java 高并发设计
文章目录
目录
文章目录
前言
一、通用设计
一、动静分离
二、数据库独立部署
三、问题
1.高并发通用设计方法
2.高并发系统的拆分顺序
二、计算资源高并发
三、网络资源高并发
超高性能场景(10万+ QPS)
中小规模场景(5万 QPS以下)
四、数据库高并发
五、
前言
高并发设计可以分为5个部分1.通用设计
1.
面对100万级别的QPS该怎么设计?
请看以下步骤
一、通用设计
一、动静分离
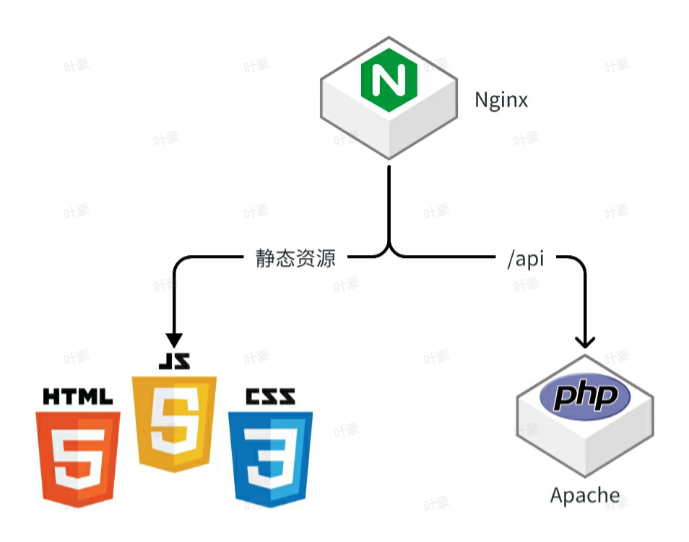
动静分离是高并发的第一步
最开始的项目我们都是要apache tomcat 来承载动态(java http请求)和静态文件(将html、css等放入static文件),而使用动静分离是指的将静态文件(前端预先加载到页面上的内容)放入nginx中
为什么用nginx,nginx处理性能大概是tomcat的4倍
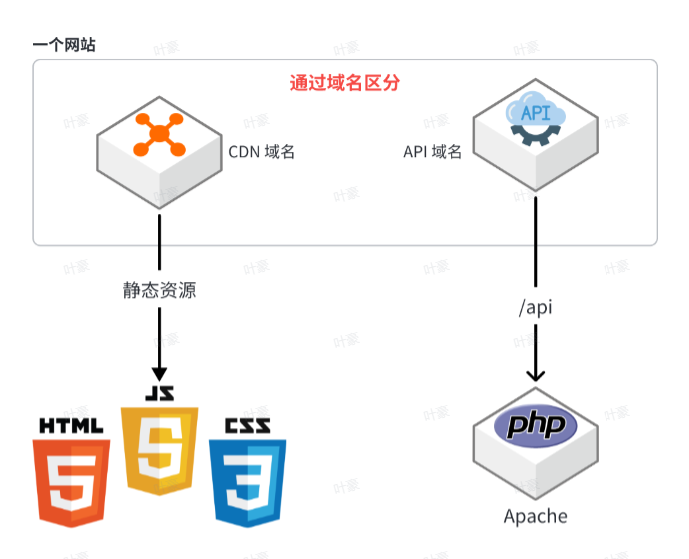
使用云服务
CDN(Content Delivery Network,内容分发网络) 是优化静态资源访问速度和降低服务器负载的核心手段
将全部资源交给云服务厂商的CDN来承载,还以获得90%的CPU节省
对比
| 场景 | CDN 直接承载 | Nginx + CDN |
|---|---|---|
| 架构复杂度 | 无需服务器,纯云服务 | 需维护 Nginx 服务器 |
| 成本 | 按需付费(存储+流量) | 服务器固定成本 + CDN 流量成本 |
| 扩展性 | 自动弹性扩展 | 需手动扩容服务器 |
| 适用场景 | 纯静态资源 | 需动态生成内容(如缩略图) |
二、数据库独立部署
如果使用nginx来承载静态资源之后,云主机还是扛不住流量,那么这时候就应该再用一台主机来:专门跑数据库,甚至有些数据库是部署到多台服务器上
一般来说我们不会将项目(后端代码)和数据库部署到同一台服务器上,这种是典型的灾难架构
这里建议直接使用云服务商的云数据库,因为一旦你的qps超过1000,自建数据库就很难满足要求了,如果搭建集群,小公司成本又太高,而直接使用云数据库就不会出现这种问题,他会自动调整资源
三、问题
1.高并发通用设计方法
高并发系统遇见瓶颈,一定是某个资源点到达极限,例如数据库,服务器,带宽等,因此需要找到这个受限点,拆分并解决
1.负载均衡:分散请求到多个服务器,减少单台服务器压力,例如nginx
2.缓存技术:将经常访问的数据放入缓存(内存中),减少数据库压力,并提高系统响应速度,例如redis
3.异步处理:多线程方式,让任务在后台处理,而主线程先返回。提高系统响应速度,释放服务器占用线程
4.消息队列:将庞大的任务,放入消息队列,由另一个线程或者多个线程来处理,实现异步,削峰,解耦等作用
5.数据库优化:优化SQL,设置数据库集群都可以提高数据库响应速度,从而提高系统响应
6.水平扩展:拆解系统,分别部署到不同服务器,来减少单台服务器cpu压力
7.服务隔离:高并发系统中,不同的模块或者说平台,一般都有隔离开,保证不同服务之间互不影响
2.高并发系统的拆分顺序
高并发系统的拆分应该从静态资源开始拆分,然后在到数据库和服务器机器分离,然后再设计负载均衡和分布式架构,最后再利用数据库集群和分布式数据库来提升数据库能力,期次再考虑其他优化手段
1.静态资源拆分:将原本后端项目集成的静态资源,拆分到nginx或者cdn中进行存储
2.数据库和后端服务机器分离:将数据库和后端服务放到不同的机器上,这样能减少数据库压力,并提高扩展能力
3.负载均衡和分布式架构:通过负载均衡将同一个项目部署到多台机器(也就是多个实例,换句话来说就是用户的请求分发到不同的机器上),提高系统处理能力,同时,采用分布式架构(将系统拆分成独立模块,再),利用多个机器同时进行服务,进一步提高系统并行能力
4.数据库集群和分布式数据库:数据库集群是将多个数据库实例分布到不同的服务器上,通过数据同步和故障转移机制,保证数据库的高可用,分布式数据库是将数据分散到多个节点上,每个数据只负责部分数据的存储和查询,从而提高整个系统的读写能力
5.基于地域进行数据库拆分:
3.静态资源如何加速:
1.高性能web服务器
2.CDN服务:将静态资源分散到全国,用户就能从最近的服务器获取消息,减少延迟
