CVPR2025 | Prompt-CAM: 让视觉 Transformer 可解释以进行细粒度分析
Prompt-CAM: Making Vision Transformers Interpretable for Fine-Grained Analysis
- 摘要-Abstract
- 引言-Introduction
- 方法-Approach
- 预备知识-Preliminaries
- Prompt-CAM: Prompt Class Attention Map
- 特征识别与定位-Trait Identification and Localization
- 变体与扩展-Variants and Extensions
- Prompt-CAM 适用于什么?-What is Prompt-CAM suited for?
- 实验-Experiments
- 结论-Conclusion

论文链接
GitHub链接
本文 “Prompt-CAM: Making Vision Transformers Interpretable for Fine-Grained Analysis” 提出 Prompt-CAM 方法,旨在使预训练的视觉 Transformer(ViT)可解释以用于细粒度分析。该方法通过学习类特定提示,利用预训练 ViT 的特征,实现细粒度图像分类、特征定位等功能。与其他方法相比,Prompt-CAM 具有简单易实现和训练的优势。在 13 个不同领域的数据集上的实验验证了其卓越的解释能力、广泛的适用性和可扩展性,能有效识别和定位特征,在生物和生态研究等领域具有应用潜力。
摘要-Abstract
We present a simple approach to make pre-trained Vision Transformers (ViTs) interpretable for fine-grained analysis, aiming to identify and localize the traits that distinguish visually similar categories, such as bird species. Pretrained ViTs, such as DINO, have demonstrated remarkable capabilities in extracting localized, discriminative features. However, saliency maps like Grad-CAM often fail to identify these traits, producing blurred, coarse heatmaps that highlight entire objects instead. We propose a novel approach, Prompt Class Attention Map (Prompt-CAM), to address this limitation. Prompt-CAM learns classspecific prompts for a pre-trained ViT and uses the corresponding outputs for classification. To correctly classify an image, the true-class prompt must attend to unique image patches not present in other classes’ images (i.e., traits). As a result, the true class’s multi-head attention maps reveal traits and their locations. Implementation-wise, Prompt-CAM is almost a “free lunch,” requiring only a modification to the prediction head of Visual Prompt Tuning (VPT). This makes Prompt-CAM easy to train and apply, in stark contrast to other interpretable methods that require designing specific models and training processes. Extensive empirical studies on a dozen datasets from various domains (e.g., birds, fishes, insects, fungi, flowers, food, and cars) validate the superior interpretation capability of Prompt-CAM.
