【Linux】深入理解Linux基础IO:从文件描述符到缓冲区设计
目录
一、文件理解(复习)
1、理解概念复习
(1)狭义理解
(2)广义理解
(3)文件操作的归类认知
(4)系统角度
2、C语言文件复习
(1)文件操作函数
(2)打开文件模式
(3)示例代码
(4)模拟cat命令打印文件内容
(5)输出信息到显示器上
(6)stdin & stdout & stderr
二、系统文件IO
1、位图传递标志位(位标志位)
2、open()函数
(1)pathname
(2)flags标志位(位标志位)
(3)返回值
(4)使用示例:
3、write()函数
4、read()函数
5、文件描述符fd
(1)【0 & 1 & 2】标准化
(2)文件读取流程的原理分析
(3)文件描述符的分配原则
(4)重定向
(5)dup / dup2 系统调用
(6)深入理解重定向与标准错误
三、理解“一切皆文件”
四、缓冲区
1、什么是缓冲区?
2、为什么要引入缓冲区机制?
3、缓冲机制
(1)缓冲区概念
(2)数据流动过程(本质是拷贝)
(3)缓冲区刷新条件(用户级缓冲区—>内核级缓冲区)
4、缓冲类型
(1)全缓冲区
(2)无缓冲区(写透模式WT)
(3)行缓冲区
(4)fflush()
(5)示例说明
5、FILE
6、模拟设计libc库
(1)mystdio.h
(2)mystdio.c
(3)usercode.c
(4)Makefile
一、文件理解(复习)
1、理解概念复习
(1)狭义理解
文件在磁盘里 磁盘是永久性存储介质,因此文件在磁盘上的存储是永久性的。
磁盘是外设(既是输出设备也是输入设备) 磁盘上的文件操作,本质是对文件的所有操作,都是对外设的输入和输出(简称 I/O)。
(2)广义理解
Linux 下一切皆文件(键盘、显示器、网卡、磁盘……这些设备都是通过抽象化的过程来管理的)(后文会详细讲解如何理解)。
(3)文件操作的归类认知
0KB 的空文件:占用磁盘空间。
文件的定义:文件是文件属性(元数据)和文件内容的集合(文件 = 属性(元数据)+ 内容)。
文件操作的本质:所有文件操作本质上是对文件内容的操作和对文件属性的操作。
(4)系统角度
文件操作的本质:文件的操作本质上是进程对文件的操作。
磁盘的管理者:磁盘的管理者是操作系统。
文件读写的本质:文件的读写操作并不是通过 C/C++ 的库函数来实现的(这些库函数只是为用户提供了方便),而是通过文件相关的系统调用接口来实现的。
2、C语言文件复习
(1)文件操作函数
// 打开和关闭文件
FILE *fopen(const char *filename, const char *mode);
int fclose(FILE *stream);
// 二进制读写文件
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream); // 返回读到的基本单位数
size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream);
// 检查文件结束标志
int feof(FILE *stream);(2)打开文件模式
"r":只读(文件必须存在)
"w":只写(创建新文件或清空已有文件)
"a":追加(在文件末尾写入)
"r+":读写(文件必须存在)
"w+":读写(创建新文件或清空已有文件)
"a+":读写(从文件末尾开始)
(3)示例代码
二进制文件操作演示:打开、写入、读取文件
#include<stdio.h>
#include<string.h>int main()
{// 1.打开文件FILE *fp1 = fopen("log.txt", "w");if(fp1 == NULL){perror("fopen");return 1;}// 2.写文件const char *msg = "hello";int cnt = 1;while(cnt <= 10){char buffer[1024];snprintf(buffer, sizeof(buffer), "%s: %d\n", msg, cnt++); // 格式化输出fwrite(buffer, strlen(buffer), 1, fp1);}fclose(fp1);// 3.读文件FILE *fp2 = fopen("log.txt", "r");if(fp2 == NULL){perror("fopen");return 1;}while(1){char buf[1024];int s = fread(buf, 1, sizeof(buf)-1, fp2); // 把打开文件的内容读到buf数组里if(s > 0){buf[s] = '\0'; //末尾置为0printf("%s", buf); // 输出显示器}if(feof(fp2)) break; // 判断文件读到结尾}fclose(fp2);return 0;
}(4)模拟cat命令打印文件内容
#include<stdio.h>
#include<string.h>int main(int argc, char *argv[])
{if(argc != 2) // 命令行参数为2才行哦!{printf("argc error!\n");return 1;}FILE *fp = fopen(argv[1], "r"); // 打开命令行参数表if(!fp){printf("fopen error!\n");return 2;}char buffer[128];while(1){int n = fread(buffer, 1, sizeof(buffer), fp); // 读取内容到bufferif(n > 0){buffer[n] = '\0';printf("%s", buffer);}if(feof(fp)) break;}fclose(fp);return 0;
}
# 执行
$ ./myfile log.txt
hello: 1
hello: 2
hello: 3
hello: 4
hello: 5
hello: 6
hello: 7
hello: 8
hello: 9
hello: 10
(5)输出信息到显示器上
#include <stdio.h>
#include <string.h>int main()
{const char *msg = "hello fwrite\n";// 使用fwrite输出到标准输出(stdout)fwrite(msg, strlen(msg), 1, stdout);// 使用printf输出printf("hello printf\n");// 使用fprintf输出到标准输出(stdout)fprintf(stdout, "hello fprintf\n");return 0;
}(6)stdin & stdout & stderr
● 默认会打开三个输入输出流,分别是stdin,stdout,stderr。
● 仔细观察发现,这三个流的类型都是FILE*,fopen返回值类型,文件指针
#include <stdio.h>extern FILE *stdin; // 标准输入流(通常对应键盘输入)
extern FILE *stdout; // 标准输出流(通常对应屏幕输出)
extern FILE *stderr; // 标准错误流(通常对应屏幕错误输出)二、系统文件IO
打开文件的方式不仅仅是fopen,ifstream等流式,语言层的方案,其实系统才是打开文件最底层的方案。不过,在学习系统文件IO之前,要先了解如何给函数传递标志位,该方案在系统文件IO接口钟会使用到。
1、位图传递标志位(位标志位)
位图是一种高效存储和传递多个标志位(flag)的技术,它通过单个整数的各个二进制位来表示不同的布尔状态。位图利用整型变量的每一位(bit)来表示一个独立的状态标志(1 表示标志被设置,0 表示标志未设置)。
#include<stdio.h>#define ONE 001
#define TWO 002
