一致性hash
目录
- 传统哈希的局限性
- 节点增减时数据迁移量大
- 负载不均衡
- 无法支持动态扩展
- 容易产生热点问题
- 维护成本高
- 一致性hash 和普通hash的特征比较
- 一致性hash的实现原理
- 哈希环的结构
- 数据分配逻辑
- 虚拟节点的作用
- 节点增减时的处理
- 一致性hash解决传统hash的问题
- 一致性hash的应用场景
- 一致性hash为什么是2^32?
传统哈希的局限性
传统哈希,例如如 hash(key) % N)在节点数 N 变化时,所有数据的哈希值都需要重新计算,导致分配不均,节点映射变化大。
测试代码:
import java.util.*;public class TraditionalHashSimulation {// 模拟一个传统哈希映射器static class TraditionalHashMapper {private final Set<String> nodes = new HashSet<>();public void addNode(String node) {nodes.add(node);}public void removeNode(String node) {nodes.remove(node);}public String getNodeForKey(String key) {int hash = Math.abs(key.hashCode());int nodeIndex = hash % nodes.size();return (String) nodes.toArray()[nodeIndex];}public List<String> getNodes() {return new ArrayList<>(nodes);}}// 模拟测试数据迁移率public static void testMigrationRate(int initialNodeCount, int newNodesCount, int totalKeys) {TraditionalHashMapper mapper = new TraditionalHashMapper();// 添加初始节点for (int i = 0; i < initialNodeCount; i++) {mapper.addNode("Node-" + i);}// 生成键并记录其分配的节点Map<String, String> keyToNodeBefore = new HashMap<>();for (int i = 0; i < totalKeys; i++) {String key = "key-" + i;keyToNodeBefore.put(key, mapper.getNodeForKey(key));}// 添加新节点,模拟扩容for (int i = initialNodeCount; i < newNodesCount; i++) {mapper.addNode("Node-" + i);}// 再次分配键并统计迁移率int migrated = 0;for (Map.Entry<String, String> entry : keyToNodeBefore.entrySet()) {String key = entry.getKey();String oldNode = entry.getValue();String newNode = mapper.getNodeForKey(key);if (!newNode.equals(oldNode)) {migrated++;}}double migrationRate = (double) migrated / totalKeys * 100;System.out.println("迁移比例: " + String.format("%.2f%%", migrationRate));}public static void main(String[] args) {// 测试:从 3 节点扩容到 4 节点,共 10000 个 keytestMigrationRate(3, 4, 10000);}
}
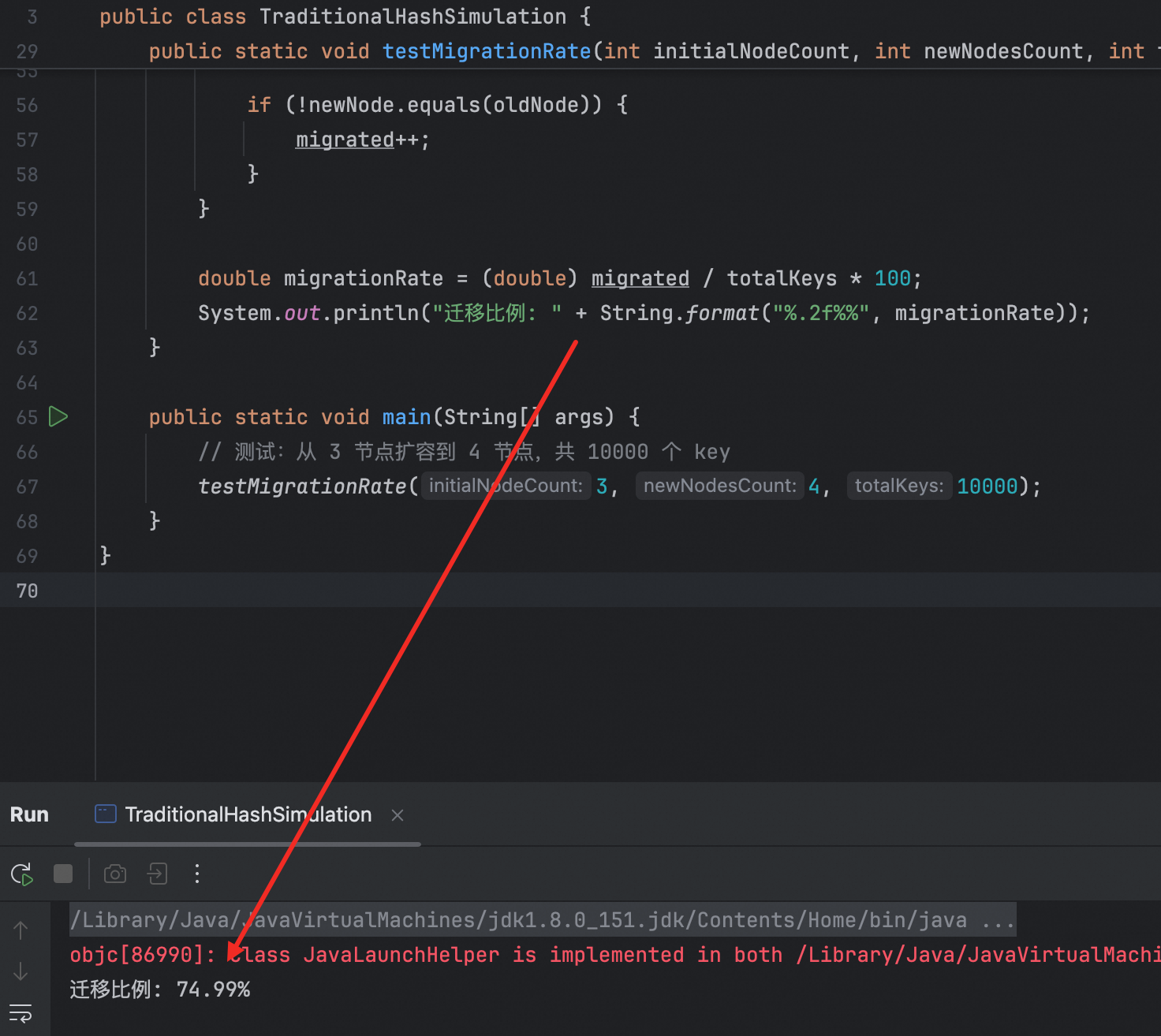
如上测试这表明当节点数从 3 增加到 4 时,有70%多的 key 会被重新分配,这说明传统哈希在节点变化时存在大规模数据迁移的问题。
节点增减时数据迁移量大
- 问题描述:
当节点数 N 发生变化时(如新增或移除服务器),所有数据的哈希值需要重新计算,导致大规模数据迁移。 - 示例:
若缓存集群从 3 台服务器扩容到 4 台,传统哈希会重新分配所有数据的存储位置,即使数据量是 100 万条,也需要全部迁移。 - 后果:
高昂的迁移开销可能导致系统性能下降甚至短暂不可用。
负载不均衡
- 问题描述:
传统哈希无法保证数据在节点间的均匀分布,容易出现数据倾斜(某些节点负载过高)。 - 原因:
