论文阅读:A Survey on Large Language Models for Code Generation
地址:A Survey on Large Language Models for Code Generation

摘要
大型语言模型(LLMs)在各种代码相关任务中取得了显著进【展,被称为代码 LLMs,尤其在从自然语言描述生成源代码的代码生成任务中表现突出。这一新兴领域因其在软件开发中的实际意义,如 GitHub Copilot,引起了学术研究人员和行业专业人士的极大兴趣。尽管从自然语言处理(NLP)或软件工程(SE)或两者的角度对 LLMs 进行了各种代码任务的积极探索,但缺乏专门针对代码生成 LLMs 的全面且最新的文献综述。在本综述中,我们旨在通过提供系统的文献综述来填补这一空白,为研究代码生成 LLMs 前沿进展的研究人员提供有价值的参考。我们引入了一个分类法来分类和讨论代码生成 LLMs 的最新发展,涵盖数据管理、最新进展、性能评估、伦理影响、环境影响和实际应用等方面。此外,我们还介绍了代码生成 LLMs 的发展历史概述,并使用 HumanEval、MBPP 和 BigCodeBench 基准在不同难度级别和编程任务类型上进行了实证比较,以突出 LLMs 在代码生成能力方面的逐步提升。我们确定了学术界与实际开发之间差距的关键挑战和有希望的机会。此外,我们建立了一个专门的资源 GitHub 页面(https://github.com/juyongjiang/CodeLLMSurvey),以持续记录和传播该领域的最新进展。
论文总结
本综述系统性地梳理了代码生成大型语言模型(Code LLMs)的前沿进展,为该领域提供了全面的参考框架,具体内容如下:
- 研究背景与目标:Code LLMs 在代码生成任务中展现出重要价值,但缺乏最新的综合性综述。本文通过构建分类法,覆盖数据管理、模型进展、评估体系、伦理影响及实际应用,填补这一空白。
- 核心内容框架
- 发展历程:从早期启发式规则到 Transformer 架构主导,Code LLMs 经历了从功能单一到通用化的演进,如 GPT-4、Code Llama 等模型的出现。
- 关键技术维度:
- 数据层面:涉及预处理(去重、隐私保护)、合成(Self-Instruct、Evol-Instruct)及多源数据集构建(The Stack、HumanEval)。
- 模型层面:涵盖编码器 - 解码器(如 CodeT5)、解码器 - only(如 StarCoder)架构,预训练任务包括因果语言建模(CLM)和去噪自编码(DAE)。
- 优化方法:包括全参数微调(如 WizardCoder)、参数高效微调(LoRA)、强化学习(RLHF、PPOCoder)及提示工程(自我调试、Reflexion)。
- 评估体系:结合 Metrics(Pass@k、CodeBLEU)、人类评估及 LLM 作为评判(如 ICE-Score),覆盖功能正确性、代码质量等维度。
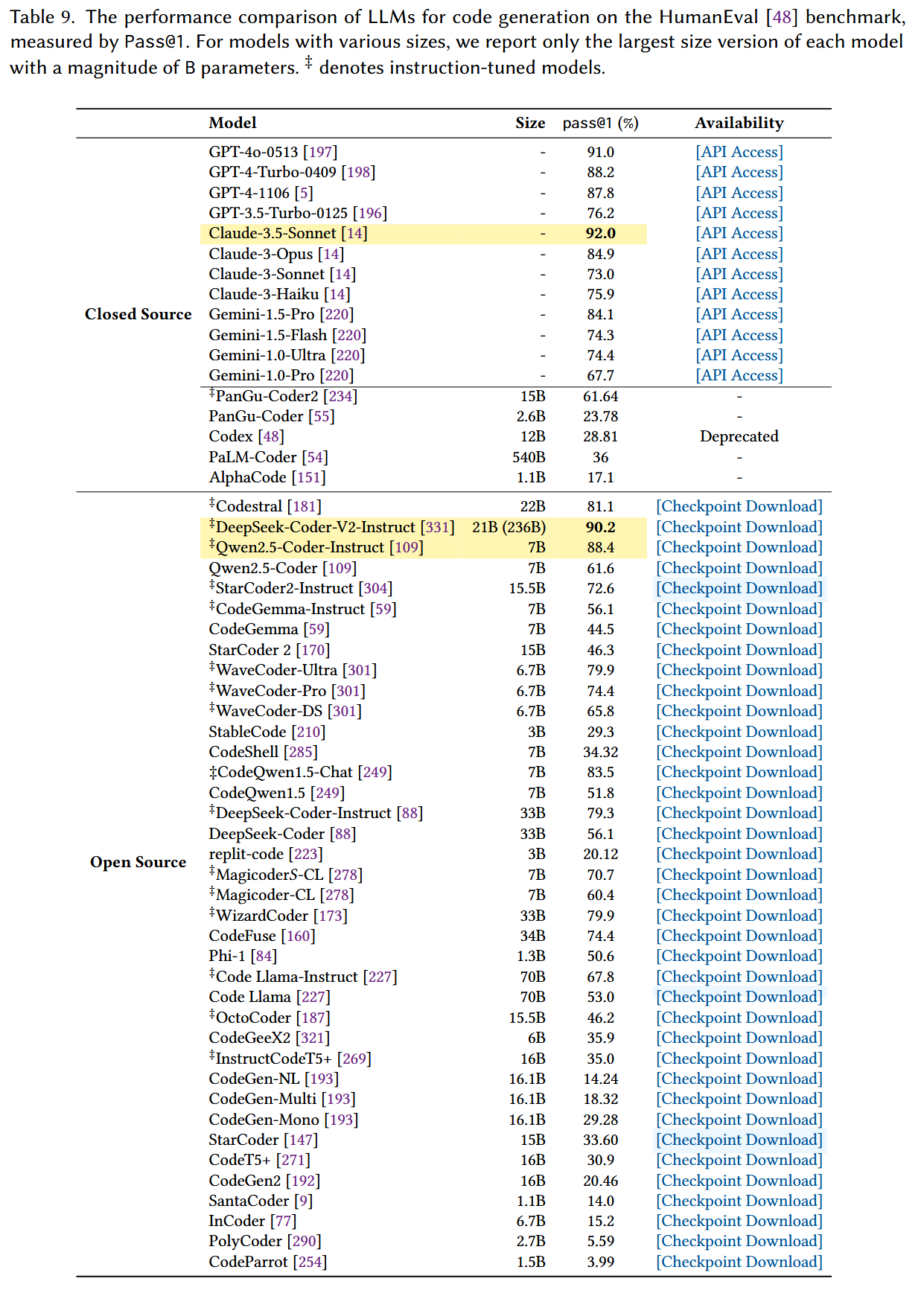
- 实证发现:在 HumanEval、MBPP、BigCodeBench 等基准上,指令微调模型普遍优于基础模型,如 Qwen2.5-Coder-Instruct 在 HumanEval 上 Pass@1 达 88.4%,且开源模型与闭源模型的性能差距逐渐缩小。
- 挑战与机会:
- 挑战:复杂代码生成能力不足、模型架构对代码结构适配性差、低资源语言支持匮乏、安全性与伦理风险等。
- 机会:新型架构(树结构神经网络)、动态知识更新、跨领域应用扩展(如数据科学、多语言支持)。
一、技术方法综述

