机器学习入门-线性回归模型/损失函数/梯度下降
1. 线性回归模型
位置:第一课/week1/4.Regression Model
使用到了numpy和matplotlib这两个库,numpy用于科学计算,matplotlib用于图像绘制
numpy的使用:
创建一个numpy数组
import numpy as np
x_train = np.array([1.0,2.0])
PS:numpy数组(N维数组对象)不是Python列表,其功能更加强大,支持高效的数值运算
使用print(type(x_train))得出这个numpy数组的类型为<class 'numpy.ndarray'>
使用ndarray.shape,shape是ndarray的一个属性,用于获取数组的形状(shape),即每个维度的“大小”。
区分行向量和一行两列的矩阵
res1 = np.array([1,2,3,4])
print(res1.shape) # 向量(4,)
res2 = np.array([[1,2,3,4]])
print(res2.shape) # 矩阵-一行四列(1,4)
行向量:[1,2,3,4],表示一个行向量,没有行、列的概念,只有长度的概念。
一行两列的矩阵:[[1,2,3,4]],有行、列的概念
matplotlib的使用:
scatter()函数:用于绘制散点图
import matplotlib.pyplot as plt
x=[1,2,3]
y=[4,5,6]
plt.scatter(x,y,marker='s', c='r')
plt.show()
注意引入的是matplotlib.pyplot而不是matplotlib
pyplot是面向用户的接口,封装了底层复杂操作(如创建图形、坐标轴等)
matplotlib是顶级模块,包含全局配置、后端系统等底层工具,不直接提供绘图函数
plt.plot(x,y,c='',label='')用于绘制线
总结:
本节描绘了Linear regression线性回归模型,是监督学习中最基础的回归算法之一,核心是拟合一条直线用来最小化预测值与真实值之间的误差。
线性回归:
单变量线性回归:
y = w 0 + w 1 x y=w_0+w_1x y=w0+w1x
线性回归数学模型:
y = w 0 + w 1 x 1 + w 2 x 2 + . . . + w n x n + ε y=w_0+w_1x_1+w_2x_2+...+w_nx_n+\varepsilon y=w0+w1x1+w2x2+...+wnxn+ε
2. 损失函数
线性回归的损失函数通常选用**最小化均方误差(MSE,Mean Squared Error)**来优化模型参数:
M S E = 1 m ∑ i = 1 m ( y i − y i ^ ) 2 MSE=\frac{1}{m}\sum_{i=1}^m(y_i-\hat{y_i})^2 MSE=m1i=1∑m(yi−yi^)2
- m:样本数量
- y i y_i yi:第 i i i个样本的真实值
- y i ^ \hat{y_i} yi^:第 i i i个样本的预测值
目标是最小化MSE,找到最优的 w w w(权重)和 w 0 w_0 w0(截距)
3. 可视化代价函数
两个例子
例子一:
使用 f w ( x ) = w x f_w(x)=wx fw(x)=wx然后训练集的数据是 ( 1 , 1 ) , ( 2 , 2 ) , ( 3 , 3 ) (1,1),(2,2),(3,3) (1,1),(2,2),(3,3),目的是通过代价函数找到合适的 w w w。
使用的代价函数:
J ( w ) = 1 2 m ∑ i = 1 m ( y − y ^ ) 2 = 1 2 m ∑ i m ( f w ( x ) − y ^ ) 2 = 1 2 m ∑ i m ( w x − y ^ ) 2 J(w)=\frac{1}{2m}\sum_{i=1}^{m}(y-\hat{y})^2=\frac{1}{2m}\sum_{i}^{m}(f_w(x)-\hat{y})^2=\frac{1}{2m}\sum_{i}^{m}(wx-\hat{y})^2 J(w)=2m1i=1∑m(y−y^)2=2m1i∑m(fw(x)−y^)2=2m1i∑m(wx−y^)2
注意看,代价函数只与w有关,与x无关!