哈希函数的输出分布不完美(如 MD5 的局部不均匀性)。
节点数为 N 时,哈希取模的余数范围为 [0, N-1],若 N 不是 2 的幂次,余数分布会不均衡。 - 后果:
热点节点可能成为性能瓶颈,而其他节点资源闲置。
无法支持动态扩展
- 问题描述:
传统哈希对节点数 N 的依赖性强,节点数固定时表现良好,但在动态扩容/缩容的场景下失效。 - 典型场景:
云服务中按需扩缩容(如 Kubernetes 集群)。
数据库分片策略调整时需重新分配数据。 - 后果:
系统无法灵活适应规模变化,需停机维护或手动迁移数据。
容易产生热点问题
- 问题描述:
某些特定键(如高频访问的 key)可能被集中分配到同一节点,导致该节点负载远超其他节点。 - 原因:
- 数据分布不均(如用户 ID 为连续数字)。
- 哈希函数未考虑业务特性(如时间戳、地理位置)。
- 后果:
热点节点可能因过载崩溃,影响整体系统稳定性。
维护成本高
- 问题描述:
传统哈希需要手动管理节点与数据的映射关系,维护复杂度随节点数增加而上升。 - 典型问题:
- 新增节点时需人工重新分区数据。
- 节点故障时需手动转移数据到其他节点。
- 后果:
降低系统自动化程度,增加运维负担。
一致性hash 和普通hash的特征比较
| 特性 | 一致性哈希 | 普通哈希(取模) |
|---|---|---|
| 节点增减影响 | 仅影响局部数据 | 全部数据需重分布 |
| 负载均衡 | 虚拟节点优化后较均衡 | 依赖节点数,易不均衡 |
| 实现复杂度 | 中等(需维护哈希环) | 简单 |
| 适用场景 | 动态节点环境(如云服务) | 固定节点数的场景 |
一致性hash的实现原理
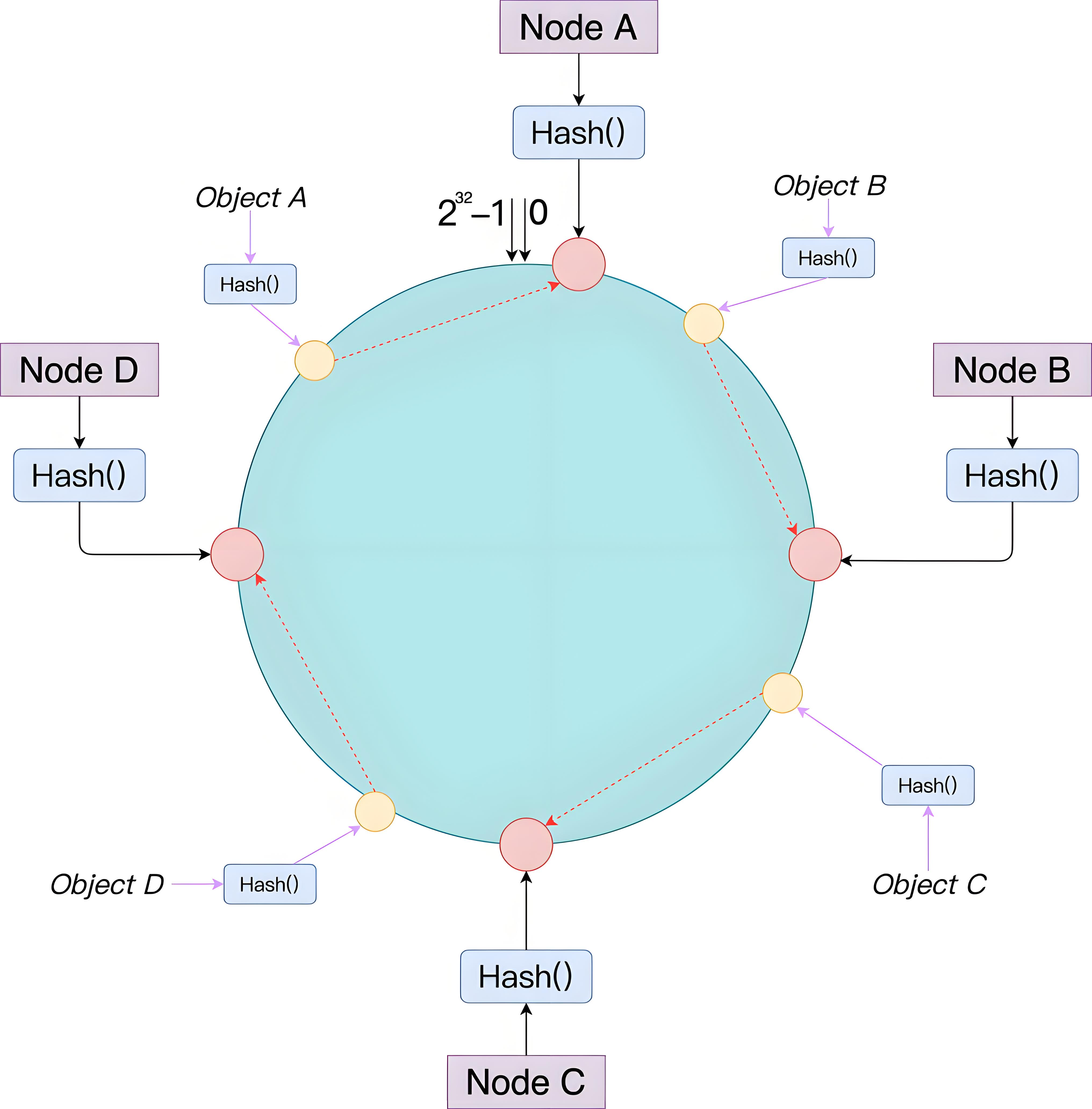
哈希环的结构
- 虚拟环形空间:将节点和数据项映射到一个虚拟的环形哈希空间(通常为 0 到 2^32的范围)。
- 节点与数据的哈希映射:
- 每个节点(物理或虚拟节点)通过哈希函数(如 MD5、CRC32)计算其在环上的位置。
- 数据项同样通过哈希函数确定其在环上的位置。
数据分配逻辑
- 顺时针查找:对于任意数据项,计算其哈希值后,在哈希环上沿顺时针方向查找第一个节点,该节点负责存储该数据项。
- 示例:假设哈希环上有节点 A、B、C,数据项 D 的哈希值位于 A 和 B 之间,则 D 被分配给 B。
虚拟节点的作用
