定根因。
4. 核心贡献
- 提出首个基于MCTS的多智能体故障定位系统,通过知识库规则奖励减少幻觉,降低上下文依赖。
- 引入故障挖掘树与MCTS结合,约束搜索空间,提升根因定位精度。
- 融合LLM与传统模型的多智能体协作,提升推理准确性。
- 在真实数据集上,根因定位准确率比SOTA方法提升49.29%–128.35%。
5. 实验结果
-
数据集:
数据集 服务数 故障数 数据类型 故障类型 A(AIOPS 2022) 43 167 指标(250+种)、追踪、日志(60GB+) 网络(50.3%)、文件I/O(16.8%)等 B(Trainticket) 41 165 指标、追踪 网络延迟(34%)、CPU(31%)等 -
性能对比(FL@1:根因服务定位准确率;FT@k:根因类型定位准确率):
方法 数据集A(FL@1) 数据集B(FL@1) 数据集A(FT@1) 数据集B(FT@1) KnowledgeMind 0.701-0.724 0.879-0.909 0.491-0.521 0.836-0.848 COT 0.317-0.365 0.727-0.788 0.251-0.288 0.715-0.727 mABC 0.359-0.485 0.818-0.848 0.275-0.330 0.776-0.812 RCAgent 0.443-0.467 0.776-0.824 0.294-0.323 0.727-0.776 -
消融实验(数据集A,Qwen2.5-max):
方法 FL@1 FT@1 含案例库 0.892 0.677 无案例库 0.724 0.509 无指标智能体 0.180 0.138 无日志智能体 0.611 0.389 -
效率对比(数据集A):
方法 平均耗时(ATC) 最大令牌消耗(MTC) KnowledgeMind 134 4362 COT 30 15786 mABC 94 34348 RCAgent 85 29324
6. 结论
- KnowledgeMind通过MCTS和多智能体协作,提升了微服务系统故障定位的准确性和效率,降低了对LLM上下文窗口的依赖。
- 未来将整合ReAct增强智能体的灵活性和自主分析能力。
关键问题:
-
KnowledgeMind如何解决现有LLM-based RCA方法的幻觉问题?
答:该系统通过两方面解决幻觉问题:一是引入基于知识库的规则奖励机制,由验证器智能体结合专家规则对推理步骤评分,约束LLM的随机分析;二是采用逐服务推理流程,通过故障挖掘树限制搜索空间,避免一次性处理所有信息导致的无效分析,减少幻觉产生的可能性。 -
相比现有方法,KnowledgeMind在性能和效率上有哪些具体优势?
答:性能上,在根因服务定位(FL@1)和根因类型定位(FT@k)指标上,相比SOTA方法(如mABC、RCAgent)提升49.29%–128.35%,数据集A中FL@1达0.701-0.724,显著高于mABC的0.359-0.485;效率上,最大令牌消耗(MTC)仅为4362,远低于mABC的34348和RCAgent的29324,且随系统规模增长,上下文窗口需求增长缓慢,更适应大规模微服务系统。 -
故障挖掘树在KnowledgeMind中起到什么作用?
答:故障挖掘树是基于服务依赖关系构建的树状结构,通过以下方式辅助推理:一是约束搜索空间,将复杂的服务依赖图分解为多个子树,结合虚拟根节点统一分析入口,使LLM能逐服务有序探索;二是明确故障传播路径,帮助LLM理解异常在服务间的传播关系,减少因传播导致的误判;三是适配MCTS流程,使逐服务评分、迭代优化的推理过程更高效,提升根因定位的准确性。
总结
本文提出的KnowledgeMind,是微服务故障定位的“智能侦探团队”。它用MCTS和故障挖掘树让排查路径更清晰,用多个智能体分工处理数据,用知识库减少LLM的幻觉,最终实现了更高的根因分析准确率,还解决了上下文窗口限制的问题。
在真实数据集上的实验证明,无论是复杂的银行系统还是基准平台,它都比现有方法表现更好。未来,研究者还想让智能体更灵活,进一步提升自主分析能力。