我们提出了一种简单的方法,使预训练的视觉 Transformer(ViT)可用于细粒度分析,旨在识别和定位那些能够区分视觉上相似类别的特征,比如鸟类物种。像 DINO 这样的预训练 ViT 在提取局部化的、具有判别力的特征方面展现出了卓越的能力。然而,诸如 Grad-CAM 这样的显著性图往往无法识别这些特征,生成的是模糊、粗糙的热图,只能突出整个物体。我们提出了一种新颖的方法——提示类注意力图(Prompt-CAM),以解决这一局限性。Prompt-CAM 为预训练的 ViT 学习特定类别的提示,并利用相应的输出进行分类。为了正确地对图像进行分类,真实类别的提示必须关注其他类别图像中不存在的独特图像块(即特征)。因此,真实类别的多头注意力图能够揭示特征及其位置。在实现方面,Prompt-CAM 几乎是一种“免费的午餐”,只需要对视觉提示调整(VPT)的预测头进行修改。这使得 Prompt-CAM 易于训练和应用,与其他需要设计特定模型和训练过程的可解释方法形成鲜明对比。在来自不同领域(如鸟类、鱼类、昆虫、真菌、花卉、食物和汽车)的十几个数据集上进行的大量实证研究,验证了 Prompt-CAM 卓越的解释能力。
引言-Introduction
该部分主要阐述了研究背景、现有方法的不足、Prompt-CAM 的提出及优势,具体内容如下:
- 研究背景:预训练的视觉 Transformer(ViT)在视觉识别任务中取得显著进展,尤其是在细粒度对象识别方面。像 DINO 和 DINOv2 等模型能够提取局部化且具有丰富信息的特征,为利用预训练 ViT 发现区分相似类别的“特征”提供了可能。
- 现有方法的不足
- 显著性图方法的问题:常用的显著性图方法,如 CAM,在 ViT 上表现不佳。它通常会生成模糊、粗糙的热图,定位整个对象,而不是聚焦于区分相似对象(如鸟类)的细微特征。即便有针对 ViT 的改进变体,问题也仅得到轻微缓解。
- 注意力图的局限性:ViT 依赖自注意力机制,
[CLS]标记的注意力图虽能突出对象内部区域,但这些区域并非类特定的,常聚焦于不同类别对象的相同身体部位,无法准确区分不同类别。
- Prompt-CAM 的提出及优势
- 方法提出:受相关研究启发,通过为 ViT 提供可学习的“类特定” token 作为提示,这些 token 可通过自注意力机制关注图像 patch,有望突出特定类别的区域,即特征。
- 方法实现:该方法名为 Prompt Class Attention Map(Prompt-CAM),为预训练 ViT 添加可学习的类特定 token,通过最小化交叉熵损失使其具有类特异性,训练时仅优化这些 token 和共享评分向量,保持预训练 ViT 骨干网络冻结。
- 优势体现:Prompt-CAM 易于实现和训练,相比其他可解释方法,如 ProtoPNet、ProtoTree 和 INTR 等,具有明显优势。它只需对 Visual Prompt Tuning(VPT)的预测头进行少量修改,无需设计特定模型和复杂训练策略。
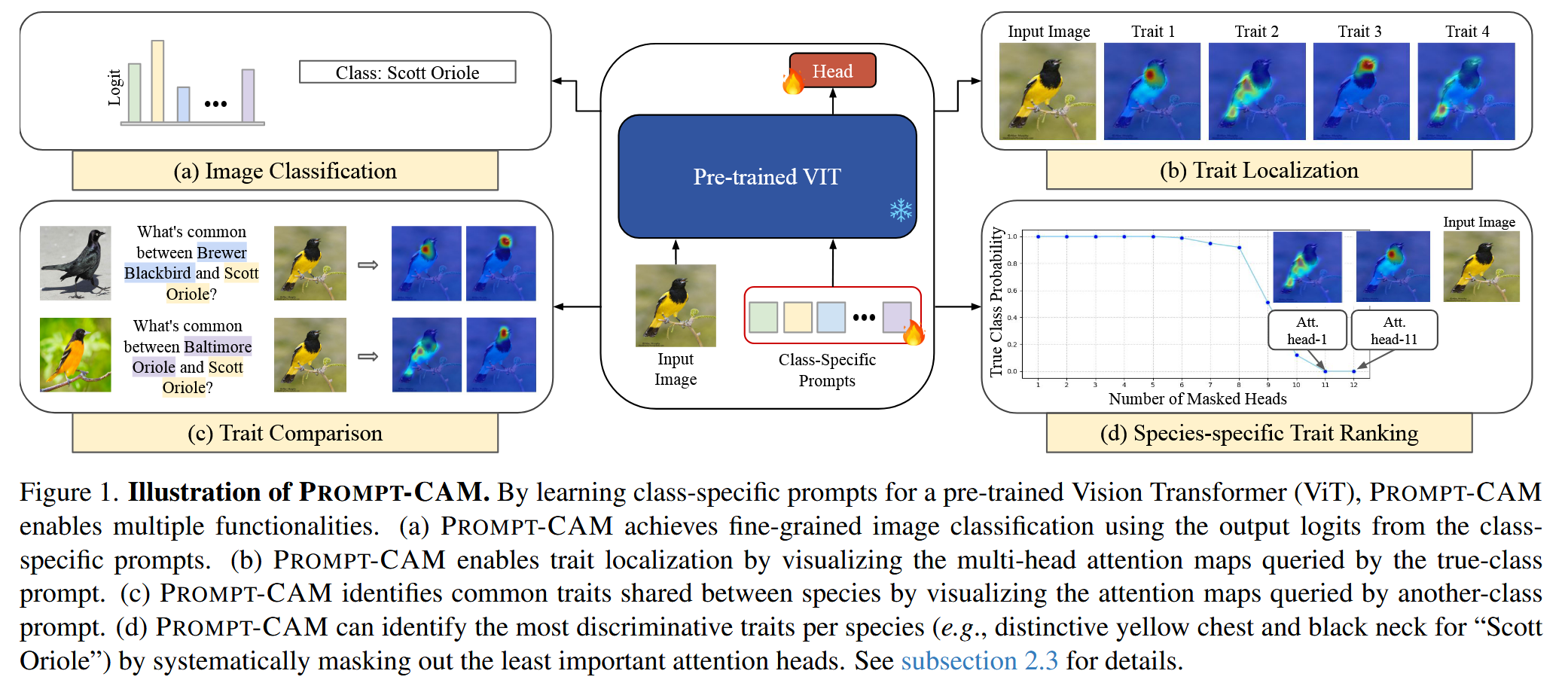
图1. Prompt-CAM 示意图。通过为预训练的视觉 Transformer(ViT)学习类特定提示,Prompt-CAM 实现了多种功能。(a) Prompt-CAM 利用类特定提示的输出对 logits 实现细粒度图像分类。(b) Prompt-CAM 通过可视化真实类提示查询的多头注意力图来实现特征定位。(c) Prompt-CAM 通过可视化其他类提示查询的注意力图来识别物种间共有的特征。(d) Prompt-CAM 可以通过系统地屏蔽最不重要的注意力头,识别每个物种最具判别力的特征(例如,“斯科特拟鹂”独特的黄色胸部和黑色颈部)。详情见2.3小节。

图2. Prompt-CAM 与视觉提示调整(VPT)的对比。(a) VPT在[CLS]标记的输出之上添加预测头,这是使用视觉 Transformer(ViT)进行分类的默认设计。(b) Prompt-CAM 在注入提示的输出之上添加预测头,使这些提示具有类别特异性,从而识别和定位特征。
- 实验验证与贡献
- 实验验证:在多个领域的十几个数据集上对 Prompt-CAM 进行验证,结果表明它能通过多头注意力机制识别类别特征并在图像中定位。
- 研究贡献:提出了 Prompt-CAM 这一可解释方法,利用预训练 ViT 进行细粒度分析;通过大量实验验证了该方法的解释质量、广泛适用性和可扩展性。
方法-Approach
预备知识-Preliminaries
该部分主要介绍了视觉 Transformer(ViT)的基本结构和输入处理方式,为后续理解 Prompt-CAM 方法奠定基础,具体内容如下:
- ViT 的基本结构:一个典型的 ViT 包含 N N N 个 Transformer 层,每个 Transformer 层由多头自注意力(MSA)块、多层感知机(MLP)块,以及层归一化和残差连接等操作组成。
- 输入处理:输入图像 I I I 会先被划分为 M M M 个固定大小的 patch。每个 patch 会被投影到 D D D 维特征空间,并添加位置编码,用 e 0 j e_{0}^{j} e0j 表示,其中 1 ≤ j ≤ M 1 \leq j \leq M 1≤j≤M ,所有 patch 的特征按列拼接表示为 E 0 = [ e 0 1 , ⋯ , e 0 M ] ∈ R D × M E_{0}=[e_{0}^{1}, \cdots, e_{0}^{M}] \in \mathbb{R}^{D ×M} E0=[e01,⋯,e0M]∈RD×M。