1、数据处理与管理

- 数据预处理
- 清洗流程:去重(精确匹配、相似度过滤)、噪声过滤(代码长度、字母数字占比阈值)、隐私保护(正则表达式删除 PII)。
- 代表性数据集:The Stack(6TB 代码)、CodeSearchNet(200 万代码 - 注释对)、HumanEval(164 个 Python 编程问题)。
- 数据合成
- 方法:Self-Instruct(基于 LLM 生成指令数据)、Evol-Instruct(渐进式复杂指令进化)、OSS-Instruct(结合开源代码片段减少偏差)。
- 应用:Code Alpaca(2 万指令数据)、WizardCoder(7.8 万进化指令)、Magicoder(7.5 万 OSS-Instruct 数据)。
| 技术类别 | 具体方法 | 优点 | 缺点 | 性能表现 | 评价指标 | 核心数据集 |
|---|---|---|---|---|---|---|
| 数据预处理 | 精确匹配去重、噪声过滤(代码长度 / 字母数字占比)、隐私删除(正则表达式) | 去除冗余数据,提升数据质量;保护隐私(如删除邮箱、用户名) | 可能误删相似有效代码;复杂项目结构文件易被误判为噪声 | The Stack v2 处理后含 3B 文件(600 + 语言) | 数据清洗效率、去重率、隐私保留率 | The Stack、GitHub Code、CodeSearchNet |
| 数据合成 | Self-Instruct、Evol-Instruct、OSS-Instruct | 低成本生成大规模指令数据;Evol-Instruct 通过迭代进化提升数据复杂性 | 合成数据可能存在偏见(如 OSS-Instruct 需人工筛选开源片段) | WizardCoder 用 7.8 万 Evol-Instruct 数据使 Pass@1 提升至 57.3% | 生成数据与真实代码的相似度、任务覆盖率 | Code Alpaca、Magicoder、StarCoder2-Instruct |
2、模型架构与预训练

