Spring AI 系列之十三 - RAG-加载本地嵌入模型
之前做个几个大模型的应用,都是使用Python语言,后来有一个项目使用了Java,并使用了Spring AI框架。随着Spring AI不断地完善,最近它发布了1.0正式版,意味着它已经能很好的作为企业级生产环境的使用。对于Java开发者来说真是一个福音,其功能已经能满足基于大模型开发企业级应用。借着这次机会,给大家分享一下Spring AI框架。
注意:由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是 Spring AI-1.0.0,JDK版本使用的是19。
代码参考: https://github.com/forever1986/springai-study
目录
- 1 运行本地的嵌入模型
- 2 基于ONNX运行embedding模型示例
- 2.1 前期准备
- 2.2 项目初始化
- 2.3 编写模型加载和使用
- 2.4 演示
前几章从入门到进阶的演示了Spring AI的RAG框架。但其中有一个问题就是使用了向量化的模型是智谱云上的Embedding-2,这是部署在云端的付费模型,那么是否可以通过将embedding模型权重下载之后,在本地加载,就不用付费了。
1 运行本地的嵌入模型
上一章的示例中,是通过API的方式访问embedding模型,其实很多embedding模型都是比较小,在本地机子不需要GPU的情况下都可以运行。那么如何在本地运行embedding模型,方法其实有多种,比如采用Ollama方式、ONNX方式。
- Ollama:Ollama方式就是本地基于Ollama部署模型,然后如同你调用远程模型一样调用Ollama中的模型即可。
- ONNX:ONNX是一种开放的神经网络交换格式,无论是pytorch、transforms等框架模型都可以统一格式转换,从而实现模型的可移植性和互操作性。在Java中基于Deep Java 库和 Microsoft ONNX Java Runtime库用于运行 ONNX 模型并计算 Java 中的嵌入。
本次先使用ONNX方式加载本地模型,至于Ollama后面再讲。
2 基于ONNX运行embedding模型示例
参考代码lesson12子模块
示例说明:依旧和lesson11子模块一致,基于智谱的免费大模型,但是embedding模型不再采用智谱的embedding-2的付费,而是通过加载本地的bge-small-zh-v1.5模型作为embedding模型
2.1 前期准备
在开始代码之前,需要下载bge-small-zh-v1.5模型文件,并将其转换为ONNX格式。
1)安装python
2)安装modelscope(魔塔的客户端工具)
pip install modelscope
3)下载模型,通过modelscope的客户端工具下载(如果不想使用modelscope 客户端工具,也可以去魔塔官方网站下载)
modelscope download --model BAAI/bge-small-zh-v1.5 --local_dir BAAI

4)安装ONNX
pip install optimum onnx onnxruntime sentence-transformers
5)转换模型(其中:BAAI是模型的路径,onnx是转换后模型文件路径)
optimum-cli export onnx --task sentence-similarity --model BAAI onnx
可以看到onnx目录下onnx生成了ONNX格式的模型文件
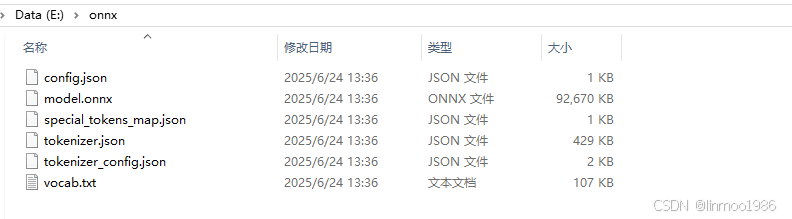
说明:其中model.onnx是权重文件,tokenizer.json是tokenizer分词器配置文件,这两个文件后续会使用的
2.2 项目初始化
1)新建子模块lesson12,其pom配置如下:
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-zhipuai</artifactId></dependency><!-- 引入向量数据库插件 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-advisors-vector-store</artifactId></dependency><!-- 引入model-transformers插件 为了加载onnx格式模型--><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-transformers</artifactId></dependency>
</dependencies>
2)在resources目录下新建bge-small-zh子目录,并将ONNX格式的模型和tokenizer.json文件拷贝到该目录下
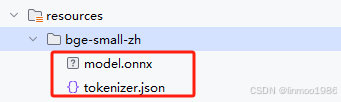
3)在resources目录下,新建application.properties配置文件
# 聊天模型
spring.ai.zhipuai.api-key=你的智谱模型的API KEY
spring.ai.zhipuai.chat.options.model=GLM-4-Flash-250414
spring.ai.zhipuai.chat.options.temperature=0.7# embedding模型的权重文件
spring.ai.embedding.transformer.onnx.modelUri=classpath:/bge-small-zh/model.onnx
# embedding模型的tokenizer配置文件
spring.ai.embedding.transformer.tokenizer.uri=classpath:/bge-small-zh/tokenizer.json
# embedding模型输出参数,这里做向量编码,因此返回token_embeddings
spring.ai.embedding.transformer.onnx.modelOutputName=token_embeddings
