Deep Research(信息检索增强)认识和项目实战
文章目录
- 参考资料
- 说明
- Deep Research
- Deep Research架构模式
- 管道代理
- 规划器/执行器-代理(分层结构)
- 合作型多智能体
- 以内存为中心(图-RAG)
- Tavily搜索引擎
- Mini Deep Research应用构建架构
- planner_agent
- search_agent
- writer_agent
- Mini Deep Research项目实现
- 后端项目开发和部署
- 项目开发环境准备
- 项目整体结构
- 关键代码
- graph.py
- langgraph.json
- 后端项目部署
- 前端项目开发和部署
- 运行效果展示
- 前端项目效果
- 后端项目效果
- LangSmith检测效果
参考资料
- Mini DeepResearch
- Deep Research应用开发实战
说明
- 本文仅供学习交流使用,不用作任何商业用途!感谢赋范社区的贡献和付出!
Deep Research
- Deep Research(深度研究)是一种新兴的大模型驱动多步信息检索与报告生成技术。Deep Research自主检索和阅读网页内容,提取关键信息,并多轮推理整理成全面的研究报告。它能够自动将复杂问题分解为子问题、反复搜索权威资料、交叉分析多源信息,最终生成带有引用来源的结构化报告。旨在解决传统搜索和一般问答中的信息碎片化和Al幻觉问题。
- 相比用户手动点击众多链接筛选信息(耗时低效),DeepResearch通过多次自动检索和跨来源验证,大幅提升信息准确性和研究深度。简而言之,DeepResearch是一种让大型语言模型作为代理人选代检索和分析信息,并输出详尽报告的技术。
