Cycleresearcher:通过自动化评审改进自动化研究
1、引言
迄今为止,整个科学发现过程自动化的挑战在很大程度上仍未解决,特别是在生成和改进符合同行评审工作高标准的研究成果方面。此外,很少有工作涉及迭代反馈的整合,这对保持学术的健全性和新奇至关重要。当前的模型往往难以适应整个研究阶段,突出了它们在进行全面、多步骤科学发现的能力方面的差距。
科学过程的核心是提交、同行评审和改进的迭代循环–这是一种维持学术工作质量和完整性的既定机制。来自审稿人和同行的反馈在这一周期中发挥着关键作用,提供了有助于研究人员改进工作并提高其严谨性和影响力的见解。从这一循环过程中得到启发,我们提出了一个新的框架,后训练作为自治代理的LLMs,以模拟科学发现过程的完整循环。我们的方法完全建立在开源模型的基础上,旨在复制研究开发和同行评审流程的真实动态。通过利用可训练模型,我们能够利用迭代偏好训练机制通过强化学习使用抽样示例。我们的目标是确定法学硕士是否能积极地为科学探究的每个阶段做出贡献,从文献综述和想法产生到实验设计、手稿准备、同行评议和论文提炼。
自动化整个研究生命周期,“Oberg等人(2022)对当前基于代理的方法提出了重大挑战(Lu等人,2024年; Si等人,2024年; Yang等人,2024 b),主要依赖于商业模式。因此,这些方法不能有效地建模为使用强化学习的策略优化问题。虽然自校正方法(Weng等人,2023; Yuan等人,2024年; Lee等人,2024)已经开发,以提高推理性能通过评估的质量ofLLM结果,他们还没有被采用的论文写作领域,这需要从多个角度更复杂的评估。我们的研究通过引入迭代后训练框架来解决这一差距。我们提出的中心研究问题是:“我们如何通过培训后的LLM自动化研究-审查-细化过程?”因此,可以根据自动化评论的反馈来改进自动化研究。
我们建立了一个新的迭代训练框架(Pang et al.,2024),包含两个核心组件:政策模型(即CycleResearcher)和奖励模型(即CycleReviewer),大小范围从12 B到123 B,基于Mistral(Jiang等人,2023)和Qwen 2.5(Yang等人,2024a;在我们的框架中,CycleResearcher充当科学思想家,负责阅读文献,识别研究问题,提出解决方案和设计实验,而具体的实验执行则委托给专门的代码模型。特别是,政策模型执行各种研究任务.用于纸张生成1.另一方面,奖励模型模拟同行评审过程,评估研究成果的质量,并提供反馈,为强化学习奖励提供信息。在虚拟RL环境中,为了加速训练,我们需要制作实验结果,而不是进行实际实验。
为了说明我们的框架的操作,在探索“VLM的黑客奖励”这个话题时,我们首先给微调过的CycleResearcher提供了一组相关的已发表论文,以激发它提出新颖的想法。在生成一批与这些想法相对应的第一轮论文后,微调的CycleReviewer对其进行评估,以生成成对偏好样本,这些样本用于使用SimPO优化策略模型(Meng et al.,#20240;,这一过程不断重复。
