第16节:传统分类模型-支持向量机(SVM)在图像分类中的应用
一、引言
支持向量机(Support Vector Machine, SVM)作为一种经典的机器学习算法,自20世纪90年代由Vapnik等人提出以来,在模式识别和分类任务中表现出卓越的性能。
在深度学习兴起之前,SVM长期占据着图像分类领域的主导地位,即使在当今深度神经网络大行其道的时代,SVM仍因其理论完备性、小样本学习能力和良好的泛化性能而在特定场景下保持着不可替代的价值。
本文将从SVM的基本原理出发,系统阐述其在图像分类任务中的应用方法、关键技术、优化策略以及实际案例,全面展示这一传统分类模型在计算机视觉领域的独特优势和实用价值。
全文将分为以下几个部分:SVM基本原理回顾、图像分类问题概述、SVM在图像分类中的实现方法、性能优化策略、应用案例分析、与深度学习的对比及未来展望。
二、SVM基本原理回顾
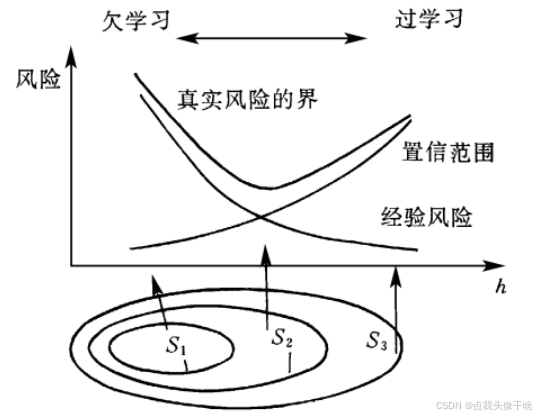
2.1 统计学习理论与结构风险最小化
SVM建立在统计学习理论的基础上,遵循结构风险最小化(Structural Risk Minimization, SRM)原则,与传统的经验风险最小化(Empirical Risk Minimization, ERM)方法形成对比。
SRM通过在经验风险和置信区间之间寻求平衡,有效控制了模型的泛化误差,这使得SVM在小样本情况下仍能保持良好的分类性能。
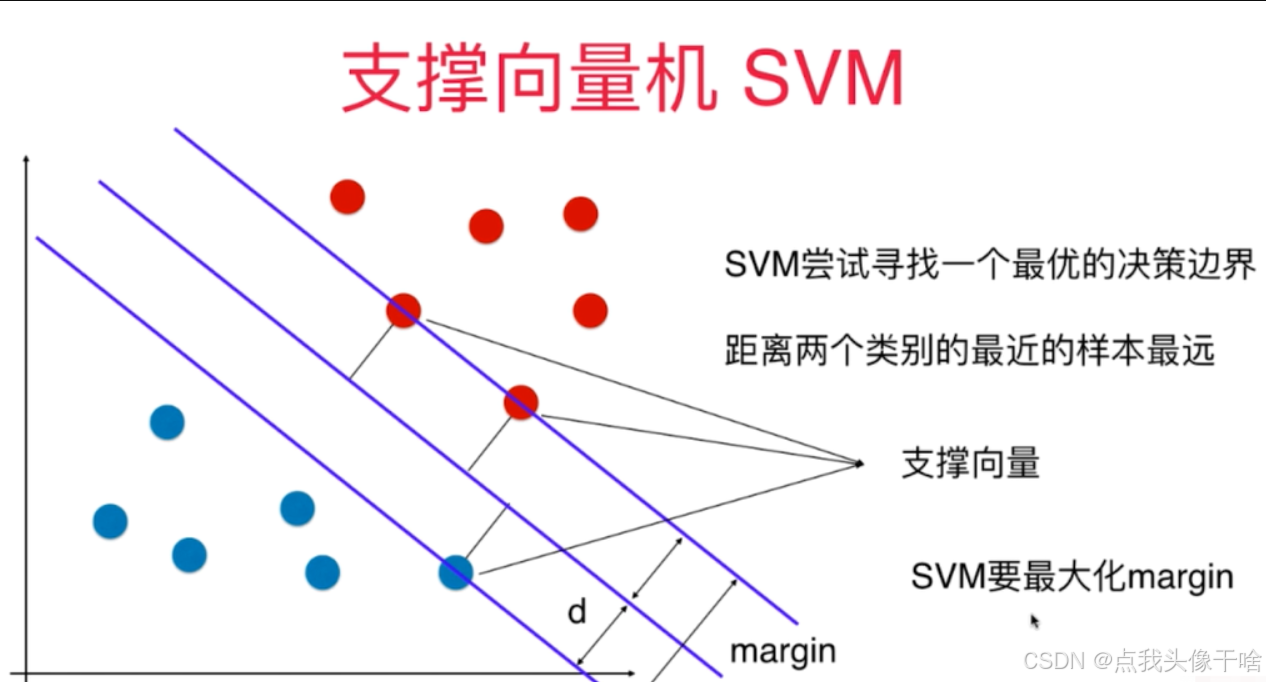
2.2 线性可分情况下的最大间隔分类器
对于线性可分的数据集,SVM的核心思想是寻找一个最优超平面,使得该超平面不仅能将不同类别的样本正确分开,而且能使两类样本到超平面的最小距离(即间隔)最大化。这个最优超平面可以表示为:
w·x + b = 0
其中w是法向量,决定了超平面的方向;b是位移项,决定了超平面与原点的距离。最大化间隔等价于最小化||w||,从而转化为一个凸二次规划问题:
min 1/2 ||w||²
s.t. y_i(w·x_i + b) ≥ 1, ∀i
2.3 非线性情况与核技巧
对于非线性可分问题,SVM通过核技巧(kernel trick)将原始特征空间映射到高维特征空间,在高维空间中实现线性可分。这一过程隐式地通过核函数完成,避免了显式的高维计算。常用的核函数包括:
线性核:K(x_i, x_j) = x_i·x_j
多项式核:K(x_i, x_j) = (γx_i·x_j + r)^d
高斯径向基核(RBF):K(x_i, x_j) = exp(-γ||x_i - x_j||²)
Sigmoid核:K(x_i, x_j) = tanh(γx_i·x_j + r)
2.4 软间隔与松弛变量
现实中的数据往往存在噪声和异常点,严格的线性可分假设不成立。为此,SVM引入软间隔(soft margin)概念,通过松弛变量ξ允许部分样本违反间隔约束,同时惩罚这些违反行为。优化问题变为:
min 1/2 ||w||² + C∑ξ_i
s.t. y_i(w·x_i + b) ≥ 1 - ξ_i, ξ_i ≥ 0, ∀i
其中C是惩罚参数,控制对误分类的容忍程度。
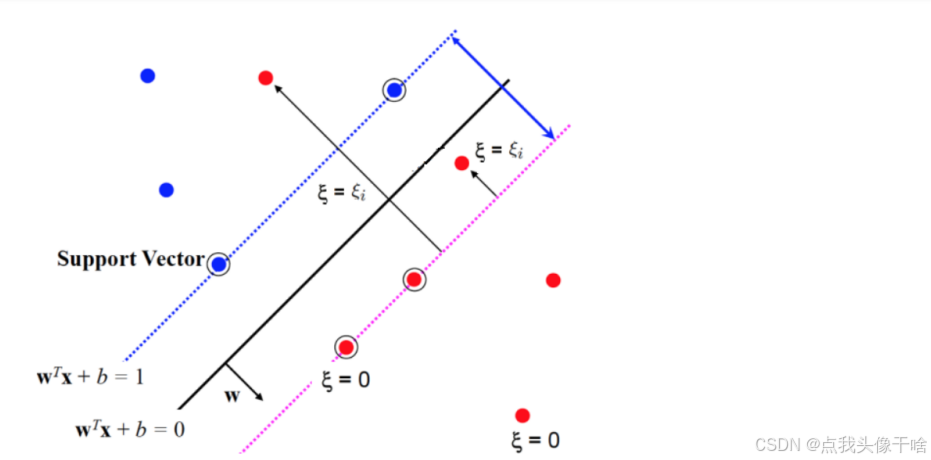
2.5 对偶问题与支持向量
通过拉格朗日乘子法将原问题转化为对偶问题后,SVM的解可以表示为支持向量的线性组合:
f(x) = sign(∑α_i y_i K(x_i, x) + b)