- OpenAI、Google、Perplexity等公司相继推出各自的深度研究代理功能。OpenAIDeep Research作为ChatGPT的新代理功能,宣称可自主搜索、分析并综合上百份在线资料,生生成接近研究分析师水准的报告。Google的Gemini模型也强调了探索复杂主题并输出易读报告的能力。这些产品体现出深度研究在降低信息误差和提升决策效率上的巨大潜力:通过自动化检索和智能分析,减少错误信息与幻觉,让企业和专业人士获得更可靠的研究结果,从而更高效地做出决策。
Deep Research的实现过程可以分为以下几个步骤:
- 问题分解:将复杂问题分解为多个子问题,每个子问题都对应一个信息检索任务。
- 信息检索:使用搜索引擎或API检索相关信息。
- 信息整合:将检索到的信息进行整合,形成一个全面的研究报告。
- 报告生成:将整合后的信息生成一个全面的研究报告。
- 根据arXiv 2506.12594 《A Comprehensive Survey of Deep Research: Systems, Methodologies, and Applications》的梳理, Deep Research包含三个核心维度
| 维度 | 含义 | 论文要点 |
|---|---|---|
| 认知-推理(Cognitive Reasoning) | 以LLM作为思考引擎,具备自主规划、链式推理与反思。 | 系统需能把复杂研究任务拆分为子目标,自主调用工具再综合结论。https://arxiv.org/pdf/2506.12594 |