4)创建启动类Lesson12Application :
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class Lesson12Application {public static void main(String[] args) {SpringApplication.run(Lesson12Application.class, args);}}
2.3 编写模型加载和使用
1)创建VectorStoreConfig配置类,初始化向量存储VectorStore
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.transformers.TransformersEmbeddingModel;
import org.springframework.ai.vectorstore.SimpleVectorStore;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.List;
import java.util.Map;@Configuration
public class VectorStoreConfig {/*** @param transformersEmbeddingModel - 这里使用TransformersEmbeddingModel,就是配置加载本地的embedding模型*/@Beanpublic VectorStore vectorStore(TransformersEmbeddingModel transformersEmbeddingModel){SimpleVectorStore simpleVectorStore = SimpleVectorStore.builder(transformersEmbeddingModel).build();List<Document> documents = List.of(new Document("ChatGLM3 是北京智谱华章科技有限公司和清华大学 KEG 实验室联合发布的对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:\n" +"\n" +"更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,* ChatGLM3-6B-Base 具有在 10B 以下的基础模型中最强的性能*。\n" +"更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式 ,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。\n" +"更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM3-6B-Base 、长文本对话模型 ChatGLM3-6B-32K 和进一步强化了对于长文本理解能力的 ChatGLM3-6B-128K。以上所有权重对学术研究完全开放 ,在填写 问卷 进行登记后亦允许免费商业使用。\n" +"\n" +"北京智谱华章科技有限公司是一家来自中国的公司,致力于打造新一代认知智能大模型,专注于做大模型创新。"));simpleVectorStore.add(documents);return simpleVectorStore;}}
注意:这里使用的是TransformersEmbeddingModel的embedding模型,如果你使用原先的EmbeddingModel可能会出现冲突,因为智谱会自动加载其EmbeddingModel。
2)创建演示类RAGController:
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.vectorstore.QuestionAnswerAdvisor;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;@RestController
public class RAGController {private ChatClient chatClient;public RAGController(ChatClient.Builder chatClientBuilder, VectorStore vectorStore) {this.chatClient = chatClientBuilder// 通过Advisors方式,对向量数据库进行封装.defaultAdvisors(new QuestionAnswerAdvisor(vectorStore)).build();}/*** @param message 问题*/@GetMapping("/ai/rag")public String rag(@RequestParam(value = "message", required = true, defaultValue = "ChatGLM3是哪个国家的大模型?") String message) {return this.chatClient.prompt().user(message).call().content();}}
2.4 演示
1)启动项目,第一次启动时会出现下载pytorch的dll文件

下载成功之后
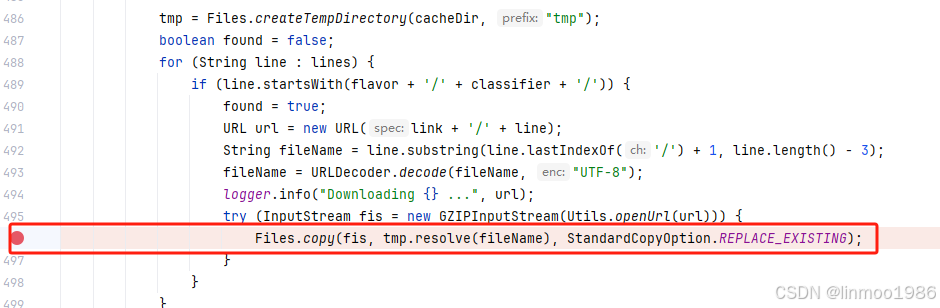
注意:这里可能会下载失败,因为文件还是比较大的,经常下载失败,可以使用debug一下ai.djl.pytorch.jni.LibUtils类进行一个个下载,成功率好像会高一些
2)访问地址
http://localhost:8080/ai/rag
结语:本章演示了如何通过本地加载embedding模型,当然包括大模型也可以本地化部署,这样就可以实现RAG过程中完全本地化。下一章还会继续对Spring AI中RAG的功能进行探讨。
Spring AI系列上一章:《Spring AI 系列之十二 - RAG-进阶RetrievalAugmentationAdvisor案例》
Spring AI系列下一章:《Spring AI 系列之十四 - RAG-ETL之一》