Apollo 可观测性最佳实践
简介
Apollo(阿波罗)是一款可靠的分布式配置管理中心,诞生于携程框架研发部,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景,提供 Java 和 dotNET 原生客户端,提供了 Spring 的集成支持,其他语言通过 HTTP API 使用。
Apollo 在分布式部署时包含由三类进程 Portal、ConfigService、AdminService 扮演的众多角色,例如为测试和生产环境分别部署专用的 ConfigService、AdminService 实现不同环境间的隔离,Apollo 官方部署架构文档详细讨论了这一主题。在可观测方面,Apollo 的所有进程在 /prometheus 端口暴露指标,因此需要在每个进程采集指标,且需要通过进程角色类别、进程实例名称两类标签对部署的进程做出区分。
了解 Apollo 的工作机制是通过指标观测 Apollo 的前提,Apollo 官方设计文档详细讨论了这一主题,这里列出 Apollo 的配置发布过程:
- 用户登录 Portal 发布配置;
- Portal 调用 AdminService 接口进行配置发布;
- AdminService 发布配置后,向所有 ConfigService 发送 ReleaseMessage;
- ConfigService 收到 ReleaseMessage 后通过监听器通知对应客户端拉取配置;
- 客户端以 HTTP 长轮询方式连接监听器,60 秒内没有客户端相关的配置发布时连接器返回 304,客户端重新建立连接,有相关配置发布时监听器立即返回,客户端根据返回信息拉取配置,此外,客户端会定时拉取配置,配置信息缓存在内存和本地文件中。
以上过程中 ReleaseMessage 的发送过程是典型的消息消费场景,但是 Apollo 为了轻量化设计采用了以下设计方案:
- AdminService 在配置发布后向 ReleaseMessage 表插入记录:AppId+Cluster+Namespace;
- ConfigService 每秒扫描一次 ReleaseMessage 表,如发现新消息则通知所有的消息监听器;
- 消息监听器得到 ReleaseMessage 后通知对应客户端。
观测云