为了训练我们的模型,我们构建了两个大规模的、公开可用的数据集:Review-5 k和Research-14 k(在第2节中描述),其中包含来自主要ML会议的同行评审和公认论文(例如,ICLR、ICML、NeurIPS)。在测试中,我们采用了主观的人工评价和基于模型的客观评价来评估CycleReviewer和CycleResearcher的质量。我们的实验表明,与基于API的代理相比,CycleReviewer在支持同行评审过程方面表现出了有前途的能力,而CycleResearcher在研究构思和实验设计方面表现出了一致的性能(Lu等人,2024年)的报告。我们也承认,跨研究领域的可推广性仍然是当前法学硕士面临的挑战。我们的贡献可概括为:
- 我们引入了一个迭代强化学习框架,可以自动化整个研究生命周期,这反映了现实世界的研究-审查-改进周期。我们的框架包括CycleResearcher,一个研究任务的政策模型,和CycleReviewer,一个模拟同行评议的奖励模型。该框架使大型语言模型(LLM)能够通过研究-审查-改进周期迭代地改进研究成果。
- 我们发布了两个大规模数据集,Review-5 k和Research-14 k,它们是公开的,旨在捕捉机器学习中同行评审和研究论文生成的复杂性。这些数据集为评估和训练学术论文生成和评论中的模型提供了宝贵的资源。
- 我们证明了CycleResearcher模型可以生成平均质量水平接近人类书面预印本的论文,达到31.07%的接受率。此外,我们的CycleReviewer模型显示了令人鼓舞的结果,与单个评审员相比,MAE提高了26.89%,这表明自动化研究评估在研究评估任务中的平均绝对误差(MAE)方面具有潜力,为自动化研究评估设定了新的基准。
注意:
我们目前的实现将实验执行委托给代码生成模型,使CycleResearcher能够专注于高级研究规划和分析。值得注意的是,CycleResearcher在这项工作中产生的实验结果是捏造的,并不代表真实的实验数据。
2、数据集构建
在本节中,我们将概述如何收集大量学术论文语料库并将其组织到Review-5 k和Research-14 k训练数据集中。如图1所示,我们引入了结构化的大纲提取和分割,以帮助LLM在生成研究论文之前进行规划。值得注意的是,我们将只公开那些获得出版商书面同意的论文的数据集(见附录C)。
2.1 REVIEW-5K
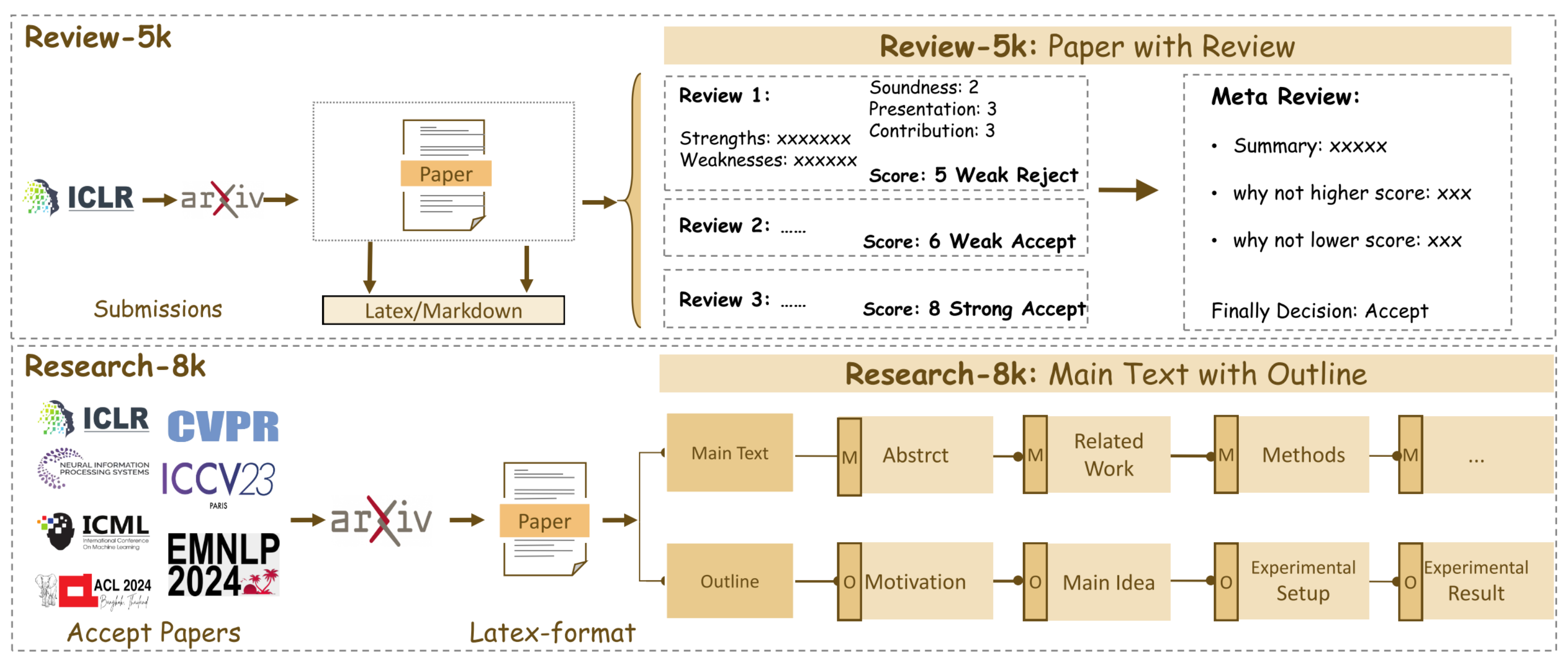
图1:Research-14 k数据集和Review-5 k数据集的数据构建管道。Review-8 k数据集包括研究论文的正文(M)和大纲(O),涵盖了动机、方法、实验设置和结果等关键组成部分。Research-5 k数据集为每篇论文提供3篇综述和1篇荟萃综述
为了收集高质量的综述数据集,我们首先收集论文信息(包括标题、摘要和PDF数据)沿着ICLR 2024的相应综述评论。这确保了所有的论文都按照一致的标准进行评估。然后,我们尝试从ArXiv检索允许的LaTeX文件。如果LaTeX文件不可用,我们使用MagicDoc将检索到的PDF转换为markdown格式。然后,受传统同行评审流程的启发,一组评审员评估论文,然后由高级评审员综合他们的反馈并做出最终决定,我们收集每个数据点,包括关键组件:1)工作总结,2)确定的优势和劣势,3)需要澄清的问题,沿着4)健全性、演示、贡献的数字评分,和总体评级。最后,我们留下了一个名为Review-5 k的数据集,包含从ICLR 2024收集的4,991篇论文,包括超过16,000条评论。最后,我们将数据集分成相互排斥的训练/测试集,我们保留了4,189篇论文评论用于训练,782个样本用于测试。
