从零实现一个高并发内存池 - 3
上一篇![]() https://blog.csdn.net/Small_entreprene/article/details/147932183?fromshare=blogdetail&sharetype=blogdetail&sharerId=147932183&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link
https://blog.csdn.net/Small_entreprene/article/details/147932183?fromshare=blogdetail&sharetype=blogdetail&sharerId=147932183&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link
高并发内存池 - central cache
中央缓存(Central Cache)结构
中央缓存采用哈希桶结构,其哈希桶的映射关系与线程本地缓存(Thread Cache)一致。不同之处在于,thread cache 是每一个线程独享的,central cache是被共享的,是需要加锁的!还有中央缓存的每个哈希桶位置挂载的是一个 SpanList 链表结构。每个映射桶下的 Span 中的大内存块被按照映射关系切割成一个个小内存块对象,并挂在 Span 的自由链表中。而thread cache 是挂着切好的内存块!(Span管理的是一个跨度的大块内存,管理一页为单位的大块内存,而且一个桶下的Span不只有一个,就像从thread cache上下来要,可能你要你个,他会一次性给你10个,因为后面就不需要频繁下来了,而且在上面取是更加高效的!)
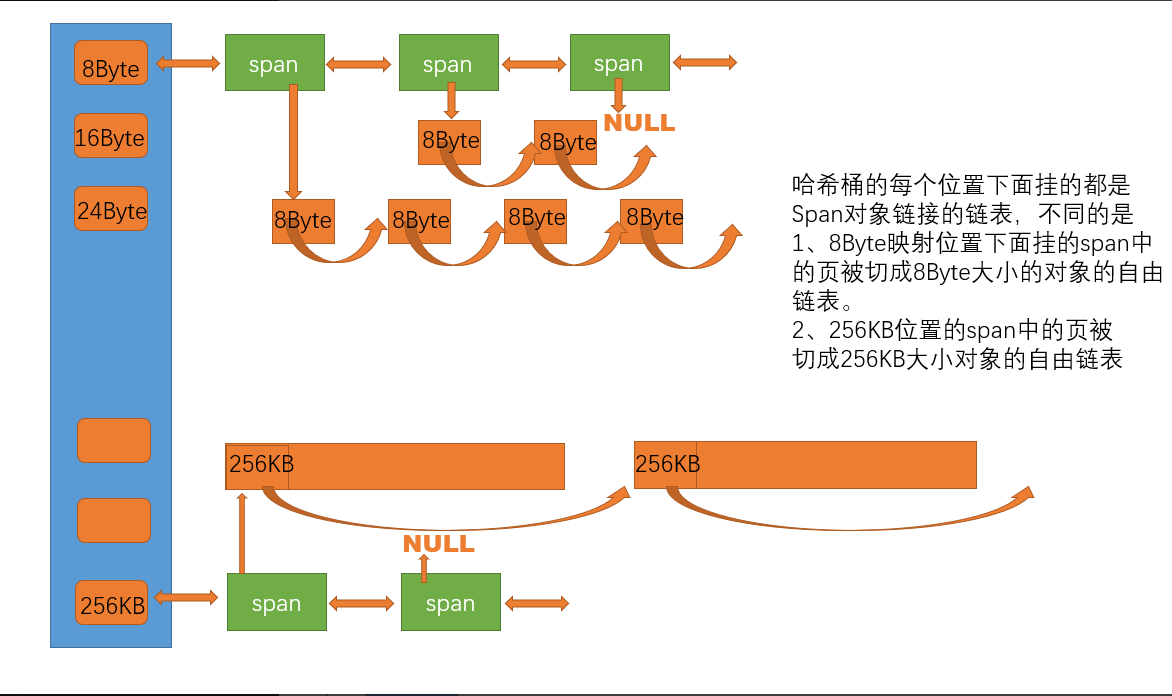
两者的哈希桶的映射规则是一样的,因为这样方便去对象!对于锁方面,central cache 使用的是桶锁,并不是一个锁将整个哈希表结构全部锁住了,而是每一个桶下有相应的一个锁!只有多西安城访问同一个桶的话才会导致锁竞争,所以整体来说,锁的竞争是比较低的!