#define THREE 004void Func(int flags)
{if(flags & ONE) printf("flags is ONE! ");if(flags & TWO) printf("flags is TWO! ");if(flags & THREE) printf("flags is THREE! ");printf("\n");
}
int main()
{Func(ONE);Func(ONE | TWO);Func(ONE | TWO | THREE);return 0;
}2、open()函数
open() 是 Linux/Unix 系统中用于打开或创建文件的低级 I/O 系统调用,相比标准库的 fopen(),它提供更底层的控制。
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);(1)pathname
要打开或创建文件的名字(文件路径名)
(2)flags标志位(位标志位)
打开文件时,可以传入多个参数选项,用下面的一个或多个常数进行“或”运算,构成flags。这些常量在头文件<fcntl.h>钟定义。
① 基本打开模式(必须指定其一):
O_RDONLY: 只读
O_WRONLY: 只写
O_RDWR: 读写
大多数实现将O_RDONLY定义为0,O_WRONLY定义为1,O_RDWR定义为2,以与早期的程序兼容。
② 常用可选标志:
O_CREAT: 文件不存在则创建(使用该选项时,open函数需要同时说明第3个参数mode,用mode指定该新文件的访问权限位<缺省权限是666>)
O_EXCL: 与 O_CREAT 同用时,若文件存在则失败
O_TRUNC: 打开时清空文件
O_APPEND: 追加模式
O_NONBLOCK: 非阻塞模式
O_SYNC: 同步写入(数据+元数据落盘)
O_DSYNC: 同步写入(仅数据落盘)
O_CLOEXEC: exec时自动关闭
(3)返回值
成功打开文件,返回文件的文件描述符,打开失败,返回-1,错误原因存储在 errno 全局变量中。
(4)使用示例:
#include<stdio.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>int main()
{// 只读方式创建文件,设置权限0666// 但系统权限掩码是2,最终显示出的权限是0664//int fd = open("data.txt", O_CREAT | O_RDONLY, 0666);// 我们直接设置权限掩码为全0,最终权限也就是0666了umask(0);int fd = open("data.txt", O_CREAT | O_RDONLY, 0666);if(fd < 0){perror("open error!");return 1;}return 0;
}
3、write()函数
调用write()函数向打开文件写数据。
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);fd:文件描述符,可以是普通文件、管道、套接字、设备等,必须是以可写方式打开的(如 O_WRONLY 或 O_RDWR)
buf:要写入数据的缓冲区指针,类型为 const void*,可以传递任何类型的数据指针,不在乎是文本写入还是二进制写入,只要传入的是格式化后的buf(自己进行文本解释)。
count:请求写入的字节数(不能是'\0'),类型为 size_t(无符号整型)
返回值:若成功,返回自己写的字节数;若出错,返回-1。
其返回值通常与参数count的值相同,否则表示出错。write出错的一个常见原因就是磁盘已写满,或者超过了一个给定进程的文件长度限制。
对于普通文件,写操作从文件的当前偏移量处开始。如果在打开文件时,指定了O_APPEND选项,则在每次写操作之前,将文件偏移量设置在文件的当前结尾处。在一次成功写入后,该文件偏移量增加了实际写的字节数。
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>int main()
{umask(0);int fd = open("data.txt", O_CREAT | O_WRONLY | O_APPEND, 0666);if(fd < 0){perror("open error!");return 1;}printf("%d\n", fd);const char *msg = "abc!\n";//int cnt = 3; // 第一次没有带追加选项时设置的int cnt = 1;while(cnt){// 不要加'\0',添加多余的\0会污染数据write(fd, msg, strlen(msg));cnt--;}close(fd);return 0;
}
$ cat data.txt
hello!
hello!
hello!
abc!
4、read()函数
调用read()函数从打开文件中读取数据。
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);fd:文件描述符,可以是普通文件、管道、套接字、设备等,必须是以可读方式打开的(如 O_RDONLY 或 O_RDWR)
buf:数据读取缓冲区,类型为 void*,可接收任意类型数据,必须预先分配足够内存
count:请求读取的最大字节数,通常设置为缓冲区大小减1(为字符串保留\0空间)
返回值:如read成功,则返回读到的字节数。如达到文件的尾端,则返回0。
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>int main()
{umask(0);int fd = open("log.txt", O_RDONLY, 0666);if(fd < 0){perror("open error!");return 1;}while(1){char buffer[128];int n = read(fd, buffer, sizeof(buffer)-1);if(n > 0){buffer[n] = 0;printf("%s", buffer);}if(n == 0){break;}}close(fd);return 0;
}
5、文件描述符fd
对于内核而言,所有打开的文件都通过文件描述符引用。文件描述符是一个非负整数。当打开一个现有文件或创建一个新文件时,内核向进程返回一个文件描述符。当读、写一个文件时,使用 open 或 creat 返回的文件描述符标识该文件,将其作为参数传送给 read 或 write。
(1)【0 & 1 & 2】标准化
Linux进程默认情况下会有三个缺省打开的文件描述符,分别是标准输入0,标准输出1,标准错误2。这是各种Shell以及很多应用程序的惯例。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <string.h>int main()
{char buf[1024];ssize_t s = read(0, buf, sizeof(buf));if (s > 0) {buf[s] = 0;write(1, buf, strlen(buf));write(2, buf, strlen(buf));}return 0;
}在操作系统接口层面,只认文件描述符fd,用来区别标准输入、标准输出和标准错误。那我们以前学的stdin,stdout,stderr 其实是 C标准库(stdio.h)提供的 FILE* 类型的流对象(语言层),它们封装了底层的文件描述符fd,并添加了缓冲区和高级读写功能。这些 FILE* 对象在程序启动时由C库自动创建,并分别绑定到文件描述符 0、1、2。
extern FILE *stdin; // 标准输入(键盘输入,fd=0)
extern FILE *stdout; // 标准输出(终端输出,fd=1)
extern FILE *stderr; // 标准错误(终端错误输出,fd=2)为什么需要 FILE* 而不仅仅是 fd?
