AI Engine Kernel and Graph Programming--知识分享3
使用AI引擎API的示例设计
FIR滤波器
设计分析
有限脉冲响应(FIR)滤波器由以下等式描述,其中x表示输入,C表示系数,y表示输出,并且N表示滤波器的长度。
![]()
以下是一个32抽头滤波器的示例。

每个输出需要32次乘法。如果将cint16作为数据类型和系数类型,则在内核中计算一个样本需要4个周期,因为每个AI Engine每个周期可以执行8个MAC操作。如果数据从一个流端口(32位)流传输,则一个数据可以产生一个输出(在处理过程中)。
因此,设计是计算限制的。您将看到如何将内核拆分为4个级联内核,以便每个周期处理一个样本。
标量黄金参考
AI引擎包含一个标量处理器,可用于实现标量数学运算、非线性函数和其他通用运算。有时候,拥有一个黄金标量参考版本的代码会很有帮助。但请注意,与矢量化版本相比,标量版本的代码在仿真和硬件中运行所需的时间要长得多。下面提供了32抽头滤波器标量版本的示例代码:
static cint16 eq_coef[32]={{1,2},{3,4},...};
//keep margin data between different invocations of the graphstatic cint16 delay_line[32];__attribute__((noinline)) void fir_32tap_scalar(input_stream<cint16> *sig_in,output_stream<cint16> * sig_out){
for(int i=0;i<SAMPLES;i++){cycle_num[0]=tile.cycles();//cycle counter of the AI Engine tilecint64 sum={0,0};//larger data to mimic accumulatorfor(int j=0;j<32;j++){//auto integer promotion to prevent overflowsum.real+=delay_line[j].real*eq_coef[j].real-delay_line[j].imag*eq_coef[j].imag;sum.imag+=delay_line[j].real*eq_coef[j].imag+delay_line[j].imag*eq_coef[j].real;
}sum=sum>>SHIFT;
//produce one sample per loop iterationwriteincr(sig_out,{(int16)sum.real,(int16)sum.imag});for(int j=0;j<32;j++){if(j==31){delay_line[j]=readincr(sig_in);}else{delay_line[j]=delay_line[j+1];}}}
}
void fir_32tap_scalar_init(){//initialize datafor (int i=0;i<32;i++){int tmp=get_ss(0);delay_line[i]=*(cint16*)&tmp;}
};注意:
·函数fir_32tap_scalar_init用作内核的初始化函数,它只会在graph.run()之后调用一次。
·标量处理器不支持舍入和饱和模式。它们可以通过标准的C操作来实现,比如shift。
·瓦片计数器用于分析代码的主循环。
从分析结果中可以看到,每个样本需要2803个周期。如果在AI Engine模拟期间启用选项--profile,则可以在葡萄属IDE中的Profile部分下查看信息。
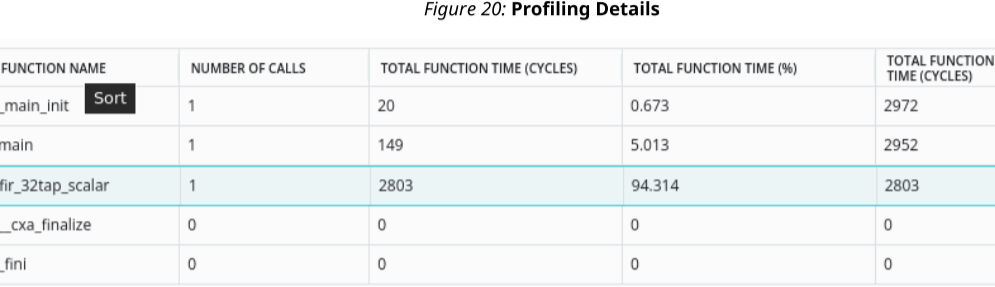
注意事项:当有不同的编译器选项、位置约束等时,分析的周期可能会有所不同。并且它可能会在版本与版本之间有所不同。但是这里介绍的设计分析和性能分析的概念无论如何都适用。
使用单个内核的矢量化版本
AI Engine自然支持多通道MAC操作。对于FIR应用的变体,可以使用在多通道乘法- sliding_穆尔中引入的aie::sliding_穆尔 * 类和函数组。
在本节中,您将选择Lanes=8和Points=8的aie::sliding_穆尔和aie::sliding_mac函数。数据步长和系数步长均为1,这是默认值。例如,acc = aie::sliding_mac<8,8>(acc,coe[1],0,buff,8);执行:
Lane 0: acc[0]=acc[0]+coe[1][0]*buff[8]+coe[1][1]*buff[9]+...+coe[1][7]*buff[15];
Lane 1: acc[1]=acc[1]+coe[1][0]*buff[9]+coe[1][1]*buff[10]+...+coe[1][7]*buff[16];
...