| 工具集成(Tool Integration) | 无缝调用搜索/数据库/代码执行等外部工具。 | 强调“可插拔工具层”,并提出超过80个商用/开源实现对比。https://arxiv.org/pdf/2506.12594、https://github.com/scienceaix/deepresearch?utm_source=chatgpt.com |
| 流程自动化(Workflow Automation) | 端到端覆盖检索、阅读、实验、写作、迭代。 | 区分于只包一层prompt的“单点LLM应用”。https://arxiv.org/pdf/2506.12594 |
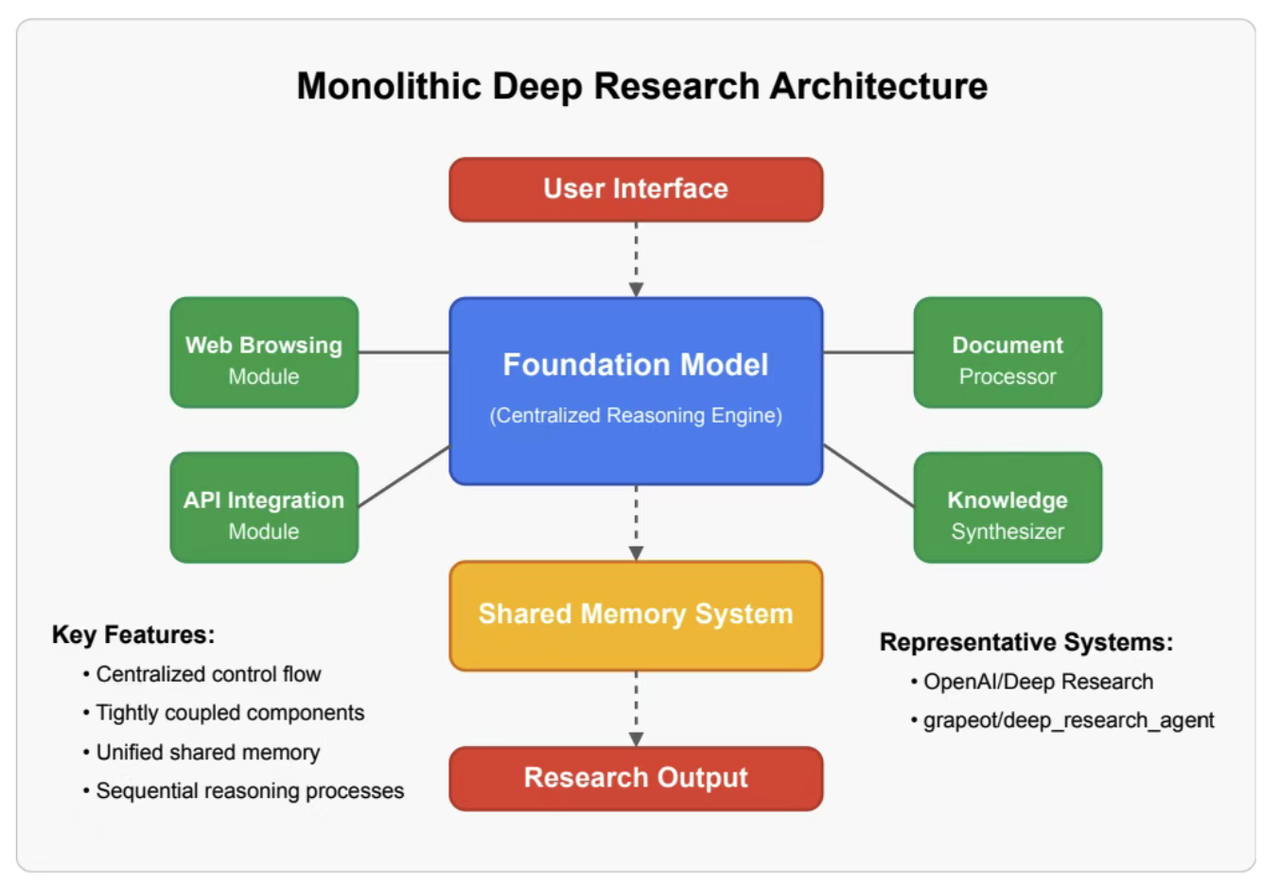
Deep Research架构模式
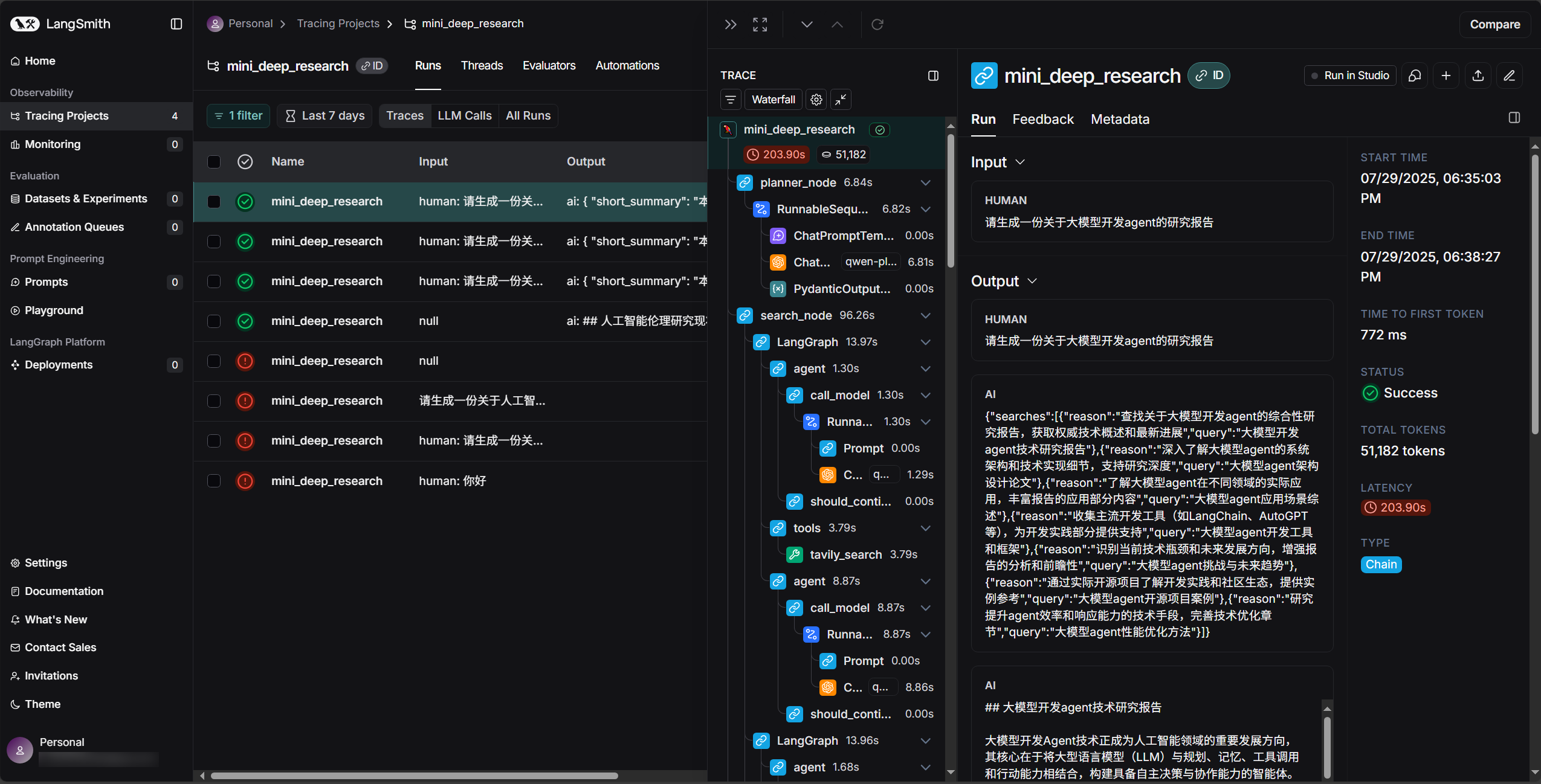
管道代理
- Pipeline-Agent(顺序管线)
- LLM 负责分段调用
Search → Read → Synthesis。 - 代表:
Perplexity、PubMed GPT。
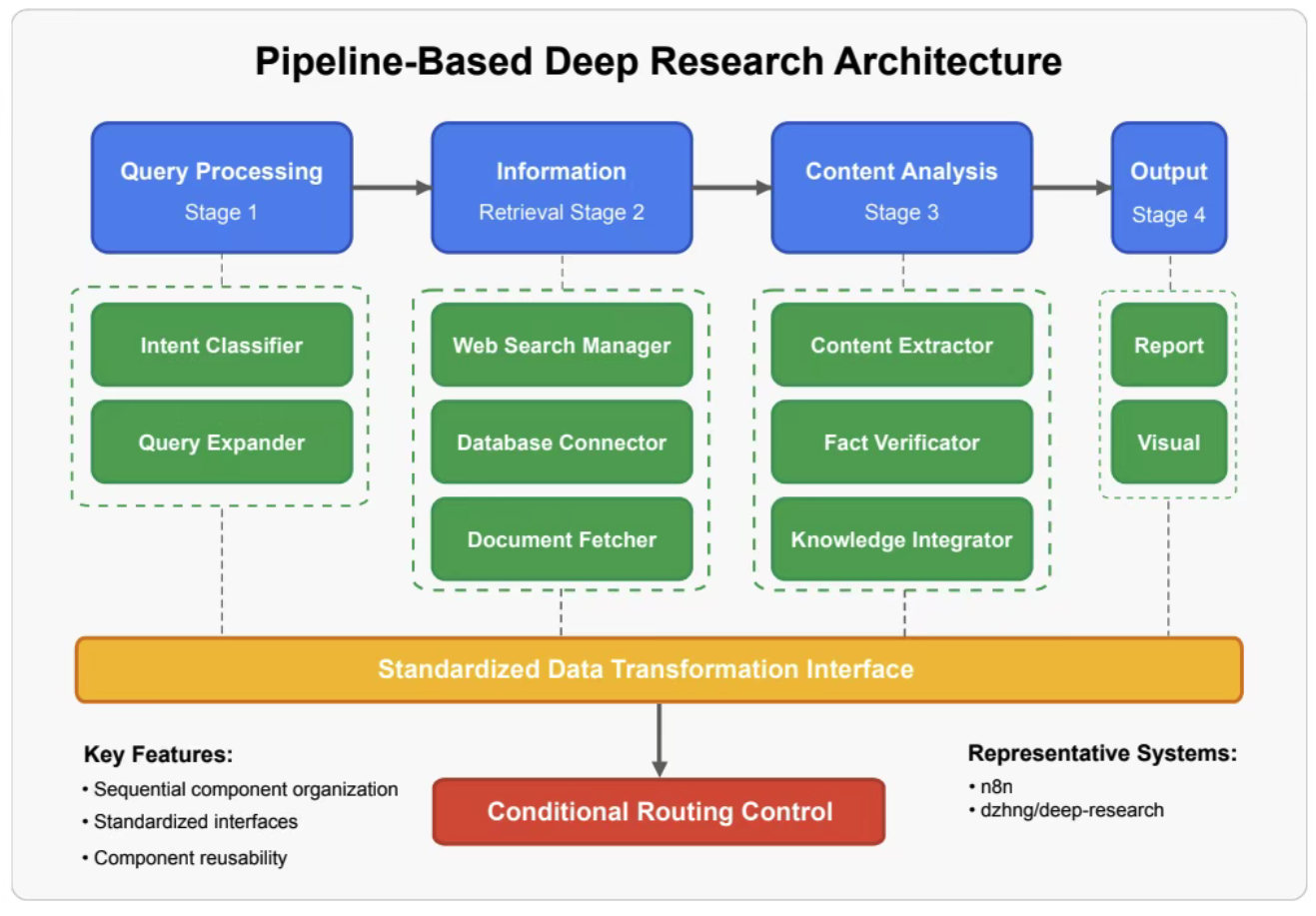
规划器/执行器-代理(分层结构)
- 规划器/执行器-代理(分层结构):
Planner/Executor-Agent (Hierarchical)。- 顶层 Planner 生成任务树,下层
Executor并行执行子节点。 - 代表:
OpenAI DeepResearch、Microsoft AutoGen。
- 顶层 Planner 生成任务树,下层
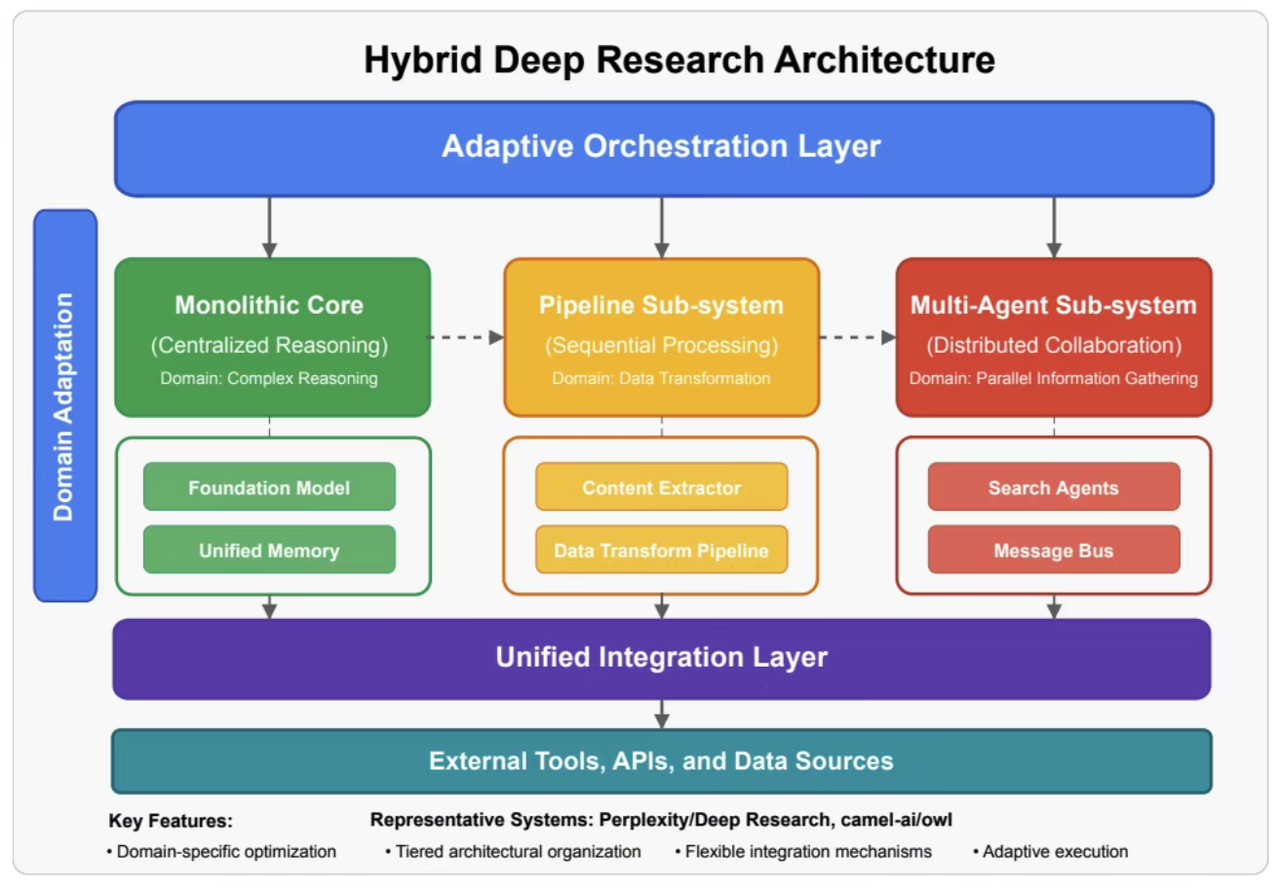