① 文件描述符(fd):直接调用 write(1, "Hello", 5) 会立即写入终端(无缓冲)。
② FILE*(如 stdout):默认是行缓冲(遇到 \n 或缓冲区满时才真正调用 write),并且支持格式化输入输出(fprintf/fscanf)、按行读写(fgets/fputs)、安全错误处理等。
(2)文件读取流程的原理分析
总结:文件描述符就是从0开始的小整数。当我们打开文件时,操作系统在内存中要创建相应的数据结构来描述目标文件。于是就有了file结构体。表示一个已经打开的文件对象。而进程执行open系统调用,所以必须让进程和文件关联起来。每个进程都有一个指针*files, 指向一张表files_struct,该表最重要的部分就是包含一个指针数组,每个元素都是一个指向打开文件的指针!所以,本质上,文件描述符就是该数组的下标。所以,只要拿着文件描述符,就可以找到对应的文件。
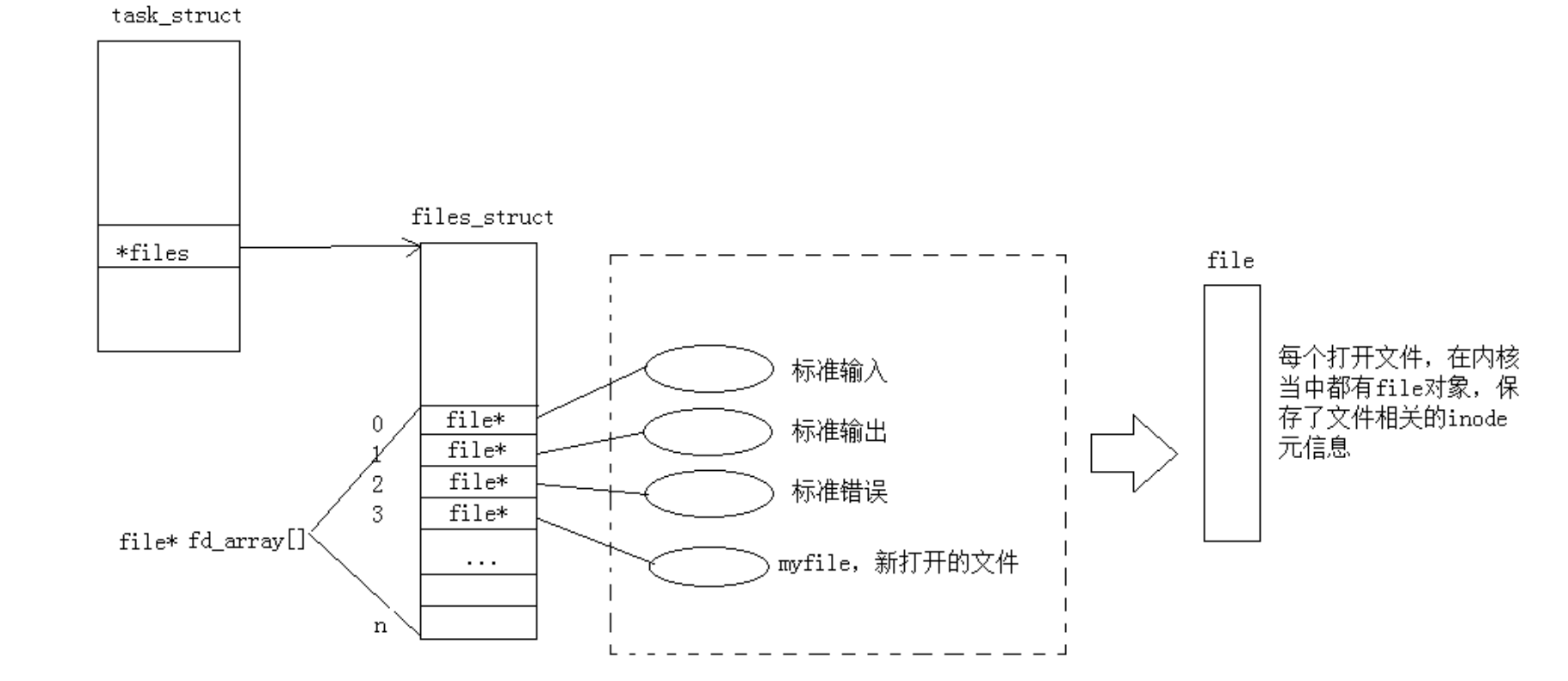
下面我们用一个完整的文件读取流程来帮助理解:
① 当用户发起文件读取请求:
int fd = open("log.txt", O_RDONLY);
char buffer[1024];
read(fd, buffer, sizeof(buffer));
close(fd);② 操作系统处理文件描述符
● 打开文件: 操作系统接收到 open 系统调用后,会在进程的 task_struct 中查找或创建一个 files_struct 结构体。 在 files_struct 中,操作系统会分配一个文件描述符(fd),并将其存储在 fd_array 中。 操作系统还会创建一个 struct file 结构体,用于表示打开的文件,并将其与文件描述符关联。
● 读取文件: 用户调用 read 系统调用时,操作系统会使用文件描述符在 fd_array 中查找对应的 struct file 结构体。 操作系统通过 struct file 结构体中的信息(如文件位置、文件状态等)来定位文件在磁盘上的位置。
③ 文件系统操作
● 文件缓冲区: 操作系统会检查文件缓冲区(file_buffer),看是否已经有需要的数据。 如果文件缓冲区中没有数据,操作系统会从磁盘读取数据到文件缓冲区。 文件缓冲区的作用是减少磁盘I/O操作,提高文件访问速度。
● 数据传输: 操作系统从文件缓冲区中读取数据,并将其复制到用户提供的缓冲区(buffer)中。 如果用户提供的缓冲区大小大于文件缓冲区中的数据量,操作系统会继续从磁盘读取数据,直到满足用户请求的数据量。
④ 关闭文件
用户调用 close 系统调用时,操作系统会释放与文件描述符关联的资源。 操作系统会检查文件缓冲区中是否有未写入磁盘的数据,如果有,会将这些数据写入磁盘。 最后,操作系统会从 fd_array 中移除文件描述符,并释放 struct file 结构体。
⑤ 文件缓冲区管理
文件缓冲区由操作系统管理,操作系统会根据需要自动分配和释放缓冲区。 缓冲区中的数据会在适当的时候写入磁盘,以确保数据的一致性。
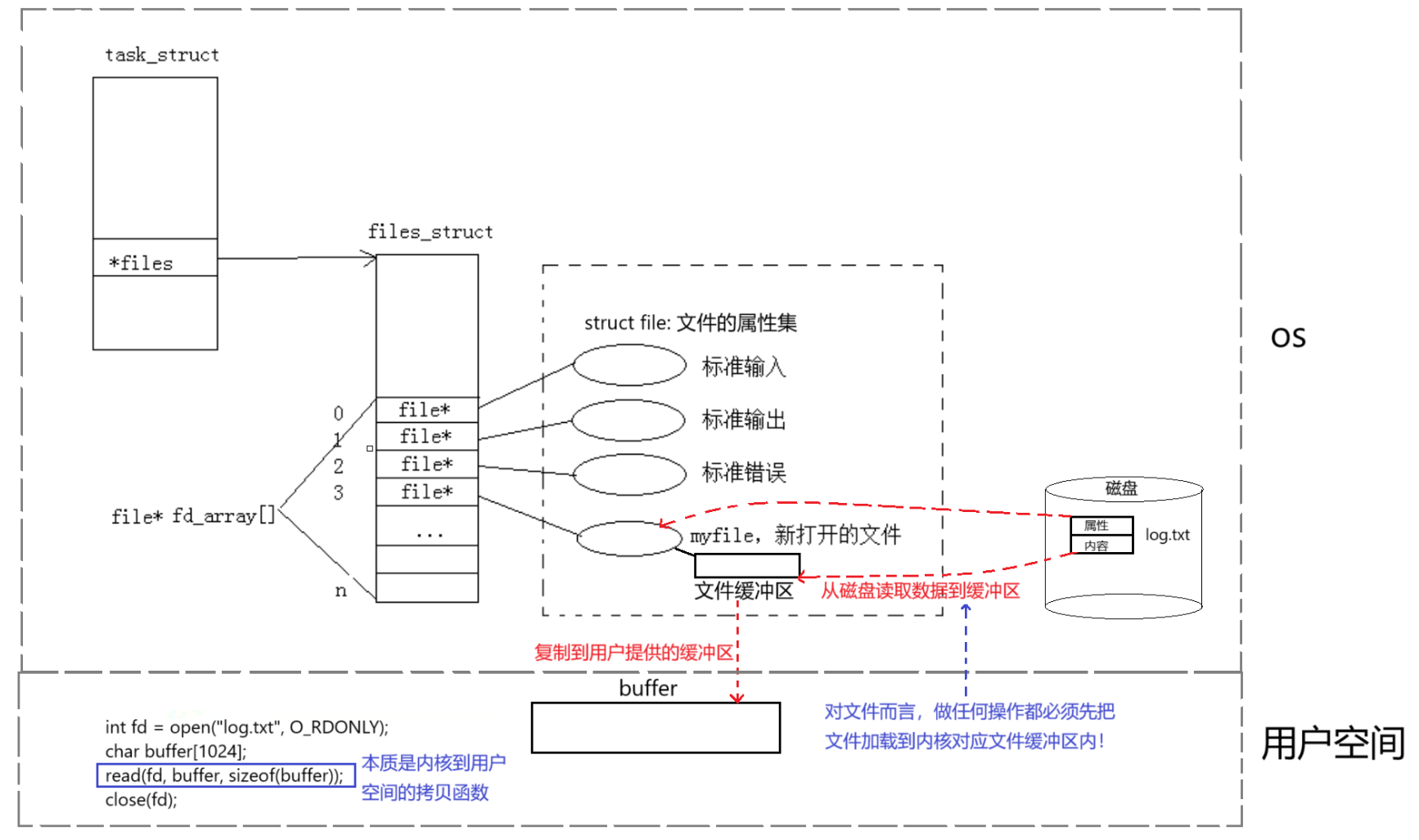
(3)文件描述符的分配原则
文件描述符的分配原则:在file_struct数组中,找到当前没有被使用的最小的一个下标,作为新的文件描述符。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
{int fd = open("myfile", O_RDONLY);if (fd < 0) {perror("open");return 1;}printf("fd: %d\n", fd);close(fd);return 0;
}