- ViT 的前向传播公式:
[CLS]是一个可学习的向量 x 0 ∈ R D x_{0} \in \mathbb{R}^{D} x0∈RD ,ViT 的前向传播可以表示为: [ E i , x i ] = L i ( [ E i − 1 , x i − 1 ] ) , i = 1 , ⋯ , N \left[E_{i}, x_{i}\right]=L_{i}\left(\left[E_{i - 1}, x_{i - 1}\right]\right), i = 1, \cdots, N [Ei,xi]=Li([Ei−1,xi−1]),i=1,⋯,N,其中 L i L_{i} Li 表示第 i i i 个 Transformer 层。最终的 x N x_{N} xN 通常用于表示整个图像,并被输入到预测头进行分类。
Prompt-CAM: Prompt Class Attention Map
该部分主要介绍了 Prompt Class Attention Map(Prompt-CAM)的具体实现方式,包括两种变体:Prompt-CAM-Shallow 和 Prompt-CAM-Deep,具体内容如下:
- Prompt-CAM-Shallow:给定预训练的 ViT 和有 c c c 个类别的下游分类数据集,引入一组 c c c 个可学习的 D D D 维向量作为提示。这些类特定提示被注入到第一个 Transformer 层 L 1 L_{1} L1,用 p c ∈ R D p^{c} \in \mathbb{R}^{D} pc∈RD 表示每个提示( 1 ≤ c ≤ C 1 ≤ c ≤ C 1≤c≤C),其按列拼接为 P = [ p 1 , ⋯ , p C ] ∈ R D × C P=[p^{1}, \cdots, p^{C}] \in \mathbb{R}^{D ×C} P=[p1,⋯,pC]∈RD×C。
则添加提示后的 ViT 前向传播公式为 [ Z 1 , E 1 , x 1 ] = L 1 ( [ P , E 0 , x 0 ] ) \left[Z_{1}, E_{1}, x_{1}\right]=L_{1}\left(\left[P, E_{0}, x_{0}\right]\right) [Z1,E1,x1]=L1([P,E0,x0]),后续层为 [ Z i , E i , x i ] = L i ( [ Z i − 1 , E i − 1 , x i − 1 ] ) , i = 2 , ⋯ , N \left[Z_{i}, E_{i}, x_{i}\right]=L_{i}\left(\left[Z_{i - 1}, E_{i - 1}, x_{i - 1}\right]\right), i = 2, \cdots, N [Zi,Ei,xi]=Li([Zi−1,Ei−1,xi−1]),i=2,⋯,N ,其中 Z i Z_{i} Zi 代表 P P P 对应的特征。为使 P P P 具有类特异性,在 ViT 输出 Z N = [ z N 1 , ⋯ , z N C ] Z_{N}=[z_{N}^{1}, \cdots, z_{N}^{C}] ZN=[zN1,⋯,zNC] 的基础上使用交叉熵损失。对于 token 的训练样本 ( I , y ∈ { 1 , ⋯ , C } ) (I, y \in\{1, \cdots, C\}) (I,y∈{1,⋯,C}) ,通过 s [ c ] = w ⊤ z N c s[c]=w^{\top} z_{N}^{c} s[c]=w⊤zNc( 1 ≤ c ≤ C 1 \leq c \leq C 1≤c≤C , w ∈ R D w \in \mathbb{R}^{D} w∈RD 为可学习向量 )计算每个类别的 logit,再通过最小化 − l o g ( e x p ( s [ y ] ) ∑ c e x p ( s [ c ] ) ) -log \left(\frac{exp (s[y])}{\sum_{c} exp (s[c])}\right) −log(∑cexp(s[c])exp(s[y])) 来更新 P P P。 - Prompt-CAM-Deep:Prompt-CAM-Shallow 存在潜在缺陷,早期层特征区分度不足且提示需承担多种功能。Prompt-CAM-Deep 借鉴 VPT-Deep 设计并解耦提示角色。VPT-Deep 给每个层的输入添加可学习提示,在 Prompt-CAM-Deep 中,深层提示的 ViT 公式为 [ Z i , E i , x i ] = L i ( [ P i − 1 , E i − 1 , x i − 1 ] ) , i = 1 , ⋯ , N \left[Z_{i}, E_{i}, x_{i}\right]=L_{i}\left(\left[P_{i - 1}, E_{i - 1}, x_{i - 1}\right]\right), i = 1, \cdots, N [Zi,Ei,xi]=Li([Pi−1,Ei−1,xi−1]),i=1,⋯,N.