我们来看看基本框架,假设有一页,一页是8KB,也就是当thread cache申请到下一层的时候,对应的桶下的所有Span中总共有1024个8byte,有时候只有线程1会一直往下central cache申请,这样,别的线程想要申请就比较不合适了,就会再往下申请,为了均衡调度,有相应解决方案会让对应thread cache返回内存块,不要老是占用,这是为了调度均衡;span结构中有一个_useCount,当其为0是就是代表该Span是还没有分配出去的,分配出去就++,回收回来就--,所以这是一个很巧妙的设计,当然了,如果Span的资源全部换回来了,就需要一样的操作还给下一层,page cache 进行合并,减少内存碎片,这也就需要双向链表来实现,因为换回来的是对应的某一个Span,我们下面代码实现会详细体现!
内存申请流程
线程本地缓存内存不足时:
-
当线程本地缓存(Thread Cache)中没有足够的内存时,会批量向中央缓存(Central Cache)申请内存对象。批量获取对象的数量采用类似网络 TCP 协议拥塞控制的慢开始算法。
-
中央缓存有一个哈希映射的
SpanList,每个SpanList中挂载多个Span。从Span中取出对象并分配给线程本地缓存,这个过程需要加锁。为了提高效率,这里使用的是一个桶锁(per-bucket lock)。
中央缓存内存不足时:
-
如果中央缓存映射的
SpanList中所有Span都没有可用内存,则需要向页面缓存(Page Cache)申请一个新的Span对象。 -
拿到新的
Span后,将Span管理的内存按照大小切分成多个小内存块,并作为自由链表链接在一起。然后从Span中取出对象分配给线程本地缓存。
使用计数管理:
-
每个
Span中的use_count记录分配了多少个对象出去。每分配一个对象给线程本地缓存,use_count就增加 1。
内存释放流程
线程本地缓存释放内存:
-
当线程本地缓存过长或者线程销毁时,会将内存释放回中央缓存。释放时,
use_count减少 1。 -
当
use_count减少到 0 时,表示所有对象都已经回到了Span中。此时,将Span释放回页面缓存,页面缓存会对前后相邻的空闲页面进行合并。
代码部分:
Common.h
#pragma once
#include<iostream>
#include<vector>
#include<ctime>
#include<windows.h>
#include<assert.h>
#include<thread>
#include<mutex>
#include<algorithm>//方便,不使用using namespace std;是因为防止污染
using std::cout;
using std::endl;static const size_t MAX_BYTES = 256 * 1024;
static const size_t NFREELIST = 208;//#ifdef _WIN64typedef unsigned long long PAGE_ID;
#elif _WIN32typedef size_t PAGE_ID;
#else//Linux
#endifstatic void*& NextObj(void* obj)
{return *(void**)obj;
}// 管理切分好的小对象的自由链表
class FreeList
{
public:void Push(void* obj){assert(obj);// 头插//*(void**)obj = _freeList;NextObj(obj) = _freeList;_freeList = obj;}//支持给一个范围,插入到自由链表---头插void PushRange(void* start, void* end){NextObj(end) = _freeList;_freeList = start;}void* Pop(){assert(_freeList);// 头删void* obj = _freeList;_freeList = NextObj(obj);return obj;}bool Empty(){return _freeList == nullptr;}size_t& MaxSize(){return _maxSize;}private:void* _freeList = nullptr;//这个要写,因为我们没有写构造size_t _maxSize = 1;//慢调节算法的要点之一
};// 计算对象大小的对其映射规则
class SizeClass
{
public:// 提供函数来计算给一个字节数,对应到正确的桶位置;// 规则如下:// 整体控制在最多10%左右的内碎片浪费!!!// ***************************************************************************************************// ***************************************************************************************************// [1,128] 8byte对齐 freelist[0,16) 这个没办法>^<// [128+1,1024] 16byte对齐 freelist[16,72) 15/(129+15)=0.10....// [1024+1,8*1024] 128byte对齐 freelist[72,128) 127/(1025+127)=0.11....// [8*1024+1,64*1024] 1024byte对齐 freelist[128,184) //......// [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208) //......