输出的fd是3, 但关闭0,发现fd是0。
#include <stdio.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>int main()
{close(0);int fd = open("myfile", O_RDONLY);if (fd < 0) {perror("open");return 1;}printf("fd: %d\n", fd);close(fd);return 0;
}(4)重定向
关闭1(标准输出)后,我们发现原本应该输出到显示器的内容,输出到了文件file.txt当中,其中fd=1。这种现象叫做输出重定向。操作系统底层做了重定向,在我们看来上层的数组下标不变,重定向改变的是文件描述符表对应的数组下标里面的指针的指向。
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>int main()
{close(1);int fd = open("file.txt", O_WRONLY|O_CREAT, 0666);if(fd < 0){perror("open error!");return 1;}printf("fd: %d\n", fd); // 向stdout里打印的fflush(stdout); // 刷新显示器文件close(fd);return 0;
}
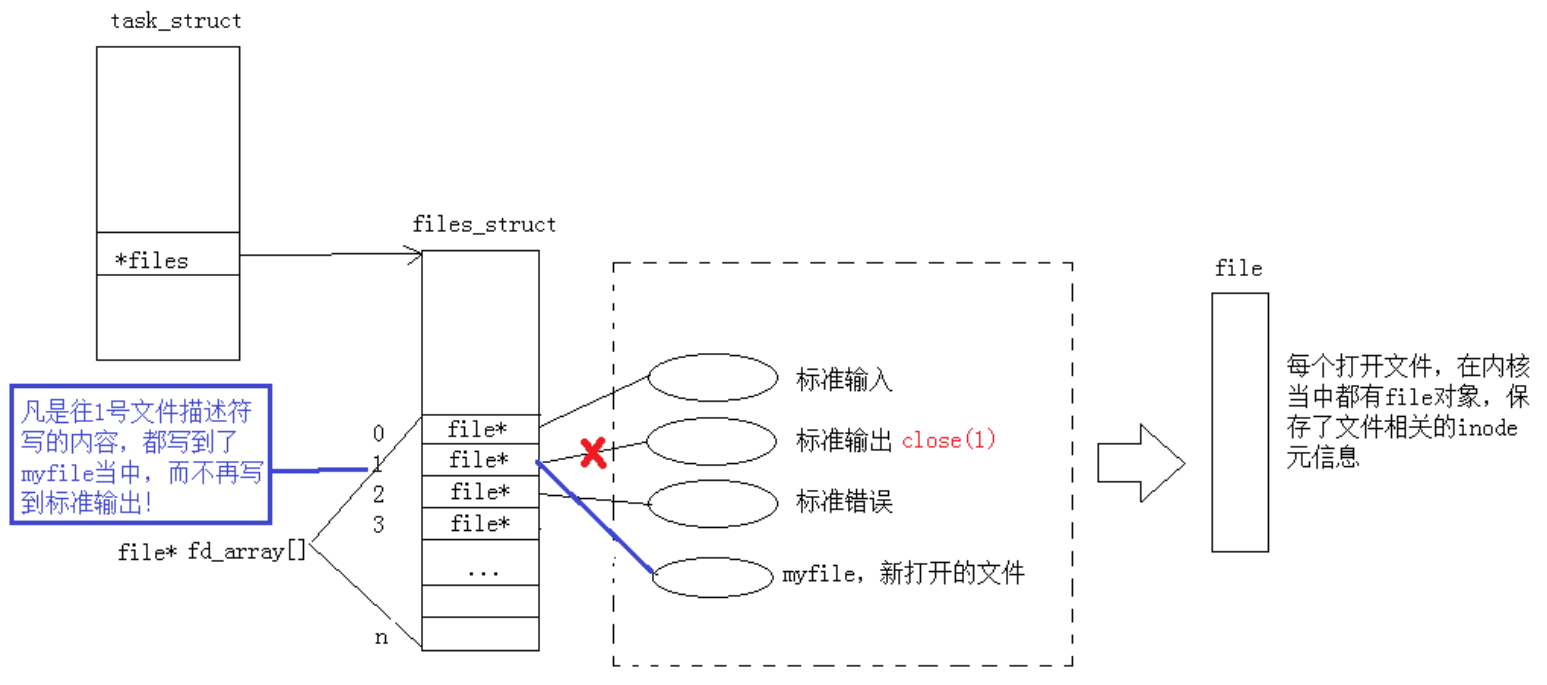
(5)dup / dup2 系统调用
dup 和 dup2 是 Linux/Unix 系统提供的用于复制文件描述符的系统调用,常用于文件描述符重定向。
#include <unistd.h>int dup(int oldfd);
int dup2(int oldfd, int newfd);两函数的返回值:若成功返回新的文件描述符表,若出错返回-1。对于 dup2() 是让 newfd 的内容变成 oldfd 的拷贝,也就是让 newfd 的指针也指向 oldfd 指向的 struct file{}。如果 newfd 已经打开,则先将其关闭。如若 newfd 等于 oldfd,则 dup2() 返回 newfd,而不关闭它。
下面是我们自己实现的输出重定向。printf是C库当中的IO函数,一般往stdout中输出,但是stdout底层访问文件的时候,找的还是fd:1。但此时,fd:1下标所表示内容,已经变成了myfile的地址,不再是显示器文件的地址,所以,输出的任何消息都会往文件中写入,进而完成输出重定向。
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>int main()
{int fd = open("file.txt", O_WRONLY | O_CREAT | O_TRUNC, 0666);if(fd < 0){perror("open error!");return 1;}dup2(fd,1); // 输出重定向printf("fd: %d\n", fd);printf("hello!\n");printf("hello!\n");printf("hello!\n");fprintf(stdout, "hello stdout!\n");fprintf(stdout, "hello stdout!\n");fprintf(stdout, "hello stdout!\n");const char *buffer = "hello word!\n";write(fd, buffer, strlen(buffer));close(fd);return 0;
}$ cat file.txt
hello word!