2.2 RESEARCH-14K
research-14 k数据集旨在从学术论文中捕获结构化的大纲和详细的主要文本。数据构建过程包括三个步骤:(1)。我们首先汇编了2022年至2024年期间主要国际机器学习会议(如ICLR、NeurIPS、ICML、ACL、EMNLP、CVPR和ICCV)的已接受论文列表。使用Semantic Scholar 2,我们检索了每篇论文相应的ArXiv链接和LaTeX格式文件,共收集了14,911篇论文。然后,使用基于规则的过滤对这些论文的正文进行预处理,以删除不相关的内容,如评论(“%”)和注释。(二)、由于学术论文的学术价值取决于其背景,我们也使用语义学者API从bib文件中检索被引用的作品,并将其摘要添加到其中。最后,我们将每篇论文的主体组织成大纲和单独的部分,以帮助模型更好地理解研究过程。我们使用Mistral-Large-2模型(Jiang等人,2023)从论文中提取大纲信息,遵循图1所示的大纲结构,并将每个大纲与其相应的部分连接起来。这些组件构成了完整的微调数据集,其中输入包括详细的参考文件,输出包含论文大纲和正文。
在过滤掉不符合要求的论文后,最终的数据集Research-14 k包括12,696个训练样本和802个测试样本。它涵盖了过去三年中几乎所有重要的机器学习论文,并确保所有收集的论文都是开放获取的。训练集和测试集按时间顺序划分,测试论文比训练论文晚发布。该数据集用于监督微调,使LLM能够生成结构良好的学术论文。此外,Research-14 k是一个长输出数据集,平均输出长度为28 K。
3、迭代式培训框架
我们使用迭代的简单偏好优化(SimPO)(孟等人,2024)框架来复制学术研究中典型的研究-评论-改进周期。正如引言中提到的,我们主要关注思想的发展和写作过程,而实际实验的执行(Liu et al., 2024b;朱周,2024;Hu et al., 2025)超出了本工作的范围。这个过程从初始化两个模型开始:一个是为学术写作微调的基线语言模型(CycleResearcher),一个是专门评估研究论文的大型语言模型(CycleReviewer)。
如图2所示,每次迭代包括两个主要阶段:(1)CycleResearcher模型模拟关键的研究步骤,包括文献综述、假设制定、实验设计和论文写作,最终产生一篇学术论文。(2)随后,CycleReviewer模型基于生成的论文模拟同行评议过程,提供全面反馈和定量评分。为了促进迭代改进,我们在每一轮之后实现重新抽样过程,根据论文分数生成新的偏好数据,然后利用这些数据为后续迭代训练模型。
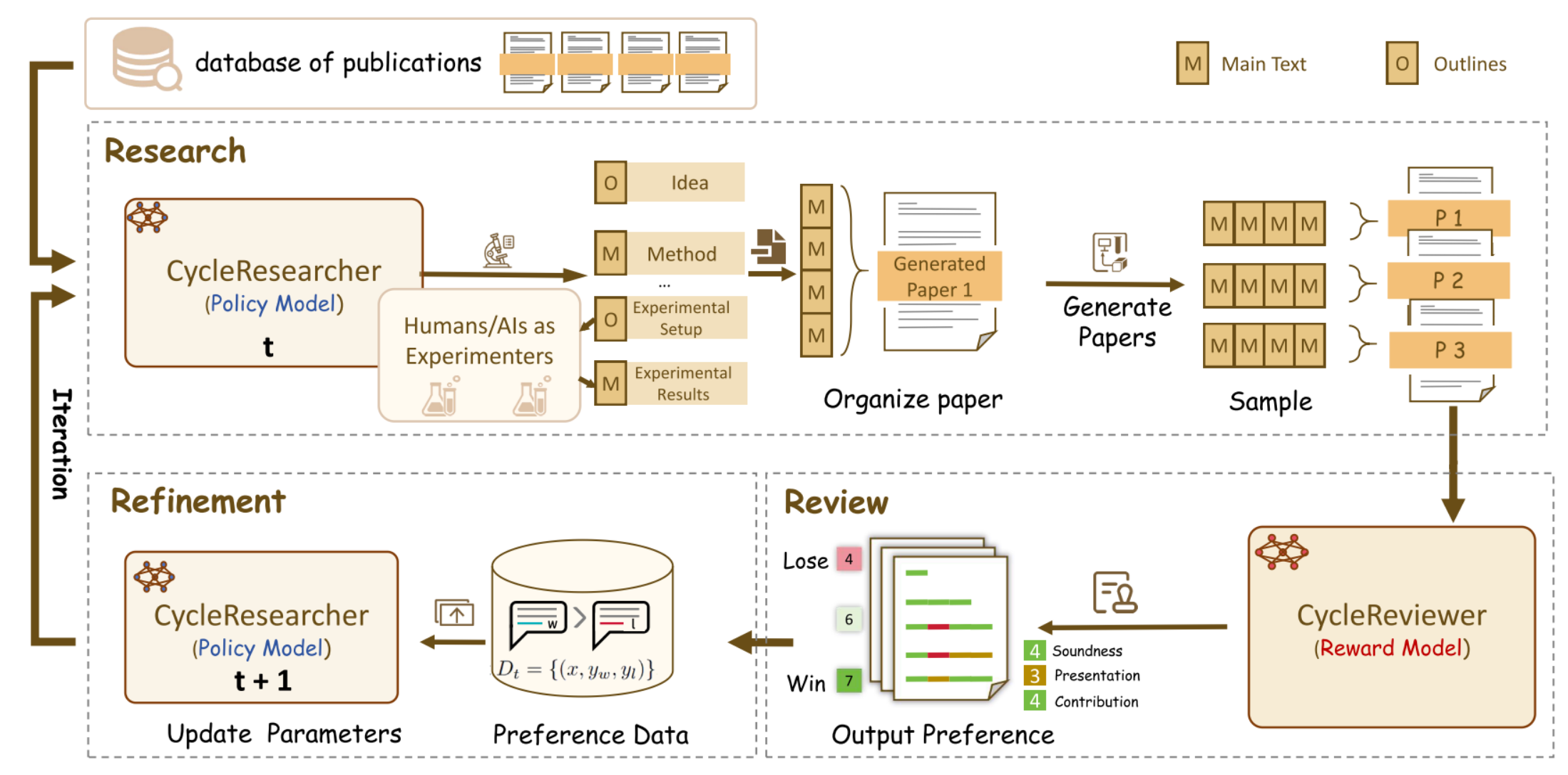
图2:迭代训练框架。CycleResearcher模型生成大纲(O)和主要文本(M)来组织论文,由CycleReviewer进行评估,并根据奖励构建成偏好对。然后迭代地改进整个过程,每次迭代都会逐步提高研究能力。
3.1 奖励模型:CYCLEREVIEWER
我们在Review-5 k数据集上训练CycleReviewer作为生成奖励模型。为了准确反映学术同行评审过程,我们建立了一个简化的评估工作流程:
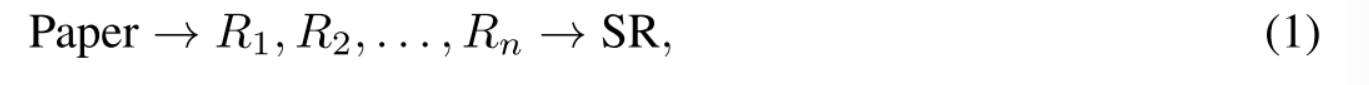
其中研究论文(论文)由多个审稿人(R1, R2,…)审阅。, Rn)。每个审稿人的意见然后由高级审稿人(SR)总结,形成最终决定。