Lane 7: acc[7]=acc[7]+coe[1][0]*buff[15]+coe[1][1]*buff[16]+...+coe[1][7]*buff[22];请注意,数据缓冲区从不同通道中的不同索引开始。它需要超过8个样本(从buff[8]到buff[22])才能在执行前准备就绪。由于FIR具有32个抽头,因此需要一个aie::sliding_穆尔<8,8>操作和三个aie::sliding_mac<8,8>操作来计算八个输出通道。通过buff.insert从流端口更新数据缓冲区。
向量化的内核代码如下:
//keep margin data between different executions of graph
static aie::vector<cint16,32> delay_line;
alignas(aie::vector_decl_align) static cint16 eq_coef[32]={{1,2},{3,4},...};
__attribute__((noinline)) void fir_32tap_vector(input_stream<cint16> *sig_in, output_stream<cint16> * sig_out){
const int LSIZE=(SAMPLES/32);
aie::accum<cacc48,8> acc;
const aie::vector<cint16,8> coe[4] =
{aie::load_v<8>(eq_coef),aie::load_v<8>(eq_coef+8),aie::load_v<8>(eq_coef+16),aie::load_v<8>(eq_coef+24)};
aie::vector<cint16,32> buff=delay_line;
for(int i=0;i<LSIZE;i++){//1st 8 samplesacc = aie::sliding_mul<8,8>(coe[0],0,buff,0);acc = aie::sliding_mac<8,8>(acc,coe[1],0,buff,8);buff.insert(0,readincr_v<4>(sig_in));buff.insert(1,readincr_v<4>(sig_in));acc = aie::sliding_mac<8,8>(acc,coe[2],0,buff,16);acc = aie::sliding_mac<8,8>(acc,coe[3],0,buff,24);writeincr(sig_out,acc.to_vector<cint16>(SHIFT));
//2nd 8 samplesacc = aie::sliding_mul<8,8>(coe[0],0,buff,8);acc = aie::sliding_mac<8,8>(acc,coe[1],0,buff,16);buff.insert(2,readincr_v<4>(sig_in));buff.insert(3,readincr_v<4>(sig_in));acc = aie::sliding_mac<8,8>(acc,coe[2],0,buff,24);acc = aie::sliding_mac<8,8>(acc,coe[3],0,buff,0);writeincr(sig_out,acc.to_vector<cint16>(SHIFT));
//3rd 8 samplesacc = aie::sliding_mul<8,8>(coe[0],0,buff,16);acc = aie::sliding_mac<8,8>(acc,coe[1],0,buff,24);buff.insert(4,readincr_v<4>(sig_in));buff.insert(5,readincr_v<4>(sig_in));acc = aie::sliding_mac<8,8>(acc,coe[2],0,buff,0);acc = aie::sliding_mac<8,8>(acc,coe[3],0,buff,8);writeincr(sig_out,acc.to_vector<cint16>(SHIFT));
//4th 8 samplesacc = aie::sliding_mul<8,8>(coe[0],0,buff,24);acc = aie::sliding_mac<8,8>(acc,coe[1],0,buff,0);buff.insert(6,readincr_v<4>(sig_in));buff.insert(7,readincr_v<4>(sig_in));acc = aie::sliding_mac<8,8>(acc,coe[2],0,buff,8);acc = aie::sliding_mac<8,8>(acc,coe[3],0,buff,16);writeincr(sig_out,acc.to_vector<cint16>(SHIFT));}delay_line=buff;
}
void fir_32tap_vector_init()
{//initialize datafor (int i=0;i<8;i++){aie::vector<int16,8> tmp=get_wss(0);delay_line.insert(i,tmp.cast_to<cint16>());}
};注:
·对齐(aie::VECTOR_DECL_ALIGN)可用于确保向量加载和存储的数据对齐。
·主循环的每次迭代都会计算多个样本。因此,减少了循环计数。
·数据更新、计算和数据写入在代码中交错。使用AIE::Sliding_MUL的DATA_START控制读取数据缓冲区的哪一部分。
应确定主回路的启动间隔。要定位循环的启动间隔:
1.将-v选项添加到AI引擎编译器,以输出详细的内核编译报告。
2.打开内核编译日志,如Work/aie/<;Col_row>;/<;Col_row>;.log。
3.在日志中,搜索do-loop等关键字,查找循环的启动间隔。下面是一个示例结果:
HW do-loop #2821 in ".../fir_32tap_vector.cc", line 21: (loop #3) :
critical cycle of length 130 : ...