fd: 3
hello!
hello!
hello!
hello stdout!
hello stdout!
hello stdout!
那追加和输入重定向如何完成呢?只需要将打开文件的方式改为O_APPEND就可是实现追加重定向;下面实现输入重定向:
#include<stdio.h>
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>int main()
{int fd = open("file.txt", O_RDONLY | O_CREAT, 0666);if(fd < 0){perror("open error!");return 1;}dup2(fd,0);close(fd);while(1){char buffer[128];if(!fgets(buffer, sizeof(buffer), stdin)) break;printf("%s", buffer);}return 0;
}
$ ./myfile
hello word!
fd: 3
hello stdout!
hello word!
fd: 3
hello stdout!
hello word!
fd: 3
hello stdout!
重定向:打开文件的方式+dup2( )
(6)深入理解重定向与标准错误
// stream.cc
#include <iostream>
#include <stdio.h>int main()
{// 输出到标准输出[1]上——>显示器文件std::cout<< "hello cout!" << std::endl;printf("hello printf!\n");// 输出到标准错误[2]上——>显示器文件std::cerr << "hello cerr!" << std::endl;fprintf(stderr, "hello fprintf!\n");return 0;
}
$ ./a.out
hello cout!
hello printf!
hello cerr!
hello fprintf!# 将标准输出指向的文件内容输出重定向到log.txtx文件,
# 但执行了a.out文件显示器文件还是会打印标准错误指向的文件
$ ./a.out > log.txt
hello cerr!
hello fprintf!
$ cat log.txt
hello cout!
hello printf!std::cout 和 printf 都输出到标准输出(stdout)
std::cerr 和 fprintf(stderr) 都输出到标准错误(stderr)
重定向默认行为:./a.out > log.txt 等价于 ./a.out 1 > log.txt
在终端中,stdout 和 stderr 默认都显示在屏幕(显示器文件)上,但可以分别重定向:可以通过重定向能力,把常规消息和错误消息进行分离。
# 标准输出指向的文件内容输出重定向到log.normal文件,
# 标准错误指向的文件内容输出重定向到log.error文件。
$ ./a.out 1>log.normal 2>log.error
$ cat log.normal
hello cout!
hello printf!
$ cat log.error
hello cerr!
hello fprintf!这样解释了在 Linux/Unix 系统中,已经有stdout(标准输出)默认指向显示器了,为什么还要有stdout(标准错误)???
stdout(文件描述符1):用于程序正常的输出结果(例如 printf、cout)。
stderr(文件描述符2):专用于错误消息、警告或日志(例如 fprintf(stderr)、cerr)。
目的:即使程序将正常输出重定向到文件(如 ./a.out > log.txt),错误信息仍能立即显示在终端,提醒用户注意问题。
如果我想把stdout和stderr的内容都写到同一个文件呢?
$ ./a.out 1>log.normal 2>&1
$ cat log.normal
hello cout!
hello printf!
hello cerr!
hello fprintf!$ ./a.out 1>log.normal 2>>log.normal
$ cat log.normal
hello cout!
hello printf!
hello cerr!
hello fprintf!这里的【2>&1】语法含义是将1(标准输出)指向的内容写到2(标准错误)指向的内容中。
三、理解“一切皆文件”