观测云采集器 DataKit 支持 Prometheus 指标采集插件,能够从指标端点自动拉取指标,并在指标上报时附加由用户定义的标签。
部署 DataKit
登录观测云控制台,点击「集成」-「DataKit」-「Linux」,复制安装命令在服务器执行即可。
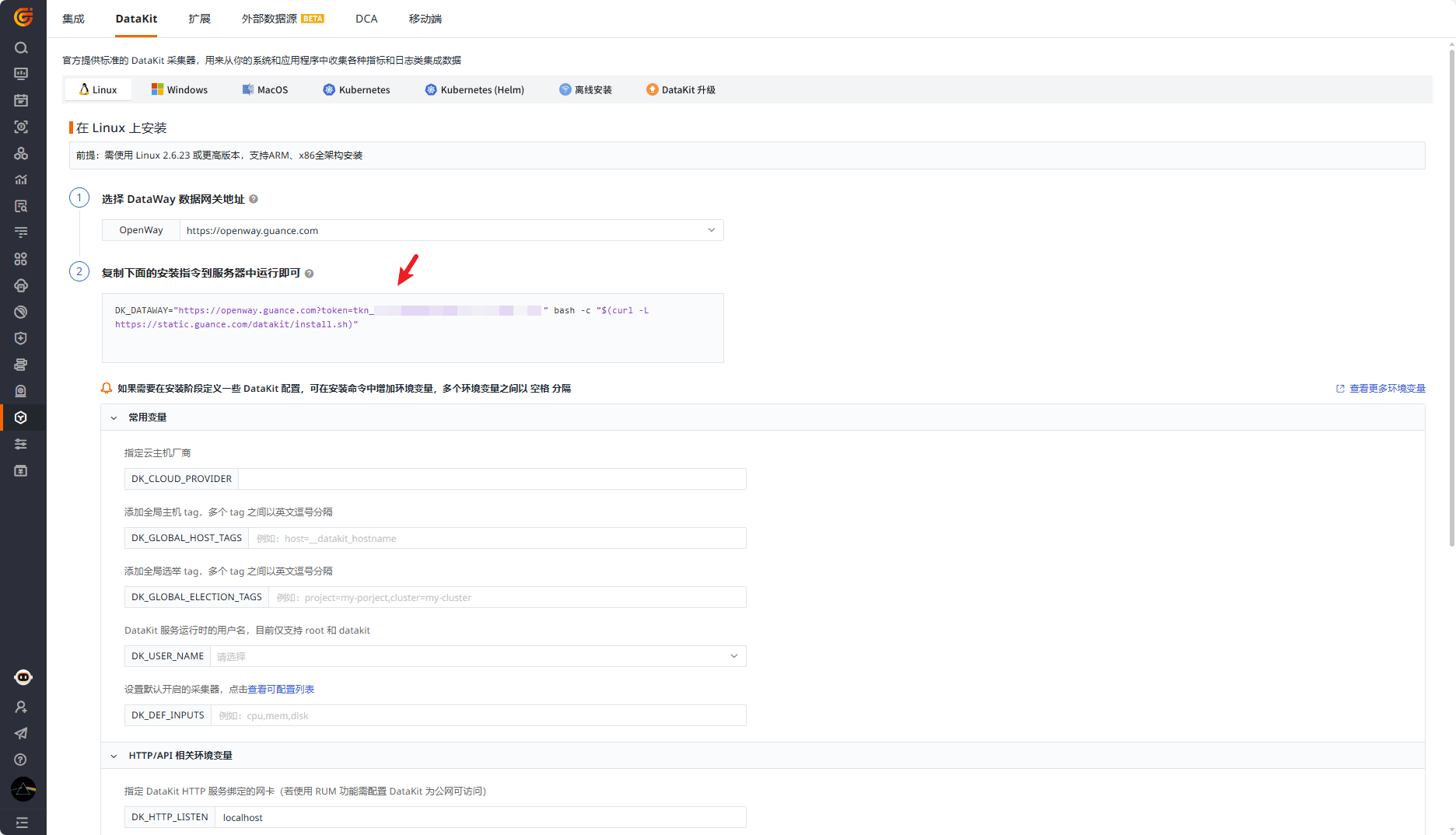
开启 Promv2 插件
这里以一个较为简单的部署架构说明采集配置,Portal、ConfigService、AdminService 部署在同一服务器中,部署架构如下:
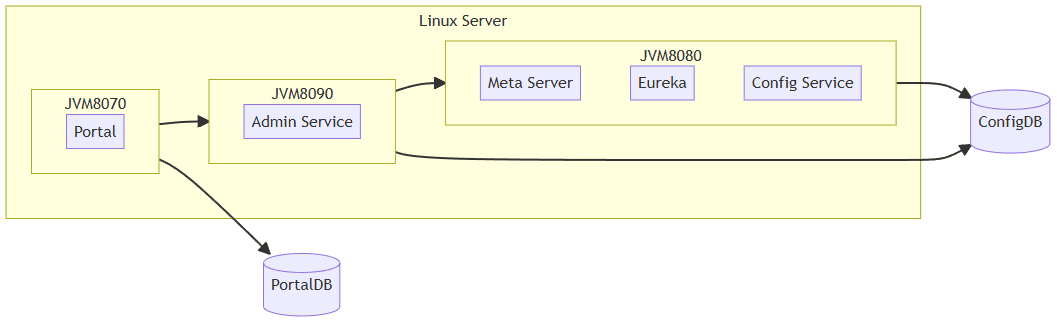
他们分别监听在 8070、8080、8090 端口,按照以下说明创建采集配置:
# 进入 Prometheus 采集器配置文件目录
cd /usr/local/datakit/conf.d/prom# 为每个角色复制配置文件,文件名能够标识一个进程,此处采用的命名规则为:<应用>-<进程类别>-<环境>-<实例编号>
cp promv2.conf.sample apollo-portal-prod-1.conf
cp promv2.conf.sample apollo-config-prod-1.conf
cp promv2.conf.sample apollo-admin-prod-1.conf
修改配置文件,以 apollo-portal-prod-1.conf 为例,修改以下字段的值:
- source,DataKit 显示的采集器别名,与配置文件名保持一致,例如:apollo_portal_prod_1;
- url,采集端点,例如:
http://localhost:8070/prometheus; - measurement_name,指标集名称:apollo;
- guance_role_name,角色标签,可选值:portal、admin_service、config_service;
- guance_instance_name,进程标签,例如:portal_prod_1,表示 Portal 生产环境实例1。
完整配置示例:
# {"version": "1.65.1", "desc": "do NOT edit this line"}[[inputs.promv2]]## Collector alias.source = "apollo_portal_prod_1"url = "http://127.0.0.1:8070/prometheus"## (Optional) Collect interval: (defaults to "30s").interval = "30s"## Measurement name.## If measurement_name is empty, split metric name by '_', the first field after split as measurement set name, the rest as current metric name.## If measurement_name is not empty, using this as measurement set name.measurement_name = "apollo"## Keep Exist Metric Name## If the keep_exist_metric_name is true, keep the raw value for field names.keep_exist_metric_name = true## TLS config# insecure_skip_verify = true## Following ca_certs/cert/cert_key are optional, if insecure_skip_verify = true.# ca_certs = ["/opt/tls/ca.crt"]# cert = "/opt/tls/client.root.crt"# cert_key = "/opt/tls/client.root.key"## Set to 'true' to enable election.election = true## Add HTTP headers to data pulling (Example basic authentication).# [inputs.promv2.http_headers]# Authorization = ""[inputs.promv2.tags]# some_tag = "some_value"# more_tag = "some_other_value"guance_role_name = "portal"guance_instance_name = "portal_prod_1"
按照以上方式修改其他配置文件。修改完成后执行命令 datakit service -R 重启 DataKit,启用采集器,可执行命令 datakit monitor 查看采集器运行情况。