minimum length due to resources: 128
scheduling HW do-loop #2821
(algo 2) -> # cycles: ......
NOTE: automatically decreased the number of used priority functions to 3
to reduce runtime
-> # cycles: .....183 (exceeds -k 110) -> no folding: 183
-> HW do-loop #2821 in ".../Vitis/<VERSION>/aietools/include/adf/
stream/me/stream_utils.h", line 870: (loop #3) : 183 cycles其中:·循环的起始间隔为183。这意味着大约在183/32~=6个循环中产生样品。·消息(exceeds -k 110)-> no folding指示调度器没有尝试软件流水线化,因为循环周期计数超过限制。
4.要覆盖循环周期限制,请向AI Engine编译器添加用户约束,例如-Xchess=“fir_32tap_vector:backend.mist2.maxfoldk=200”。然后,示例结果如下:
(resume algo)
-> after folding: 160 (folded over 1 iterations)
-> HW do-loop #3518 in ".../Vitis/<VERSION>/aietools/include/adf/
stream/me/stream_utils.h", line 277: (loop #3) : 160 cycles其中,软件需要大约160/32=5个周期来产生样本。
注意:根据特定的编译器设置和所使用的编译器版本,确切的周期数可能会略有波动。然而,无论这些变化如何,本节中描述的分析技术仍然相关且适用。
使用多个内核的矢量化版本
按照设计分析中的估计,每个周期有一个输入数据,您必须并行运行四个内核以获得最佳吞吐量。一个这样的解决方案是将32个系数划分为四个内核,其中数据被广播到四个内核。来自核的部分累加结果可以被级联以在最后一个核中产生结果。具体实现如下图所示:
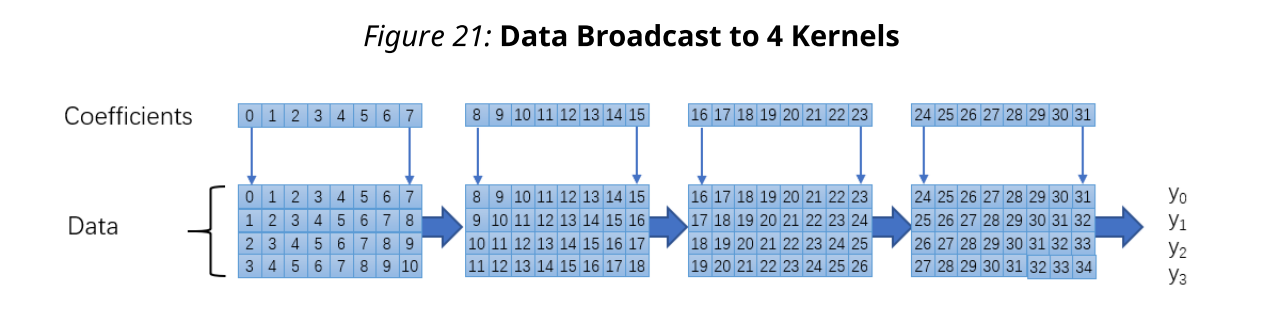
请注意,在后续内核中会丢弃部分初始数据。例如,第二个内核将丢弃前八个输入。选择了四条车道和八个点作为aie::liding_mul。数据读取和写入与计算交织在一起。第一个内核代码如下:
alignas(aie::vector_decl_align) static cint16 eq_coef0[8]={{1,2},{3,4},...};
//For storing data between graph iterations
static aie::vector<cint16,16> delay_line;
__attribute__((noinline)) void fir_32tap_core0(input_stream<cint16> *
sig_in,output_cascade<cacc48> * cascadeout){
const cint16_t * restrict coeff = eq_coef0;
const aie::vector<cint16,8> coe = aie::load_v<8>(coeff);
aie::vector<cint16,16> buff = delay_line;
aie::accum<cacc48,4> acc;
const unsigned LSIZE = (SAMPLES/4/4); // assuming samples is integerpower of 2 and greater than 16
main_loop:for (unsigned int i = 0; i < LSIZE; ++i)
chess_prepare_for_pipelining
{//8 MAC produce 4 partial outputbuff.insert(2,readincr_v<4>(sig_in));acc = aie::sliding_mul<4,8>(coe,0,buff,0);writeincr(cascadeout,acc);//8 MAC produce 4 partial outputbuff.insert(3,readincr_v<4>(sig_in));acc = aie::sliding_mul<4,8>(coe,0,buff,4);writeincr(cascadeout,acc);buff.insert(0,readincr_v<4>(sig_in));acc = aie::sliding_mul<4,8>(coe,0,buff,8);writeincr(cascadeout,acc);buff.insert(1,readincr_v<4>(sig_in));acc = aie::sliding_mul<4,8>(coe,0,buff,12);writeincr(cascadeout,acc);
}
delay_line = buff;
}
void fir_32tap_core0_init(){// Drop samples if not first blockint const Delay = 0;for (int i = 0; i < Delay; ++i){get_ss(0);
}//initialize data
for (int i=0;i<8;i++){int tmp=get_ss(0);delay_line.set(*(cint16*)&tmp,i);}
};注意:
· __attribute__((noinline))是可选的,以保持函数层次结构。