首先,在windows中是文件的东西,它们在linux中也是文件;其次一些在windows中不是文件的东西,比如进程、磁盘、显示器、键盘这样硬件设备也被抽象成了文件,你可以使用访问文件的方法访问它们获得信息;甚至管道,也是文件;将来我们要学习网络编程中的socket(套接字)这样的东西,使用的接口跟文件接口也是一致的。
这样做最明显的好处是,开发者仅需要使用一套 API 和开发工具,即可调取 Linux 系统中绝大部分的资源。举个简单的例子,Linux 中几乎所有读(读文件,读系统状态,读PIPE)的操作都可以用 read 函数来进行;几乎所有更改(更改文件,更改系统参数,写 PIPE)的操作都可以用 write 函数来进行。
之前我们讲过,当打开一个文件时,操作系统为了管理所打开的文件,都会为这个文件创建一个file结构体,值得关注的是 struct file 中的 f_op 指针指向了一个 file_operations 结构体,这个结构体中的成员除了 struct module* owner 其余都是函数指针。file_operation 就是把系统调用和驱动程序关联起来的关键数据结构,这个结构的每一个成员都对应着一个系统调用。读取 file_operation 中相应的函数指针,接着把控制权转交给函数,从而完成了 Linux 设备驱动程序的工作。
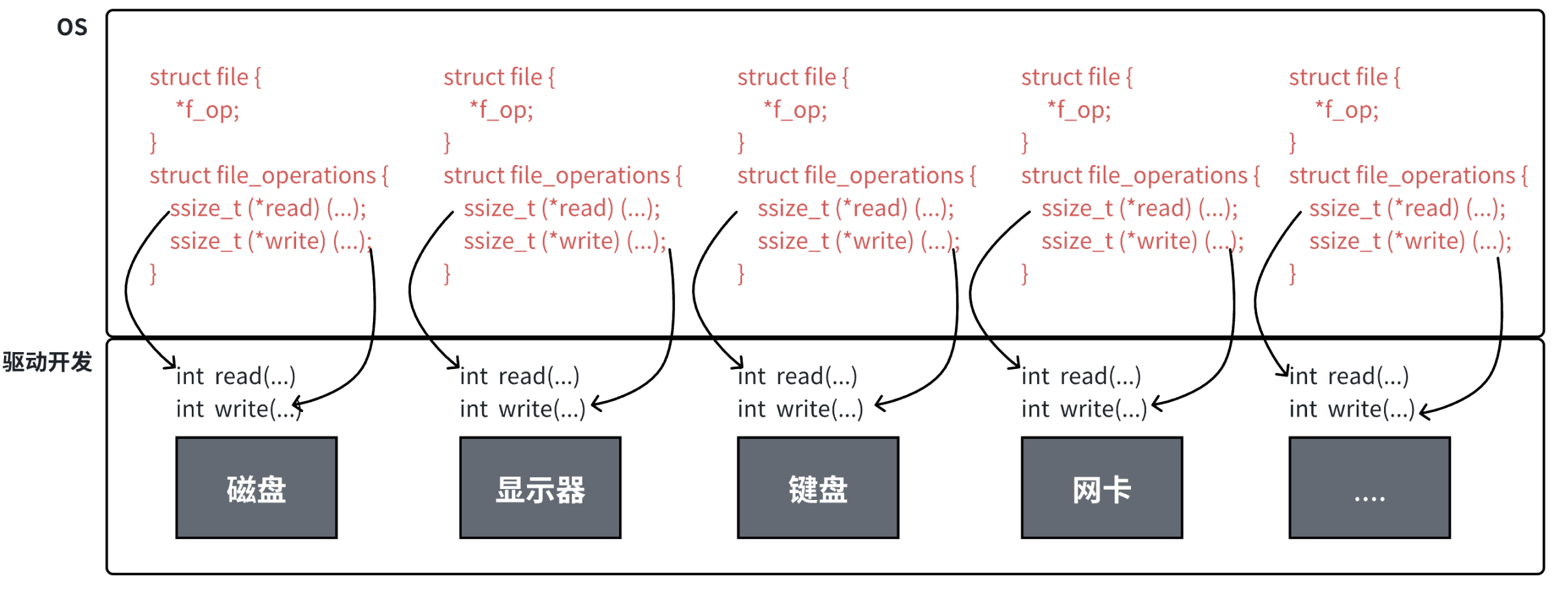
上图中的外设,每个设备都可以有自己的read、write,但一定是对应着不同的操作方法!!但通过struct file下file_operation中的各种函数回调,让我们开发者只用file便可调取Linux系统中绝大部分的资源!!这便是"linux下一切皆文件"的核心理解。
四、缓冲区
1、什么是缓冲区?
缓冲区是内存空间的一部分。也就是说,在内存空间中预留了一定的存储空间,这些存储空间用来缓冲输入或输出的数据,这部分预留的空间就叫做缓冲区。缓冲区根据其对应的是输入设备还是输出设备,分为输入缓冲区和输出缓冲区。
2、为什么要引入缓冲区机制?
读写文件时,如果不开辟文件操作的缓冲区,直接通过系统调用对磁盘进行操作(读、写等),那么每次对文件进行一次读写操作时,都需要使用读写系统调用来处理此操作,即需要执行一次系统调用。执行一次系统调用将涉及CPU状态的切换,即从用户空间切换到内核空间,实现进程上下文的切换,这将损耗一定的CPU时间,频繁的磁盘访问对程序的执行效率造成很大的影响。
为了减少使用系统调用(是有成本的)的次数,提高效率,我们就可以采用缓冲机制。比如我们从磁盘里取信息,可以在磁盘文件进行操作时,一次从文件中读出大量的数据到缓冲区中,以后对这部分的访问就不需要再使用系统调用了,等缓冲区的数据取完后再去磁盘中读取,这样就可以减少磁盘的读写次数。再加上计算机对缓冲区的操作速度远快于对磁盘的操作,故应用缓冲区可大幅提高计算机的运行速度。
又比如,我们使用打印机打印文档,由于打印机的打印速度相对较慢,我们先把文档输出到打印机相应的缓冲区,打印机再自行逐步打印,这时我们的CPU可以处理别的事情。可以看出,缓冲区就是一块内存区,它用在输入输出设备和CPU之间,用来缓存数据。它使得低速的输入输出设备和高速的CPU能够协调工作,避免低速的输入输出设备占用CPU,解放出CPU,使其能够高效率工作。
3、缓冲机制
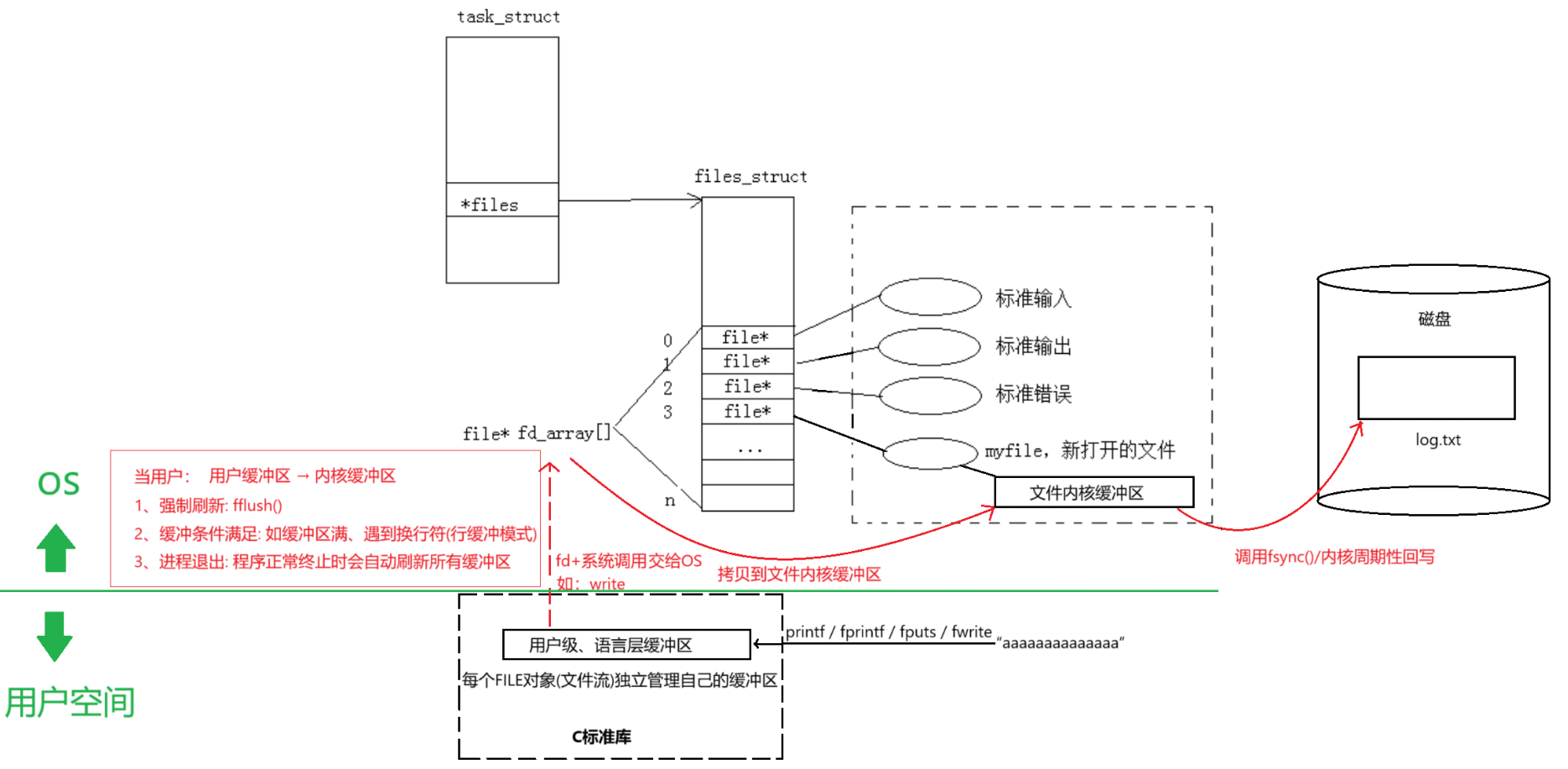
(1)缓冲区概念
缓冲区本质上是内存中的临时数据中转站,现代计算机系统通常有多级缓冲区:
用户程序 → 语言层缓冲区 → 内核缓冲区 → 硬件缓存 → 物理设备
● 用户级缓冲区 (语言层缓冲区)
实现者:由编程语言标准库实现(如C的stdio、C++的iostream)
存储位置:在进程的用户空间内存中
管理单位:每个FILE对象(文件流)独立管理自己的缓冲区
典型大小:通常为4KB-8KB(与文件系统块大小对齐)
● 文件内核缓冲区是操作系统内核的一部分,用于临时存储从用户空间传递过来的数据。
(2)数据流动过程(本质是拷贝)
● 用户程序调用如printf等函数时,数据首先被写入用户级缓冲区。
● 然后数据从用户级缓冲区通过系统调用(如write)传递到文件内核缓冲区。
● 当用户执行某些操作触发缓冲区刷新时,文件内核缓冲区中的数据会被写入到实际的文件中。
(3)缓冲区刷新条件(用户级缓冲区—>内核级缓冲区)
● 强制刷新:调用fflush()函数
● 刷新条件满足:如缓冲区满、遇到换行符(行缓冲模式)
● 进程退出:程序正常终止时会自动刷新所有缓冲区
4、缓冲类型
标准I/O提供了三种类型的缓冲区:
(1)全缓冲区