稍后,可在观测云「指标」-「指标管理」页面搜索指标集 apollo 查看指标。
关键指标
| 指标名 | 类型 | 单位 | 描述 |
|---|---|---|---|
| http_server_requests_seconds | Summary | Second | HTTP 服务器处理请求的响应时间,客户端使用 HTTP 方式连接 Apollo 服务端 |
| process_uptime_seconds | Gauge | Second | JVM 启动时长 |
| hikaricp_connections_active | Gauge | - | 活跃连接数 |
| hikaricp_connections_idle | Gauge | - | 空闲连接数 |
| hikaricp_connections_pending | Gauge | - | 等待连接的线程数,正常时为 0,持续不为 0 时应告警,使用增加最大连接数等方式优化 |
| hikaricp_connections_usage_seconds | Summary | Second | 连接被业务占用的时间,过长时告警,可能由数据库响应缓慢引起,关注平均值与P99极值 |
| jvm_memory_max_bytes | Gauge | Byte | JVM 管理的最大内存数,使用 id 标签标识不同内存类型 |
| jvm_memory_usage_after_gc_percent | Gauge | 0-1 | 上一次 GC 后长期存活对象在堆内存中的占比 |
| jvm_memory_used_bytes | Gauge | Byte | JVM 管理的已用内存数,使用 id 标签标识不同内存类型 |
| jvm_memory_committed_bytes | Gauge | Byte | JVM 已提交内存数 |
| jvm_gc_pause_seconds | Summary | Second | JVM GC 暂停的时长 |
| system_load_average_1m | Gauge | - | 操作系统最近一分钟平均负载 |