CycleReviewer模型的输入是一篇完整的研究论文。在收到论文后,模型为关键方面生成连续的反馈和分数,包括优势,劣势,可靠性,演示,贡献和总体得分。总体得分从1到10打分,其中1分代表最低分,10分代表最高分,5分表示论文处于被拒绝的边缘,6分表示接近被接受。模型的输出包括总体得分和标记为“最终建议”的建议。CycleReviewer模拟跨多个审阅者的审阅过程,生成一组Overall Scores。最后的输出是这些分数的平均值,代表系统对论文的总体评价。
实验设置:
我们在一个8 × H100 80G的集群上使用带有LoRA-GA的Mistral-Large-2模型(Wang et al., 2024a),学习率为1e-5,批处理大小为4x8,在Reviewer-5k数据集上进行了12次epoch。为了确保生成的评论的多样性,CycleReviewer首先模拟评分最低的审稿人的反馈,逐渐发展到评分最高的审稿人。这种方法确保在高级审稿人交付最终评估之前,考虑了从更关键到更有利的一系列观点。
3.2 POLICY MODEL: CYCLERESEARCHER
CycleResearcher模型在Research-14k上进行训练,该过程从文献综述开始,其中输入的bib文件包含所有参考文献及其相应的摘要。在对研究背景有了全面的了解后,模型开始进行手稿准备。在这个阶段,生成大纲和主要文本交替以确保逻辑流。首先,该模型在大纲中生成动机和主要思想,然后在正文中生成标题、摘要、介绍和方法部分。接下来,它概述了实验设置和结果,随后在正文中生成实验设计和模拟结果,其中还包含了讨论。在虚拟RL环境中,为了加速训练,我们要求“实验结果”是虚构的,而不是进行实际的实验。最后,对实验结果进行分析,得出结论。一旦生成了主要文本的所有部分,它们就会以LaTeX格式组合成一篇完整的论文。值得注意的是,research -14k中研究论文的每个部分都是精确分割的。最后,使用CycleReviewer对生成的论文P进行评估,如第3.1节所述。
实验设置:
为了构建策略模型,我们选择了广泛使用的开源大型语言模型: Mistral-Nemo-12B、qwen2.5 - directive - 72b和Mistral-Large-2 123B。所有模型都使用8倍H100 gpu和DeepSpeed + ZeRO2进行训练(Rajbhandari等人,2020;Rasley et al., 2020)。我们通过将12B模型设置为32K令牌来最大化上下文长度,而将72B和123B模型设置为24K令牌。给定内存约束,超过预设上下文长度的样本将被随机截断。我们使用的批处理大小为2×8,学习率为4e−5,总共训练了12,000步。这些模型支持高达128K令牌的上下文窗口,使其适合规划研究项目和撰写研究论文。作为回应,我们提供了三个版本的政策模型:cyclerresearcher - 12b、cyclerresearcher - 72b和cyclerresearcher - 123b。在强化学习阶段,我们使用了5e-7的学习率。对于12B模型,我们使用了18K的文本长度,而对于72B和123B模型,最大文本长度为10K,并从末尾进行截断。每次迭代使用采样获得的数据训练一个历元。