合作型多智能体
- Cooperative Multi-Agent:合作型多智能体
- 多 Agent 互评互改,降低 hallucination,提升深度。
- 代表:Anthropic Team-Agent 原型、Google Gemini “Science Agents” 实验。
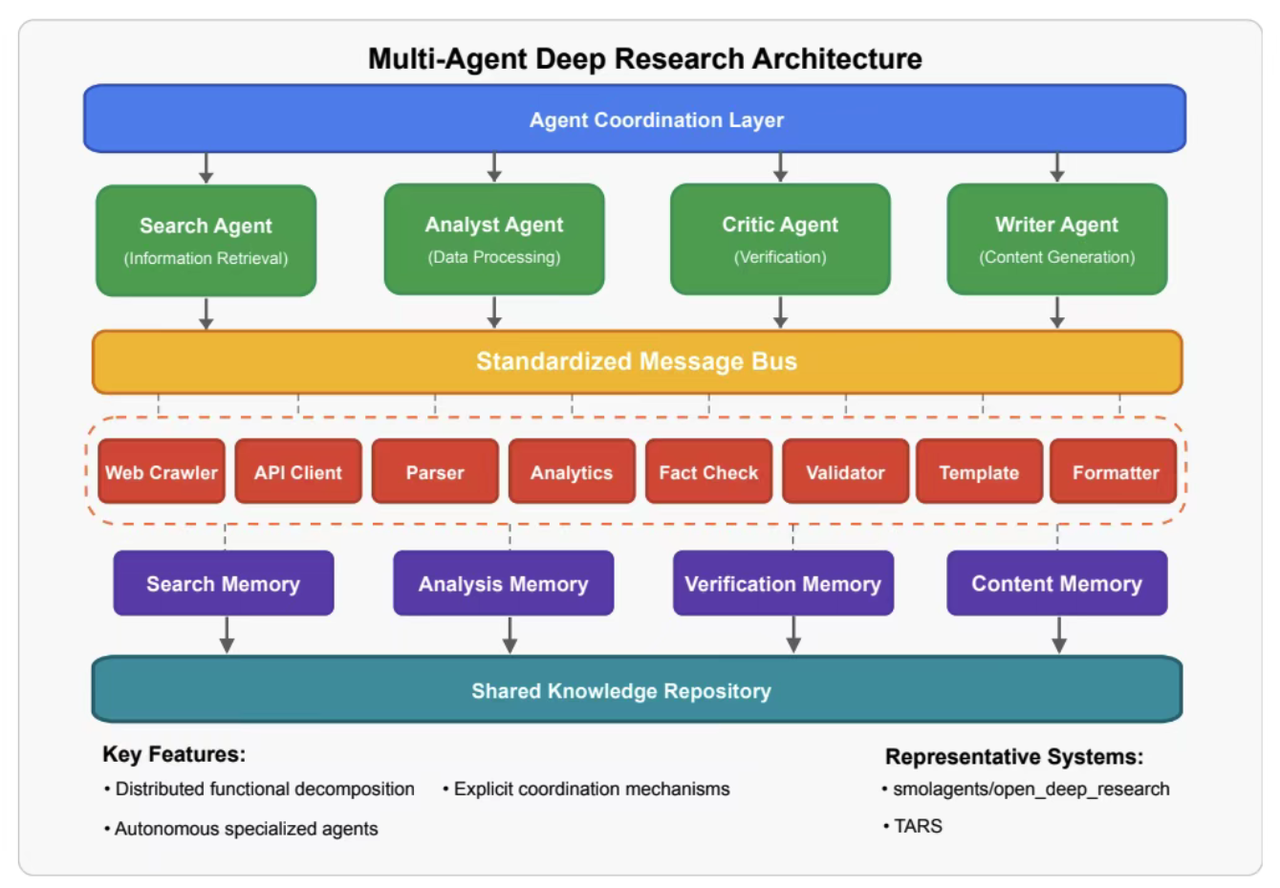
以内存为中心(图-RAG)
- Memory-Centric (Graph-RAG):以内存为中心(图-RAG)
- 将外部检索结果与过程记忆统一写入向量+图存储,支持“持续研究”
- 代表:OpenAI Knowledge Graph、Meta ResearchGraph。
Tavily搜索引擎
- Agent常用搜索引擎Tavily使用学习
Mini Deep Research应用构建架构
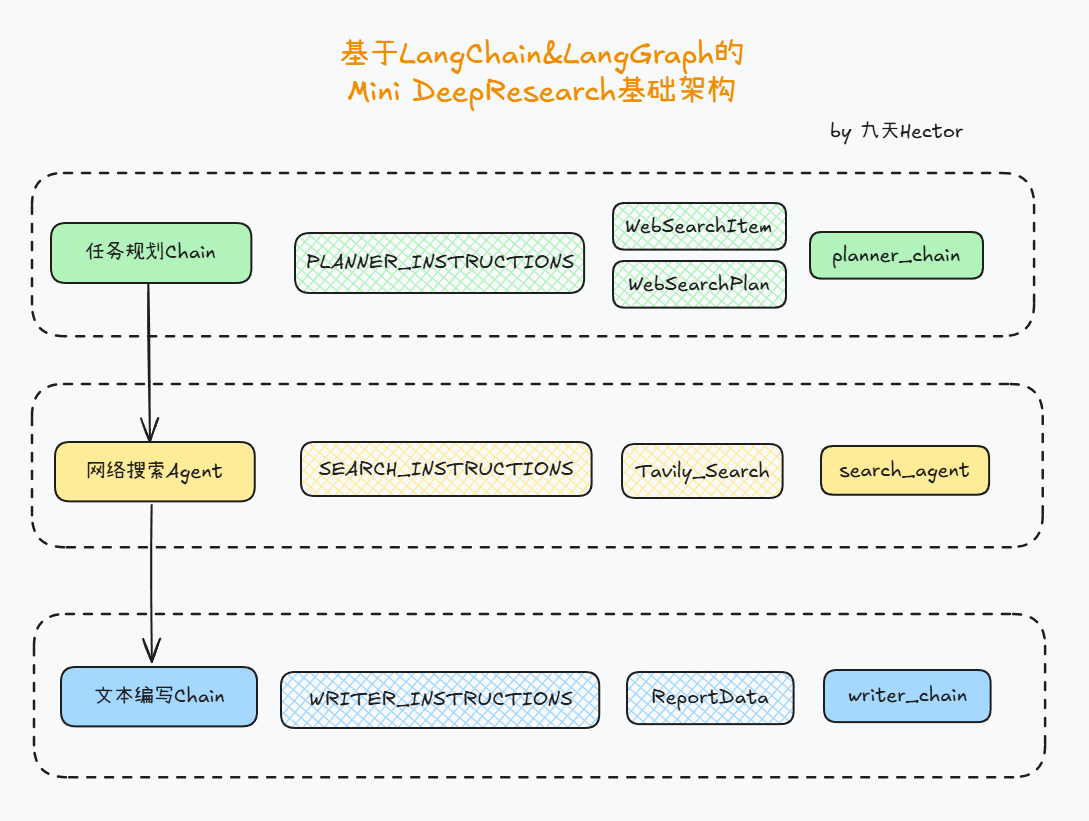
| Agent 名 | 职责 |
|---|---|
| planner_agent | 生成研究关键词和搜索策略 |
| search_agent | 负责执行网络搜索 + 总结内容(使用工具) |
| writer_agent | 汇总所有搜索结果,编写报告 |
1. 用户输入研究主题 → planner_agent → 搜索关键词列表
2. 每个关键词 → search_agent → 搜索摘要
3. 所有摘要集合 + 原始主题 → writer_agent →📌 输出:- short_summary- markdown_report(正文)- follow_up_questions(可继续研究的问题)
planner_agent
- Planner Agent 的职责是:接收一个研究主题,生成一份“搜索计划(WebSearchPlan)”,告诉系统应该搜索哪些子问题/关键词以及搜索这些关键词的理由。
'''
定义Agent 的提示词(Prompt),告诉 LLM:
- 你是一个研究助手;
- 收到一个主题后,请生成 20 到 30 条搜索建议;
- 每条建议应当包括 搜索关键词 + 搜索原因。
'''
PLANNER_INSTRUCTIONS = ("You are a helpful research assistant. Given a query, come up with 5-7 web searches ""to perform to best answer the query.\n""Return **ONLY valid JSON** that follows this schema:\n"'{{"searches": [ {{"query": "example", "reason": "why"}} ]}}\n'
)'''
单个搜索建议,包含两个字段
reason 为什么要搜索这个关键词?(用于解释搜索动机)
query 要搜索的关键词本身
'''
class WebSearchItem(BaseModel):reason: str"Your reasoning for why this search is important to the query."query: str"The search term to use for the web search."'''