支持向量是训练集中对决策边界起决定性作用的样本,通常只占训练样本的一小部分,这使得SVM具有较好的稀疏性。
三、图像分类问题概述
3.1 图像分类的定义与挑战
图像分类是计算机视觉中的基础任务,旨在为输入图像分配一个预定义的类别标签。与一般的分类问题相比,图像数据具有以下特点:
-
高维性:即使是一张小尺寸图像,其原始像素空间维度也很高(如256×256 RGB图像有196,608维)
-
局部相关性:相邻像素之间存在强相关性,包含丰富的空间结构信息
-
光照、姿态、遮挡等变化:同一物体在不同条件下可能呈现显著不同的视觉表现
-
类内差异与类间相似性:同一类别可能包含外观差异很大的实例,而不同类别可能有相似的外观
3.2 传统图像分类流程
在深度学习出现之前,传统的图像分类通常遵循"特征提取+分类器"的两阶段流程:
-
特征提取:从原始像素中提取有判别性的特征表示
-
全局特征:颜色直方图、纹理特征、形状描述符等
-
局部特征:SIFT、HOG、SURF等
-
编码特征:词袋模型(BoW)、Fisher向量、VLAD等
-
-
分类模型:基于提取的特征训练分类器
-
常用分类器包括SVM、随机森林、AdaBoost等
-
SVM因其良好的泛化能力成为最受欢迎的选择
-
3.3 评价指标
图像分类任务的常用评价指标包括:
-
准确率(Accuracy):正确分类样本占总样本的比例
-
混淆矩阵(Confusion Matrix):详细展示各类别间的分类情况
-
精确率(Precision)、召回率(Recall)、F1分数:针对类别不平衡问题的评价指标
-
ROC曲线与AUC值:评估分类器在不同阈值下的性能表现
四、SVM在图像分类中的实现方法
4.1 特征提取与表示
4.1.1 全局特征
-
颜色特征:
-
颜色直方图:统计各颜色通道的分布情况
-
颜色矩:通过均值、方差、偏度等描述颜色分布
-
颜色相关图:考虑颜色空间分布关系
-
-
纹理特征:
-
Gabor滤波器:模拟人类视觉系统对纹理的感知
-
LBP(Local Binary Patterns):描述局部纹理模式
-
Tamura纹理特征:包括粗糙度、对比度、方向性等
-
-
形状特征:
-
Hu矩:具有平移、旋转和尺度不变性的形状描述符
-
Zernike矩:在单位圆上定义的正交矩
-
边缘方向直方图:统计图像边缘的方向分布
-
4.1.2 局部特征
-
关键点检测与描述:
-
SIFT(Scale-Invariant Feature Transform):具有尺度不变性的局部特征
-
SURF(Speeded Up Robust Features):SIFT的加速版本
-
ORB(Oriented FAST and Rotated BRIEF):结合FAST关键点与BRIEF描述符
-
-
特征编码:
-
词袋模型(Bag of Words):将局部特征量化到视觉词典
-
Fisher向量:通过高斯混合模型对特征分布进行编码
-
VLAD(Vector of Locally Aggregated Descriptors):对特征与聚类中心的残差进行聚合
-
4.1.3 特征选择与降维
高维特征可能导致"维度灾难"和计算效率问题,常用的降维方法包括:
-
主成分分析(PCA):通过线性变换将数据投影到低维空间
-
线性判别分析(LDA):寻找能最大化类间差异、最小化类内差异的投影方向
-
t-SNE:非线性降维方法,适合可视化高维数据
4.2 多类SVM策略
标准SVM是二分类器,而图像分类通常涉及多个类别。常见的多类扩展策略包括:
-
一对多(One-vs-Rest, OvR):
-
为每个类别训练一个二分类SVM,将该类与其他所有类区分
-
预测时选择决策函数值最大的类别
-
简单直接,但当类别很多时可能面临类别不平衡问题
-
-
一对一(One-vs-One, OvO):
-
为每两个类别训练一个二分类SVM
-
对于K个类别,需要训练K(K-1)/2个分类器
-
预测时采用投票机制,选择得票最多的类别
-
每个子问题更简单,但分类器数量随类别数平方增长
-
-
有向无环图(DAGSVM):
-
将OvO分类器组织成有向无环图
-
通过逐层淘汰减少分类器调用次数
-
保持OvO精度的同时提高预测效率
-
-
多类目标函数:
-
直接修改SVM目标函数,使其能同时优化所有类别的分类边界
-
如Crammer和Singer提出的多类SVM公式
-
理论更优雅,但实现复杂度较高
-
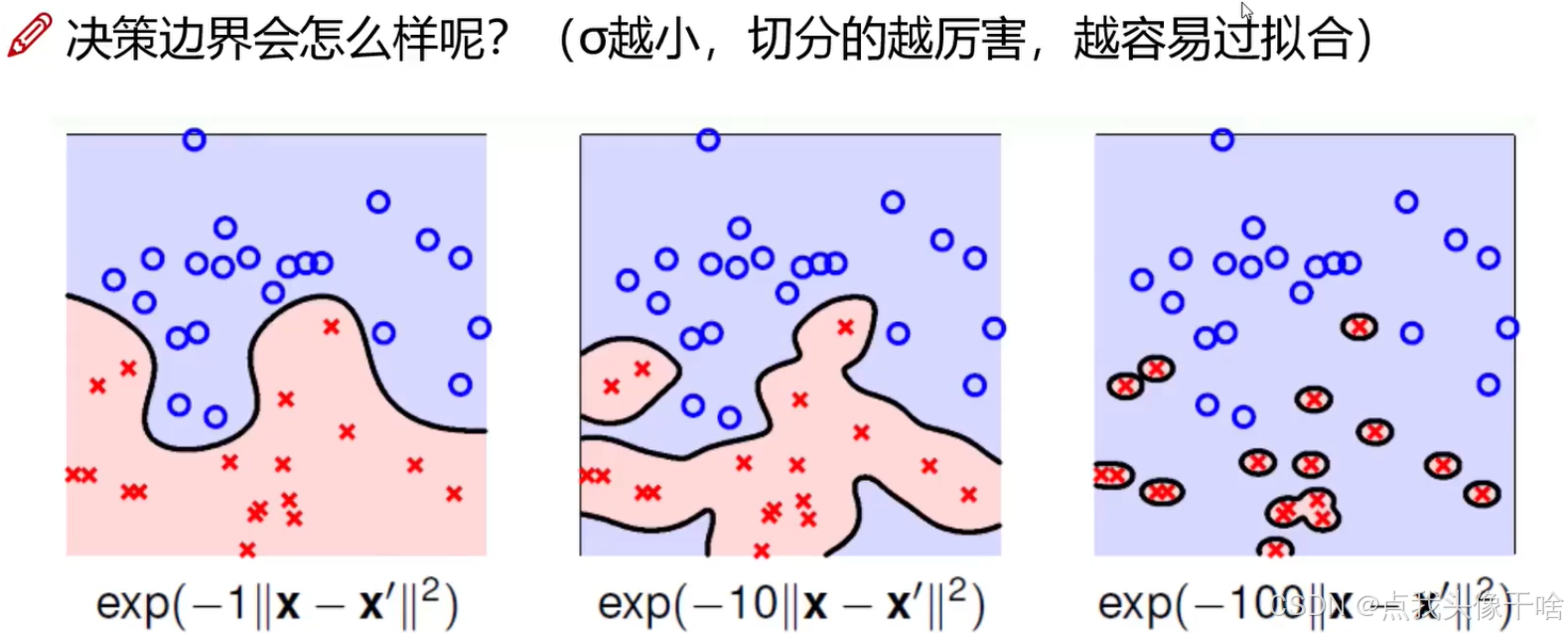
4.3 核函数选择与参数优化
4.3.1 核函数选择
在图像分类中,核函数的选择至关重要:
-
线性核:
-
适用于特征维度高、样本量大的情况
-
计算效率高,但无法处理非线性可分问题
-
常用于稀疏特征或已经过非线性变换的特征
-
-
RBF核:
-
最常用的核函数,具有较强的非线性表达能力
-
需要谨慎选择带宽参数γ
-
适用于大多数图像分类任务
-
-
多项式核:
-
适合具有明显阶数特征的问题
-
参数d的选择影响模型复杂度
-
在特定图像分类任务中可能有不错表现
-
-
自定义核:
-
针对特定问题设计专用核函数
-
如图像专用核:金字塔匹配核、空间金字塔匹配核等
-
需要领域知识和大量实验验证
-
4.3.2 参数优化
SVM的关键参数需要精心调优:
-
惩罚参数C:
-
控制模型对误分类的容忍度
-
C值大:分类边界窄,可能过拟合
-
C值小:分类边界宽,可能欠拟合
-
-
RBF核参数γ:
-
控制单个样本的影响范围
-
γ值大:决策边界复杂,可能过拟合
-
γ值小:决策边界平滑,可能欠拟合
-
-
优化方法:
-
网格搜索:在指定参数范围内系统搜索
-
随机搜索:在参数空间随机采样
-
启发式方法:如遗传算法、贝叶斯优化等
-
4.4 实现流程示例
一个完整的基于SVM的图像分类系统实现流程如下:
-
数据准备:
-
收集并标注图像数据集
-
划分训练集、验证集和测试集
-
数据增强(如翻转、旋转、裁剪等)
-
-
特征提取:
-
根据任务特点选择合适的特征提取方法
-
对每幅图像提取特征表示
-
可选进行特征标准化或归一化
-
-
模型训练:
-
选择SVM类型(线性/非线性)和核函数
-
使用交叉验证在验证集上优化参数
-
用最优参数在完整训练集上训练最终模型
-
-
评估与部署:
-
在测试集上评估模型性能
-
分析混淆矩阵找出分类薄弱环节
-
将训练好的模型部署到实际应用
-
五、性能优化策略
5.1 特征工程优化
-
多层次特征融合:
-
结合全局特征与局部特征的优势
-
如同时使用颜色直方图和SIFT特征
-
通过特征拼接或后期融合实现
-
-
空间金字塔匹配:
-
将图像划分为多层次的网格
-
在每个层次上提取并汇集局部特征
-
保留一定的空间布局信息
-
-
深度特征与传统特征结合:
-
使用预训练CNN的中间层输出作为特征
-
与传统手工设计特征相结合
-
发挥深度特征的高层语义表达能力
-
5.2 算法层面优化
-
增量学习与在线学习:
-
