2D物体检测学习
DETR
1.提出了一种新的检测思路,将目标检测任务视作为集合预测问题
2.此前的检测器大都先用手工设计的候选框预测方案,例如anchor或滑动框。这些方案也包含了其他先验知识的干涉,例如NMS等后处理方案、anchor的设计、训练时如何将检测结果与ground truth匹配等。这些手工设计的策略让人对其泛化性能会有一些怀疑。
3.DETR通过将transformer融入模型,跳过手工设计的部分,将问题转化为集合预测问题,以端到端的方式直接输出预测的(对象,框)的集合。
4.本文的方法还可以用来做segmentation任务
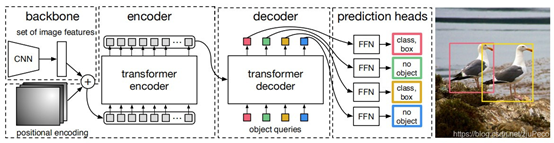
CNN为ResNet50和Res101
encoder结构不变,位置编码改一下(固定的更好)
decoder输入可学习的object queries,并行计算得到独立输出
FFN边框预测是用ReLU激活的3层感知机,类别预测是一个线性层+softmax预测层
得到预测结果以后,将object predictions和ground truth box之间通过匈牙利算法进行二分匹配:假如有K个目标,那么100个object predictions中就会有K个能够匹配到这K个ground truth,其他的都会和“no object”匹配成功,使其在理论上每个object query都有唯一匹配的目标,不会存在重叠,所以DETR不需要nms进行后处理
DINO grounding
根据文字描述检测指定目标
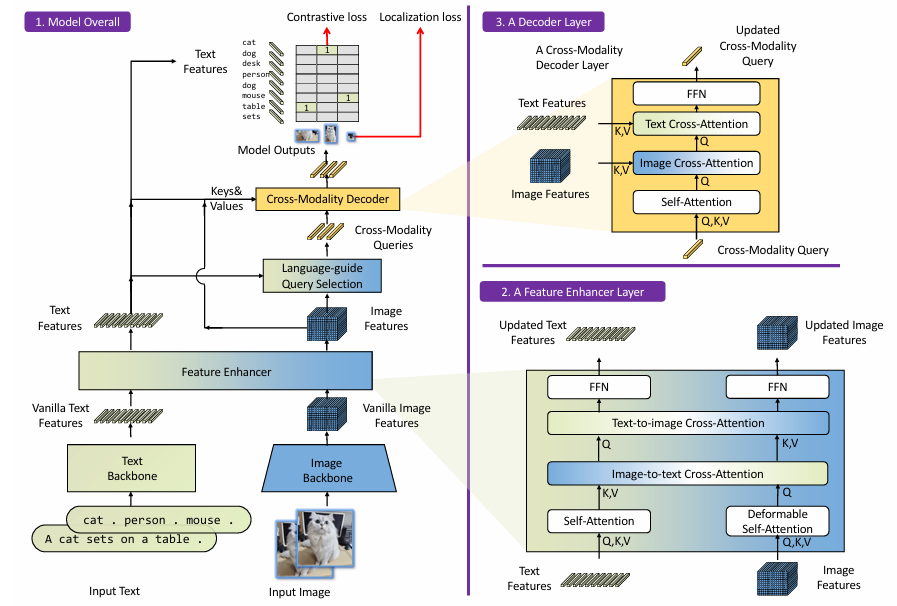
提取:Swin Transformer作为image backbone,BERT作为text backbone
多模态融合:利用Deformable Self-Attention和Self-Attention来增强image features和text features,然后利用GLIP中的image-to-text 和 text-to-image cross-attention实现特征融合
选query:![]() ,两个模态特征乘起来求最大的前Nq个
,两个模态特征乘起来求最大的前Nq个
解码:Self-Attention、Image Cross-Attention、Text Cross-Attention组合
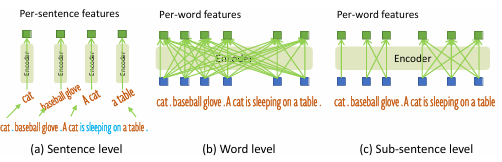
关于text prompt:mask掉不相关类别名之间的联系
DINO-X
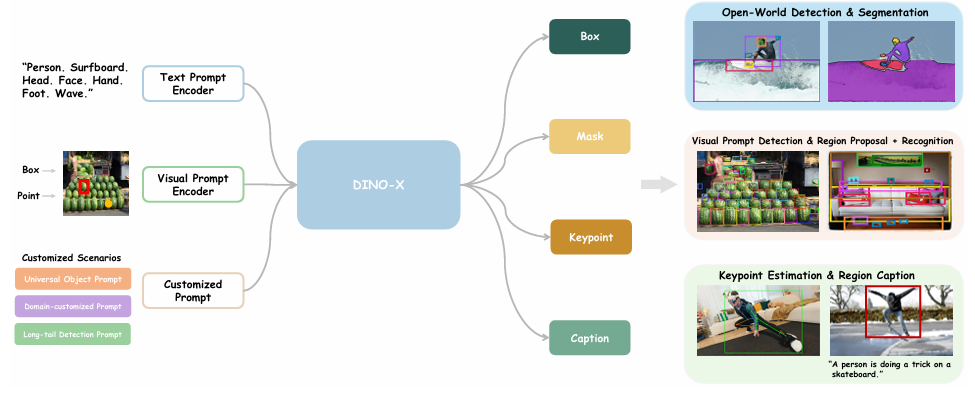