为了构建策略模型,我们选择了广泛使用的开源大型语言模型: Mistral-Nemo-12B、qwen2.5 - directive - 72b和Mistral-Large-2 123B。所有模型都使用8倍H100 gpu和DeepSpeed + ZeRO2进行训练(Rajbhandari等人,2020;Rasley et al., 2020)。我们通过将12B模型设置为32K令牌来最大化上下文长度,而将72B和123B模型设置为24K令牌。给定内存约束,超过预设上下文长度的样本将被随机截断。我们使用的批处理大小为2×8,学习率为4e−5,总共训练了12,000步。这些模型支持高达128K令牌的上下文窗口,使其适合规划研究项目和撰写研究论文。作为回应,我们提供了三个版本的政策模型:cyclerresearcher - 12b、cyclerresearcher - 72b和cyclerresearcher - 123b。在强化学习阶段,我们使用了5e-7的学习率。对于12B模型,我们使用了18K的文本长度,而对于72B和123B模型,最大文本长度为10K,并从末尾进行截断。每次迭代使用采样获得的数据训练一个历元。
3.3 ITERATIVE SIMPO
我们设计了迭代偏好优化对齐方法(Xiong等人,2024; Liu等人,2024 a),其模拟同行评审过程作为奖励机制。为了构建一个偏好对数据集,我们首先收集了arXiv上最近发表的4,152篇机器学习论文,只保留参考部分作为知识库。然后,我们从温度为0.4的CycleResearcher中采样三次,并将结果处理为标准的LaTeX风格文本M1,M2,M3。接下来,CycleReviewer模型模拟了多位评审员之间的讨论,提供了对论文各个方面的详细评估(例如,新奇、方法、实验设计、结果分析)。将所有模拟评审员的平均得分ri分配给每个输出Mi。然后,我们选择具有最高奖励值的输出作为正样本yw,具有最低奖励值的输出作为负样本yl,形成偏好对数据集D 0 =(x,yw,yl)。
Policy Optimization:我们没有使用迭代DPO训练框架(Pang et al., 2024),而是采用SimPO作为节省计算成本的基本方法。为了减轻过拟合,我们在每轮中对完整数据集的三分之一进行采样。然后,我们生成了一系列模型P1,…。,其中每个模型PT +1都是使用模型PT生成的偏好数据Dt来创建的。使用偏好对数据集,我们从PT到PT +1训练了一个新的策略模型πθ。P1是使用指令调优从原始的微调过的CycleResearcher模型初始化的。
SimPO建立在DPO (Rafailov et al., 2023)的基础上,DPO是最常见的离线偏好优化方法之一。该算法引入了与生成目标对齐的长度归一化奖励函数,从而消除了对参考模型πref的依赖,降低了内存和计算需求。
考虑到研究过程中使用的模型可能涉及复杂的推理和数学计算,我们将从偏好对中学习到的SimPO损失与负对数似然(NLL)损失结合起来,以稳定训练(Pang et al., 2024)。
3.4维护学术诚信
除了自动化研究过程,我们也关心维护学术诚信。我们的目标是防止大型语言模型在研究界的滥用。为了实现这一点,我们采用了Fast-DetectGPT (Bao等人,2024),该方法旨在使用条件概率曲率的度量来确定论文提交是否由大型语言模型生成。具体来说,我们使用Llama-3-8B (Dubey et al., 2024)作为评分模型,并通过比较条件概率曲率与预定义阈值λ来确定论文是否由大型语言模型生成。如果论文的曲率大于阈值,我们将论文分类为llm生成的,否则为人类编写的。