对于大规模数据集,采用增量式SVM
-
支持新增样本的增量训练
-
减少重新训练的计算成本
-
-
概率输出校准:
-
标准SVM输出非概率性决策值
-
通过sigmoid函数或Platt缩放转换为概率
-
便于后续的多模型融合或决策
-
-
集成学习方法:
-
将多个SVM模型集成提升性能
-
Bagging:通过自助采样构建多样性基分类器
-
Boosting:迭代调整样本权重聚焦难样本
-
5.3 计算效率优化
-
近似算法与稀疏化:
-
使用近似SVM算法处理大规模数据
-
如Core Vector Machine(CVM)
-
通过稀疏化减少支持向量数量
-
-
并行计算:
-
利用SVM训练中的并行性
-
多核CPU或GPU加速计算
-
特别适用于核矩阵计算
-
-
专用优化库:
-
LIBSVM:经典的SVM实现库
-
LIBLINEAR:针对线性SVM的高效实现
-
ThunderSVM:支持GPU加速的SVM库
-
六、应用案例分析
6.1 手写数字识别(MNIST)
MNIST数据集包含0-9手写数字的28×28灰度图像,是经典的图像分类基准。

-
特征提取:
-
原始像素(784维)
-
HOG特征(提取边缘方向信息)
-
投影特征(水平和垂直方向的投影直方图)
-
-
SVM实现:
-
采用RBF核SVM
-
参数通过网格搜索优化(C=10, γ=0.01)
-
使用OvO策略处理多类问题
-
-
性能表现:
-
原始像素特征:准确率约98.5%
-
结合HOG特征:准确率可达99%以上
-
与简单神经网络性能相当
-
6.2 场景分类(Scene-15)
Scene-15包含15类室内外场景图像,每类200-400张。

-
特征提取:
-
密集采样的SIFT特征
-
通过K-means构建视觉词典(1000词)
-
空间金字塔匹配(1×1, 2×2, 4×4网格)
-
-
SVM实现:
-
采用χ²核SVM(适合直方图类特征)
-
多类采用OvR策略
-
参数优化后C=100, γ=0.1
-
-
性能表现:
-
平均准确率约85%
-
优于当时的多数传统方法
-
计算效率高于早期CNN方法
-
6.3 物体识别(Caltech-101)
Caltech-101包含101类物体图像,每类约40-800张。

-
特征提取:
-
基于SIFT的Fisher向量编码
-
局部颜色特征补充
-
PCA降维至128维
-
-
SVM实现:
-
RBF核SVM
-
采用DAGSVM多类策略
-
参数C=1, γ=0.005
-
-
性能表现:
-
平均准确率约75%(30训练样本/类)
-
对小样本情况鲁棒性强
-
特征工程对性能影响显著
-
6.4 医学图像分类(皮肤病变)
ISIC皮肤病变数据集包含多种皮肤镜图像。
-
特征提取:
-
不对称性、边界、颜色和纹理特征(ABCD规则)
-
深度特征(预训练ResNet的池化层输出)
-
临床元数据(患者年龄、病变位置等)
-
-
SVM实现:
-
采用线性SVM(因特征已高度工程化)
-
概率输出用于临床决策支持
-
类别加权处理不平衡数据
-
-
性能表现:
-
AUC达0.92,优于多数传统方法
-
模型可解释性强,受医生欢迎
-
计算效率高,适合临床部署
-
七、与深度学习的对比及未来展望
7.1 SVM与深度学习的比较
| 特性 | SVM | 深度神经网络 |
|---|---|---|
| 理论基础 | 统计学习理论,凸优化 | 生物启发,非凸优化 |
| 特征处理 | 需要手工特征工程 | 自动特征学习 |
