YOLOv8 模块添加与修改讲解:从源码修改到配置文件配置
YOLOv8 作为当前主流的目标检测框架,其模块化设计可以灵活添加或替换网络组件(如注意力模块、特征金字塔模块等)。本文将讲解以下内容:
- 何时需要修改源码?何时需修改配置文件?
- 如何通过修改配置文件添加模块?以 AFPN 为例详解流程
- 源码修改与原始代码的部分指标差异对比
一、何时需要修改源码?何时需修改配置文件?
YOLOv8 的模块化设计允许通过 源码修改 和 配置文件调整 两种方式实现模型的添加和修改。
1. 需要修改源码的场景
(1) 新增自定义模块(如 AFPN、ASFF、DCN、注意力机制等)
-
为什么需要改源码?
YOLOv8 的模块(如Conv、C2f、AFPN)本质上是继承自nn.Module的类,需在代码中定义其前向传播逻辑。
新增模块必须定义类,否则无法被模型解析。 -
修改步骤:
-
定义模块类
在ultralytics/nn/modules/block.py或在这同级目录中新建.py文件中编写模块逻辑。
示例:定义ASFF_2模块class ASFF_2(nn.Module):def __init__(self, inter_dim, level, channels):super().__init__()self.upsample = Upsample(channels[1], channels[0]) # 上采样模块self.downsample = Downsample(channels[0], channels[1]) # 下采样模块self.weight_conv = nn.Conv2d(...) # 动态权重计算def forward(self, x):# 自适应空间融合逻辑return fused_feature2. 注册模块解析逻辑
首先在
tasks.py的顶部添加导入语句# ultralytics/nn/tasks.py# 导入自定义模块 from ultralytics.nn.modules.AFPN import ASFF_2, ASFF_3然后在
ultralytics/nn/tasks.py的parse_model函数中添加模块解析规则。
示例:为ASFF_2添加解析逻辑#-------------------------大胜新添加起始点---------------elif m is ASFF_2:if args[0] == 0:c2 = ch[f[0]]args = [ch[f[0]], args[0], [ch[x] for x in f]]else:c2 = ch[f[-1]]args = [ch[f[-1]], args[0], [ch[x] for x in f]]elif m is ASFF_3:if args[0] == 0:c2 = ch[f[0]]args = [ch[f[0]], args[0], [ch[x] for x in f]]elif args[0] == 1:c2 = ch[f[1]]args = [ch[f[1]], args[0], [ch[x] for x in f]]else:c2 = ch[f[-1]]args = [ch[f[-1]], args[0], [ch[x] for x in f]]# -------------------------大胜新添加结束点---------------
-
(2) 修改现有模块内部逻辑(如调整卷积参数、激活函数)
-
为什么需要改源码?
若需修改Conv模块的默认激活函数(如ReLU→SiLU)等等细致的改动,需直接修改模块源码。 -
修改步骤:
- 修改
ultralytics/nn/modules/Conv.py中的Conv类
- 修改
(3) 自定义数据预处理或后处理逻辑
- 为什么需要改源码?
若需添加特定数据增强(如Wavelet Transform)或修改 NMS 阈值逻辑,需修改data.py或postprocess.py。
2. 需要修改配置文件的场景
(1) 调整模型结构参数(如通道数、模块堆叠次数)
-
为什么只需改配置文件?
YOLOv8 的模型结构由 YAML 配置文件(如yolov8n.yaml)定义,通过修改backbone、neck、head中的模块参数即可调整结构。 -
修改步骤:
- 在
ultralytics/cfg/models/v8/yolov8n.yaml中修改模块参数:
示例:将C2f模块的通道数从 256 改为 512backbone:- [-1, 1, Conv, [64, 3, 2]] # 输入卷积层- [-1, 6, C2f, [512, True]] # 将通道数 256 → 512
- 在
(2) 添加已定义模块到模型结构中
-
为什么只需改配置文件?