- 核心架构
- 解码器 - only:如 StarCoder(15.5B 参数,8k 上下文)、Code Llama(70B 参数,16k 上下文),适用于生成任务。
- 编码器 - 解码器:如 CodeT5+(支持代码理解与生成)、AlphaCode(8.7B 参数,竞赛级代码生成)。

- 预训练任务
- 因果语言建模(CLM):自回归预测下一个 token,如 CodeGen 通过 CLM 学习代码序列逻辑。
- 去噪自编码(DAE):掩码重建代码片段,如 CodeT5 通过 DAE 增强结构理解。
- 辅助任务:标识符预测、AST 匹配,提升代码语义理解。

| 架构类型 | 代表模型 | 优点 | 缺点 | 性能(HumanEval Pass@1) | 评价指标 | 适用场景 |
|---|---|---|---|---|---|---|
| 解码器 - only | StarCoder、Code Llama、GPT 系列 | 专注生成任务,自回归架构效率高;长上下文支持(如 Code Llama 达 16k tokens) | 缺乏双向编码能力,代码理解任务表现较弱 | StarCoder 33.6%,Code Llama-Instruct 67.8% | Pass@k、执行准确率、生成速度 | 函数级代码生成、代码补全 |
| 编码器 - 解码器 | CodeT5+、AlphaCode | 同时支持代码理解与生成(如 CodeT5 + 处理代码翻译、摘要);结构建模更完整 | 训练成本高,生成速度慢于解码器 - only 模型 | CodeT5+ 30.9%,AlphaCode 17.1% | CodeBLEU、AST 匹配度、跨任务泛化性 | 代码翻译、跨语言生成、复杂结构生成 |
3、指令微调与优化

- 全参数微调(FFT)
- 方法:使用大规模指令数据微调预训练模型,如 WizardCoder 在 StarCoder 基础上用 7.8 万指令数据提升 Pass@1 至 57.3%。
- 案例:Code Llama-Instruct 通过 260M tokens 指令数据优化指令跟随能力。
- 参数高效微调(PEFT)
- 技术:LoRA(低秩适应,冻结基础参数,训练少量适配器)、QLoRA(量化 + LoRA,减少内存占用)。
- 应用:CodeUp 使用 LoRA 在单 GPU 上微调 Llama2,实现多语言代码生成。