| 数据需求 | 小样本表现良好 | 需要大量数据 |
| 计算复杂度 | 相对较低 | 通常较高 |
| 模型解释性 | 相对较好 | 通常较差 |
| 硬件需求 | CPU即可 | 通常需要GPU |
| 超参数敏感性 | 核参数和C关键 | 大量超参数需要调整 |
| 训练时间 | 相对较短 | 可能很长 |
| 部署难度 | 简单轻量 | 可能较复杂 |
7.2 SVM在深度学习时代的价值
尽管深度学习在许多图像分类任务上取得了突破性进展,SVM仍具有独特价值:
-
小数据场景:当标注数据有限时,SVM通常优于深度学习
-
可解释性要求:医疗、金融等领域需要可解释的决策过程
-
资源受限环境:嵌入式设备或实时系统需要轻量级模型
-
特征明确问题:当领域知识能指导设计有效特征时
-
模型融合:作为深度学习模型的补充或后处理组件
7.3 未来发展方向
-
与深度学习的融合:
-
使用深度特征+SVM的混合架构
-
将SVM作为神经网络的最后一层
-
借鉴SVM的间隔理论改进深度学习
-
-
新型核函数设计:
-
针对图像数据的专用核函数
-
深度核学习:结合深度网络与核方法
-
自适应核选择机制
-
-
大规模分布式SVM:
-
面向超大规模图像数据的SVM算法
-
分布式内存计算框架下的实现
-
在线学习与增量学习优化
-
-
领域专用优化:
-
针对医学、遥感等特定领域的SVM改进
-
结合领域知识的特征与核设计
-
多模态数据融合策略
-
八、结论
支持向量机作为传统机器学习中的经典分类模型,在图像分类任务中展现了强大的性能和良好的适应性。通过精心设计的特征工程、合适的核函数选择和参数优化,SVM能够在多种图像分类任务上取得媲美甚至超越早期深度学习方法的性能。尽管当前深度学习在多数视觉任务中占据主导地位,但SVM仍因其理论完备性、小样本学习能力和良好的可解释性,在特定应用场景中保持着不可替代的价值。
未来的研究应当关注SVM与深度学习的融合创新,充分发挥两类方法的互补优势。同时,针对新兴应用领域的专用SVM改进,以及面向大规模数据的高效SVM算法,也将是值得探索的方向。无论如何,SVM作为机器学习发展历程中的重要里程碑,其核心思想和算法精髓仍将持续影响计算机视觉和模式识别领域的发展。
相关代码
以下是一些使用支持向量机(SVM)进行图像分类的Python代码示例,涵盖了不同场景和应用:
库文件:pip install scikit-learn opencv-python scikit-image tensorflow
1. 基础SVM图像分类(使用sklearn)
from sklearn import svm, datasets
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report, accuracy_score
import numpy as np# 加载数据集(这里以sklearn自带的digits数据集为例)
digits = datasets.load_digits()
X = digits.images.reshape((len(digits.images), -1)) # 将图像展平
y = digits.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建SVM分类器
clf = svm.SVC(kernel='rbf', gamma=0.001, C=100)# 训练模型