二、计算资源高并发
目标:拆分计算单点,提升并行能力。
主要是部署方法的转变 物理机 → 虚拟机 → 容器化,解决计算资源利用率与弹性问题。
| 阶段 | 核心方案 | 解决的问题 | 瓶颈 |
|---|---|---|---|
| 单服务部署 | 单机运行所有服务 | 简单部署 | 资源争抢(CPU/内存耗尽) |
| 虚拟机部署 | VMware/KVM 虚拟化 | 资源隔离,多应用共存 | 虚拟机启动慢(分钟级) |
| 容器化 | Docker + Kubernetes | 进程级隔离,秒级启动 | 内核兼容性 |
三、网络资源高并发
这里大致总结:就是在7层网络模型上进行高并发的设计
首先gateway或者nginx单台支持的最大qps有限,通常32核的支持万级qps,那么怎么承担上百万QPS呢,这时候就需要在传输层搭建服务LVS,这里能支持百万级别QPS
| 层级 | OSI模型 | 代表组件 | 核心职责 |
|---|---|---|---|
| 数据链路层 | L2 (链路层) | F5 (部分功能) | MAC地址转发、VLAN隔离 |
| 网络层 | L3 (网络层) | LVS、F5 (IP转发) | IP包路由、四层负载均衡(TCP) |
| 传输层 | L4 (传输层) | LVS、HAProxy | TCP/UDP连接分发 |
| 应用层 | L7 (应用层) | Nginx/Kong/Gateway | HTTP协议解析、动态路由 |
通过分层架构:
-
L4 负载层:用低成本解决海量连接分发(LVS/硬件)
-
L7 网关层:专注业务协议处理(Kong/Nginx)
-
业务层:无网络负担,专注计算
超高性能场景(10万+ QPS)
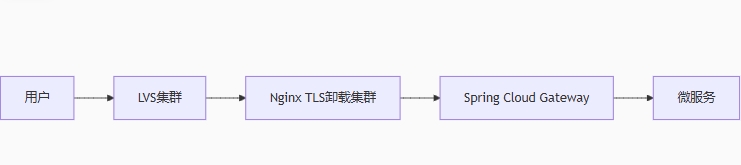
-
优势:
-
Nginx专做TLS解密(C语言极致性能)
-
Gateway专注业务路由(无需处理加密)
-
整体吞吐量提升2倍+
-
实例:加入现在目标6万QPS

中小规模场景(5万 QPS以下)

下面是百万QPS的真实案例
| 层级 | 组件 | 配置 | 数量 | 总处理能力 |
|---|---|---|---|---|
| 网络入口 | LVS + DPDK | 64核/128G/100G网卡 | 4台 | 400万 CPS |
| TLS卸载 | Nginx + 加速卡 | 32核/64G/SSL卡 | 20台 | 120万 TPS |
| 业务网关 | Rust网关(io_uring) | 32核/64G | 30台 | 450万 QPS |
| 微服务 | 商品服务 | 16核/32G | 50台 | 200万 QPS |
四、数据库高并发
核心挑战:数据库是“最难以解决的单点”,因其需保证 ACID 事务。
-
存储技术演进:
-
集中式存储(如 EMC):硬件级高可用,但成本极高(单 SAN 交换机超 40 万元)。
-
分布式存储:通过 x86 服务器集群构建存储池,依赖 PCIe 5.0 和 CXL 协议提升 IO 性能,降低成本。
-
-
数据库架构优化:
-
缓存策略:Redis 缓存热点数据,OceanBase 等分布式数据库采用“内存全缓存 + Redo Log 落盘”方案。
-
分布式方案:
-
TiDB(计算存储分离)、ClickHouse(列存储)解决海量数据分析瓶颈。
-
分库分表 + Paxos 协议保障数据一致性与高可用。
-
-
为了提高数据库读写能力,搭建读写分离1主多从,提高读能力,那么写能力呢,写是往主节点写入的,这时候就需要分布式架构了
第一代分布式架构 使用中间件 sharding-jdbc,但是可以说是属于应用层面不,不属于通用数据库范畴
第二代,出现了kv型数据库,nosql(redis)KV 数据库结构简单,性能优异,扩展性无敌,但是它只能作为核心数据库的高性能补充
第三个时代,newSQL,目前比较常见的 NewSQL 有 ClustrixDB、NuoDB、VoltDB,国内的 TiDB 和 OceanBase 也属于 NewSQL
第四个时代,云上数据库 例如阿里的PolarDB
缓存和队列
缓存(redis)消读的峰,而队列(rockemq,kafka)消写的峰
五、
持续更新。。。