搜索计划的整体结构,包含一个列表 searches,每项是上面的 WebSearchItem
'''
class WebSearchPlan(BaseModel):searches: list[WebSearchItem]"""A list of web searches to perform to best answer the query."""'''
with_structured_outputd规定输出一份结构化的 WebSearchPlan 对象,里面包含多个 WebSearchItem。
'''
planner_prompt = ChatPromptTemplate.from_messages([("system", PLANNER_INSTRUCTIONS),("human", "{query}")
])planner_chain = planner_prompt | model.with_structured_output(WebSearchPlan,method="json_mode")
search_agent
search_agent的作用是接收一个搜索关键词,调用 Web 搜索工具,然后根据搜索结果生成一份简洁的摘要(2-3 段,<300词),不带评论,只保留信息本身。也就是说,这是整个系统中真正“去网上查资料”的角色。
model = ChatOpenAI(model="qwen-plus-latest", max_tokens=32000)
# --2 search_agent--
SEARCH_INSTRUCTIONS = ("You are a research assistant. Given a search term, search the Web and produce a ""concise 2-3 paragraph (<300 words) summary of the main points. Only return the summary."
)
'''
使用tavily搜索工具进行搜索
'''
search_tool = TavilySearch(max_results=5, topic="general")search_agent = create_react_agent(model=model,prompt=SEARCH_INSTRUCTIONS,tools=[search_tool],
)
- 提示词的精髓欣赏
| 指令含义 | 说明 |
|---|---|
| 你是一个研究助手 | 模拟一个能查资料的人 |
| 给你关键词后上网搜索 | 关键词来自 planner_agent |
| 写出 2-3 段简洁总结 | 每次搜索结果必须压缩成 300 字以内的摘要 |
| 主要观点的概括 | 信息密度高,只提取信息 |
writer_agent
Writer Agent这是 整个研究系统的“输出终结者”,负责把之前所有搜索到的信息,综合成一份完整、结构化、可阅读的长篇报告。该 Agent 的任务是:- 收到研究主题和之前的所有搜索摘要。
- 先写一个大纲(outline)。
- 然后根据大纲写出一份 详细的 Markdown 格式报告。
# --3 writer_chain--
WRITER_PROMPT = ("You are a senior researcher tasked with writing a cohesive report for a research query. ""You will be provided with the original query and some initial research.\n\n""① 先给出完整的大纲;\n""② 然后生成正式报告。\n\n""**写作要求**:\n""• 报告使用 Markdown 格式;\n""• 章节清晰,层次分明;\n""• markdown_report部分至少包含2000中文字 (注意需要用中文进行回复);\n""• 内容丰富、论据充分,可加入引用和数据,允许分段、添加引用、表格等;\n""• 最终仅返回 JSON:\n"'{{"short_summary": "...", "markdown_report": "...", "follow_up_questions": ["..."]}}'
)'''
定义ReportData类,用来约束模型的输出结构
'''
class ReportData(BaseModel):short_summary: str"""A short 2-3 sentence summary of the findings.一份2-3句话的简短研究结论摘要。"""markdown_report: str"""The final report最终生成的报告(Markdown格式)"""follow_up_questions: list[str]"""Suggested topics to research further建议进一步研究的相关主题。"""writer_prompt = ChatPromptTemplate.from_messages([("system", WRITER_PROMPT),("human", "{query}")
])writer_chain = writer_prompt | model.with_structured_output(ReportData)
- 提示词精髓欣赏
| 行为 | 说明 |
|---|---|
| 角色设定 | 你是一个资深研究员(senior researcher) |
| 输入 | 会拿到:研究主题 + 搜索摘要 |
| 第一步 | 写出报告结构(outline) |
| 第二步 | 写出 Markdown 报告正文 |
| 要求 | 长、详细、有逻辑(10-20页,3000+词) |
| 输出格式 | Markdown 格式(如 # 一级标题, - 列表 等) |
| 语言风格 | 精炼、学术、结构清晰 |
| 最终返回格式 | 要求的JSON格式 |
- 模型的输出结构ReportData 类的字段说明
| 字段名 | 类型 | 说明 |
|---|---|---|
| short_summary | str | 对研究结果的简要总结(2~3句话) |
| markdown_report | str | 报告正文,Markdown 格式,内容详实 |
| follow_up_questions | list[str] | 建议后续可以进一步研究的问题列表 |
Mini Deep Research项目实现
- 基于LangGraph、LangSmith、LangGraph CLI和Chat Agent UI相关技术实现。
- 使用的工具和平台包括:Tavily、阿里云百炼、LangSmith。
后端项目开发和部署
项目开发环境准备
- 新建项目目录
mini_deep_research,然后在该目录下打开终端,创建python虚拟环境
uv venv