clf.fit(X_train, y_train)# 预测
y_pred = clf.predict(X_test)# 评估
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))2. 使用HOG特征+SVM进行图像分类
from skimage.feature import hog
from skimage import exposure
import cv2
import numpy as np# 提取HOG特征
def extract_hog_features(images):features = []for image in images:# 如果是彩色图像,先转换为灰度if len(image.shape) > 2:image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)# 计算HOG特征fd, hog_image = hog(image, orientations=8, pixels_per_cell=(16, 16),cells_per_block=(1, 1), visualize=True)features.append(fd)return np.array(features)# 假设我们已经加载了图像数据到X_train, X_test, y_train, y_test# 提取HOG特征
X_train_hog = extract_hog_features(X_train)
X_test_hog = extract_hog_features(X_test)# 创建并训练SVM
hog_svm = svm.SVC(kernel='linear', C=1.0)
hog_svm.fit(X_train_hog, y_train)# 评估
hog_pred = hog_svm.predict(X_test_hog)
print("HOG+SVM Accuracy:", accuracy_score(y_test, hog_pred))3. 使用SIFT特征+BOW+SVM(适用于更复杂的图像分类)
import cv2
import numpy as np
from sklearn.cluster import KMeans
from sklearn.svm import SVC# SIFT特征提取
def extract_sift_features(images):sift = cv2.SIFT_create()descriptors_list = []for img in images:gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)_, descriptors = sift.detectAndCompute(gray, None)if descriptors is not None:descriptors_list.append(descriptors)return descriptors_list# 创建视觉词典
def create_visual_dictionary(descriptors_list, n_clusters=100):all_descriptors = np.vstack(descriptors_list)kmeans = KMeans(n_clusters=n_clusters, random_state=42)kmeans.fit(all_descriptors)return kmeans# 将图像转换为BoW特征