| system_cpu_count | Gauge | - | JVM 能够使用的 CPU 数 |
| system_cpu_usage | Gauge | - | 操作系统 CPU 使用率 |
| process_cpu_usage | Gauge | - | 进程 CPU 使用率 |
| process_files_max_files | Gauge | - | 允许进程打开的最大文件描述符数 |
| process_files_open_files | Gauge | - | 进程打开的文件描述符数 |
场景视图
登录观测云控制台,点击「场景」 -「新建仪表板」,输入 “Apollo”, 选择 “Apollo 监控视图” ,点击 “确定” 即可添加视图。
Apollo 监控视图包含 HTTP 请求、Hikaricp 连接池、JVM、进程指标相关的聚合,可针对角色、实例、HTTP URI 和请求结果进行过滤。
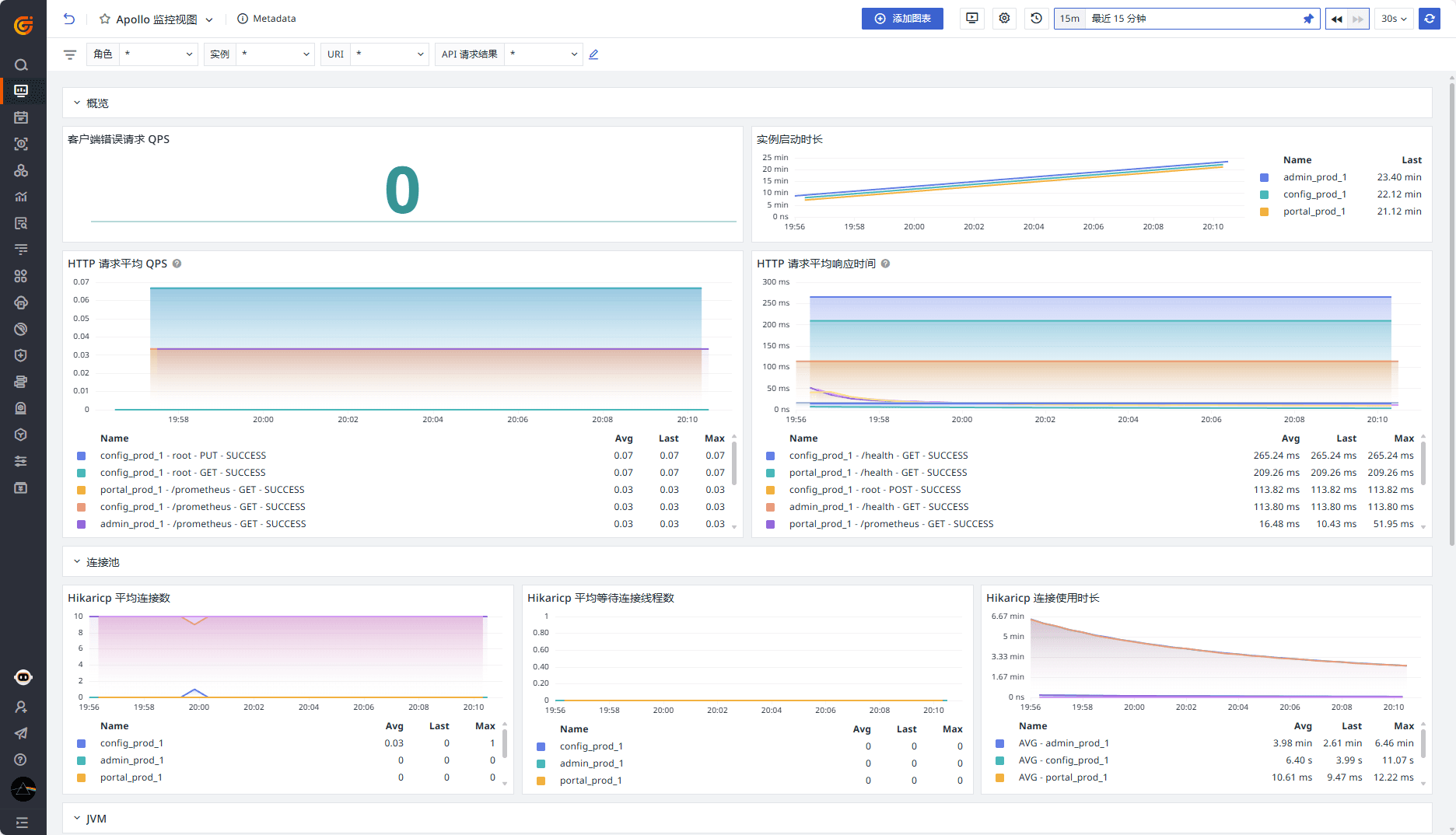
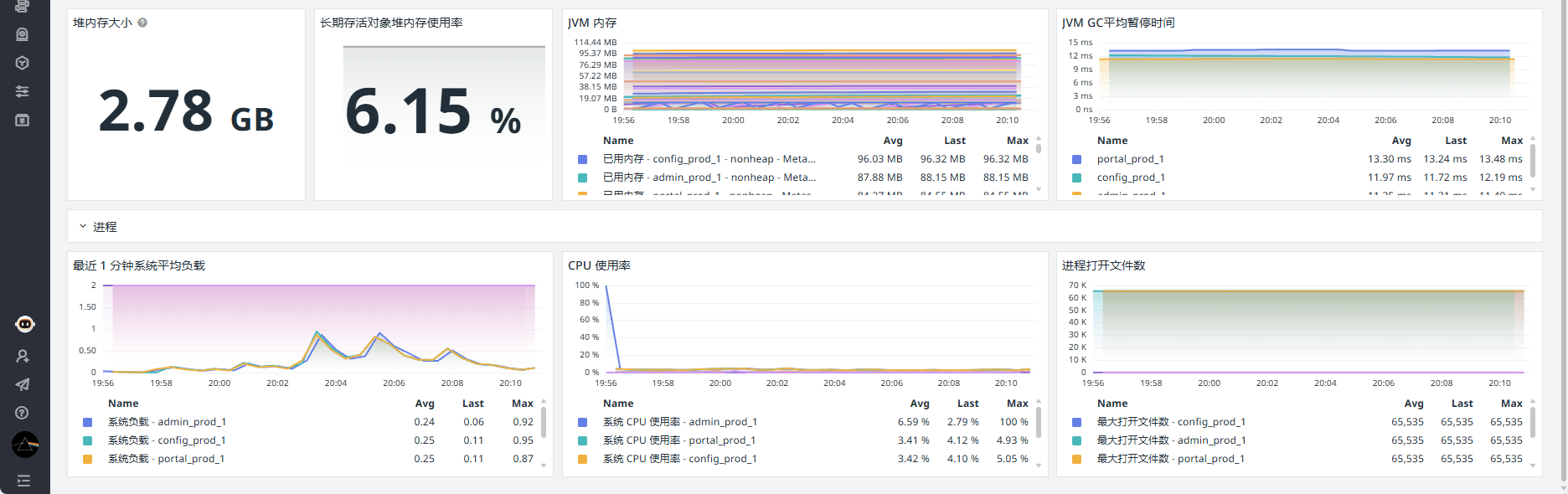
监控器
观测云已内置部分监控器,在「监控」-「监控器」页面启用 Apollo检测库。
| 监控器名称 | 告警提示 |
|---|---|
| Apollo 客户端错误请求 QPS 突增 | 客户端错误突增意味客户端获取配置可能出现问题,请通过仪表盘分析错误来源 |
| Apollo Hikaricp 平均等待连接线程数非零 | Hikaricp 平均等待连接线程数非零意味着大量并发或者 SQL 执行缓慢,请结合连接使用时间分析并进行优化 |
| Apollo Hikaricp 连接使用平均时长突增 | Hikaricp 连接使用时间突增意味数据库查询时间过长,请结合 P99 时长分析导致查询缓慢的根本原因。 |
| Apollo 打开文件数占比过高 | 打开文件数达到系统限制值将导致进程无法正常运行,请结合打开文件数增长趋势判断,必要时调整操作系统进程最大打开文件数限制。 |
| Apollo 操作系统最近一分钟负载过高 | 系统负载大于 CPU 核数意味系统负载过高,请结合主机进程和操作系统各项指标进行分析 |
总结
通过采集 Apollo 信息,可以实时分析服务运行状况,分析数据、对未来可能发生的故障提前介入,防患于未然。