| 策略类型 | 代表方法 | 优点 | 缺点 | 性能提升(vs 基础模型) | 评价指标 | 资源消耗 |
|---|---|---|---|---|---|---|
| 全参数微调(FFT) | WizardCoder、Magicoder | 充分利用预训练知识,性能提升显著(如 WizardCoder 在 StarCoder 基础上提升 23.7%) | 需大量计算资源(如 70B 模型微调需数百 GPU 小时) | Code Llama→Code Llama-Instruct 提升 14.8% | Pass@k、任务泛化性 | 高(显存占用大、训练时间长) |
| 参数高效微调(PEFT) | LoRA、QLoRA | 冻结 99% 基础参数,仅训练适配器(如 LoRA 秩 r=8),显存需求降低 90% 以上 | 性能略低于 FFT(如 CodeUp 用 LoRA 在单 GPU 微调,Pass@1 达 61.6%) | QLoRA 在 7B 模型上保留 85% 性能 | 参数更新率、推理速度、精度损失 | 低(单 GPU 可完成微调) |
4、强化学习与反馈机制
- 基于执行反馈:通过编译器 / 解释器反馈优化代码,如 PPOCoder 结合 AST 与 DFG 相似度奖励,提升功能正确性。
- 人类偏好对齐:RLHF(如 InstructGPT)通过人类排序数据微调,CodeRL 使用单元测试信号作为奖励信号。
| 技术类型 | 代表方法 | 优点 | 缺点 | 性能(HumanEval Pass@1) | 评价指标 | 数据需求 |
|---|---|---|---|---|---|---|
| 执行反馈(RL) | PPOCoder、RLTF | 利用编译器 / 测试用例反馈提升功能正确性(如 PPOCoder 结合 AST/DFG 奖励) | 需大量可执行测试用例,训练稳定性差 | PPOCoder 从 30.9% 提升至 41.2% | 测试通过率、代码鲁棒性 | 高(需结构化测试数据) |
| 人类偏好对齐 | RLHF(InstructGPT 范式) | 生成结果更符合人类预期(如减少有害代码生成) | 人工标注成本极高(需数千小时标注) | - | 人工评分、伦理合规性 | 极高(依赖人工标注) |
5、提示工程
- 自我改进机制:Self-Debugging(利用执行结果迭代优化代码)、Reflexion(通过反思记忆提升决策)。
- 推理增强:Chain-of-Thought(分步推理)、Tree-of-Thought(树状搜索),如 LATS 通过 MCTS 优化代码生成路径。
| 技术类型 | 代表方法 | 优点 | 缺点 | 性能(HumanEval Pass@1) | 评价指标 | 适用场景 |
|---|---|---|---|---|---|---|
| 自我改进 | Self-Debugging、Reflexion | 利用执行错误迭代优化代码(如 Self-Debugging 通过错误解释修正逻辑) | 需多次推理 - 执行循环,效率低;复杂错误难定位 | Reflexion 使 GPT-4 Pass@1 达 94.4% | 错误修复率、迭代次数 | 代码调试、错误修正 |
| 推理增强 | Chain-of-Thought(CoT) | 分步推理提升复杂任务解决能力(如数学问题转代码) | 对简单任务可能过度推理,增加生成耗时 | CoT 使 GSM8K 解题率提升 20% | 多步推理准确率、逻辑连贯性 | 复杂算法生成、数学问题求解 |
6、存储库级与长上下文生成
- 技术挑战:跨文件依赖处理、长上下文建模(如 CodePlan 通过多步编辑计划处理存储库级任务)。
- 方法:RepoFusion 融合存储库上下文、RepoCoder 迭代检索生成,支持万级 token 上下文。
7、检索增强生成
- 框架:REDCODER 检索相关代码片段,DocPrompting 结合文档检索生成代码,解决知识过时与幻觉问题。
- 流程:查询编码→向量数据库检索→上下文融合→LLM 生成,如 HGNN 通过图神经网络增强检索相关性。

| 技术类型 | 代表方法 | 优点 | 缺点 | 性能(RepoEval 指标) | 评价指标 | 挑战场景 |
|---|---|---|---|---|---|---|
| 长上下文处理 | CodePlan、RepoFusion | 处理跨文件依赖(如 CodePlan 生成多文件编辑计划);利用存储库结构信息 | 上下文长度受限(当前模型最多支持 16k tokens);复杂项目易超时 | RepoFusion 在 Stack-Repo 上准确率提升 15% | 跨文件引用准确率、结构一致性 | 大型项目维护、多文件协作 |
| 检索增强 | RepoCoder、DocPrompting | 通过检索相关代码片段提升生成准确性(如 DocPrompting 结合文档检索) | 检索结果可能包含过时 API;噪声检索数据降低性能 | RepoCoder 在代码补全中提升 20% | 检索相关性、生成一致性 | 新框架调用、API 文档生成 |
8、自主编码代理
- 多代理协作:AgentCoder(程序员、测试设计师、执行器代理分工)、MetaGPT 模拟软件开发流程(需求分析→架构设计→编码)。
- 工具集成:OpenDevin 结合 bash 工具执行、代码解释器,实现 GitHub 问题自动解决。