def images_to_bow(images, kmeans, sift):bow_features = np.zeros((len(images), kmeans.n_clusters))for i, img in enumerate(images):gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)_, descriptors = sift.detectAndCompute(gray, None)if descriptors is not None:words = kmeans.predict(descriptors)for w in words:bow_features[i][w] += 1return bow_features# 假设我们已经加载了图像数据到train_images, test_images, y_train, y_test# 提取SIFT特征
train_descriptors = extract_sift_features(train_images)# 创建视觉词典
kmeans = create_visual_dictionary(train_descriptors, n_clusters=100)# 转换为BoW特征
sift = cv2.SIFT_create()
X_train_bow = images_to_bow(train_images, kmeans, sift)
X_test_bow = images_to_bow(test_images, kmeans, sift)# 训练SVM
bow_svm = SVC(kernel='rbf', C=10, gamma=0.1)
bow_svm.fit(X_train_bow, y_train)# 评估
bow_pred = bow_svm.predict(X_test_bow)
print("BoW+SVM Accuracy:", accuracy_score(y_test, bow_pred))4. 使用预训练CNN特征+SVM(结合深度学习方法)
from tensorflow.keras.applications import VGG16
from tensorflow.keras.models import Model
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input
import numpy as np# 加载预训练VGG16模型(去掉最后的全连接层)
base_model = VGG16(weights='imagenet', include_top=False)
model = Model(inputs=base_model.input, outputs=base_model.get_layer('block5_pool').output)# 提取CNN特征
def extract_cnn_features(img_paths):features = []for img_path in img_paths:img = image.load_img(img_path, target_size=(224, 224))x = image.img_to_array(img)x = np.expand_dims(x, axis=0)x = preprocess_input(x)feature = model.predict(x)features.append(feature.flatten())return np.array(features)# 假设我们有一组图像路径和标签
