编程规范之整数运算
在表达式中混用有符号数和无符号数时,可能会因隐式转换而导致非预期的结果。因此应尽量在表达式中使用相同符号类型的
变量。
对于无法使用相同符号类型的场景,应将不同类型的变量显式转换为相同类型,当表达式中的无符号数隐式转换为另一个有符
号数类型时,如果这个有符号数类型能够完全涵盖无符号数类型的值域,则可以不做显式类型转换,如: int32 = uint8 。
其中有一个示例,我一开始是没有看懂的,然后理解了,记录一下。有符号数和无符号数混用的例子
uint32_t x = 1;
uint32_t y = -1;
std::cout << x / y << std::endl;//打印结果为0
一开始我是没有搞懂为什么结果是0的,我虽然知道混用了有符号数和无符号数。应该是发生了整型提升,但是怎么提升我不知道了。
查了资料,
在C语言中,有符号数和无符号数之间的运算会导致编译器进行隐式类型转换。这种转换通常会将有符号数视为无符号数进行处理,尤其是在进行算术运算时。例如,当执行有符号数和无符号数的除法运算时,有符号数会被隐式转换为无符号数,然后进行除法运算。这种转换可能会导致一些意想不到的结果,因为转换后的数值范围和无符号数的范围相同,且不考虑符号。
具体到除法运算,有符号数和无符号数混合运算时,如果除数为无符号数,那么有符号数会被当作无符号数处理,这可能会导致结果不符合预期,尤其是当有符号数为负数时。例如,如果有一个有符号整数-1和一个无符号整数2进行除法运算,由于-1被当作无符号数处理,其实际值会变成一个很大的正数(在32位系统中,这通常是4294967276),从而导致除法结果远大于预期。
此外,有符号数与无符号数的除法运算在底层是通过不同的汇编指令实现的,有符号的除法使用
idiv指令,而无符号的除法使用div指令。这表明编译器在处理这类运算时会根据操作数的类型选择适当的指令,进而影响运算的结果和性能。综上所述,有符号数和无符号数相除的计算结果取决于编译器的隐式类型转换规则、操作数的具体值以及底层处理这些运算的汇编指令。因此,在进行这类运算时,程序员需要清楚了解这些规则和可能的转换,以避免出现意外的结果或错误。
按照解释,应该是有符号数-1直接按照无符号数进行 运算了。-1内存中的存储形式为,1000 0000 0000 0000 0000 0000 0000 0001,符号位不变其他位取反:1111 1111 1111 1111 1111 1111 1111 1110,加1:1111 1111 1111 1111 1111 1111 1111 1111。然后1/(2^32 -1)等于0。2^32-1值为4,294,967,295。
下面验证一下-1在内存中的存储形式。
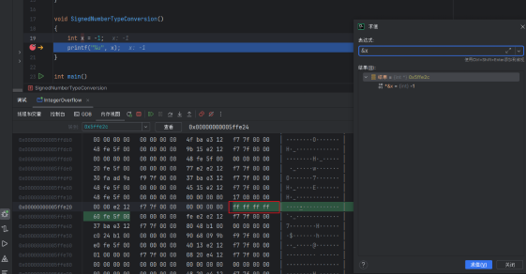
确实在内存中的存储为1111 1111 1111 1111 1111 1111 1111 1111。
而我在上文中的表述:应该是发生了整型提升。这个表述是不对的。应该是发生了强制类型转换。
而所谓的整型提升,指的是不同长度类型的数据进行运算时,发生整型提升。
整型提升整数类型按照以下顺序排列:char , short, int , long
整形提升规则
1.对于有符号数(char, signed char ,short, signed short)整形提升转化成标准长度(int)时,在左端补得是最高位(符号位),正数补0,负数补1
2.对于无符号数(unsigned short ,unsigned char),在左端补得就是0
算数运算乘法表达式操作符:
乘 *、除 / 和 % (取余)的操作数应该是算数类型。(算数类型包括整型和浮点型)。其中取余%的操作数应该是整型。除 / 和 取余的第二个操作数不能为0;取余%的任何一个操作数为负数,表达式的结果是不确定的,应该避免操作数为负数。
十六进制数表示方法为0x12,八进制为前面加0,注意避免在十进制前加0。二进制前面加0b或0B。
整数常量可以使用L、UL、LL、ULL表示类型。