大数据Hadoop集群搭建
文章目录
- 大数据Hadoop集群搭建
- 一、VMware准备Linux虚拟机
- 二、VMware虚拟机系统设置
- 1、主机名、IP、SSH免密登录
- 2、JDK环境部署
- 3、防火墙、SELinux、时间同步
- 三、VMware虚拟机集群上部署HDFS集群
- 1、集群规划
- 2、上传&解压
- 3、Hadoop安装包目录结构
- 4、修改配置文件,应用自定义设置
- 5、准备数据目录
- 6、分发Hadoop文件夹
- 7、配置环境变量
- 8、授权为hadoop用户
- 9、格式化整个文件系统
- 10、查看HDFS WEBUI
- 四、HDFS的Shell操作
- 1、HDFS相关进程的启停管理命令
- 一键启停脚本
- 单进程启停
- 2、HDFS的文件系统操作命令
- HDFS文件系统基本信息
- 介绍
- 1、创建文件夹
- 2、查看指定目录下内容
- 3、上传文件到HDFS指定目录下
- 4、查看HDFS文件内容
- 5、下载HDFS文件
- 6、拷贝HDFS文件
- 7、追加数据到HDFS文件中
- 8、HDFS数据移动操作
- 9、HDFS数据删除操作
- 10、HDFS shell其它命令
- 11、HDFS WEB浏览
- 3、HDFS客户端 - Jetbrians产品插件
- 4、HDFS客户端 - NFS
- 五、MapReduce和YARN的部署
- 一、部署说明
- 二、集群规划
- 三、MapReduce配置文件
- 四、YARN配置文件
- 五、分发配置文件
- 六、集群启动命令介绍
- 七、查看YARN的WEB UI页面
- 提交MapReduce程序至YARN运行
- 六、Hive部署
- WordCount单词计数程序
- JobMain类
- WordCountMapper类
- WordCountReducer类
大数据Hadoop集群搭建
一、VMware准备Linux虚拟机
1、首先准备VMware软件,用于后续创建虚拟机:
这里我使用的是VMware WorkStation Pro 17的版本,如下图:

2、设置VMware网段
在VMware的虚拟网络编辑器中,将VMnet8虚拟网卡的网段设置为192.168.88.0,网关设置为192.168.88.2,如下图:

点击右下角的“更改设置”,进入到下图所示的页面进行网段修改:
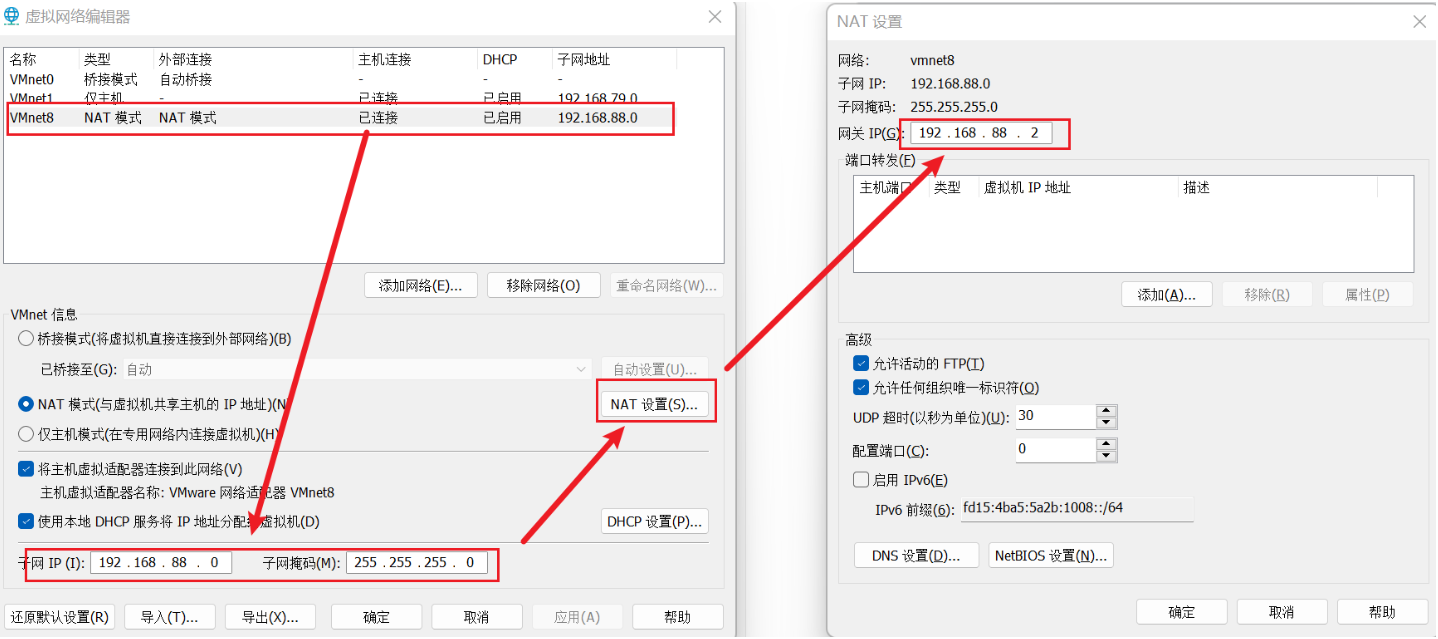
修改好之后点击“确定”即可。
3、下载CentOS的操作系统镜像文件
这里我放在了D:\Hadoop大数据虚拟机路径下