# train_images_paths, test_images_paths, y_train, y_test# 提取特征
X_train_cnn = extract_cnn_features(train_images_paths)
X_test_cnn = extract_cnn_features(test_images_paths)# 训练SVM
cnn_svm = svm.SVC(kernel='linear', C=1.0)
cnn_svm.fit(X_train_cnn, y_train)# 评估
cnn_pred = cnn_svm.predict(X_test_cnn)
print("CNN+SVM Accuracy:", accuracy_score(y_test, cnn_pred))5. 多类别SVM分类(使用OvO策略)
from sklearn.multiclass import OneVsOneClassifier
from sklearn.svm import SVC# 创建OvO SVM分类器
ovo_clf = OneVsOneClassifier(SVC(kernel='rbf', gamma=0.01, C=100))# 训练模型
ovo_clf.fit(X_train, y_train)# 预测
ovo_pred = ovo_clf.predict(X_test)# 评估
print("OvO SVM Accuracy:", accuracy_score(y_test, ovo_pred))
print("\nClassification Report:\n", classification_report(y_test, ovo_pred))6. SVM参数网格搜索(寻找最优参数)
from sklearn.model_selection import GridSearchCV# 定义参数网格
param_grid = {'C': [0.1, 1, 10, 100],'gamma': [1, 0.1, 0.01, 0.001],'kernel': ['rbf', 'linear', 'poly']
}# 创建GridSearchCV对象
grid = GridSearchCV(svm.SVC(), param_grid, refit=True, verbose=2, cv=5)
grid.fit(X_train, y_train)# 输出最佳参数
print("Best parameters found:", grid.best_params_)# 使用最佳模型预测
grid_pred = grid.predict(X_test)
print("Optimized SVM Accuracy:", accuracy_score(y_test, grid_pred))这些代码示例展示了SVM在不同场景下的图像分类应用。实际使用时,需要根据具体数据集和任务需求进行调整:
-
对于简单图像分类,可以直接使用像素值作为特征
-
对于更复杂的任务,建议使用HOG、SIFT等特征提取方法
-
当数据量不大但特征维度高时,线性SVM通常表现良好
-
对于小样本问题,RBF核SVM通常是不错的选择
-
结合深度学习特征可以进一步提升性能