.venv\Scripts\activate
- 在目录
mini_deep_research下,创建requirements.txt文件,内容如下:langgraph-cli[inmem] pydantic python-dotenv langgraph langchain-core langchain-openai langchain-tavily langsmith uv - 创建
.env文件,填写环境变量LANGSMITH_TRACING="true" LANGSMITH_ENDPOINT="https://api.smith.langchain.com" LANGSMITH_API_KEY="lsv2_xxx" LANGSMITH_PROJECT="mini_deep_research" OPENAI_API_KEY="sk-xx" OPENAI_API_BASE="https://dashscope.aliyuncs.com/compatible-mode/v1" TAVILY_API_KEY="tvly-dev-xxx"- 请在阿里云百炼获取
OPENAI_API_KEY和OPENAI_API_BASE。 - 请在openweathermap获取
OPENWEATHER_API_KEY。 - 请在tavily.com/获取
TAVILY_API_KEY
- 请在阿里云百炼获取
项目整体结构
关键代码
graph.py
import json
import os
from typing import List
from dotenv import load_dotenv
from pydantic import BaseModel, ValidationError, parse_obj_as
from langchain.prompts import ChatPromptTemplate
from langchain_core.messages import AIMessage, HumanMessage, ToolMessage
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.types import Command
from langgraph.prebuilt import create_react_agent
from langchain_tavily import TavilySearch
from langchain_openai import ChatOpenAIload_dotenv(override=True)model = ChatOpenAI(model="qwen-plus-latest", max_tokens=32000)# --1 planner_chain--PLANNER_INSTRUCTIONS = ("You are a helpful research assistant. Given a query, come up with 5-7 web searches ""to perform to best answer the query.\n""Return **ONLY valid JSON** that follows this schema:\n"'{{"searches": [ {{"query": "example", "reason": "why"}} ]}}\n'
)class WebSearchItem(BaseModel):reason: str"Your reasoning for why this search is important to the query.""你对为什么此搜索对于解答该问题很重要的理由。"query: str"The search term to use for the web search.""用于网络搜索的关键词。"class WebSearchPlan(BaseModel):searches: list[WebSearchItem]"""A list of web searches to perform to best answer the query.为了尽可能全面回答该问题而需要执行的网页搜索列表。"""planner_prompt = ChatPromptTemplate.from_messages([("system", PLANNER_INSTRUCTIONS),("human", "{query}")
])planner_chain = planner_prompt | model.with_structured_output(WebSearchPlan,method="json_mode")# --2 search_agent--
SEARCH_INSTRUCTIONS = ("You are a research assistant. Given a search term, search the Web and produce a ""concise 2-3 paragraph (<300 words) summary of the main points. Only return the summary."
)search_tool = TavilySearch(max_results=5, topic="general")search_agent = create_react_agent(model=model,prompt=SEARCH_INSTRUCTIONS,tools=[search_tool],
)# --3 writer_chain--
WRITER_PROMPT = ("You are a senior researcher tasked with writing a cohesive report for a research query. ""You will be provided with the original query and some initial research.\n\n""① 先给出完整的大纲;\n""② 然后生成正式报告。\n\n""**写作要求**:\n""• 报告使用 Markdown 格式;\n""• 章节清晰,层次分明;\n""• markdown_report部分至少包含2000中文字 (注意需要用中文进行回复);\n""• 内容丰富、论据充分,可加入引用和数据,允许分段、添加引用、表格等;\n""• 最终仅返回 JSON:\n"'{{"short_summary": "...", "markdown_report": "...", "follow_up_questions": ["..."]}}'
