记录一个单独读取evt.bdf的方法
问题描述
之前只能使用eeglab的工具,读取博瑞康达的data.bdf和evt.bdf时,使用的是eeglab的下面这个读取文件的插件。
evt.bdf使用记事本文件查看是乱码的形式。

实现方法
事实上,我们可以直接对这个文件的16进制进行解析。

对文件的位和形式进行解析。
每个数据段是event数,时间戳timestamp,还有事件标签label的组合。
可以构造出下面的读取evt.bdf的函数。
python代码实现
import os
def read_evt_bdf(evt_path)->dict:with open(evt_path, 'r', encoding='mac_roman') as file:lines = file.readlines()eof=len(lines[0])i=0Start=768Event = {}offset1 = 768def extract_event_time(String):#经过对数据的十六进制研究,发现数据是768个开始,每个数据有303# String = lines[0][Start+i*303:Start+(i+1)*302]#数据开始有三个\x00\x00\x00,#事件的次序的个数,在3号的位置‘+'和\x14之间start1 = 3end1=String.find('\x14',start1)num = String[start1:end1]# print(num)#时间戳和次序类似,‘+'和\x150\x14之间start2=String.find('+',end1)end2=String.find('\x150\x14',start2)timeStamp = String[start2:end2]# print(num,timeStamp)# 提取标签# 这个之后,242\x14label_start = end2 + len('\x150\x14')label_end = String.find('\x14', label_start)label = String[label_start:label_end]#转化成整数event_num = int(num)timeStamp=int(timeStamp.replace('.',''))# print(event_num,timeStamp)return event_num,timeStamp,label while(Start+i*303<len(lines[0])):string = lines[0][Start+i*303:Start+(i+1)*302]event_num,timeStamp,label=extract_event_time(string)Event[event_num] = {'timestamp': timeStamp, 'label': label} # 修改为存储字典i=i+1if Event !={}:return Event
dir_path = r"你的文件夹"
evt_path = os.path.join(dir_path,"evt.bdf")
event = read_evt_bdf(evt_path)
这个是运行出的event字典,可以直接按照这个对时间段进行截取。
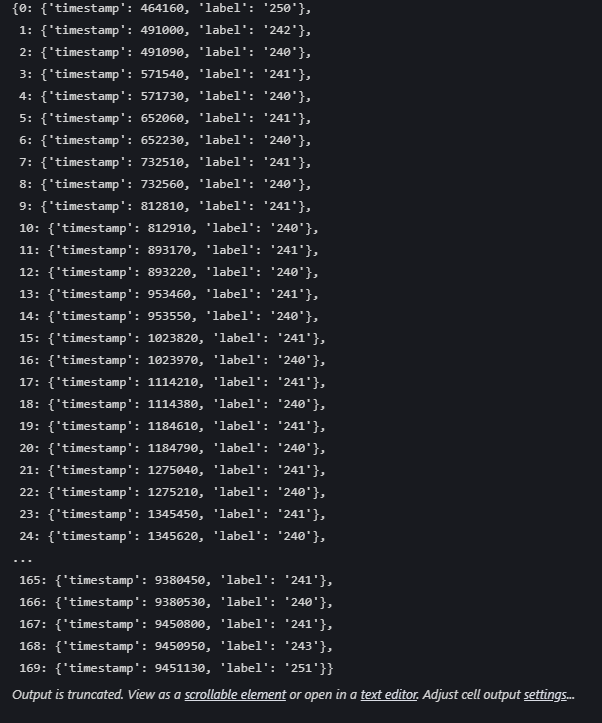
但是推荐使用mne的工具处理包,使用eeglab处理后导出的文件,因为,如果进行降采样,或者其他的处理操作,会改变,有些麻烦。
但是如果想快速截取某一段,作为机器学习的不处理的原始数据进行分析还是可以的。