这里 Z N Z_{N} ZN 用于分类,最小化交叉熵损失后,最后一层输入的提示 P N − 1 = [ p N − 1 1 , ⋯ , p N − 1 C ] P_{N - 1}=[p_{N - 1}^{1}, \cdots, p_{N - 1}^{C}] PN−1=[pN−11,⋯,pN−1C] 具有类特异性,而其他层输入的提示 P i = [ p i 1 , ⋯ , p i C ] P_{i}=[p_{i}^{1}, \cdots, p_{i}^{C}] Pi=[pi1,⋯,piC]( i = 0 , ⋯ , N − 2 i = 0, \cdots, N - 2 i=0,⋯,N−2 )保持类无关性。这种方式学习到用于特征定位的类特异性提示和用于适应任务的类无关提示,且类特异性提示仅关注最后一层输入的 patch 特征 E N − 1 E_{N - 1} EN−1,解决了 Prompt-CAM-Shallow 的问题。后续内容主要围绕 Prompt-CAM-Deep 展开 。

图3. 提示类注意力图(Prompt-CAM)概述。对于一个有 N N N 层的预训练视觉Transformer(ViT)和一个有 c c c 个类别的下游任务,我们探索了两种变体:(a) Prompt-CAM-Deep:在最后一层的输入中插入 c c c 个可学习的 “类特定 ” token,并在其他 N − 1 N-1 N−1 层的每一层输入中插入 c c c 个可学习的 “类无关 ” token;(b) Prompt-CAM-Shallow:在第一层的输入中插入 c c c 个可学习的 “类特定 ” token。在训练过程中,只有提示和预测头被更新;整个 ViT 保持冻结状态。
特征识别与定位-Trait Identification and Localization
该部分主要介绍了 Prompt-CAM-Deep 在特征识别和定位方面的应用,包括预测标签、特征识别、确定最具判别力的特征以及分析错误分类原因,具体内容如下:
- 预测标签:在推理阶段,Prompt-CAM-Deep 给定图像 I I I,先提取 patch 嵌入 E 0 = [ e 0 1 , ⋯ , e 0 M ] E_{0}=[e_{0}^{1}, \cdots, e_{0}^{M}] E0=[e01,⋯,e0M],然后依据相关公式得到 Z N Z_{N} ZN 和每个类别的分数 s [ c ] s[c] s[c] ,预测标签 y ^ \hat{y} y^ 通过公式 y ^ = a r g m a x c ∈ { 1 , ⋯ , C } s [ c ] \hat{y}=arg max _{c \in\{1, \cdots, C\}} s[c] y^=argmaxc∈{1,⋯,C}s[c] 确定。
- 特征识别:为确定类别 c c c 的特征,收集真实类别和预测类别均为 c c c 的图像,可视化由 p N − 1 c p_{N - 1}^{c} pN−1c 在 L N L_{N} LN 层查询得到的多头注意力图。在 L N L_{N} LN 层有 R R R 个注意力头,patch 特征 E N − 1 ∈ R D × M E_{N - 1} \in \mathbb{R}^{D ×M} EN−1∈RD×M 会被投影成 R R R 个键矩阵 K N − 1 r ∈ R D ′ × M K_{N - 1}^{r} \in \mathbb{R}^{D' ×M} KN−1r∈RD′×M( r = 1 , ⋯ , R r = 1, \cdots, R r=1,⋯,R ), p