4、 实验
4.1 论文评审生成实验
评估指标。评估审稿人的表现本质上是困难的,因为提交的真实质量是未知的。为了解决这一挑战,我们使用代理均方误差(Proxy Mean Squared Error, MSE)和代理平均绝对误差(Proxy Mean Absolute Error, MAE)来评估单个评论分数的准确性(Su et al., 2024),详见附录E。对于每篇论文,评论分数r的常规MSE和MAE被定义为E (r -真实值)2和E [|r -真实值|]。由于未知的真实质量,它们是无法观察到的。因此,我们引入了一种代理评估方法,使用独立,无偏估计器作为真实值分数的替代。假设我们有n个人类专家,得分R = r1, r2,…, rn,我们将每个审稿人的分数ri作为真实质量的无偏估计值。我们定义r ’ i = mean(r \ ri),它是一个不含ri的无偏估计量。因此,我们使用Proxy MSE = (ri - r ’ i)2和Proxy MAE = |ri - r ’ i|来衡量ri的质量。简单地说,对于每个提交,我们使用其他n - 1评论者分数的平均值作为真实分数的估计值。
我们对review -5k测试集的评估(平均评分5.53)使用这种代理方法进行公平比较。在n−1模式中,我们随机选择一个审稿人,并使用剩余分数的平均值作为代理真实值。我们将这种方法应用于评估人类专家和闭源模型,包括AI科学家审查系统(Lu等人,2024),具有一次性审查,自我反思(Shinn等人,2023)和集成审查。
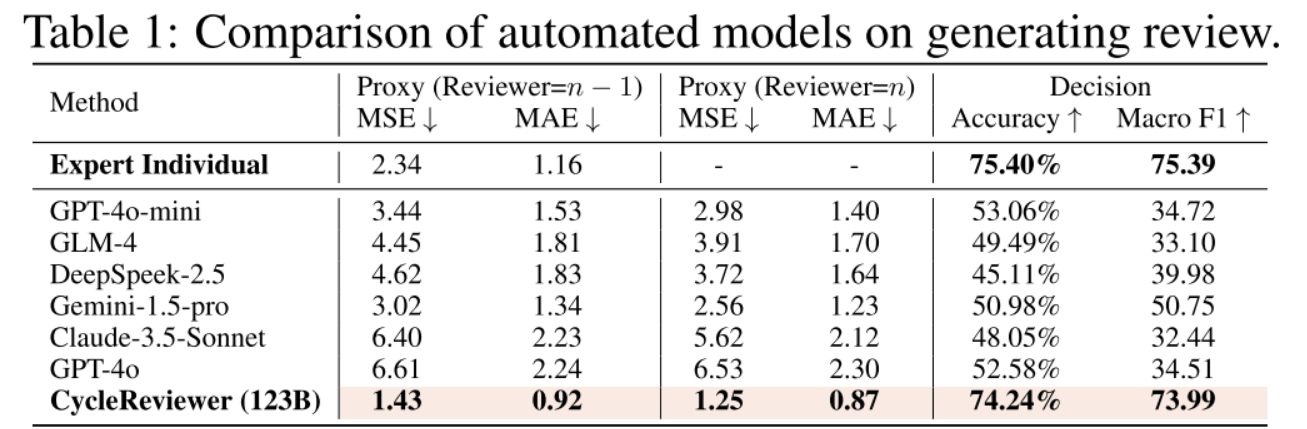
CycleReviewer引入了更高质量的审查。表1给出了不同模型之间的性能比较。与专有系统和个人审稿人相比,CycleReviewer在同行评审任务中展示了令人鼓舞的结果。我们的模型显示,与单个评论者的分数相比,Proxy MSE降低了48.77%,Proxy MAE降低了26.89%。这些指标表明,CycleReviewer可以提供一致的评分,以补充人类的专业知识。该模型的决策准确率为74.24%,与其他闭源系统相比具有竞争力。这些结果表明,我们的模型可以提供一致的评分,补充人类的专业知识,在生成可靠的评估分数方面显示出比AI科学家系统(Lu et al., 2024)的潜在优势。然而,我们强调,这些指标关注的是分数的一致性,而不是捕捉专家审查的全部复杂性,在那里,人类的洞察力仍然是无价的。
4.2研究生命周期模拟的重要性
表2:CycleReviewer对一系列论文的评价结果。这些分数的范围是1-10。CycleReviewer模拟了一组审阅者,我们报告最低Overall score的平均分数,最高Overall score的平均分数,以及总体平均分数。†表示所有这些论文实际上都被接受发表。
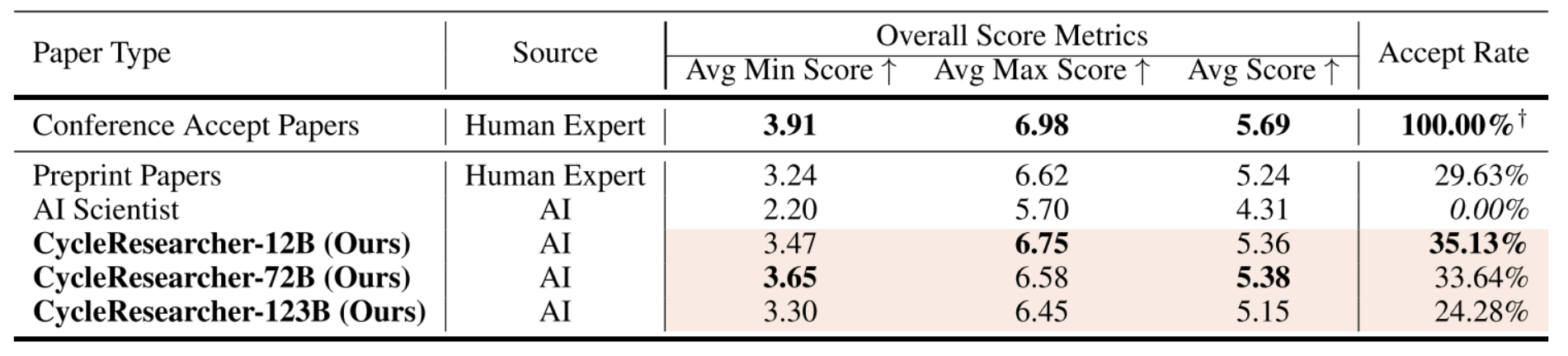