若模块已在源码中定义并注册(如AFPN),可通过 YAML 文件直接引用其名称和参数。 -
修改步骤:
- 在配置文件中添加 Conv模块:
示例:多添加 Conv模块- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
二、AFPN网络理论精炼解析
AFPN(渐近特征金字塔网络)是一种改进的多尺度特征融合结构,旨在解决传统FPN(特征金字塔网络)中特征信息丢失或语义差异过大的问题。其核心思想是通过渐进式融合和自适应空间加权,实现跨层级(包括非相邻层)的特征交互与优化。
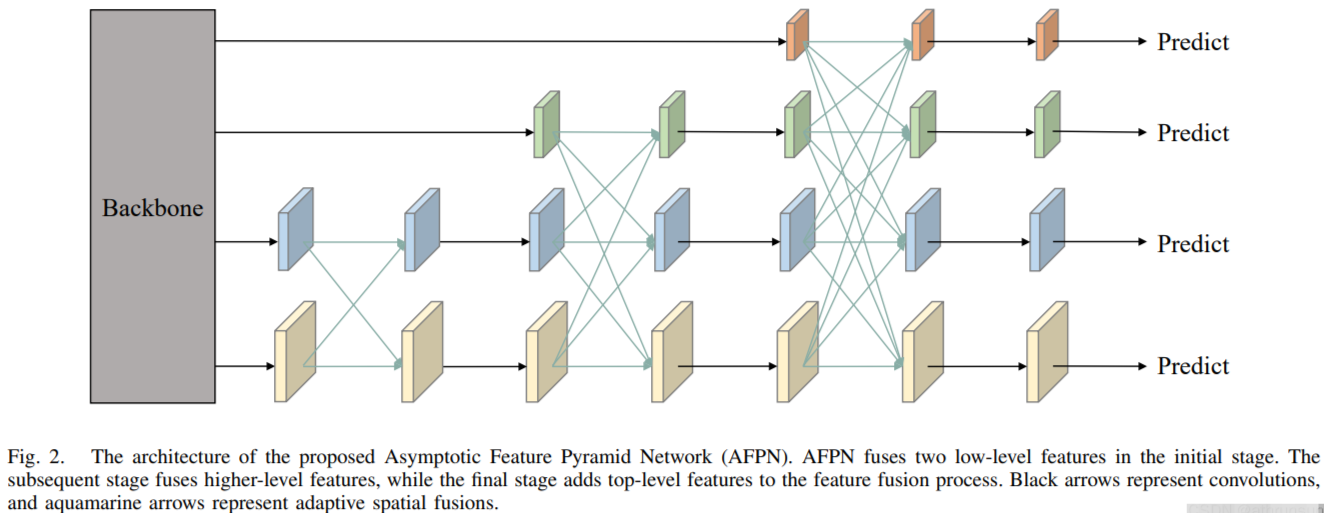
核心设计特点
-
渐进式特征融合
- 与传统FPN仅融合相邻层不同,AFPN通过逐步融合低级到高级的特征:
- 首先融合底层(如P2、P3)的高分辨率细节特征,
- 然后逐步引入更深层(如P4、P5)的语义特征,
- 最终形成多层次的渐进融合路径。
- 优势:减少非相邻层间的语义鸿沟,避免信息丢失,增强跨尺度特征的一致性。
- 与传统FPN仅融合相邻层不同,AFPN通过逐步融合低级到高级的特征:
-
自适应空间融合(ASFF)
- 在每层融合时,动态计算不同特征的空间权重(如通过可学习卷积核),根据任务需求分配不同区域的重要性。
- 作用:缓解多尺度特征间的矛盾信息(例如小目标与大目标的特征冲突),提升检测鲁棒性。
-
轻量化设计
- 仅使用常规卷积操作(无复杂模块如注意力或图网络),保持计算效率,适合实时检测场景(如YOLO系列)。
与YOLO结合的优势
- 小目标检测增强:通过底层特征的渐进融合,保留更多细节信息,提升小目标定位精度。
- 多尺度兼容性:自适应加权机制使模型更灵活应对不同尺度目标,减少误检率。
- 轻量高效:与YOLO的单阶段架构高度适配,在保持推理速度的同时提升精度。
AFPN的源码创建在 ultralytics/nn/modules目录下的AFPN.py中,代码如下:
import torch
import torch.nn as nn
from ultralytics.nn.modules.conv import Conv, Upsample, Downsample, C2fclass ASFF_2(nn.Module):def __init__(self, inter_dim=512, level=0, channel=[64, 256]):"""两层级自适应空间特征融合模块 (ASFF Level 2)Args:inter_dim: 中间特征通道数level: 当前处理层级 (0:低级特征主导, 1:高级特征主导)channel: 输入特征的通道列表 [低级特征通道, 高级特征通道]"""super(ASFF_2, self).