// ***************************************************************************************************// ***************************************************************************************************//相当于RoundUp的子函数:给定当前size大小和对应规则的对齐数AlignNum,用于处理//static inline size_t _RoundUp(size_t size, size_t alignNum)//{// size_t alignSize;// if (size % alignNum != 0)// {// alignSize = (size / alignNum + 1) * alignNum;// }// else//等于0就不需要处理了,已经对齐了// {// alignSize = alignNum;// }//}//上面的是我们普通人玩出来的,下面我们来看看高手是怎么玩的!static inline size_t _RoundUp(size_t bytes, size_t alignNum){return ((bytes + alignNum - 1) & ~(alignNum - 1));}//你给我一个size,就需要算出对其以后是多少 --- 比如说:8->8 7->8static inline size_t RoundUp(size_t size){if (size <= 128){return _RoundUp(size, 8);}else if (size <= 1024){return _RoundUp(size, 16);}else if (size <= 8 * 1024){return _RoundUp(size, 128);}else if (size <= 64 * 1024){return _RoundUp(size, 1024);}else if (size <= 256 * 1024){return _RoundUp(size, 8 * 1024);}else{//说明大于256KB了,那么就有点问题了assert(false);return -1;}}//一样的,我们来自己写写看,待会换成别人的刚好的方式//size_t _Index(size_t bytes, size_t alignNum)//{// if (bytes % alignNum == 0)// {// return bytes / alignNum - 1;// }// else// {// return bytes / alignNum;// }//}//高手的想法:static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}// 计算映射的哪一个自由链表桶static inline size_t Index(size_t bytes){assert(bytes <= MAX_BYTES);// 每个区间有多少个链static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128) {return _Index(bytes, 3);}else if (bytes <= 1024) {return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024) {return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];}else if (bytes <= 64 * 1024) {return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];}else if (bytes <= 256 * 1024) {return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];}else {assert(false);}return -1;}// 一次thread cache从中心缓存获取多少个static size_t NumMoveSize(size_t size){assert(size > 0);// [2, 512],一次批量移动多少个对象的(慢启动)上限值// 小对象一次批量上限高// 小对象一次批量上限低int num = MAX_BYTES / size;if (num < 2)num = 2;if (num > 512)num = 512;return num;}};//管理多个连续页的大块内存跨度的结构
struct Span
{PAGE_ID _pageId = 0;//页号:大块内存的起始页的页号size_t _n = 0;//页数//双向链表Span* _next = nullptr;Span* _prev = nullptr;size_t _useCount = 0;//切好的小块内存,被分配给thread cache的计数void* _freeList = nullptr;//用于管理切好的小块内存的自由列表
};//带头双向循环链表
class SpanList
{
public:SpanList(){_head = new Span;_head->_next = _head;_head->_prev = _head;}void Insert(Span* pos, Span* newSpan){assert(pos);assert(newSpan);Span* prev = pos->_prev;//prev newSpan posprev->_next = newSpan;newSpan->_prev = prev;newSpan->_next = pos;pos->_prev = newSpan;}void Erase(Span* pos){assert(pos);assert(pos != _head);Span* prev = pos->_prev;Span* next = pos->_next;prev->_next = next;next->_prev = prev;}private:Span* _head;
public:std::mutex _mtx;//桶锁
};ThreadCache.cpp
#include"ThreadCache.h"