步骤是令w为一个常数, f w ( x ) f_w(x) fw(x)就变成了关于x的函数(w是一个常数)。
然后针对每一个可能的w的值,绘制 f w ( x ) f_w(x) fw(x)和 J ( w ) J(w) J(w)的函数图像。
J ( w ) J(w) J(w)表示的是预测值与真实值之间的"距离",所以找到 J ( x ) J(x) J(x)中最接近0的点就是最优的m值。
例子二:
将例子一的 f w ( x ) = w x f_w(x)=wx fw(x)=wx换成 f w , b ( x ) = w x + b f_{w,b}(x)=wx+b fw,b(x)=wx+b,这时候 J ( w ) J(w) J(w)就变成了 J ( w , b ) J(w,b) J(w,b),此时代价函数的函数图像是一个三维图像,x轴和y轴表示w和b的值,z轴表示代价函数的值,也就是预测值与真实值之间的"距离"。
此处代价函数的图像像是一个"碗"
找到与0最接近的点,就是最佳的w和b。
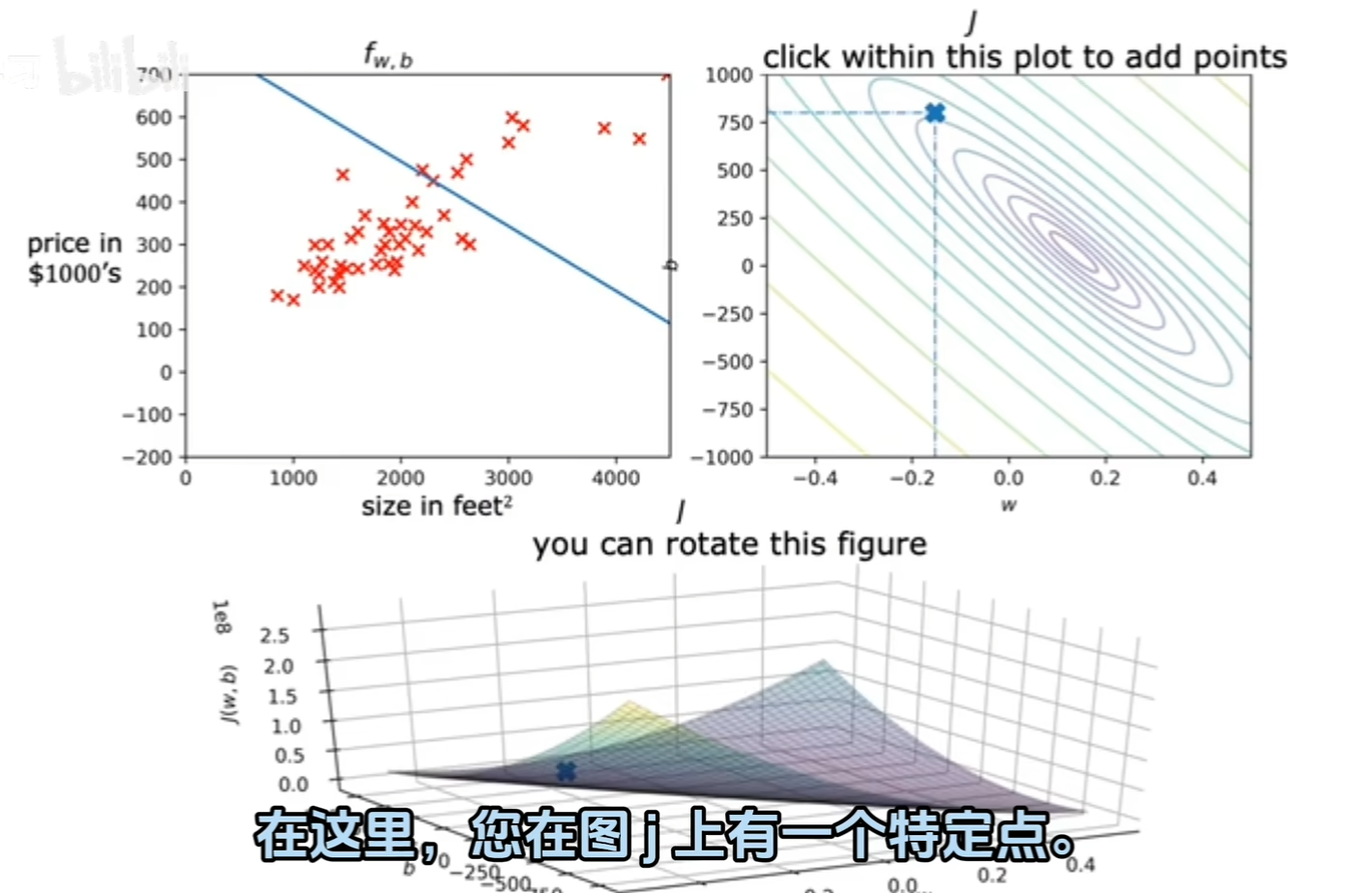
模型调优是根据损失函数来的。想办法在损失函数的函数图像上找到“代价”最小的点,这个点所对应的参数值就是模型最优的参数或拟合度最高的模型。
为了找到这个拟合度最高的参数,需要使用—梯度下降?
