轻量级因果语言视觉模型简述:nanoVLM-222M
一、nanoVLM模型概述
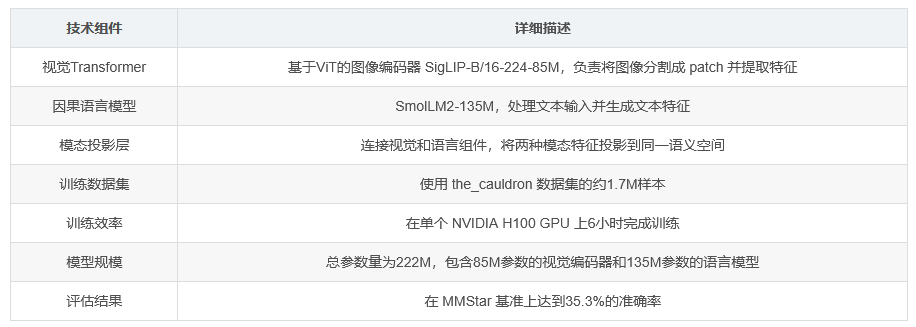
nanoVLM是一个极简且轻量级的视觉-语言模型(VLM),专为高效训练和实验而设计。该模型完全基于纯PyTorch构建,整个模型架构和训练逻辑仅占用约750行代码。它通过结合基于ViT的图像编码器(SigLIP-B/16-224-85M)和轻量级因果语言模型(SmolLM2-135M),形成了一个仅有222M参数的紧凑模型。在使用cauldron数据集的1.7M样本进行训练后,该模型在单个NVIDIA H100 GPU上仅需6小时训练即可达到MMStar准确率35.3%,使其成为低资源VLM研究的强大基准。
二、模型架构详解
nanoVLM的架构包含三个主要组成部分:
(一)视觉Transformer(SigLIP-B/16)
该组件作为图像编码器,基于Vision Transformer(ViT)架构。它将输入图像分割成固定大小的 patch,然后通过 transformer 编码器提取图像的特征表示。SigLIP-B/16 版本中的 “16” 表示图像被分割成16x16的 patch 大小,这使得模型能够在保持一定特征细节的同时,降低计算复杂度。
(二)因果语言模型(SmolLM2)
作为模型的语言处理部分,SmolLM2-135M 是一个轻量级的因果语言模型。它负责处理文本输入,通过自回归的方式生成文本特征,并与图像特征进行交互。这种因果语言模型架构能够有效捕捉文本中的顺序信息,为视觉-语言融合提供基础。
(三)模态投影层
模态投影层是连接视觉和语言组件的关键部分。它的作用是将图像特征和文本特征投影到同一语义空间,使得两种不同模态的特征能够进行有效的交互和融合。通过这种方式,模型能够理解图像和文本之间的关联,实现跨模态的理解和推理。
三、训练过程与实验结果
(一)训练数据
nanoVLM 在 the_cauldron 数据集上进行训练,该数据集提供了约1.7M个样本。这些样本包含了多样化的图像-文本对,为模型的训练提供了丰富的多模态信息。
(二)训练环境与效率
该模型在单个 NVIDIA H100 GPU 上进行训练,仅需6小时即可完成训练过程。这种高效的训练效率主要得益于模型的轻量化设计和优化的训练逻辑,使其能够在有限的计算资源下快速收敛。
(三)实验结果
在 MMStar 评估基准上,nanoVLM 取得了35.3%的准确率。这一结果证明了该模型在低资源环境下的有效性和竞争力,为后续的视觉-语言模型研究提供了一个有力的基准。
四、模型的应用场景与意义
nanoVLM 适合对计算资源有限的研究人员和开发者,它为探索视觉-语言模型的训练提供了一个低开销的实验平台。作为多模态架构研究的起点,研究人员可以在其基础上进行进一步的模型改进和架构创新,推动视觉-语言模型在更多场景下的应用和发展。
五、核心技术汇总