#include"CentralCache.h"//声明与实现分离void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{//慢开始反馈调节算法:整体控制达到双重目的://1.最开始不会一次向central cache一次批量要太多,因为要太多可能用不完//2.如果你不要size大小的需求,那么batchNum就会不断增长,知道上限(对象小上限高,对象大上限小)size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freeLists[index].MaxSize() == batchNum){_freeLists[index].MaxSize() += 1;//慢增长的过程!!!}void* start = nullptr;void* end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);//并没有说我们想要多少他这个Span里就有多少,我们要先得到一个实际的!!!assert(actualNum > 1);//你能给多少我就用多少吧,但是起码也是要有一个的吧!!!if (actualNum == 1){assert(start == end);return start;}else{_freeLists[index].PushRange(NextObj(start), end);return start;}
}void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);//并不是所有要求申请的字节数都有完全对应的一个桶位,是1字节,7字节都是放在对应的8字节桶中,那么我们就需要实现一个对应的对其映射的规则:我们在Common.h中实现size_t alignSize = SizeClass::RoundUp(size);//对齐数size_t index = SizeClass::Index(alignSize);//计算出了对齐数,那么又是对应的哪一个桶呢?//通过TLS,每个线程无锁的获取自己专属的ThreadCache对象if (!_freeLists[index].Empty()){return _freeLists->Pop();}else//这个桶下面的自由链表为空,为空只能向下一层去要了{return FetchFromCentralCache(index, alignSize);}
}void ThreadCache::Deallocate(void* ptr, size_t size)//free只需要传入对应要free空间的指针就可以了,但是为了知道放入到对应的正确的桶位置,需要size参数来定位桶的位置
{assert(ptr);assert(size <= MAX_BYTES);//找出对应的自由链表的桶,插入进去size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);//太长了的话,需要还给CentralCache ,CentralCache 满足某些条件有会还给下一层PageCache//还回逻辑我们需要将所有的申请逻辑理清才好理解!!!
}CentralCache.h
#pragma once
#include "Common.h"// 单例模式
class CentralCache
{
public://小对象是由大对象切出来的,那么这个大对象又是多大呢?//CentralCache里面定义了一个管理大块内存对象的结构---Span//但是我们不设计到类内中,因为还涉及到一些其他的问题,我们实现过程中自然就会理解:因为不仅仅要给CentralCache使用,还要给下一层PageCache使用!!!//我们需要搞定桶锁--->我们只需要将锁定义在SpanList中就可以了!!!static CentralCache* GetInstance(){return &_sInst;}// 获取一个非空的span,因为要从中心缓存获取一定数量的对象给thread cache,我们需要找到一个非空的spanSpan* GetOneSpan(SpanList& list, size_t byte_size);// 从中心缓存获取一定数量的对象给thread cachesize_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);//拿batchNum个size大小的对象,前两个为输出型参数private:SpanList _spanLists[NFREELIST];//和thread cache一样的,208个桶!
private:CentralCache(){}CentralCache(const CentralCache&) = delete;static CentralCache _sInst;//单例模式:懒汉模式
};
centralCache.cpp
#include"CentralCache.h"CentralCache CentralCache::_sInst;//获取一个非空的span
Span* CentralCache::GetOneSpan(SpanList& list, size_t byte_size)
{//需要遍历我们的SpanList,如果有就给,没有就需要向下一层了//......return nullptr;
}//重中心缓存获取一定数量的对象给thread cache
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)//拿batchNum个size大小的对象,前两个为输出型参数
{size_t index = SizeClass::Index(size);//获取对应的哈希桶的位置//因为多个线程可能同时竞争同一把桶锁,我们需要加锁_spanLists[index]._mtx.lock();Span* span = GetOneSpan(_spanLists[index], size);assert(span);assert(span->_freeList);//从span中获取batchNum个对象//如果不够batchNum个,有多少取多少start = span->_freeList;end = start;size_t i = 0;size_t actualNum = 1;//注意!!!这个和我们的下面的end的走的逻辑要对应上,不可以取成0!(既然申请到了非空的Span,那么该Span下也就起码有一个对象)//这里我们需要注意我们真的可以申请这么多吗,这个非空的Span真的有这么多吗while (i < batchNum - 1 && NextObj(end) != nullptr){end = NextObj(end);++i;++actualNum;}span->_freeList = NextObj(end);NextObj(end) = nullptr;_spanLists[index]._mtx.unlock();//加锁就需要解锁,那么这时候也应该考虑死锁的问题了return actualNum;
}
一些文字部分是后续的实现的细节,我们后续代码会议以体现出来!还回逻辑我们需要将所有的申请逻辑理清才好理解!!!
更多精彩再下文哦!!!