要求填满整个缓冲区后才进行I/O系统调用操作。对于磁盘文件的操作通常使用全缓冲的方式访问。在一个流上执行第一次I/O操作时,相关标准I/O函数通常调用 malloc 获得需使用的缓冲区。
(2)无缓冲区(写透模式WT)
标准I/O库不对字符进行缓存,直接调用系统调用。标准出错流stderr通常是不带缓冲区的,这使得出错信息能够尽快地显示出来。
(3)行缓冲区
当在输入和输出中遇到换行符时,标准I/O库函数将会执行系统调用操作。当所操作的流涉及一个终端时(例如标准输入和标准输出),使用行缓冲方式。只要填满了缓冲区,即使还没有遇到换行符,也会执行I/O系统调用操作,默认行缓冲区的大小为1024。
对于行缓冲有两个限制:
● 第一,因为标准IO库用来收集每一行的缓冲区的长度是固定的,所以只要填满了缓冲区,那么即使还没有写一个换行符,也进行I/O操作。
● 第二,任何时候只要通过标准I/O库要求从(a)一个不带缓冲的流(stderr),或者(b)一个行缓冲的流(它从内核请求需求数据)得到输入数据(stdin),那么就会冲洗所有行缓冲输出流(触发stdout刷新)。注:在(b)中带了一个在括号中的说明,其理由是,所需的数据可能已在该缓冲区中(如用户在终端输入了多行数据),此时它并不要求一定从内核读数据,所以只有缓冲区数据不足,需要向内核请求更多数据时才会刷新输出流。很明显,从一个不带缓冲的流中输入(即(a)项)需要从内核获得数据。
[用户程序]
↓ printf(无换行) → [行缓冲输出缓冲区]
↓ scanf(需要数据)
├─ 如果缓冲区有足够数据 → 不刷新
└─ 需要内核数据 → 刷新所有行缓冲输出流
↓
[内核]eg:
#include <stdio.h>int main() {// stdout通常是行缓冲的printf("This is a prompt"); // 无换行符,留在缓冲区int x;scanf("%d", &x); // 从行缓冲的stdin读取,且需要内核数据// 在scanf执行前,上面的printf内容会被自动刷新显示return 0; }// 假设用户在终端一次性输入了"10 20\n" int a, b; printf("Enter two numbers:"); // 无换行,留在缓冲区 scanf("%d", &a); // 从缓冲区读取10,不需要内核数据,不刷新 scanf("%d", &b); // 从缓冲区读取20,不需要内核数据,不刷新 // 此时提示信息可能仍未显示!
(4)fflush()
fflush 是 C 标准库(<stdio.h>)提供的函数,用于强制刷新(冲洗)输出流缓冲区,确保数据从用户缓冲区提交到内核缓冲区(但不一定立即写入磁盘)。
int fflush(FILE *stream);
stream:要刷新的文件流(如stdout、文件指针等)。
如果传入
NULL,则刷新所有打开的输出流(非标准,但大多数编译器支持)。成功返回
0,失败返回EOF(如流未打开或不可写)。
(5)示例说明
示例1:
我们发现编译执行下面的代码后,打印log.txt文件,只显示了write函数的打印结果,并不显示printf打印的结果。但当我们不关闭fd文件描述符时,所有内容都能正常打印出来。
#include <iostream>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>int main()
{close(1);int fd = open("log.txt", O_CREAT | O_WRONLY, 0666);if(fd == 0){perror("open error!");return 1;}printf("hello printf!\n");printf("hello printf!\n");printf("hello printf!\n");const char *msg = "hello write!\n";write(fd, msg, strlen(msg));close(fd);return 0;
}
# 编译执行代码后,打印log.txt文件,只显示了write函数的打印结果
$ cat log.txt
hello write!# 不关闭文件描述符fd,就能按我们预想的打印
$ cat log.txt
hello write!
hello printf!
hello printf!
hello printf!将1号描述符重定向到磁盘文件后,缓冲区的刷新方式变为了全缓冲。而我们写入的内容没有填满整个缓冲区,导致不会将缓冲区的内容刷新到磁盘文件中。解决方法,可以用fflush强制刷新缓冲区。
示例2:我们在代码的最后创建了子进程,当我们正常执行程序时,和预想的一样输出4行,但当我们对进程实现输出重定向呢?