N − 1 c p_{N - 1}^{c} pN−1c 会被投影成 R R R 个查询向量 q N − 1 c , r ∈ R D r q_{N - 1}^{c, r} \in \mathbb{R}^{D^{r}} qN−1c,r∈RDr ,第 r r r 个注意力头的注意力图 α N − 1 c , r \alpha_{N - 1}^{c, r} αN−1c,r 通过公式 α N − 1 c , r = s o f t m a x ( ( K N − 1 r ) T q N − 1 c , r D ′ ) ∈ R M \alpha_{N - 1}^{c, r}=softmax(\frac{(K_{N - 1}^{r})^{T} q_{N - 1}^{c, r}}{D'}) \in \mathbb{R}^{M} αN−1c,r=softmax(D′(KN−1r)TqN−1c,r)∈RM计算。从第 r r r 个注意力头的角度看,权重 α N − 1 c , r [ j ] \alpha_{N - 1}^{c, r}[j] αN−1c,r[j] 表明第 j j j 个 patch 对类别 c c c 分类的重要性,从而定位图像中的特征。通过可视化每个注意力图,Prompt-CAM 最多可识别出 R R R 个不同特征。
- 确定最具判别力的特征:对于区分度明显的类别,如 “红翅黑鹂”,少数特征就能将其与其他类别区分开。为自动识别这些最具判别力的特征,采用贪心算法。假设类别 c c c 是真实类别且图像被正确分类,在每个贪心步骤中,对于每个未模糊的注意力头 r ′ r' r′ ,将 α N − 1 c , r ′ \alpha_{N - 1}^{c, r'} αN−1c,r′ 替换为 1 M 1 \frac{1}{M} 1 M11( 1 ∈ R M 1 \in \mathbb{R}^{M} 1∈RM 为全1向量) ,重新计算 s [ c ] s[c] s[c]。使模糊后 s [ c ] s[c] s[c] 最高的注意力头是最不重要的,逐步模糊直到图像被误分类,剩下的注意力图突出的特征就是对分类足够重要的特征。
- 分析错误分类原因:当 y ^ ≠ y \hat{y} ≠ y y^=y 时,可视化真实类别 y y y 和预测类别 y ^ \hat{y} y^ 的注意力图 α N − 1 y , r r = 1 R {\alpha_{N - 1}^{y, r}}_{r = 1}^{R} αN−1y,rr=1R 和 α N − 1 y ^ , r r = 1 R {\alpha_{N - 1}^{\hat{y}, r}}_{r = 1}^{R} αN−1y^,rr=1R,可分析分类器做出错误预测的原因。例如,可能是类别 y y y 的某些特征在图像 I I I 中不可见或不清晰,或者图像 I I I 中的对象由于光照等条件呈现出类别 y ^ \hat{y} y^ 的视觉特征。
变体与扩展-Variants and Extensions
该部分主要介绍了 Prompt-CAM 的设计变体和应用扩展,具体内容如下:
- 其他 Prompt-CAM 设计:除了在第一层(Prompt-CAM-Shallow)或最后一层(Prompt-CAM-Deep)注入类特定提示,还探索了两者的插值方式。在第 i i i 层引入类似 Prompt-CAM-Shallow 的类特定提示,并在第 1 1 1 到 i − 1 i - 1 i−1 层引入类似 Prompt-CAM-Deep 的类无关提示,相关比较在补充材料中给出。