4、创建虚拟机
选择创建虚拟机

选择“典型”

选择刚刚下载好的虚拟机镜像文件

然后设置账号和密码(用于学习的话密码建议直接设置为123456):

接下来给虚拟机起一个名称,选择虚拟机的存放位置,这里我选择放在路径D:\Hadoop大数据虚拟机\vm\bigdata下面,后续创建的三个虚拟机结点也是存放在这个文件夹下面:


磁盘大小选择20~40GB都可以,我这里选择默认的20GB:

最后点击完成,等待虚拟机的安装完成:

接下来我通过已经创建好的名为“CentOS-7.6 Base”的这一个虚拟机去克隆出来三个结点的虚拟机:

虚拟机创建好后如下所示:

然后还要修改一下每个结点的硬件配置,如下:(硬件配置集群规划)
因为后续在node1的节点上运行的软件会多一些,所以这里我们给node1的内存调大一些。
| 节点 | CPU | 内存 |
|---|---|---|
| node1 | 1核心 | 4GB |
| node2 | 1核心 | 2GB |
| node3 | 1核心 | 2GB |
二、VMware虚拟机系统设置
1、主机名、IP、SSH免密登录
配置固定IP地址
开启node1,修改主机名为node1,并修改固定IP为:192.168.88.131
在终端的root用户下执行下面的命令:
# 修改主机名
hostnamectl set-hostname node1# 修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR="192.168.88.131"# 重启网卡
systemctl stop network
systemctl start network
# 或者直接
ststemctl restart network
同样的操作启动node2和node3,修改node2主机名为node2,设置ip为192.168.88.132;修改node3主机名为node3,设置ip为192.168.88.133。
配置主机名映射
在Windows系统中修改hosts文件,填入如下内容:
192.168.88.131 node1
192.168.88.132 node2
192.168.88.133 node3
在3台Linux的/etc/hosts的文件中,填入如下内容(3台都要添加)
192.168.88.131 node1
192.168.88.132 node2
192.168.88.133 node3
配置SSH免密登录
后续安装的集群化软件,多数需要远程登录以及远程执行命令,我们可以简单起见,配置三台Linux服务器之间的免密码互相SSH登录
1、在每一台机器都执行:ssh-keygen -t rsa -b 4096,一路回车到底即可。
2、在每一台机器都执行:
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
3、执行完毕后,node1、node2、node3之间将完成root用户之间的免密互通。
创建hadoop用户并配置免密登录
后续大数据的软件,将不会以root用户启动(确保安全,养成良好的习惯)。
我们为大数据的软件创建一个单独的用户hadoop,并为三台服务器同样配置hadoop用户的免密互通。
1、在每一台机器都执行:useradd hadoop,创建hadoop用户
2、在每一台机器都执行:passwd hadoop,设置hadoop用户密码为123456
3、在每一台机器均切换到hadoop用户:su -hadoop,并执行ssh-keygen -t rsa -b 4096,创建ssh秘钥
4、在每一台机器均执行
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3
2、JDK环境部署
下载JDK1.8,这里我存放到了D:\Hadoop大数据虚拟机路径下:

1、创建文件夹,用来部署JDK,将JDK和Tomcat都安装部署到:/export/server内
mkdir -p /export/server
2、解压缩JDK安装文件
tar -zxvf jdk-8u361-linux-x64.tar.gz -C /export/server
3、配置JDK的软连接
ln -s /export/server/jdk1.8.0_361 /export/server/jdk
4、配置JAVA_HOME环境变量
# 编辑/etc/profile文件
export JAVA_HOME=/export/server/jdk
export PATH=$PATH:$JAVA_HOME/bin
3、防火墙、SELinux、时间同步
关闭防火墙和SELinux:
集群化软件之间需要通过端口互相通讯,为了避免出现网络不通的问题,我们可以简单的在集群内部关闭防火墙。
在每一台机器都执行:
systemctl stop firewalld
systemctl disable firewalld
Linux有一个安全模块:SELinux,用以限制用户和程序的相关权限,来确保系统的安全稳定。
在当前,我们只需要关闭SELinux功能,避免导致后面的软件出现问题即可。
在每一台机器都执行:
vim /etc/sysconfig/selinux# 将第七行,SELINUX=enforcing改为
SELINUX=disabled
# 退出保存后,重启虚拟机即可,千万要注意disabled单词不要写错,不然无法启动系统
修改时区并配置自动时间同步:
一下操作在三台Linux均执行
1、安装ntp软件
yum install -y ntp
2、更新时区
rm -f /etc/localtime;sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
3、同步时间
ntpdate -u ntp.aliyun.com
4、开启ntp服务并设置开机自启
systemctl start ntpd
systemctl enable ntpd
至此,配置Hadoop大数据集群环境的前置准备就已经全部完成了,下面开始正式进入Hadoop集群环境的配置:
三、VMware虚拟机集群上部署HDFS集群
Hadoop安装包下载:(这里我使用hadoop3.3.4的版本)