9、评估体系
- 自动化指标:Pass@k(HumanEval 标准)、CodeBLEU(结合 AST/DFG 语义匹配)、执行准确率。
- 人类评估:代码风格、可维护性评分,如 InstructCodeT5 + 通过人工评估验证指令跟随能力。
- LLM 作为评判:ICE-Score 使用 LLM 评估代码质量,AlpacaEval 通过 LLM 对比生成结果。
| 类别 | 指标 / 数据集 | 特点 | 适用场景 | 局限性 |
|---|---|---|---|---|
| 评价指标 | Pass@k(HumanEval) | 执行测试通过率,衡量功能正确性 | 函数级代码生成评估 | 仅覆盖单函数场景,缺乏实际项目评估 |
| CodeBLEU | 结合 AST/DFG 的语义匹配度,优于传统 NLP 指标 | 代码语义相似度评估 | 无法完全反映执行结果 | |
| 核心数据集 | HumanEval | 164 个 Python 编程问题,含单元测试 | 学术研究标准评估 | 任务类型有限,缺乏工业界复杂场景 |
| BigCodeBench | 1140 个复杂 Python 任务,覆盖 139 个库函数调用 | 工业界实际编程场景评估 | 数据规模较小,需持续扩展 | |
| MBPP | 974 个入门级 Python 问题,适合基础代码生成 | 入门级模型评估 | 难度较低,无法体现高级编程能力 |
二、当前研究热点
1、复杂代码生成与长上下文处理
随着软件开发项目规模不断扩大,代码结构愈发复杂,跨文件、跨模块的代码生成需求凸显。如何让 Code LLMs 有效处理长上下文,理解并生成涉及多个类、函数间复杂调用关系与依赖的代码,成为当下热点。像针对存储库级任务,RepoFusion、CodePlan 等方法尝试利用存储库结构信息,生成多文件编辑计划,但现有模型上下文长度仍受限,难以应对超大型项目。同时,如何在长序列数据处理中,提升模型对代码逻辑连贯性与一致性的把握,也是研究重点,如探索更优的长上下文建模架构,以突破 Transformer 二次计算复杂性瓶颈,实现线性时间推理与训练。
2、检索增强生成(RAG)技术深化
单纯依赖模型参数记忆生成代码,易出现知识过时、幻觉等问题,RAG 技术通过检索外部知识库辅助生成,成为改进关键。当下热点集中于优化检索器与生成器集成方式,提高检索效率与生成质量,如 REDCODER、DocPrompting 等框架探索更有效的查询编码、向量数据库检索及上下文融合策略。跨模态应用场景下的 RAG 研究也备受关注,例如结合代码注释、文档图片等多模态信息检索,生成更贴合实际需求的代码;以及如何让模型动态更新知识,及时跟进最新 API、框架变化,持续优化代码生成结果。
3、自主编码代理与多智能体协作
构建具备自主决策、任务规划与执行能力的编码代理,模拟人类程序员协作开发流程,是极具潜力的热点方向。像 MetaGPT 模拟软件开发全流程,从需求分析到编码;AgentCoder 实现程序员、测试设计师等多代理分工协作。研究聚焦于提升代理的常识推理、持续学习与多任务处理能力,使其能灵活应对复杂多变的开发任务,以及优化代理间通信、协调机制,避免冲突,提升整体协作效率,在实际项目中实现高效自动化开发。
三、挑战
1、复杂代码生成能力不足
当前模型在生成涉及复杂算法、设计模式及大规模系统架构代码时,表现欠佳。生成代码常存在逻辑漏洞、结构不合理问题,难以满足实际项目工程化要求。需深入研究代码语义理解、结构建模技术,增强模型对复杂编程概念与架构设计的把握能力,通过构建更丰富、复杂的代码数据集与针对性训练任务,提升复杂代码生成质量。
2、模型安全性与伦理风险
代码生成模型可能泄露训练数据中的敏感信息,如隐私数据、商业机密代码片段;生成代码也可能存在安全漏洞、侵权风险,如未经授权使用开源代码。亟待建立完善的数据隐私保护机制,对训练数据进行严格脱敏、过滤;开发代码安全检测工具,在模型生成代码后,自动检测安全漏洞与侵权风险,确保生成代码安全、合规。
3、数据质量与偏见问题
训练数据质量参差不齐,存在噪声、错误标注,影响模型学习效果;同时,数据分布偏见可能导致模型生成代码在特定领域、语言或编程风格上表现不佳。需强化数据预处理流程,采用更先进去噪、清洗技术提升数据纯度;设计公平性评估指标与数据增强方法,消除数据偏见,使模型具备更广泛适用性与公平性,生成多样化、无偏见高质量代码 。