__init__()self.inter_dim = inter_dimself.level = level# 压缩通道数(ASFF论文中通过1×1卷积压缩通道减少计算量)compress_c = 8 # 为每个输入特征生成空间权重(ASFF核心:动态权重学习)self.weight_level_1 = Conv(self.inter_dim, compress_c, 1, 1) # level0特征权重self.weight_level_2 = Conv(self.inter_dim, compress_c, 1, 1) # level1特征权重# 合并压缩后的权重通道并生成最终归一化权重(ASFF论文中使用Softmax归一化)self.weight_levels = nn.Conv2d(compress_c * 2, 2, kernel_size=1, stride=1, padding=0)# 特征融合后的卷积处理(3×3卷积保持特征表达能力)self.conv = Conv(self.inter_dim, self.inter_dim, 3, 1)# 多尺度对齐操作(根据ASFF论文要求,特征需调整到相同尺寸)self.upsample = Upsample(channel[1], channel[0]) # 上采样高级特征self.downsample = Downsample(channel[0], channel[1]) # 下采样低级特征# 后续特征增强模块(C2f残差块,增强融合后的特征表达)self.c2f = C2f(inter_dim, inter_dim)def forward(self, x):input1, input2 = x # input1:低级特征, input2:高级特征# 根据层级调整特征尺寸(ASFF论文中特征需统一尺寸)if self.level == 0: # 低级特征主导input2 = self.upsample(input2) # 将高级特征上采样到低级特征尺寸elif self.level == 1: # 高级特征主导input1 = self.downsample(input1) # 将低级特征下采样到高级特征尺寸# 生成各层级特征的权重(ASFF论文中的动态权重计算流程)level_1_weight_v = self.weight_level_1(input1) # 