1、集群规划
在前面的操作中,我们准备了基于VMware的三台虚拟机,其硬件配置如下:
| 节点 | CPU | 内存 |
|---|---|---|
| node1 | 1核心 | 4GB |
| node2 | 1核心 | 2GB |
| node3 | 1核心 | 2GB |
Hadoop HDFS的角色包含:
- NameNode,主节点管理者
- DataNode,从节点工作者
- SecondaryNameNode,主节点辅助
服务规划:
| 节点 | 服务 |
|---|---|
| node1 | NameNode、DataNode、SecondaryNameNode |
| node2 | DataNode |
| node3 | DataNode |
2、上传&解压
注意:请确认已经完成前置准备中的服务器创建、固定IP、防火墙关闭、Hadoop用户创建、SSH免密、JDK部署等操作。
(下面的操作均在node1节点执行,以root身份登录)
1、上传Hadoop安装包到node1节点中
2、解压缩安装包到/export/server/中
tar -zxvf hadoop-3.3.4.tar.gz -C /export/server
3、构建软链接
cd /export/server
ln -s /export/server/hadoop-3.3.4 hadoop
4、进入hadoop安装包内
cd hadoop
3、Hadoop安装包目录结构
cd进入Hadoop安装包内,通过ls -l命令查看文件夹内部结构
4、修改配置文件,应用自定义设置
配置HDFS集群,我们主要涉及到如下文件的修改:
- workers:配置从节点(DataNode)有哪些
- hadoop-env.sh:配置Hadoop的相关环境变量
- core-site.xml:Hadoop核心配置文件
- hdfs-site.xml:HDFS核心配置文件
这些文件均存在与 H A D O O P H O M E / e t c / h a d o o p 文件夹中。( HADOOP_HOME/etc/hadoop文件夹中。( HADOOPHOME/etc/hadoop文件夹中。(HADOOP_HOME是后续我们要设置的环境变量,其指代Hadoop安装文件夹即/export/server/hadoop)
- 配置workers文件
# 进入配置文件目录
cd etc/hadoop
# 编辑workers文件
vim workers
# 填入如下内容
node1
node2
node3
上面填入的node1、node2、node3表明集群记录了三个从节点(DataNode)
- 配置hadoop-env.sh文件
# 填入如下内容
export JAVA_HOME=/export/server/jdk #JAVA_HOME,指明JDK环境的位置在哪
export HADOOP_HOME=/export/server/hadoop #HADOOP_HOME,指明Hadoop安装位置
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop #HADOOP_CONF_DIR,指明Hadoop配置文件目录位置
export HADOOP_LOG_DIR=$HADOOP_HOME/logs #HADOOP_LOG_DIR,指明Hadoop运行日志目录位置
通过记录这些环境变量,来指明上述运行时的重要信息。
- 配置core-site.xml文件
# 在文件内部填入如下内容
<configuration><property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><property><name>io.file.buffer.size</name><value>131072</value></property>
</configuration>
-
hdfs://node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议)
-
表明DataNode将和node1的8020端口通讯,node1是NameNode所在机器
-
此配置固定了node1必须启动NameNode进程
-
配置hdfs-site.xml文件
<configuration><property> # key:dfs.datanode.data.dir.perm<name>dfs.datanode.data.dir.perm</name> # 含义:hdfs文件系统,默认创建的文件权限位置<value>700</value> # 值:700,即:rwx------</property><property> # key:dfs.namenode.name.dir<name>dfs.namenode.name.dir</name> # 含义:NameNode元数据的存储位置<value>/data/nn</value> # 值:/data/nn,在node1节点的/data/nn目录下</property><property> # key:dfs.namenode.hosts<name>dfs.namenode.hosts</name> # 含义:NameNode允许哪几个节点的DataNode连接(即允许加入集群)<value>node1,node2,node3</value> # 值:node1、node2、node3,这三台服务器被授权</property><property> # key:dfs.blocksize<name>dfs.blocksize</name> # 含义:hdfs默认块大小<value>268435456</value> # 值:268435456(256MB)</property><property> # key:dfs.namenode.handler.count<name>dfs.namenode.handler.count</name> # 含义:nameode处理的并发线程数<value>100</value> # 值:100,以100个并行度处理文件系统的管理任务</property><property> # key:dfs.datanode.data.dir<name>dfs.datanode.data.dir</name> # 含义:从节点DataNode的数据存储目录<value>/data/dn</value> # 值:/data/dn,即数据存放在node1、node2、node3,三台机器的</property> # /data/dn内
</configuration>
<configuration><property> <name>dfs.datanode.data.dir.perm</name> <value>700</value> </property><property> <name>dfs.namenode.name.dir</name> <value>/data/nn</value> </property><property> <name>dfs.namenode.hosts</name> <value>node1,node2,node3</value> </property><property> <name>dfs.blocksize</name> <value>268435456</value> </property><property> <name>dfs.namenode.handler.count</name> <value>100</value> </property><property> <name>dfs.datanode.data.dir</name><value>/data/dn</value></property>
</configuration>
5、准备数据目录

6、分发Hadoop文件夹
目前,已经基本完成Hadoop的配置操作,可以从node1将hadoop安装文件夹远程复制到node2、node3。
- 分发
# 在node1执行如下命令
cd /export/server
scp -r hadoop-3.3.4 node2:`pwd`/
scp -r hadoop-3.3.4 node3:`pwd`/
- 在node2执行,为hadoop配置软链接
# 在node2执行如下命令
ln -s /export/server/hadoop-3.3.4/export/server/hadoop
- 在node3执行,为hadoop配置软链接
# 在node3执行如下命令
ln -s /export/server/hadoop-3.3.4/export/server/hadoop