- Prompt-CAM 用于发现分类学关键特征:在生物学等包含众多细粒度类别的领域,研究人员常构建层次决策树辅助分类,如分类学。分类学中每个中间“树节点”的作用是将一类子集划分为多个组,每个组具有特定的特征(即分类学关键特征)。Prompt-CAM 的简单性使其可高效训练多组提示,用于每个中间树节点,进而有可能重新发现分类学关键特征。在训练前,只需将同一组的类别重新标记为单个标签。预期在从根节点到叶节点的路径上,每个中间树节点能在叶节点的同一图像上关注不同的组级特征。文中给出了初步结果展示其潜力。
Prompt-CAM 适用于什么?-What is Prompt-CAM suited for?
该部分主要探讨了 Prompt-CAM 的适用场景,通过与传统分类器对比,说明了它更适合细粒度分析的原因,具体内容如下:
- Prompt-CAM 的设计目的:Prompt-CAM 专注于细粒度分析,旨在识别和定位有助于区分不同类别的特征,但这并不意味着它在细粒度分类准确性上表现卓越。因为现代神经网络参数众多,若模型训练主要追求准确性而无约束,会发现数据中的“捷径”,这些“捷径”虽有助于分类,但不利于分析。
- 与传统分类器的对比
- 传统分类器的问题:传统分类器在 ViT 的基础上使用全连接层进行预测,以一个简化的单头注意力 Transformer 层为例,其预测公式为 y ^ = a r g m a x c w c ⊤ ( ∑ j α ∗ [ j ] × v j ) \hat{y} = arg max _{c} w_{c}^{\top}\left(\sum_{j} \alpha^{*}[j] × v^{j}\right) y^=argmaxcwc⊤(∑jα∗[j]×vj)。这种公式可能存在“迂回”情况,即模型可以在不依赖有意义的注意力权重的情况下正确分类图像,通过生成整体有区分性但不保留空间分辨率的特征,使 v j v^{j} vj 与 w y w_{y} wy 对齐,即便 α ∗ \alpha^{*} α∗ 的值无实际意义,只要满足 softmax 默认的和为1的条件,预测结果也不受影响 。
- Prompt-CAM 的优势:Prompt-CAM 的预测公式为 y ^ = a r g m a x c w ⊤ ( ∑ j α c [ j ] × v j ) \hat{y} = arg max _{c} w^{\top}\left(\sum_{j} \alpha^{c}[j] × v^{j}\right) y^=argmaxcw⊤(∑jαc[j]×vj),其中 w w w 是共享二进制分类器。这一公式从根本上改变了模型行为,使模型难以在 v j v^{j} vj 的通道中存储类别的区分信息,因为没有 w c w_{c} wc 与之对齐。而且模型不能再生成无空间分辨率的整体特征,否则无法区分不同类别,因为所有类别的分数 s [ c ] s[c] s[c] 会完全相同。
- Prompt-CAM 的能力要求:为最小化交叉熵误差,使用 Prompt-CAM 的模型必须具备两种能力:一是生成突出图像判别性 patch(如翅膀上的红色斑点)的局部化特征 v j v^{j} vj;二是生成不同类别的独特注意力权重 α c \alpha^{c} αc,每个权重聚焦于该类中常见的特征。这些特性正是细粒度分析所需要的。Prompt-CAM 通过注入类无关提示,从预训练 ViT 的 patch 特征中提取局部化、特定于特征的信息,避免 patch 特征编码类别的整体区分信息。
实验-Experiments
该部分主要介绍了针对 Prompt-CAM 所开展的实验,涵盖实验设置、结果以及进一步的分析讨论,以此验证该方法的性能和效果,具体内容如下:
- 实验设置
- 数据集:选用 13 个来自不同领域的细粒度图像分类数据集,包含以动物为基础的(像 CUB-200-2011、Birds-525 等)、以植物和真菌为基础的(例如 iNaturalist-2021-Fungi、Oxford Flowers 等)以及以物体为基础的(如 Stanford Cars、Food 101)数据集,对其进行数据处理和统计。
- 模型:采用 DINO、DINOv2 和 BioCLIP 这三种预训练的 ViT 骨干网络,且在应用 Prompt-CAM 时骨干网络保持完全冻结状态,实验主要以 DINO 为主。
- 基线方法:将 Prompt-CAM 与 Grad-CAM、Layer-CAM、Eigen-CAM 等可解释方法,以及 ProtoPFormer、TesNet、ProtoConcepts、INTR 等可解释模型进行对比。
- 实验结果
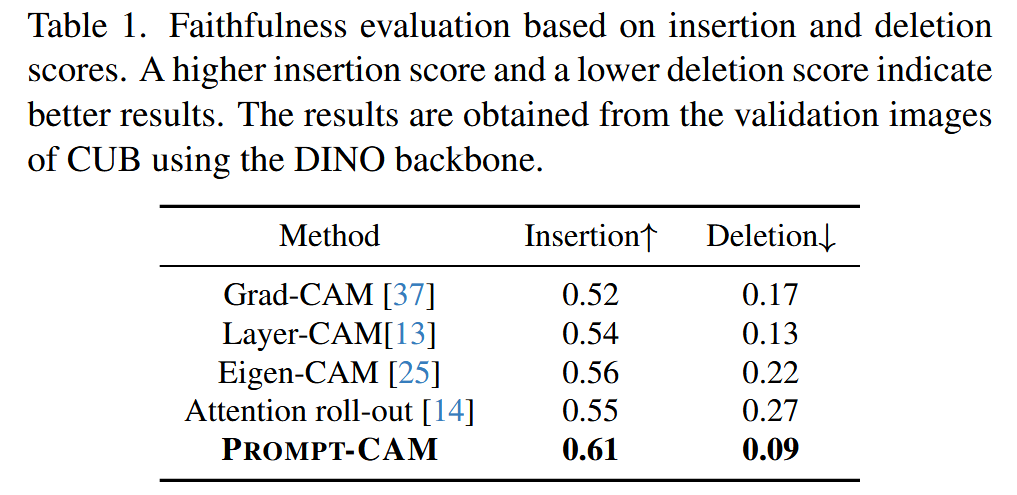
- Prompt-CAM 的忠实性:通过使用插入和删除指标进行评估,Prompt-CAM 的插入分数更高(达到0.61),删除分数更低(为0.09),这表明它更专注于图像的判别特征,解释性比标准的事后算法更强。
表1. 基于插入和删除分数的忠实度评估。插入分数越高且删除分数越低,则表明结果越好。这些结果是使用 DINO 骨干网络对 CUB 的验证图像进行评估得到的。
- 特征识别(人类评估):通过定量的人类研究评估特征识别质量,参与者对 Prompt-CAM 生成的特征识别率平均达到60.49%,显著优于 TesNet(39.14%)和ProtoConcepts(30.39%),突出了该方法在有效强调和传达相关特征方面的优越性。
- 分类精度比较:与线性探测相比,Prompt-CAM 的分类精度略有下降。原因在于它依据类特定的局部特征进行分类,当这些特征因遮挡、异常姿态或光照等因素不可见时,就会导致分类失败。例如,在一些图像中,“Red-breasted Grosbeak” 的红色胸部特征难以看见,Prompt-CAM 就会误分类,而线性探测利用全局信息能够正确分类。
表2. 使用 DINO 骨干网络的准确率(%)对比。
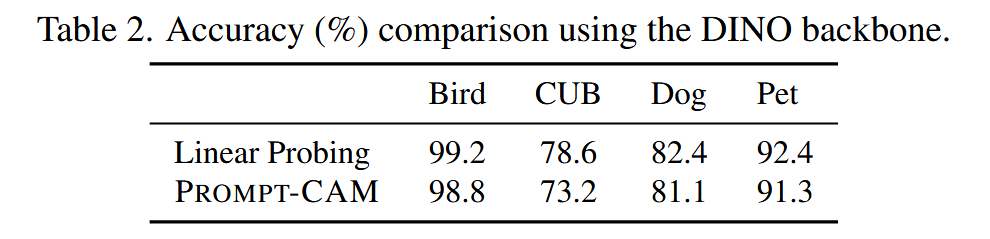

图5. 被 Prompt-CAM 误分类但被线性探测正确分类的图像。特定物种的特征,比如“玫胸白斑翅雀”的红色胸部,在被误分类的图像中几乎看不见,而线性探测利用身体形状、姿势和背景等全局特征做出正确预测。 - 与可解释模型的比较:定性分析显示,与其他可解释方法相比,Prompt-CAM 能够捕捉到更广泛、更精细的特征。例如,在对 “Lazuli Bunting” 的图像分析中,它能关注到更多独特的特征,而其他方法的关注点往往较为狭窄或重复。
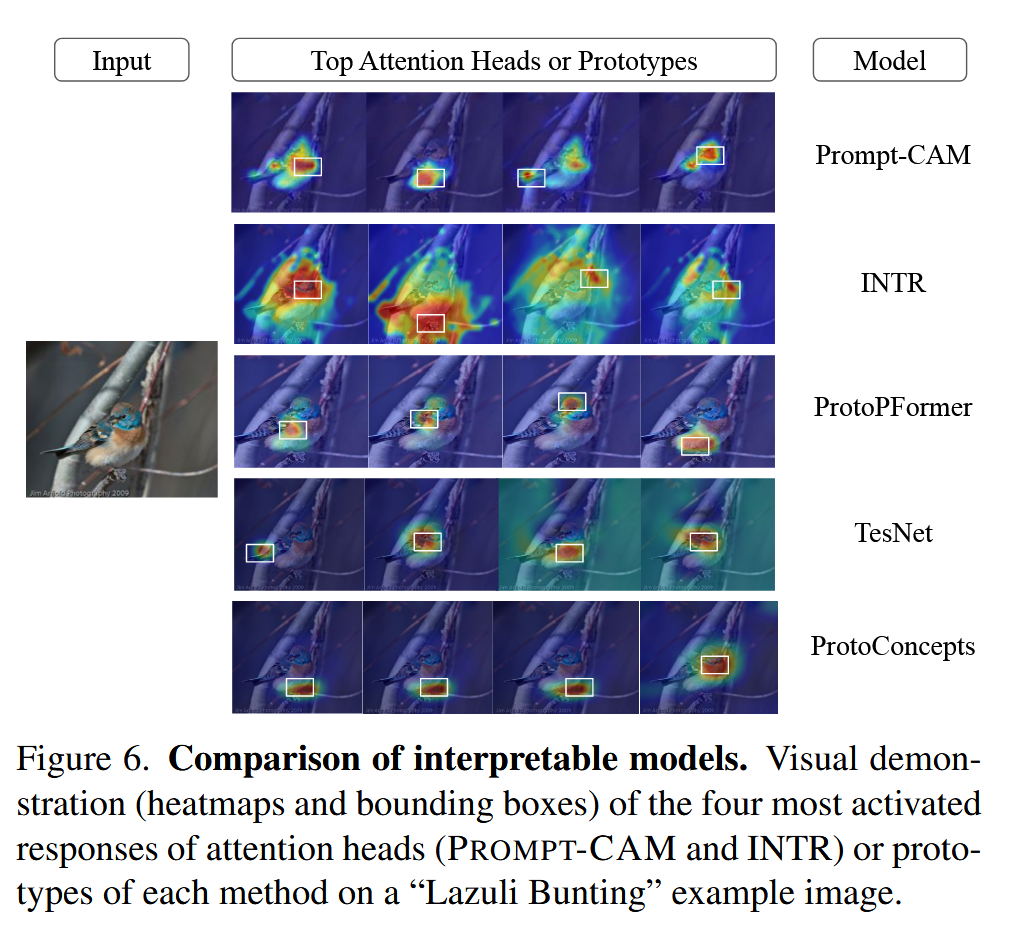
图6. 可解释模型的比较。以“蓝翅莺”的示例图像为例,展示了(Prompt-CAM 和 INTR)注意力头的四个最活跃响应或每种方法的原型的可视化演示(热图和边界框)。
- Prompt-CAM 的忠实性:通过使用插入和删除指标进行评估,Prompt-CAM 的插入分数更高(达到0.61),删除分数更低(为0.09),这表明它更专注于图像的判别特征,解释性比标准的事后算法更强。
- 进一步分析和讨论