低级特征权重向量level_2_weight_v = self.weight_level_2(input2) # 高级特征权重向量# 权重通道拼接并生成最终归一化权重(Softmax保证权重和为1)levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v), 1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1) # 空间位置的权重分配# 自适应加权融合(ASFF论文中的核心公式:F_out = Σ(α_i * F_i))fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \input2 * levels_weight[:, 1:2, :, :]# 后处理增强特征表达out = self.conv(fused_out_reduced)return self.c2f(out) # 通过残差结构进一步优化特征class ASFF_3(nn.Module):def __init__(self, inter_dim=512, level=0, channel=[64, 128, 256]):"""三层级自适应空间特征融合模块 (ASFF Level 3)Args:inter_dim: 中间特征通道数level: 当前处理层级 (0:底层主导, 1:中层主导, 2:顶层主导)channel: 输入特征的通道列表 [P3, P4, P5]"""super(ASFF_3, self).__init__()self.inter_dim = inter_dimcompress_c = 8 # 压缩通道数# 为每个输入特征生成空间权重(ASFF论文中独立卷积核)self.weight_level_1 = Conv(self.inter_dim, compress_c, 1, 1) # P3权重self.weight_level_2 = Conv(self.inter_dim, compress_c, 1, 1) # P4权重self.weight_level_3 = Conv(self.inter_dim, compress_c, 1, 1) # P5权重# 合并权重通道并生成最终归一化权重self.weight_levels = nn.Conv2d(compress_c * 3, 3, kernel_size=1, stride=1, padding=0)# 特征融合后的卷积处理self.conv = Conv(self.inter_dim, self.inter_dim, 3, 1)self.level = level# 根据层级配置多尺度对齐操作(ASFF论文中的特征尺寸对齐策略)if self.level == 0: # 底层主导self.upsample4x = Upsample(channel[2], channel[0], scale_factor=4) # P5→P3self.upsample2x = Upsample(channel[1], channel[0], scale_factor=2) # P4→P3elif self.level == 1: # 中层主导self.upsample2x1 = Upsample(channel[2], channel[1], scale_factor=2) # P5→P4self.downsample2x1 = Downsample(channel[0], channel[1], scale_factor=2) # P3→P4elif self.level == 2: # 顶层主导self.downsample2x = Downsample(channel[1], channel[2], scale_factor=2) # P4→P5self.downsample4x = Downsample(channel[0], channel[2], scale_factor=4) # P3→P5# 后续特征增强模块self.c2f = C2f(inter_dim, inter_dim)def forward(self, x):input1, input2, input3 = x # P3, P4, P5特征# 根据层级调整特征尺寸(ASFF论文要求统一空间尺寸)if self.level == 0: # 底层主导input2 = self.upsample2x(input2) # P4上采样到P3尺寸input3 = self.upsample4x(input3) # P5上采样到P3尺寸elif self.level == 1: # 中层主导input3 = self.upsample2x1(input3) # P5上采样到P4尺寸input1 = self.downsample2x1(input1) # P3下采样到P4尺寸elif self.level == 2: # 顶层主导input1 = self.downsample4x(input1) # P3下采样到P5尺寸input2 = self.downsample2x(input2) # P4下采样到P5尺寸# 生成各层级特征的权重level_1_weight_v = self.weight_level_1(input1) # P3权重level_2_weight_v = self.weight_level_2(input2) # P4权重level_3_weight_v = self.weight_level_3(input3) # P5权重# 权重通道拼接并生成最终归一化权重levels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v, level_3_weight_v), 1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1) # Softmax归一化# 自适应加权融合(ASFF论文公式实现)fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \input2 * levels_weight[:, 1:2, :, :] + \input3 * levels_weight[:, 2:, :, :]# 后处理增强特征表达out = self.conv(fused_out_reduced)return self.c2f(out) # 通过残差结构进一步优化特征# 测试代码示例
if __name__ == '__main__':# 测试ASFF_2模块input_0 = torch.randn(1, 256, 40, 40) # P4特征 (batch, channels, height, width)input_1 = torch.randn(1, 512, 20, 20) # P5特征input = [input_0, input_1]model1 = ASFF_2(512, level=1, channel=[256, 512]) # 高级特征主导output = model1(input)print("ASFF_2 Output Shape:", output.shape) # 应输出与输入特征通道数匹配的张量# 测试ASFF_3模块input_0 = torch.randn(1, 256, 80, 80) # P3特征input_1 = torch.randn(1, 512, 40, 40) # P4特征input_2 = torch.randn(1, 1024, 20, 20) # P5特征input = [input_0, input_1, input_2]model2 = ASFF_3(256, level=0, channel=[256, 512, 1024]) # 底层主导output = model2(input)print("ASFF_3 Output Shape:", output.shape) # 应输出与输入特征通道数匹配的张量本文重点不在于探讨AFPN的网络结构,不对代码作过多赘述。
三、源码修改与原始代码的部分指标差异对比
首先在ultralytics/nn/tasks.py的顶部添加导入语句
# 导入自定义模块
from ultralytics.nn.modules.AFPN import ASFF_2, ASFF_3 然后在配置文件中修改文件,只有head部分和原始的YOLOv8有不同
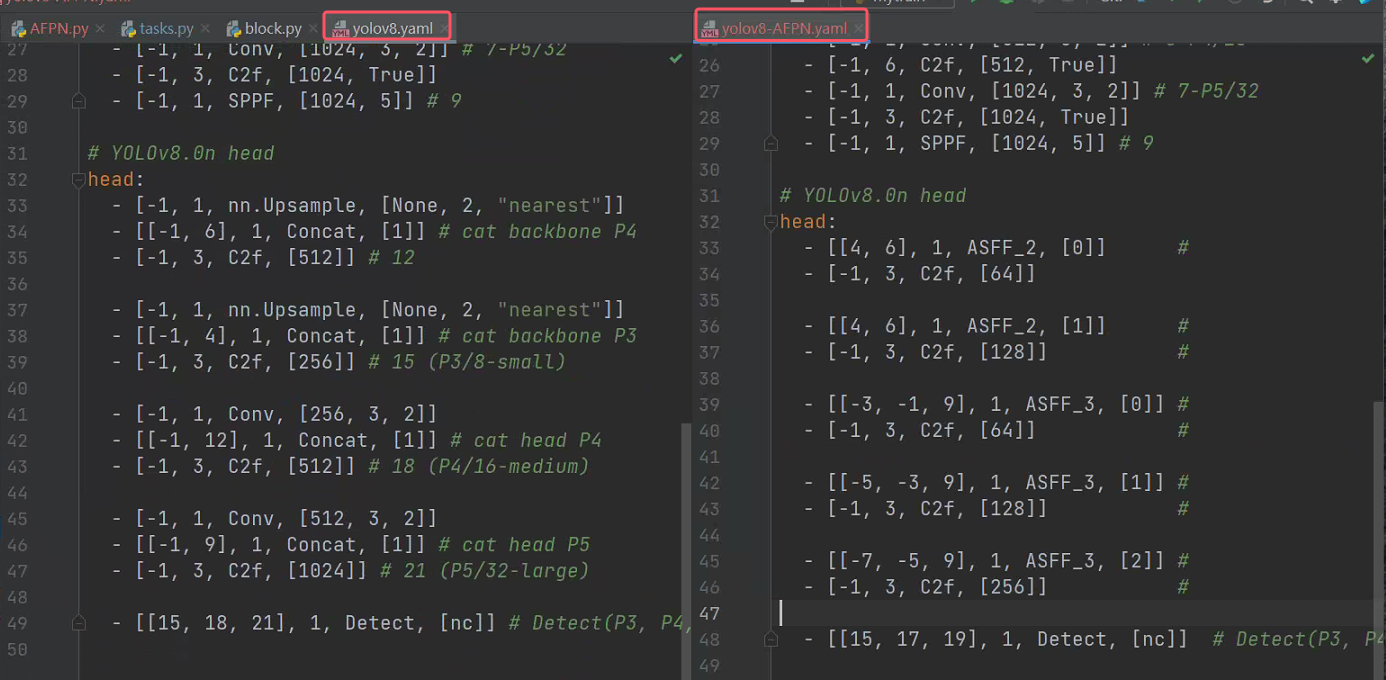
之后在 ultralytics/nn/tasks.py 的 parse_model 函数中添加模块解析规则。
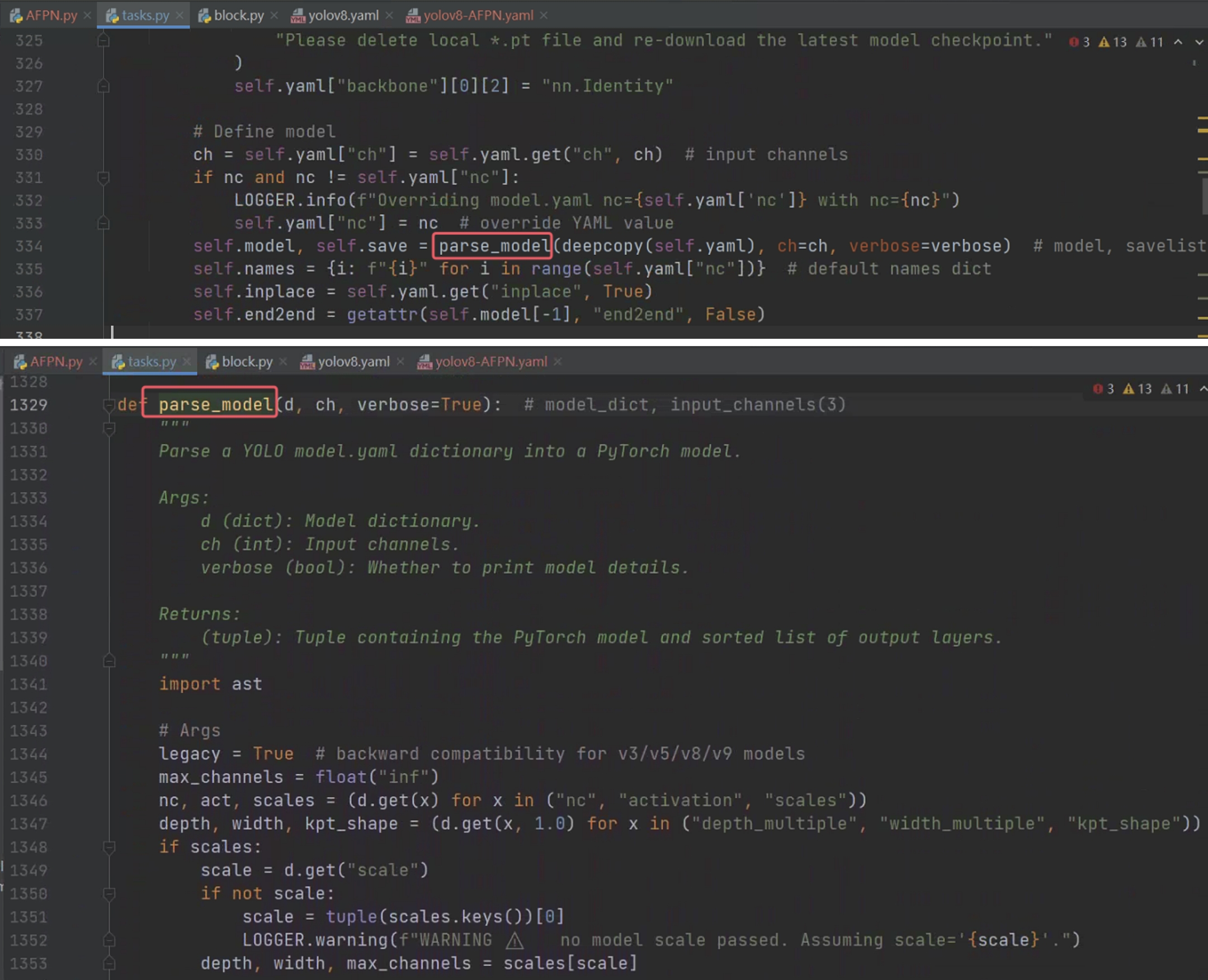
其中parse_model传入的参数解释如下:
d:模型配置字典,定义了网络结构、超参数和模块参数。ch:输入通道数列表,动态记录每一层的输出通道数,用于通道匹配和缩放。
添加代码的位置如下:
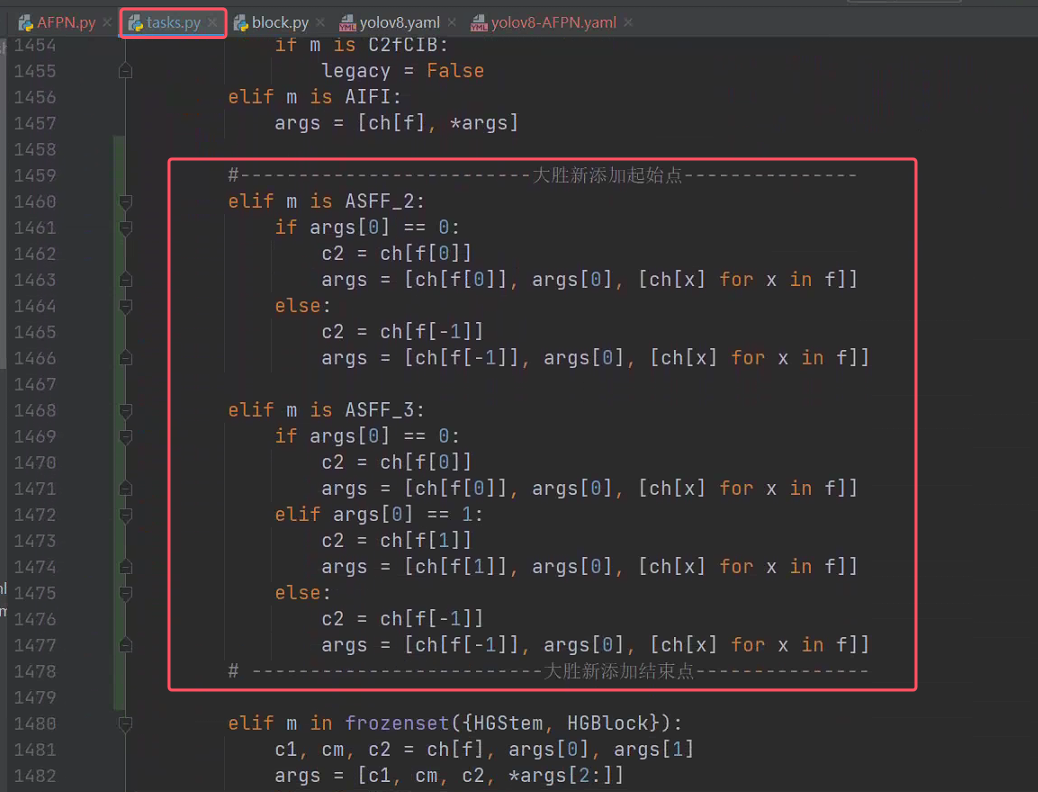
添加的代码做了注释
elif m is ASFF_2:# 处理ASFF_2模块的参数解析# args[0]对应ASFF_2构造函数中的level参数(0或1)# f是来自配置文件的from字段(如[-1, -2]表示输入来自前两层的输出)if args[0] == 0:# 当level=0(低级特征主导)时:# 输出通道c2 = 第一个输入特征的通道数(ch[f[0]])# 例如:若输入来自P3和P4,此时取P3的通道数c2 = ch[f[0]]# 参数重组:[低级特征通道, level=0, [所有输入层的通道列表]]# 例如:ASFF_2(ch[f[0]], level=0, channel=[ch[f[0]], ch[f[1]]])args = [ch[f[0]], args[0], [ch[x] for x in f]]else:# 当level=1(高级特征主导)时:# 输出通道c2 = 最后一个输入特征的通道数(ch[f[-1]])# 例如:若输入来自P3和P4,此时取P4的通道数c2 = ch[f[-1]]# 参数重组:[高级特征通道, level=1, [所有输入层的通道列表]]# 