· chess_prepare_for_pipelining是可选的,因为工具可以进行自动流水线操作。
·每个aie::sliding_穆尔<4,8>乘以四个通道八个点MAC,并且部分结果通过级联链发送到下一个内核。
·从aie::sliding_穆尔的data_start参数开始读取数据缓冲区。当内核代码以循环方式到达结尾时,它将返回到开头。编译报告可以在Work/aie/<COL_ROW>/<COL_ROW>.log中找到,并且需要-v选项来生成详细报告。在日志中,搜索关键字,如do-loop,以查找循环的启动间隔。在下面的示例日志文件中,可以看到循环的初始间隔为16:
(resume algo) -> after folding: 16 (folded over 1 iterations)
-> HW do-loop #128 in ".../Vitis/<VERSION>/aietools/include/adf/stream/me/
stream_utils.h", line 1192: (loop #3) : 16 cycles上面的内核代码大约需要16(周期)/ 16(部分结果)= 1个周期来产生部分输出。其他三个内核是相似的。第二个内核代码如下:
alignas(aie::vector_decl_align) static cint16 eq_coef2[8]={{17,18},
{19,20},...};
//For storing data between graph iterations
alignas(aie::vector_decl_align) static aie::vector<cint16,16> delay_line;
__attribute__((noinline)) void fir_32tap_core1(input_stream<cint16> *
sig_in, input_cascade<cacc48> * cascadein,
output_cascade<cacc48> * cascadeout){
const aie::vector<cint16,8> coe = aie::load_v<8>(eq_coef1);
aie::vector<cint16,16> buff = delay_line;
aie::accum<cacc48,4> acc;
const unsigned LSIZE = (SAMPLES/4/4); // assuming samples is integer
power of 2 and greater than 16
for (unsigned int i = 0; i < LSIZE; ++i)
chess_prepare_for_pipelining
{//8 MAC produce 4 partial outputacc = readincr_v4(cascadein);buff.insert(2,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,0);writeincr(cascadeout,acc);acc = readincr_v4(cascadein);buff.insert(3,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,4);writeincr(cascadeout,acc);acc = readincr_v4(cascadein);buff.insert(0,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,8);writeincr(cascadeout,acc);acc = readincr_v4(cascadein);buff.insert(1,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,12);writeincr(cascadeout,acc);
}
delay_line = buff;
}
void fir_32tap_core1_init()
{// Drop samples if not first blockint const Delay = 8;for (int i = 0; i < Delay; ++i){get_ss(0);}//initialize datafor (int i=0;i<8;i++){int tmp=get_ss(0);delay_line.set(*(cint16*)&tmp,i);}
};第三个内核代码如下:
alignas(aie::vector_decl_align) static cint16 eq_coef2[8]={{33,34},
{35,36},...};
//For storing data between graph iterations
alignas(aie::vector_decl_align) static aie::vector<cint16,16> delay_line;
__attribute__((noinline)) void fir_32tap_core2(input_stream<cint16> *
sig_in, input_cascade<cacc48> * cascadein,
output_cascade<cacc48> * cascadeout){
const aie::vector<cint16,8> coe = aie::load_v<8>(eq_coef2);
aie::vector<cint16,16> buff = delay_line;
aie::accum<cacc48,4> acc;
const unsigned LSIZE = (SAMPLES/4/4); // assuming samples is integer