7、配置环境变量
为了方便我们操作Hadoop,可以将Hadoop的一些脚本、程序配置到PATH中,方便后续使用。
在Hadoop文件夹中的bin、sbin两个文件夹内有许多的脚本和程序,现在来配置一下环境变量。
1、vim /etc/profile
# 在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

2、在node2和node3配置同样的环境变量
8、授权为hadoop用户
hadoop部署准备的工作基本完成。
为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个Hadoop服务。
所以,现在需要对文件权限进行授权。
(请确保已经提前创建好了hadoop用户,并配置好了hadoop用户之间的免密登录)
- 以root身份,在node1、node2、node3三台服务器上均执行如下命令
# 以root身份,在三台服务器上均执行
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export
9、格式化整个文件系统
前期准备全部完成,现在对整个文件系统执行初始化。
- 格式化namenode
# 确保以hadoop用户执行
su - hadoop
# 格式化namenode
hadoop namenode -format
- 启动
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh# 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
启动后,可以通过jps命令来查看当前系统重正在运行的Java进行进程有哪些。
10、查看HDFS WEBUI
启动完成后,可以在浏览器打开:http://node1:9870,即可查看到hdfs文件系统的管理网页。
四、HDFS的Shell操作
1、HDFS相关进程的启停管理命令
一键启停脚本
Hadoop HDFS组件内置了HDFS集群的一键启停脚本。
-
$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
执行原理:
- 在执行此脚本的机器上,启动SecondaryNameNode
- 读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,启动NameNode
- 读取workers内容,确认DataNode所在机器,启动全部DataNode
-
$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
执行原理:
- 在执行此脚本的机器上,关闭SecondaryNameNode
- 读取core-site.xml内容(fs.defaultFS项),确认NameNode所在机器,关闭NameNode
- 读取workers内容,确认DataNode所在机器,关闭全部DataNode
单进程启停
除了一键启停外,也可以单独控制进程的启停。
1、$HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程的启停
用法:hadoop-daemon.sh (start|status|stop) (namenode|secondarynamenode|datanode)
2、$HADOOP_HOME/bin/hdfs,此程序也可以用以单独控制所在机器的进程的启停
用法:hdfs --daemon (start|status|stop) (namenode|secondarynamenode|datanode)
2、HDFS的文件系统操作命令
HDFS文件系统基本信息
HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。
HDFS同Linux系统一样,均是以/作为根目录的组织形式。