#include <iostream>
#include <stdio.h>
#include <unistd.h>
#include <fcntl.h>
#include <string.h>int main()
{// 库函数printf("hello printf!\n");fprintf(stdout, "hello fprintf!\n");const char *s = "hello fwrite!\n";fwrite(s, strlen(s), 1, stdout);// 系统调用const char *msg = "hello write\n";write(1, msg, strlen(msg));// 创建子进程, 程序结束父子进程的缓冲区都会刷新fork();return 0;
}$ make
g++ -o stream stream.cc
$ ./stream
hello printf!
hello fprintf!
hello fwrite!
hello write$ ./stream > log.txt
$ cat log.txt
hello write
hello printf!
hello fprintf!
hello fwrite!
hello printf!
hello fprintf!
hello fwrite!我们发现库函数的调用都打印了两遍,而系统调用只打印了一遍。
● 一般C库函数写入文件时是全缓冲的,而写入显示器是行缓冲。
● 而执行该程序就是向显示器stdout写入,是行刷新。库函数执行完缓冲区里就没有数据了。
● printf / fwrite 库函数会自带缓冲区(进度条例子就可以说明),当发生重定向到普通文件时,数据的缓冲方式由行缓冲变成了全缓冲。
● 而我们放在缓冲区中的数据,就不会被立即刷新,甚至fork之后。
● 但是进程退出之后,会统一刷新,写入文件当中。
● 但是fork的时候,父子数据会发生写时拷贝,所以当你父进程准备刷新的时候,子进程也就有了同样的一份数据,随即产生两份数据。
● write 没有变化,说明没有所谓的缓冲。
综上:printf / fwrite 库函数会自带缓冲区,而 write 系统调用没有带缓冲区。另外,我们这里所说的缓冲区,都是用户级缓冲区。其实为了提升整机性能,OS也会提供相关内核级缓冲区,不过不再我们讨论范围之内。 那这个缓冲区谁提供呢?printf / fwrite 是库函数,write 是系统调用,库函数在系统调用的“上层”,是对系统调用的“封装”,但是write 没有缓冲区,而printf / fwrite 有,足以说明,该缓冲区是二次加上的,又因为是C,所以由C标准库提供。其实就是FILE结构体。
5、FILE
前面我们介绍了FILE结构体它们封装了底层的文件描述符fd,并添加了缓冲区和高级读写功能。我们来看看内核是如何封装(glibc)的:
struct _IO_FILE {int _flags; // 文件状态标志char* _IO_read_ptr; // 读缓冲区当前位置char* _IO_read_end; // 读缓冲区结束位置char* _IO_read_base; // 读缓冲区起始位置char* _IO_write_ptr; // 写缓冲区当前位置char* _IO_write_end; // 写缓冲区结束位置char* _IO_write_base; // 写缓冲区起始位置int _fileno; // 文件描述符int _bufsiz; // 缓冲区大小// 其他维护字段...
};6、模拟设计libc库
(1)mystdio.h
#pragma once#include<stdio.h>
#include<fcntl.h>
#include<string.h>
#include <unistd.h>
#include <stdlib.h>#define MAX 1024
// 用标记位实现刷新方式
#define NONE_FLUSH (1<<0)
#define LINE_FLUSH (1<<1)
#define FULL_FLUSH (1<<2)typedef struct IO_FILE
{int fileno;int flag;char outbuffer[MAX]; // 固定的缓冲区大小int bufferlen; // 有效元素个数int flush_method; // 刷新方式
}MYFILE;MYFILE *MyFopen(const char *path, const char *mode);
void MyFcolse(MYFILE *file);
int MyFwrite(MYFILE *file, const char *str, int len);
void MyFflush(MYFILE *file);(2)mystdio.c
#include"mystdio.h"// 申请MYFILE结构体空间
static MYFILE* BuyFlie(int fd, int flag)
{MYFILE *f = (MYFILE*)malloc(sizeof(MYFILE));if(f == NULL) return NULL;f->bufferlen = 0;f->fileno = fd;f->flag = flag;f->flush_method = LINE_FLUSH; memset(f->outbuffer, 0, sizeof(f->outbuffer)); // 缓冲区置为零return f;
}MYFILE *MyFopen(const char *path, const char *mode)
{int fd = -1;int flag = 0;if(strcmp(mode, "w") == 0){flag = O_CREAT | O_WRONLY | O_TRUNC; fd = open(path, flag, 0666);}else if(strcmp(mode, "r") == 0){flag = O_RDONLY;fd = open(path, flag, 0666);}else if(strcmp(mode, "a") == 0){flag = O_CREAT | O_WRONLY | O_APPEND; fd = open(path, flag, 0666);}else{}if(fd < 0) return NULL;return BuyFlie(fd, flag);
}// 写入的本质就是拷贝
int MyFwrite(MYFILE * file, const char *str, int len)
{// 1.拷贝memcpy(file->outbuffer + file->bufferlen, str, len);file->bufferlen += len;// 2.尝试判断是否满足刷新条件if(file->flush_method == LINE_FLUSH && file->outbuffer[file->bufferlen - 1] == '\n'){MyFflush(file);}return len;
}void MyFflush(MYFILE *file)
{if(file->bufferlen <= 0) return;// 把数据从用户空间拷贝到内核文件缓冲区int n = write(file->fileno, file->outbuffer, file->bufferlen);(void)n;// 刷新到外设fsync(file->fileno);file->bufferlen = 0;
}void MyFcolse(MYFILE *file)
{ if(file->fileno < 0) return;// 关闭文件要刷新缓冲区MyFflush(file);close(file->fileno);free(file);
}(3)usercode.c
#include "mystdio.h"int main()
{MYFILE *filep = MyFopen("log.txt", "a");if (!filep){printf("MyFopen error!\n");return 1;}// const char *msg = "hello MyFwrite\n"; // 行刷新// MyFwrite(filep, msg, strlen(msg));int cnt = 5;while (cnt--){const char *msg = "hello MyFwrite!"; // 没有'\n',不满足刷新条件,待在缓冲区MyFwrite(filep, msg, strlen(msg));// 强制刷新缓冲区MyFflush(filep);printf("buffer:%s\n", filep->outbuffer); // 打印缓冲区内容sleep(1);}MyFcolse(filep);return 0;
}(4)Makefile
code:mystdio.c usercode.cg++ -o $@ $^
.PHONY:clean
clean:rm -f code