- 问题背景:物理节点直接映射到哈希环可能导致分布不均(如节点数量少时,部分区域负载高)。
- 虚拟节点的引入:
- 每个物理节点生成多个虚拟节点(如 100 个),这些虚拟节点均匀分布在哈希环上。
- 虚拟节点仍指向同一个物理节点,但覆盖的区域更小,从而实现更均匀的数据分布。
- 效果:
- 减少数据倾斜(负载不均衡)。
- 提升负载均衡能力,尤其在物理节点数量较少时。
节点增减时的处理
-
添加节点
操作:新节点的虚拟节点插入到哈希环中。
影响:仅需迁移新节点顺时针方向相邻区域的数据到新节点。
示例:在节点 A 和 B 之间添加新节点 C,则原本属于 B 的部分数据迁移至 C。 -
移除节点
操作:旧节点的虚拟节点从哈希环中移除。
影响:其负责的数据迁移至下一个顺时针方向的节点。
示例:移除节点 B 后,其数据迁移至 C。
一致性hash解决传统hash的问题
| 特性 | 一致性哈希 | 传统哈希 |
|---|---|---|
| 数据迁移量 | 局部迁移(仅影响邻近数据) | 全量迁移(所有数据重分布) |
| 负载均衡 | 通过虚拟节点优化,数据分布更均匀 | 依赖哈希函数质量,易倾斜 |
| 动态扩展支持 | 支持动态增减节点,无需停机 | 不支持,需手动调整 |
| 热点问题缓解 | 虚拟节点分散热点压力 | 无法缓解 |
一致性hash的应用场景
- 分布式缓存:如 Memcached、Redis 集群。
- 数据库分片:如 Cassandra、DynamoDB。
- 内容分发网络(CDN):根据用户地理位置动态分配服务器。
- 微服务架构:服务发现与负载均衡(如 Consul、etcd)。
redis集群使用一致性hash见:https://doctording.blog.csdn.net/article/details/148265781
一致性hash为什么是2^32?
1. 与IPv4地址的兼容性:服务器IP地址由32位二进制数构成,因此2^32的哈希空间能确保每个IP地址获得唯一映射,避免冲突。
2. 数值空间的实用性:
- 足够大的范围:2^32(约42.9亿)的哈希值空间能均匀分布数据,减少哈希冲突概率。
* 计算效率:32位无符号整型的运算在现代计算机中高效且通用。
技术优势
动态扩展性:在集群增减节点时,仅影响哈希环上相邻节点的数据迁移,而非全局重新分配。
负载均衡:大范围的哈希空间更易实现数据的平衡分布,满足一致性哈希的平衡性要求。