- Linux:file:/// => file:///usr/local/hello.txt
- HDFS:hdfs://namenode:port**/** => hdfs://node1:8020/usr/local/hello.txt
协议头file:///或hdfs://node1:8020/可以省略
- 需要提供Linux路径的参数,会自动识别为file://
- 需要提供HDFS路径的参数,会自动识别为hdfs://
除非是明确需要写或者是不写会有BUG,否则一般不用写协议头。
介绍
关于HDFS文件系统的操作命令,Hadoop提供了2套命令体系。
- hadoop命令(老版本用法),用法:hadoop fs [generic options]
- hdfs命令(新版本用法),用法:hdfs dfs [generic options]
两者在文件系统操作上,用法完全一致,用哪个都可以(只有某些个别的特殊操作需要选择hadoop命令或hdfs命令)
1、创建文件夹
- hadoop fs -mkdir [-p]
… - hdfs dfs -mkdir [-p]
…
path为待创建的目录,-p选项的行为与Linux mkdir -p一致,它会沿着路径创建父目录。
2、查看指定目录下内容
- hadoop fs -ls [-h] [-R] [
…] - hdfs dfs -ls [-h] [-R] [
…]
path指定目录路径,-h人性化显示文件size,-R递归查看指定目录及其子目录。
3、上传文件到HDFS指定目录下
- hadoop fs -put [-f] [-p] …
- hdfs dfs -put [-f] [-p] …
4、查看HDFS文件内容
- hadoop fs -cat …
- hdfs dfs -cat …
读取大文件可以使用管道符配合more(more命令是Linux中对内容进行翻页的命令)
- hadoop fs -cat | more
- hdfs dfs -cat | more
5、下载HDFS文件
- hadoop fs -get [-f] [-p] …
- hdfs dfs -get [-f] [-p] …
下载文件到本地文件系统指定目录,localhost必须是目录。
-f 覆盖目标文件(已存在下);-p 保留访问和修改时间,所有权和权限。
6、拷贝HDFS文件
- hadoop fs -cp [-f] …
- hdfs dfs -cp [-f] …
-f 覆盖目标文件(已存在下)
7、追加数据到HDFS文件中
整个HDFS文件系统,它的文件的修改只支持两种,第一种是直接删掉,第二种是追加内容。(整个HDFS文件系统只能够进行删除和追加,不能修改里面某一行某一个字符)。
- hadoop fs -appendToFile …
- hdfs dfs -appendToFile …
将所有给定本地文件的内容追加到给定dst文件。dst如果文件不存在,将创建该文件 。如果为-,则输入为从标准输入中读取。
8、HDFS数据移动操作
- hadoop fs -mv …
- hdfs dfs -mv …
移动文件到指定文件夹下,可以使用该命令移动数据以及重命名文件的名称。
9、HDFS数据删除操作
- hadoop fs -rm -r [-skipTrash] URI [URI…]
- hdfs dfs -rm -r [-skipTrash] URI [URI…]
删除指定路径的文件或文件夹,-skipTrash 跳过回收站,直接删除。
# 回收站功能默认关闭,如果要开启需要在core-site.xml内配置:
<property><name>fs.trash.interval</name><value>1440</value>
</property><property><name>fs.trash.checkpoint.interval</name><value>120</value>
</property>#无需重启集群,在哪个机器配的,在哪个机器执行命令就生效。回收站默认位置在:/usr/用户名(hadoop)/.Trash
10、HDFS shell其它命令
命令官方指导文档:https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-common/FileSystemShell.html
11、HDFS WEB浏览
除了使用命令操作HDFS文件系统之外,在HDFS的WEB UI上也可以查看HDFS文件系统的内容。

但使用WEB浏览操作文件系统,一般会遇到权限问题:

这是因为WEB浏览器中是以匿名用户(dr.who)登录的,其只有只读权限,多数操作是做不了的。
如果需要以特权用户在浏览器中进行操作,需要配置如下内容到core-site.xml并重启集群。
<property><name>hadoop.http.staticuser.user</name><value>hadoop</value>
</property>
但是,不推荐这样做:HDFS WEBUI只读权限挺好的,简单浏览即可。而且如果给与高权限,会有很大的安全问题,造成数据泄露或丢失。
3、HDFS客户端 - Jetbrians产品插件
4、HDFS客户端 - NFS
注意:要求Windows电脑为专业版,家庭版没有NFS服务。

五、MapReduce和YARN的部署
一、部署说明
Hadoop HDFS分布式文件系统,我们会启动:
- NameNode进程作为管理节点
- DataNode进程作为工作节点
- SecondaryNameNode作为辅助
同理,Hadoop YARN分布式资源调度,会启动:
- ResourceManager进程作为管理节点
- NodeManager进程作为工作节点
- ProxyServer、JobHistoryServer这两个辅助节点