- 不同骨干网络上的 Prompt-CAM:实验表明 Prompt-CAM 与不同的 ViT 骨干网络兼容。以“Scott Oriole”的图像为例,使用 DINO、DINOv2 和 BioCLIP 骨干网络时,Prompt-CAM 都能一致地识别出用于物种识别的关键特征。

图7. 不同骨干网络上的 Prompt-CAM。这里展示了 Prompt-CAM 在(a)DINO、(b)DINOv2和(c)BioCLIP骨干网络上的顶级注意力图。这三组注意力头都指向“斯科特拟鹂”这一物种一致的关键特征——黄色腹部、黑色头部和黑色胸部。 - 不同数据集上的Prompt-CAM:在不同领域的多个数据集上,Prompt-CAM 都能有效地捕捉到每个物种的重要特征,准确识别物种,展现出良好的泛化性和广泛的适用性。

图4. PROMPT-CAM 在不同数据集上的可视化结果。我们展示了每个正确分类的测试样本由真实类别触发的前四个注意力图(从左到右)。 - Prompt-CAM 对特征操作的识别和解释:通过反事实风格的分析,如对 “Red-winged Blackbird” 图像的处理,当去除其红色翅膀斑点后,模型不再将其预测为该物种,而是“Boat-tailed Grackle”,这展示了 Prompt-CAM 对特征差异的敏感性和在细粒度识别中的可解释性。
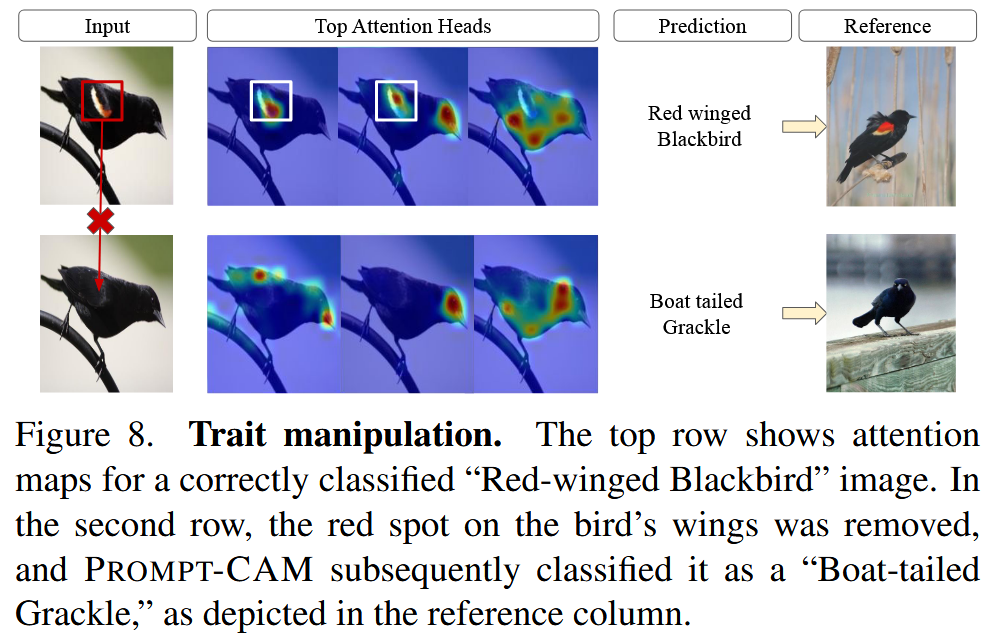
图8. 特征操控。顶行展示了一张被正确分类为“红翅黑鹂”的图像的注意力图。第二行中,鸟翅膀上的红色斑点被去除,Prompt-CAM 随后将其分类为“船尾拟八哥”,如参考列所示。 - Prompt-CAM 检测有意义特征的能力:Prompt-CAM 能够检测出生物学和分类学上有意义的特征。它可以识别同一物种图像中的一致特征,还能通过可视化不同类别的提示来发现物种间的共同特征。在基于层次框架训练时,它能从粗粒度到细粒度地关注不同层次的特征,有助于识别分类学关键特征。

图9. Prompt-CAM 能够检测出具有分类学意义的特征。以物种“克氏双锯鱼(Amophiprion Clarkii)”的图像为例,Prompt-CAM 会突出显示其腹鳍和双条纹,以便在物种层面将它与“黑背双锯鱼(Amophiprion Melanopus)”区分开来。在属的层面上,Prompt-CAM 会观察身体和尾巴的图案,从而将图像归类到“双锯鱼属(Amophiprion)”。再往上到科的层面,不同鱼类在外观上差异明显。Prompt-CAM 仅需观察尾巴和腹鳍,就能将图像归类到“雀鲷科(Pomacentridae)”。
- 不同骨干网络上的 Prompt-CAM:实验表明 Prompt-CAM 与不同的 ViT 骨干网络兼容。以“Scott Oriole”的图像为例,使用 DINO、DINOv2 和 BioCLIP 骨干网络时,Prompt-CAM 都能一致地识别出用于物种识别的关键特征。
结论-Conclusion
该部分总结了 Prompt-CAM 方法的核心要点、优势及研究意义,具体内容如下:
- 方法概述:提出Prompt Class Attention Map(Prompt-CAM),这是一种简单有效的可解释方法,借助预训练的视觉Transformer(ViT)来识别和定位用于细粒度分类的判别性特征。
- 方法优势:Prompt-CAM 易于实施和训练,仅需对视觉提示调整(VPT)的预测头进行修改,使用标准交叉熵损失和随机梯度下降(SGD)算法即可完成训练。
- 研究意义:大量实证研究充分验证了 Prompt-CAM 的强大性能,展示了其在将标准模型用于可解释性方面的潜力,为后续相关研究和应用提供了重要的参考和借鉴。