例如:ASFF_2(ch[f[-1]], level=1, channel=[ch[f[0]], ch[f[1]]])args = [ch[f[-1]], args[0], [ch[x] for x in f]]elif m is ASFF_3:# 处理ASFF_3模块的参数解析# args[0]对应ASFF_3构造函数中的level参数(0/1/2)if args[0] == 0:# 当level=0(底层主导)时:# 输出通道c2 = 第一个输入特征的通道数(ch[f[0]])# 例如:输入来自P3/P4/P5,此时取P3的通道数c2 = ch[f[0]]# 参数重组:[底层通道, level=0, [所有输入层的通道列表]]# 例如:ASFF_3(ch[f[0]], level=0, channel=[ch[f[0]], ch[f[1]], ch[f[2]]])args = [ch[f[0]], args[0], [ch[x] for x in f]]elif args[0] == 1:# 当level=1(中层主导)时:# 输出通道c2 = 中间输入特征的通道数(ch[f[1]])# 例如:输入来自P3/P4/P5,此时取P4的通道数c2 = ch[f[1]]# 参数重组:[中层通道, level=1, [所有输入层的通道列表]]# 例如:ASFF_3(ch[f[1]], level=1, channel=[ch[f[0]], ch[f[1]], ch[f[2]]])args = [ch[f[1]], args[0], [ch[x] for x in f]]else:# 当level=2(顶层主导)时:# 输出通道c2 = 最后一个输入特征的通道数(ch[f[-1]])# 例如:输入来自P3/P4/P5,此时取P5的通道数c2 = ch[f[-1]]# 参数重组:[顶层通道, level=2, [所有输入层的通道列表]]# 例如:ASFF_3(ch[f[-1]], level=2, channel=[ch[f[0]], ch[f[1]], ch[f[2]]])args = [ch[f[-1]], args[0], [ch[x] for x in f]]模型修改后的参数和推理效率的对比如下:
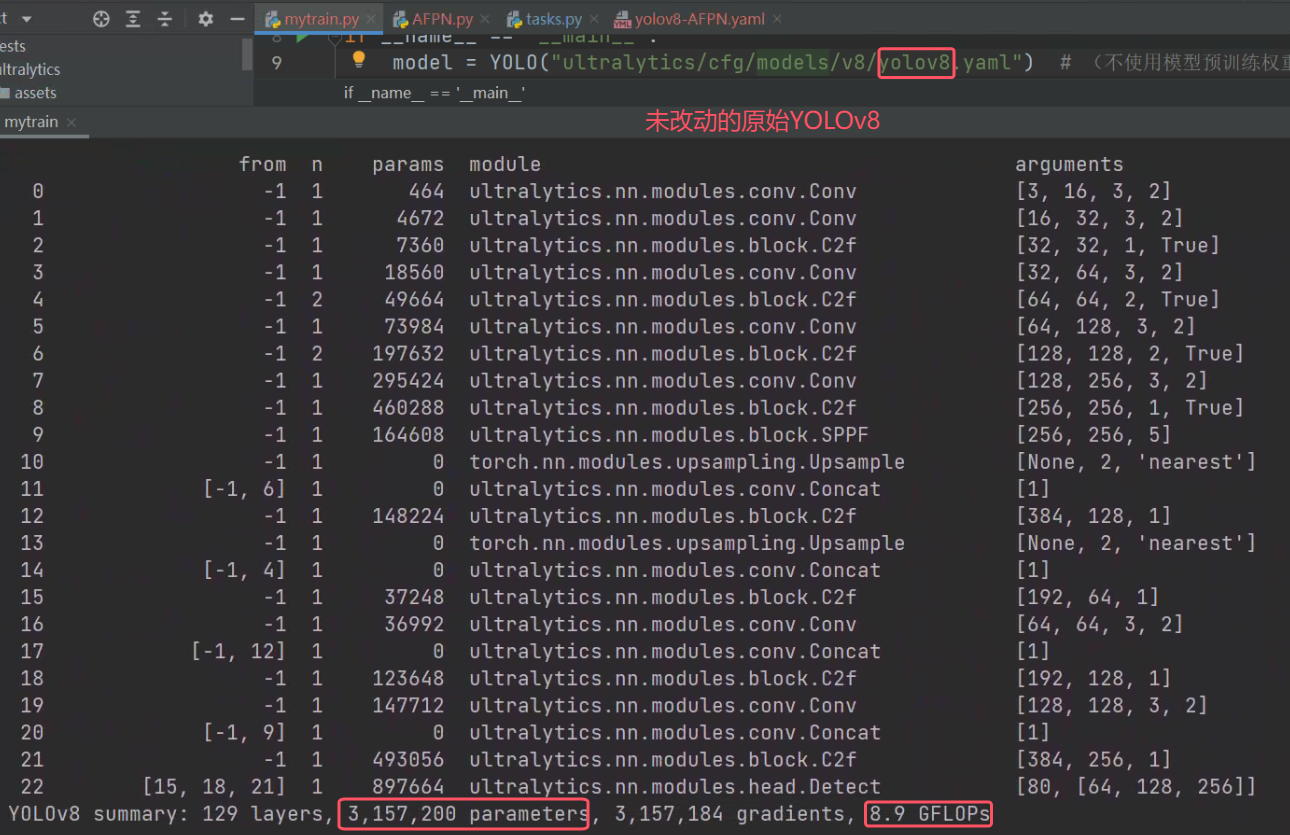
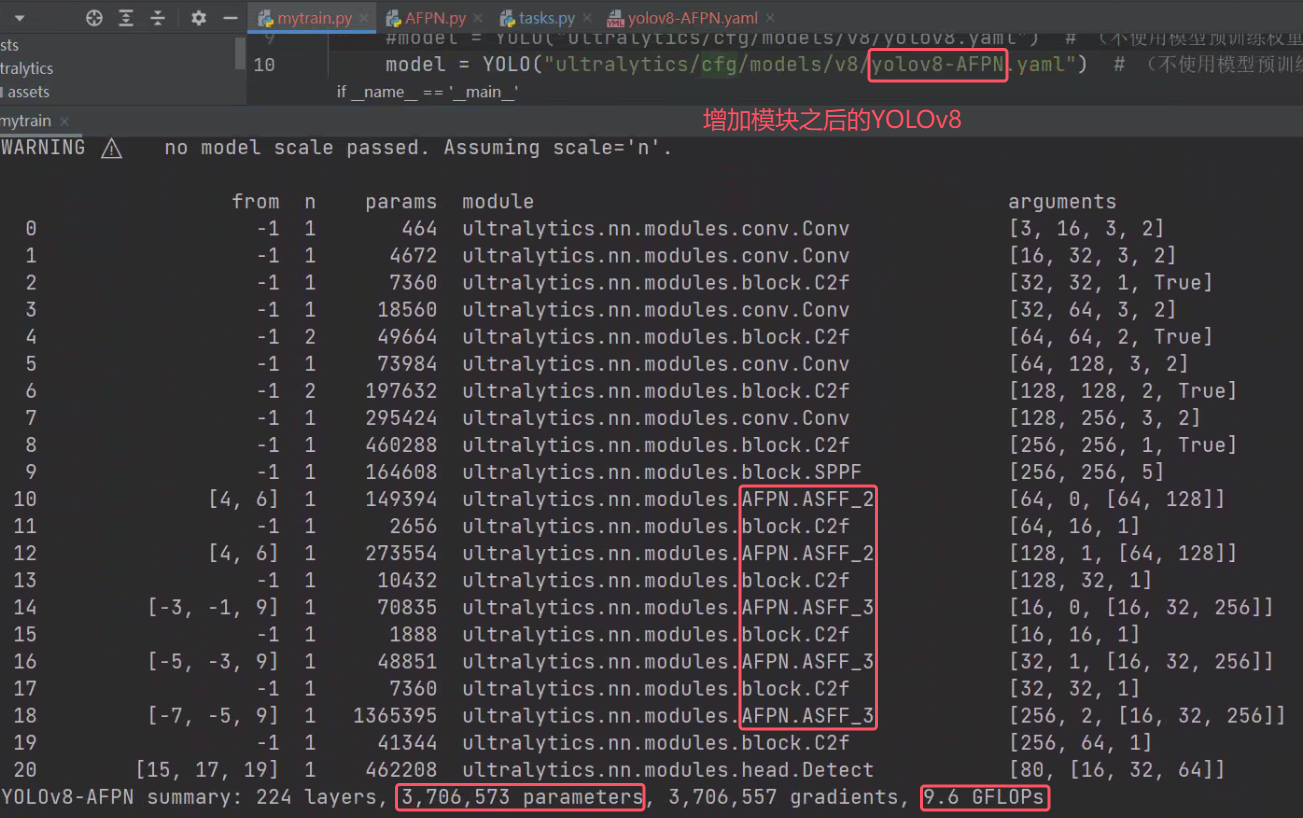
模型参数略微增加,推理速度有所下降。
最终的结果就不放了,本文主要讲解修改模型的步骤,到此流程打通就结束了。