MapReduce运行在YARN容器内,无需启动独立进程。
所以关于MapReduce和YARN的部署,其实就是2件事情:
- 关于MapReduce:修改相关配置文件,但是没有进程可以启动。
- 关于YARN:修改相关配置文件,并启动ResourceManager、NodeManager进程以及辅助进程(代理服务器、历史服务器)。
通过表格汇总如下:
| 组件 | 配置文件 | 启动进程 | 备注 |
|---|---|---|---|
| Hadoop HDFS | 需修改 | 需启动NameNode作为主节点、DataNode作为从节点、SecondaryNameNode主节点辅助 | 分布式文件系统 |
| Hadoop YARN | 需修改 | 需启动ResourceManager作为集群资源管理者、NodeManager作为单机资源管理者、ProxyServer代理服务器提供安全性、JobHistoryServer记录历史信息和日志 | 分布式资源调度 |
| Hadoop MapReduce | 需修改 | 无需启动任何进程,MapReduce程序运行在YARN容器内 | 分布式数据计算 |
二、集群规划
有3台服务器,其中node1配置较高。
集群规划如下:
| 主机 | 角色 |
|---|---|
| node1 | ResourceManager、NodeManager、ProxyServer、JobHistoryServer |
| node2 | NodeManager |
| node3 | NodeManager |
三、MapReduce配置文件
在$HADOOP_HOME/etc/hadoop文件夹内,修改:
- mapred-env.sh文件,添加如下环境变量
# 设置JDK路径
export JAVA_HOME=/export/server/jdk
# 设置JobHistoryServer进程的内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
# 设置日志级别为INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
- mapred-site.xml文件,添加如下配置信息
<property><name>mapreduce.framework.name</name><value>yarn</value><description>MapReduce的运行框架设置为YARN</description>
</property><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value><description>历史服务器通讯端口为node1:10020</description>
</property><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value><description>历史服务器web端口为node1的19888</description>
</property><property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/data/mr-history/tmp</value><description>历史信息在HDFS的记录临时路径</description>
</property><property><name>mapreduce.jobhistory.done-dir</name><value>/data/mr-history/done</value><description>历史信息在HDFS的记录路径</description>
</property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME设置为HADOOP_HOME</description>
</property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME设置为HADOOP_HOME</description>
</property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value><description>MapReduce HOME设置为HADOOP_HOME</description>
</property>
四、YARN配置文件
在$HADOOP_HOME/etc/hadoop文件夹内,修改:
- yarn-env.sh文件,添加如下4行环境变量内容:
# 设置JDK路径的环境变量
export JAVA_HOME=/export/server/jdk
# 设置HADOOP_HOME的环境变量
export HADOOP_HOME=/export/server/hadoop
# 设置配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# 设置日志文件路径的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
- yarn-site.xml文件
<property><name>yarn.resourcemanager.hostname</name><value>node1</value><description>ResourceManager设置在node1节点</description>
</property><property><name>yarn.nodemanager.local-dirs</name><value>/data/nm-local</value><description>NodeManager中间数据本地存储路径</description>
</property><property><name>yarn.nodemanager.log-dirs</name><value>/data/nm-log</value><description>NodeManager数据日志本地存储路径</description>
</property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>为MapReduce程序开启Shuffle服务</description>
</property><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value><description>历史服务器URL</description>
</property><property><name>yarn.web-proxy.address</name><value>node1:8089</value><description>代理服务器主机和端口</description>
</property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>开启日志聚合</description>
</property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/tmp/logs</value><description>程序日志HDFS的存储路径</description>
</property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value><description>选择公平调度器</description>
</property>
五、分发配置文件
MapReduce和YARN的配置文件修改好后,需要分发到其它的服务器节点中。
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node3:`pwd`/
分发完配置文件,就可以启动YARN的相关进程了。
六、集群启动命令介绍
常见的进程启动命令如下:
- 一键启动YARN集群:$HADOOP_HOME/sbin/start-yarn.sh
- 会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager
- 会基于workers文件配置的主机启动NodeManager
- 一键停止YARN集群:$HADOOP_HOME/sbin/stop-yarn.sh
七、查看YARN的WEB UI页面
打开http://node:8080即可看到YARN集群的监控页面(ResourceManager的WEB UI)