power of 2 and greater than 16
for (unsigned int i = 0; i < LSIZE; ++i)
chess_prepare_for_pipelining
{
//8 MAC produce 4 partial outputacc = readincr_v4(cascadein);buff.insert(2,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,0);writeincr(cascadeout,acc);acc = readincr_v4(cascadein);buff.insert(3,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,4);writeincr(cascadeout,acc);acc = readincr_v4(cascadein);buff.insert(0,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,8);writeincr(cascadeout,acc);acc = readincr_v4(cascadein);buff.insert(1,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,12);writeincr(cascadeout,acc);
}delay_line = buff;
}
void fir_32tap_core2_init(){
// Drop samples if not first block
int const Delay = 16;for (int i = 0; i < Delay; ++i){get_ss(0);}
//initialize datafor (int i=0;i<8;i++){int tmp=get_ss(0);delay_line.set(*(cint16*)&tmp,i);}
};最后一个内核代码如下:
alignas(aie::vector_decl_align) static cint16 eq_coef3[8]={{49,50},
{51,52},...};
//For storing data between graph iterations
alignas(aie::vector_decl_align) static aie::vector<cint16,16> delay_line;
__attribute__((noinline)) void fir_32tap_core3(input_stream<cint16> *
sig_in, input_cascade<cacc48> * cascadein,
output_stream<cint16> * data_out){
const aie::vector<cint16,8> coe = aie::load_v<8>(eq_coef3);
aie::vector<cint16,16> buff = delay_line;
aie::accum<cacc48,4> acc;
const unsigned LSIZE = (SAMPLES/4/4); // assuming samples is integer
power of 2 and greater than 16
for (unsigned int i = 0; i < LSIZE; ++i)
chess_prepare_for_pipelining
{
//8 MAC produce 4 outputacc = readincr_v4(cascadein);buff.insert(2,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,0);writeincr(data_out,acc.to_vector<cint16>(SHIFT));acc = readincr_v4(cascadein);buff.insert(3,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,4);writeincr(data_out,acc.to_vector<cint16>(SHIFT));acc = readincr_v4(cascadein);buff.insert(0,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,8);writeincr(data_out,acc.to_vector<cint16>(SHIFT));acc = readincr_v4(cascadein);buff.insert(1,readincr_v<4>(sig_in));acc = aie::sliding_mac<4,8>(acc,coe,0,buff,12);writeincr(data_out,acc.to_vector<cint16>(SHIFT));
}
delay_line = buff;
}
void fir_32tap_core3_init()
{
// Drop samples if not first blockint const Delay = 24;for (int i = 0; i < Delay; ++i){get_ss(0);}
//initialize datafor (int i=0;i<8;i++){int tmp=get_ss(0);delay_line.set(*(cint16*)&tmp,i);}
};最后一个内核使用acc.to_vector<cint16>(vector)将结果写入输出流。每个内核需要一个周期来产生部分输出。当它们同时工作时,系统性能为一个周期产生一个输出,达到了设计目标。
精彩文章,请关注订阅号:威视锐科技