)class ReportData(BaseModel):short_summary: str"""A short 2-3 sentence summary of the findings.一份2-3句话的简短研究结论摘要。"""markdown_report: str"""The final report最终生成的报告(Markdown格式)"""follow_up_questions: list[str]"""Suggested topics to research further建议进一步研究的相关主题。"""writer_prompt = ChatPromptTemplate.from_messages([("system", WRITER_PROMPT),("human", "{query}")
])writer_chain = writer_prompt | model.with_structured_output(ReportData)# -------- planner_node --------
def planner_node(state: MessagesState) -> Command:user_query = state["messages"][-1].contentraw = planner_chain.invoke({"query": user_query})# raw 可能已经是 WebSearchPlan,也可能是 dict(被解析过)try:plan = parse_obj_as(WebSearchPlan, raw)except ValidationError:# 若模型只返回 ["keyword1", ...]if isinstance(raw, dict) and isinstance(raw.get("searches"), list):plan = WebSearchPlan(searches=[WebSearchItem(query=q, reason="") for q in raw["searches"]])else:raisereturn Command(goto="search_node",update={"messages": [AIMessage(content=plan.model_dump_json())], # JSON 字符串"plan": plan, # 同时保存原生对象,后面也能直接用},)
# ---------- search_node ----------def search_node(state: MessagesState) -> Command:plan_json = state["messages"][-1].contentplan = WebSearchPlan.model_validate_json(plan_json)summaries = []for item in plan.searches:# 1.用 HumanMessagerun = search_agent.invoke({"messages": [HumanMessage(content=item.query)]})# 2.取可读内容:最后一条 ToolMessage 或 AIMessagemsgs = run["messages"]readable = next((m for m in reversed(msgs) if isinstance(m, (ToolMessage, AIMessage))), msgs[-1])summaries.append(f"## {item.query}\n\n{readable.content}")combined = "\n\n".join(summaries)return Command(goto="writer_node",update={"messages": [AIMessage(content=combined)]})# ---------- writer_node ----------
def writer_node(state: MessagesState) -> Command:original_query = state["messages"][0].contentcombined_summary = state["messages"][-1].contentwriter_input = (f"原始问题:{original_query}\n\n"f"搜索摘要:\n{combined_summary}")report: ReportData = writer_chain.invoke({"query": writer_input})return Command(goto=END,update={"messages": [AIMessage(content=json.dumps(report.dict(), ensure_ascii=False, indent=2))]},)# -------- 构建 & 运行 Graph --------
builder = StateGraph(MessagesState)
builder.add_node("planner_node", planner_node)
builder.add_node("search_node", search_node)
builder.add_node("writer_node", writer_node)builder.add_edge(START, "planner_node")
builder.add_edge("planner_node", "search_node")
builder.add_edge("search_node", "writer_node")
builder.add_edge("writer_node", END)graph = builder.compile()
langgraph.json
{"dependencies": ["./"],"graphs": {"mini_deep_research": "./graph.py:graph"},"env": ".env"
}
后端项目部署
- 在
mini_deep_research虚拟环境下,进入mini_deep_research目录执行graphrag dev即可运行后端部分。
前端项目开发和部署
- 首先本地安装node.js
- 打开Agent Chat UI项目主页,下载项目源码,然后解压到
data_agent目录下。 - 使用管理员运行终端,进入Agent Chat UI项目目录,执行以下命令:
npm install -g pnpm
pnpm -v
pnpm install # 安装前端项目依赖
- 使用管理员运行终端,进入
mini_deep_research项目目录,执行以下命令,打开ip:3000地址,填写Graph ID和LangSmith API Key进行连接。npm install -g pnpm pnpm -v pnpm install # 安装前端项目依赖 pnpm dev # 开启Chat Agent UI
运行效果展示
前端项目效果


后端项目效果
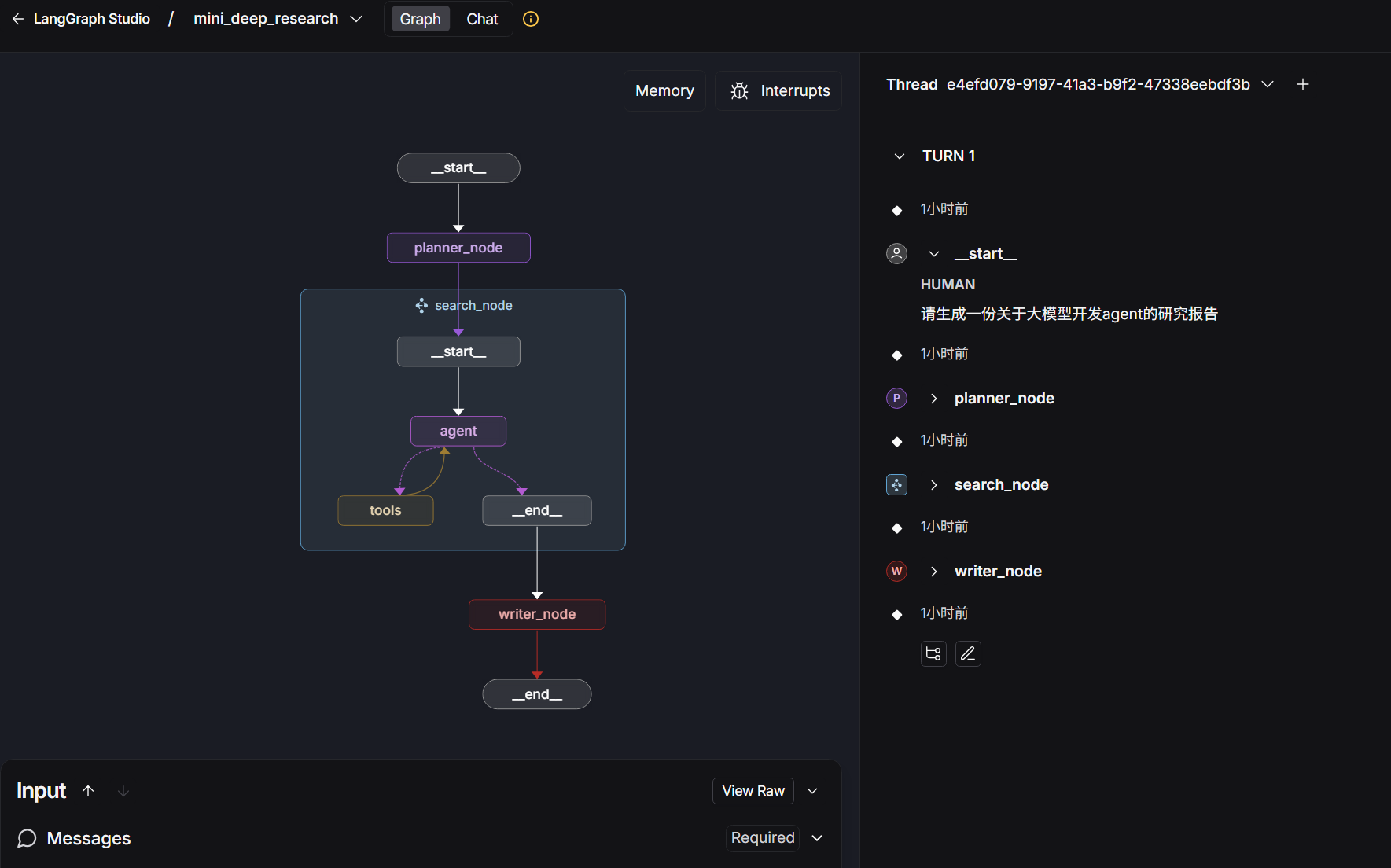
LangSmith检测效果