提交MapReduce程序至YARN运行
六、Hive部署
Hive是分布式运行的框架还是单击运行的?
Hive是单机工具,只需要部署在一台服务器即可。
Hive虽然是单机的,但是它可以提交分布式运行的MapReduce程序运行。
WordCount单词计数程序
下面单词计数程序的运行命令:
hadoop jar mapreduce_wordcount-1.0-SNAPSHOT.jar cn.itcast.mapreduce.JobMain
hdfs dfs -rm -r hdfs://node1:8020/wordcount_out
hadoop jar mapreduce_wordcount-1.0-SNAPSHOT.jar cn.itcast.mapreduce.JobMain 1
hadoop jar mapreduce_wordcount-1.0-SNAPSHOT.jar cn.itcast.mapreduce.JobMain 2
hadoop jar mapreduce_wordcount-1.0-SNAPSHOT.jar cn.itcast.mapreduce.JobMain 3
JobMain类
package cn.itcast.mapreduce;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;public class JobMain extends Configured implements Tool {@Overridepublic int run(String[] strings) throws Exception {//创建一个任务对象Job job = Job.getInstance(super.getConf(), "mapreduce-wordcount");//打包放在集群运行时,需要做一个配置job.setJarByClass(JobMain.class);//第一步:设置读取文件的类:K1和V1job.setInputFormatClass(TextInputFormat.class);TextInputFormat.addInputPath(job,new Path("hdfs://node1:8020/wordcount"));//第二步:设置Mapper类job.setMapperClass(WordCountMapper.class);//设置Map阶段的输出类型:K2和V2的类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);//第三、四、五、六步采用默认方式(分区、排序、规约、分组)//第七步:设置我们的Reducer类job.setReducerClass(WordCountReducer.class);//设置Reduce阶段的输出类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);//第八步:设置输出类job.setOutputFormatClass(TextOutputFormat.class);//设置输出路径TextOutputFormat.setOutputPath(job,new Path("hdfs://node1:8020/wordcount_out"));boolean b = job.waitForCompletion(true);return b?0:1;}public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();//启动一个任务int run = ToolRunner.run(configuration, new JobMain(), args);System.exit(run);}
}
WordCountMapper类
package cn.itcast.mapreduce;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** Mapper的泛型:* KEYIN:K1的类型 行偏移量 LongWritable* VALUEIN:v1的类型 一行的文本数据 Text* KEYOUT:k2的类型 每个单词 Text* VALUEOUT:v2的类型 固定值1 LongWritable*/
public class WordCountMapper extends Mapper<LongWritable,Text,Text,LongWritable> {/*map方法是将k1和v1转为k2和v2key:k1value:v1context:表示MapReduce上下文对象K1 V10 hello,world11 hello,hadoop-----------------------K2 V2hello 1world 1hadoop 1
*/@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1、对每一行的数据进行字符串拆分String line = value.toString();String[] split = line.split(",");//2、遍历数组,获取每一个单词for(String word : split){context.write(new Text(word),new LongWritable(1));}}
}
WordCountReducer类
package cn.itcast.mapreduce;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** KEYIN:K2的类型 Text 每个单词* VALUEIN:v2的类型 LongWritable 集合中泛型的类型* KEYOUT:k3的类型 Text 每个单词* VALUEOUT:v3的类型 LongWritable 每个单词出现的次数*/
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {/*reduce的方法的作用是将K2和V2转化为K3和V3key:K2values:集合context:MapReduce的上下文对象*//*新 K2 V2hello <1,1>world <1,1>hadoop <1,1,1>--------------------K3 V3hello 2world 2hadoop 3*/@Overrideprotected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException {long count = 0;//1、遍历values集合for(LongWritable value : values){//2、将集合中的值相加count+=value.get();}//3、将k3和v3写入上下文中context.write(key,new LongWritable(count));}
}
package cn.itcast.mapreduce;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/*** KEYIN:K2的类型 Text 每个单词* VALUEIN:v2的类型 LongWritable 集合中泛型的类型* KEYOUT:k3的类型 Text 每个单词* VALUEOUT:v3的类型 LongWritable 每个单词出现的次数*/
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {/*reduce的方法的作用是将K2和V2转化为K3和V3key:K2values:集合context:MapReduce的上下文对象*//*新 K2 V2hello <1,1>world <1,1>hadoop <1,1,1>--------------------K3 V3hello 2world 2hadoop 3*/@Overrideprotected void reduce(Text key, Iterable<LongWritable> values,Context context) throws IOException, InterruptedException {long count = 0;//1、遍历values集合for(LongWritable value : values){//2、将集合中的值相加count+=value.get();}//3、将k3和v3写入上下文中context.write(key,new LongWritable(count));}
}