数据结构——快排和归并排序(非递归)
快速排序和归并排序一般都是用递归来实现的,但是掌握非递归也是很重要的,说不定在面试的时候面试官突然问你快排或者归并非递归实现,递归有时候并不好,在数据量非常大的时候效率就不好,但是使用非递归结果就不一样了,总之各有各的好。
目录
快速排序非递归实现
归并排序非递归实现
计数排序
快速排序非递归实现
要实现快排的非递归需要借助栈,将区间存入栈中,在快排的递归中先是对整个区间单趟排序,把key值放到最终位置,在非递归中与递归的思想不变,先手搓一个栈,当然这里博主以前写过,直接复制粘贴就行,有了栈就先对栈进行初始化,将整个区间压栈,先压左区间,再压右区间,根据栈的特性“先进后出”,在一个循环中出栈再压栈,每次出栈和压栈都是一个区间,出栈就对该区间进行排序,排序好后就返回该一个值,这个值就是排序好的值的下标,以该下标为分界分为两个区间,再开始进行排序,循环往复,直到栈中没有数据退出循环,最后销毁栈。
int PartSort(int* a, int left, int right)
{if (left >= right)return -1;int prev = left, cur = left + 1;int keyi = left;while (cur <= right){if (a[cur] < a[keyi]){prev++;Swap(&a[cur], &a[prev]);}cur++;}Swap(&a[keyi], &a[prev]);return prev;
}void PartSortR(int* a, int left, int right)
{ST st;STInit(&st);STPush(&st, left);STPush(&st, right);int begin = left, end = right;while (!STEmpty(&st)){end = STTop(&st);STPop(&st);begin = STTop(&st);STPop(&st);int keyi = PartSort(a, begin, end);//对一个区间单趟排序if (keyi+1 < end){STPush(&st, keyi + 1);STPush(&st, end);}if (keyi > begin){STPush(&st, begin);STPush(&st, keyi);}}STDestory(&st);
}在实现快排非递归时,单趟排序可以用hoare版本或者挖坑法以及前后指针法,这里使用的是前后指针法,在出栈和压栈都是两个数据,代表区间。

归并排序非递归实现
非递归的归并排序和递归归并排序的思想一样,将一个大的问题分成一个一个小问题,将一串数据先通过分解来分成一个一个,再进行合并,在合并过程中比较大小,再放入一个新的数组中,最后把新数组拷贝到原来的数组,而非递归也是如此,只不过不需要和递归一样分解,我们直接设置间距gap,一开始gap等于1,每个数据单独为一组,每个数据进行比较,放入新数组,gap等于2,每两个数据为一组,与下一组进行比较,每次gap需要乘以2,直到gap大于或者等于数据个数就结束,对数组的拷贝可以是在全部结束之后拷贝,也可以是部分拷贝只不过要拷贝多次。
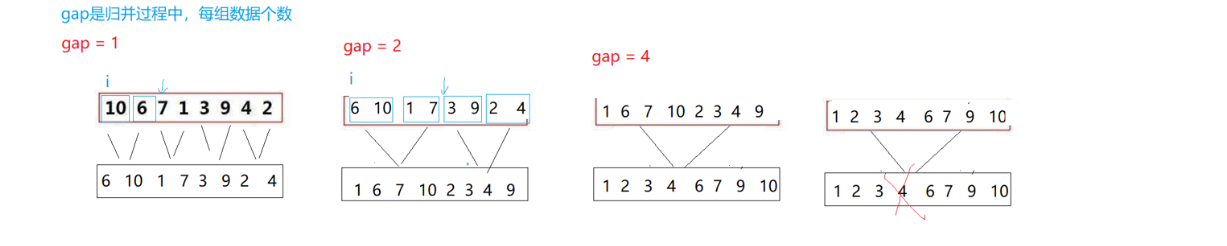
因为gap每次都是乘以2,所以在数据个数不是2的n次方时会出现越界访问,需要对该问题解决,可以通过调试解决,但是这里有一个小技巧,我们可以打印出区间,更好的看出哪个区间出现了越界访问。
错误代码:
void MergesortR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}int gap = 1;while (gap < n){int j = 0;for (int i = 0; i < n; i += 2 * gap){int begin1 = i, end1 = i - 1 + gap;int begin2 = i + gap, end2 = i + 2 * gap - 1;printf("[%d,%d][%d,%d] ", begin1, end1, begin2, end2);while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}}printf("\n");memcpy(a, tmp, sizeof(int) * n);gap *= 2;}free(tmp);
}这里数据是9个,看运行结果:
 这里可以看出gap为不同值时比较的区间,这里有三种情况:
这里可以看出gap为不同值时比较的区间,这里有三种情况:
1、begin2越界访问了,begin2越界end2肯定也越界了。
2、end1越界了,begin2和end2肯定也越界了。
3、end2越界了。
所以只需要根据这三种情况对症下药:
1.当begin2越界了,就把begin2调成end2大的数就可以,因为end2 大于begin2就不会进入下面的循环,也就不会越界访问。
2.当end1越界了,就把end1调成边界值就可以,begin2 和 end2 就和第一种情况一样的解决方法。
3.end2越界了就只需要将end2调成边界就好了。
调整代码:
void MergesortR(int* a,int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}int gap = 1;while (gap < n){int j = 0;for (int i = 0; i < n; i += 2 * gap){int begin1 = i, end1 = i - 1 + gap;int begin2 = i + gap, end2 = i + 2 * gap - 1;//printf("[%d,%d][%d,%d] ", begin1, end1, begin2, end2);if (end1 > n - 1){end1 = n-1;begin2 = n + 1;end2 = n;}else if (end2 > n - 1){end2 = n - 1;}else if (begin2 > n - 1){end2 = n;begin2 = n + 1;}//printf("[%d,%d][%d,%d] ", begin1, end1, begin2, end2);while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}}//printf("\n");memcpy(a, tmp, sizeof(int) * n);gap *= 2;}free(tmp);
}运行结果:
最后不要忘记释放向操作系统申请的空间,有借有还才行。
计数排序
思想:计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。
1. 统计相同元素出现次数
2. 根据统计的结果将序列回收到原来的序列中
代码展示:
//计数排序
void Countsort(int* a, int n)
{int max = a[0], min = a[0];for (int i = 0; i < n; i++){if (max < a[i]){max = a[i];}if (min > a[i]){min = a[i];}}int k = max - min+1;int *CountA = (int*)calloc(k, sizeof(int));if (CountA == NULL){perror("calloc fail");return;}for (int i = 0; i < n; i++){CountA[a[i] - min]++;}int j = 0;for (int i = 0; i < k; i++){while (CountA[i]--){a[j++] = i + min;}}
}写计数排序最好不要写绝对位置,相对位置是最好的,绝对位置就是1就是在新数组对应的就是下标为1的位置,当数据中有负数时就会出现越界 ,相对位置就是在统计某个值时,放入新数组时将该值减去这组数据中的最小值,所以需要找出该组数据中的最大和最小值,那么新数组的大小就是最大值减去最小值加一,当统计数据出现的个数时需要减去最小值,因为最小值减去最小值等于0,也就是新数组的下标范围是0~最大值减去最小值。当完成以上操作就可以开始排序了,从新数组起始位置开始也就是0,将下标值加上最小值放入原来数组,循环次数就是在该下标对应值,如果CountA[i]等于0,说明i+最小值这个值不存在。
计数排序的特性总结:
1. 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
2. 时间复杂度:O(MAX(N,范围))
3. 空间复杂度:O(范围)