接受文本提示、视觉提示和自定义提示作为输入,并且可以生成各个语义层面的表示,包括边界框、分割蒙版、姿势关键点和对象标题
Pro
文本提示编码器:CLIP的文本编码器
视觉提示编码器:采用了来自T-Rex2 的视觉提示编码器,将其整合以利用用户定义的箱形和点形式的视觉提示来增强物体检测。通过正弦-余弦层转换成位置嵌入。模型使用不同的线性投影分离箱形和点提示
自定义提示:通过提示微调技术覆盖更多的长尾、特定领域或功能特定场景
给定一张输入图像和用户提供的提示,无论是文本、视觉还是自定义提示嵌入,DINO-X都会在提示与从输入图像中提取的视觉特征之间进行深层特征融合,然后根据不同感知任务应用不同的头。具体实现的头部如下所述:
框头:遵循Grounding DINO,采用了语言引导的查询选择模块,接着是一个简单的MLP层来预测每个对象查询对应的边界框坐标
Mask头:遵循Mask2Former和Mask DINO的核心设计,我们通过融合1/4分辨率的主干特征和从Transformer编码器上采样的1/8分辨率特征来构建像素嵌入图。然后,我们计算Transformer解码器中的每个对象查询与像素嵌入图之间的点积以获取查询的掩膜输出
关键点头:接收DINO-X的相关检测输出,例如人或手,作为输入,并使用单独的解码器来解码物体的关键点。每个检测输出被视为一个查询并扩展为多个关键点,然后发送到多个可变形Transformer解码器层来预测所需的关键点位置及其可见性。这个过程可以视为简化的ED-Pose 算法,不需要考虑物体检测任务,而是专注于关键点检测。在DINO-X中,我们实例化了两个人物和手的关键点头,它们分别有17个和21个预定义的关键点。
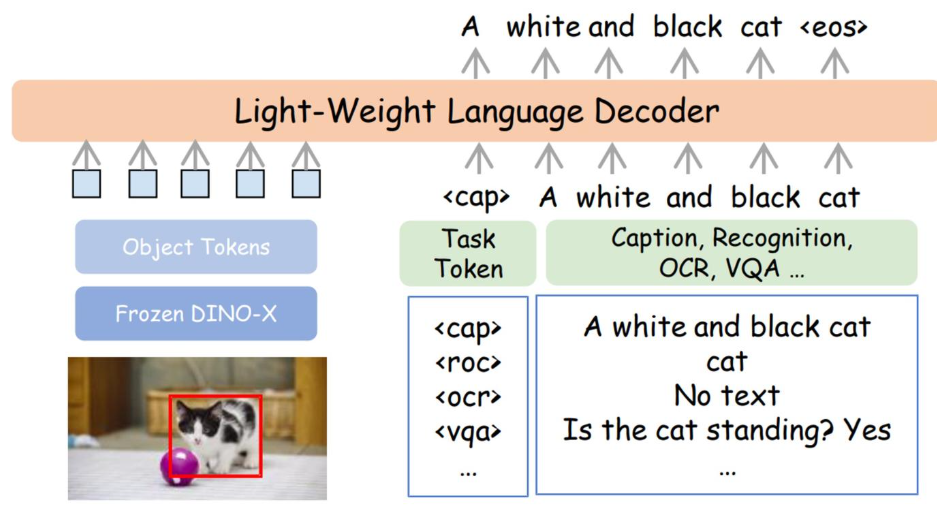
语言头:语言头是一个任务可提示的生成式小型语言模型,用于增强DINO-X理解和执行超出定位任务的感知任务的能力,如物体识别、区域字幕生成、文本识别和基于区域的视觉问答(VQA)。对于DINO-X检测到的任何物体,我们首先使用RoIAlign操作符从DINO-X主干特征中提取其区域特征,结合其查询嵌入形成我们的物体令牌。然后,我们应用一个简单的线性投影以确保它们的维度与文本嵌入对齐。轻量级的语言解码器以自回归方式将这些区域表示与任务令牌集成以生成输出。可学习的任务令牌赋予语言解码器处理各种任务的能力。
Edge
更强的文本提示编码器:CLIP文本编码器
知识蒸馏:从Pro模型使用基于特征的知识蒸馏和基于响应的知识蒸馏以增强Edge模型的性能
改进的FP16推理:我们采用了一种浮点乘法的归一化技术,使得模型可以量化为FP16而不牺牲精度