4. 梯度下降 gradient descent
-
为参数选择合适的起始值,作为函数图像上的起始点。
-
不同的初始化参数,可能会以不同的局部最小值结束,
但是凸函数是个碗型,除了一个全局最小值外没有其他最小值,so…
-
-
开始执行梯度下降算法,梯度算法会实现从起始点,360°找一个“坡度最陡”的“方向”
- 为什么选择“坡度最陡”?
- 因为坡度最陡,相同条件下,最快到达”低谷“。ps:"低谷"表示代价最低的点,该点所对应的参数值最优
- 为什么选择“坡度最陡”?
-
重复2.,直到函数收敛
梯度下降算法(正确的):
t e m p _ w = w − α ∗ ∂ J ( w , b ) ∂ w t e m p _ b = b − α ∗ ∂ J ( w , b ) ∂ b w = t e m p _ w b = t e m p _ b temp\_w = w - \alpha*\frac{\partial J(w,b)}{\partial w }\\ temp\_b = b - \alpha*\frac{\partial J(w,b)}{\partial b }\\ w = temp\_w\\ b = temp\_b temp_w=w−α∗∂w∂J(w,b)temp_b=b−α∗∂b∂J(w,b)w=temp_wb=temp_b
梯度下降算法强调同时更新(Simultaneous update),即在计算新 w w w和新 b b b时都是基于旧的 w w w和 b b b,
w 和 b 的更新互不干扰,逻辑上等价于“同时”完成。
这就要求使用 t e m p _ w temp\_w temp_w来暂存新的 w w w,如果直接赋值,那么在计算新 b b b时就会导致”新 b b b基于新 w w w,新 w w w基于旧 b b b“的问题。
那是不是可以这样:
t e m p _ w = w − α ∗ ∂ J ( w , b ) ∂ w b = b − α ∗ ∂ J ( w , b ) ∂ b w = t e m p _ w temp\_w = w - \alpha*\frac{\partial J(w,b)}{\partial w }\\ b = b - \alpha*\frac{\partial J(w,b)}{\partial b }\\ w = temp\_w\\ temp_w=w−α∗∂w∂J(w,b)b=b−α∗∂b∂J(w,b)w=temp_w
询问deepseek之后得知是正确的。
再说梯度下降算法中的参数 α \alpha α,名字叫做学习率(Learning rate),在通过梯度下降找最优参数的时候,偏导数确定方向,学习率确定跨幅,学习率是0~1之间的一个数,太小或者太大都会出现问题,所以有相关的自适应学习率算法
Batch Gradient Descent 批量梯度下降:通过每次迭代使用全部训练数据计算梯度来更新模型参数
求偏导:
∂ J ( w , b ) ∂ w = ∂ 1 2 m ∑ i = 1 m ( y i ^ − y i ) 2 ∂ w = ∂ 1 2 m ∑ i = 1 m [ ( w x i + b ) − y i ] 2 ∂ w = 1 2 m ∗ ∑ i = 1 m ∗ 2 ( w x i − y i ) ∗ x i = 1 m ∗ ∑ i = 1 m ( w x i − y i ) ∗ x i \frac{\partial J(w,b)}{\partial w} = \frac{\partial \frac{1}{2m}\sum_{i=1}^m(\hat{y_i}-y_i)^2}{\partial w} \\=\frac{\partial \frac{1}{2m}\sum_{i=1}^m[(wx_i+b)-y_i]^2}{\partial w} \\=\frac{1}{2m}*\sum_{i=1}^m*2(wx_i-y_i)*x_i \\=\frac{1}{m}*\sum_{i=1}^m(wx_i-y_i)*x_i ∂w∂J(w,b)=∂w∂2m1∑i=1m(yi^−yi)2=∂w∂2m1∑i=1m[(wxi+b)−yi]2=2m1∗i=1∑m∗2(wxi−yi)∗xi=m1∗i=1∑m(wxi−yi)∗xi