表2展示了CycleResearcher的结果,它模拟了一个项目委员会的审查过程,在整个分数范围内评估论文,并最终根据模拟的审查提供最终的接受决定。我们报告得分最低的审稿人、得分最高的审稿人的平均得分,以及总体得分。对于被接受的论文,我们使用Research-14k的测试集,其中所有的论文都已经被接受,作为人类专家标准的基准。对于预印本论文,我们评估了arXiv(2024年9月)在cs领域提交的955篇论文。ML, cs。CV和cs.LG。此外,我们用gpt - 40和Claude-3.5生成的10篇研究论文集合来评估AI科学家。
表3:CycleReviewer通过三个标准对论文的评价结果:稳定期、陈述和贡献。这些分数的范围是1-4。

在自动审查指标方面,CycleResearcher始终比AI Scientist表现得更好。从表2可以看出,cyclerresearcher - 12b的平均分为5.36,接近会议论文平均分5.69,超过了AI Scientist的4.31分。值得注意的是,它的接受率达到了35.13%,明显高于AI Scientist的0%接受率,显示出其产生研究质量输出的卓越能力。
在稳健性、呈现性和贡献性方面的比较进一步说明了CycleResearcher的优势。“cyclerearcher - 12b”的平均稳健性得分为2.71分,超过了“AI Scientist”(ggt - 40)的2.48分,与接受论文的2.83分非常接近。在陈述和贡献方面,它的平均得分分别为2.70分和2.60分,超过了AI Scientist的得分(2.69分和2.15分)。相比之下,AI Scientist显示出明显的局限性,特别是在稳健性(1.20)和贡献(1.30)的最低分数上,这表明生产高质量研究的一致性较差。与AI Scientist相比,我们的模型表现出更高的可靠性,在所有指标上的最低得分都更高(稳健性:1.73,呈现性:1.91,贡献:1.68)。这些结果强调了我们的模型在应对确保人工智能生成研究的质量和一致性的挑战方面的有效性。
根据图3中的自动评审度量,拒绝抽样提高了生成论文的质量。拒绝抽样在学术论文生成的背景下特别有价值,与其他研究阶段相比,使用语言模型制作研究计划和论文的成本相对较低。随着论文数量从1篇增加到100篇,平均分数从5.36分左右上升到7.02分,超过了预印本论文(5.24分)和接受论文(5.69分)。平均最高分从6.72提高到8.02,平均最高分从3.52大幅提高到6.01,均超过了预印本基准。这些发现表明,更大的样本量使模型能够始终如一地生成更高质量的研究论文,使拒绝抽样成为一种有效的策略,可以在稳健性、呈现性和贡献方面提高整体论文质量。
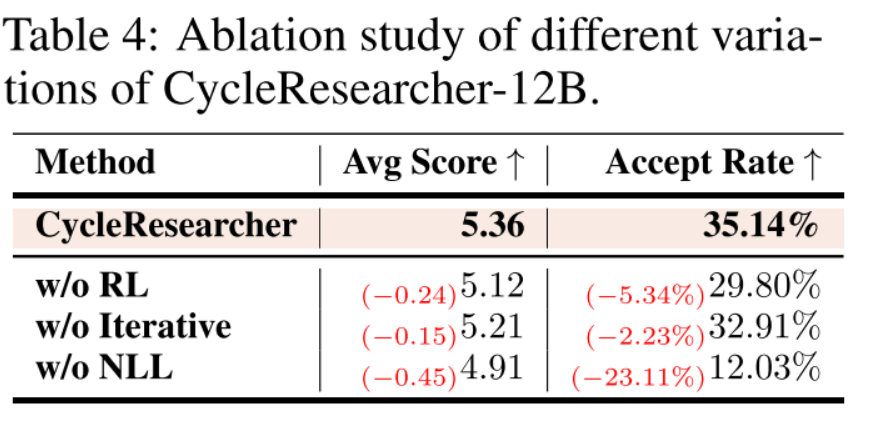
消融研究见表4。当去除了强化学习,只留下有监督训练的初始版本时,平均得分下降到5.12,接受率为29.80%。去掉迭代训练过程,得分为5.21分,接受率略高,为32.91%。当负对数似然(NLL)损失被去除时,结果显着降低。这导致了文本生成重复、生成内容错误严重等问题,平均分急剧下降到4.91分,录取率急剧下降到12.03%。这些结果突出了RL、迭代训练和NLL在维护自动评审指标方面生成的研究论文的质量和稳定性方面的重要性。克服这些挑战对于开发能够生成在自动评审中表现良好的学术内容的鲁棒的模型至关重要。
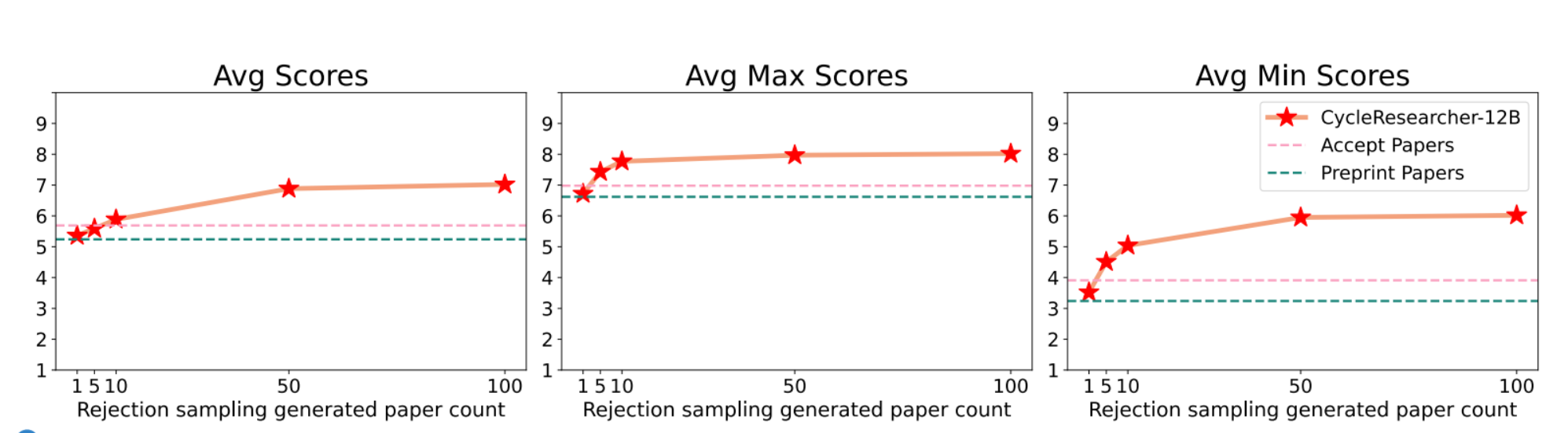
图3:通过在生成的论文中进行拒绝抽样来提高性能。图表显示了来自CycleResearcher-12B的不同数量的生成论文(1、5、10、50、100)的平均、最大和最小分数。红星代表生成论文的性能,随着样本数量的增加,表现出一致的改进。
4.3 HUMAN EVALUATION
为了严格验证CycleResearcher的表现,我们进行了一项涉及三位NLP专家的人体评估研究。这些专家,每个都有很强的发表记录(平均1110亿次学者引用)和作为顶级NLP会议审稿人的经验,被招募来完成这项任务。为了确保相关性和基于专业知识的评估,我们为每位审稿人精心选择了与其研究兴趣密切相关的论文。在评估之前,所有论文都从PDF转换为Markdown格式,并手动检查以解决格式问题(例如,图/表布局)。至关重要的是,所有识别作者的信息都是匿名的,只向审稿人提供每篇论文的主要文本。然后,每位专家总共评估了20篇论文:10篇由CycleResearcher-12B生成(使用N=100拒绝抽样),10篇由AI Scientist生成(有50个初始想法和3次改进迭代)。评估过程持续了一周,在此期间,审稿人被要求严格遵守ICLR 2024审查指南。我们明确要求他们根据标准的学术标准来评估论文,包括可靠性、展示和贡献,并为每篇论文提供详细的评论和分数。此外,我们特别指示审稿人批判性地评估每篇论文的实验设计和方法,并标记他们发现的任何潜在缺陷或不一致之处。如表5所示,人类评估分数表明,CycleResearcher在所有测量维度上都优于AI Scientist(平均总分4.8比3.6)。然而,CycleResearcher的表现仍然低于ICLR 2024投稿(5.54分)和被接受论文(6.44分)的平均得分,表明其还有进一步提高的空间。尽管如此,结果表明在自动化研究论文生成方面取得了有意义的进展,与基线系统相比,CycleResearcher在呈现性(2.8)和可靠性(2.6)方面表现出了特别的优势。
4.4道德保障
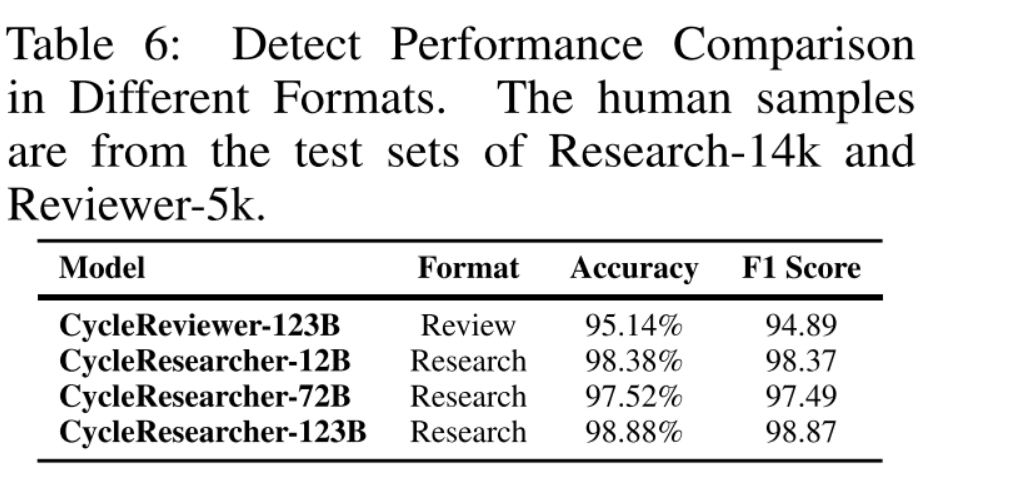
为了确保我们的模型得到负责任的使用,我们实现了Fast-DetectGPT方法来分类一篇论文是否是机器生成的。表6显示了我们的检测工具在不同格式下的性能,对审查内容的准确率超过95%,对纸质文本的准确率接近99%。这确保了CycleResearcher或CycleReviewer生成的任何输出都可以被准确识别,从而保护了研究社区的完整性。
5、结论
在本文中,我们介绍了一个使用大型语言模型(大型语言模型)自动化整个研究生命周期的新框架。我们的方法结合了旨在自主开展科学研究的政策模型CycleResearcher和模拟同行评议过程的奖励模型CycleReviewer。通过集成迭代SimPO,我们使模型能够在多个研究-审查-改进周期中自我改进。为了促进这一点,我们构建了两个新的数据集,review -5k和research -14k,它们捕捉了机器学习中同行评审和研究论文写作的复杂性。与评估的闭源模型相比,CycleReviewer显示出更高的评分一致性,而CycleResearcher在模拟评审中生成接近人类预印本质量的论文,具有竞争力的接受率。这些结果表明,使用大型语言模型对科学发现和同行评审过程都有意义的贡献是可行的。随着我们的发展,大型语言模型改变研究实践的潜力是巨大的。我们希望这项工作能激发对人工智能如何帮助研究人员的进一步研究,同时保持最高的学术诚信和道德责任标准。