el-transfer穿梭框数据量过大的解决方案
一:背景
我们这个穿梭框获取的是项目的全量数据,在左边大概有5000条,自己测试了一下5000条数据的效果,发现异常的卡顿,本来打算像el-select一样去解决的(只显示一部分,在搜索的时候去全量搜索,奈何这个搜索方法不支持远程搜索,只能弃用该解决方案),一顿百度跟ai搜索,感觉答案都比较模糊,所以记录一下该解决方案。
二:解决方案一(最简单):
参考:el-transffer大数据量页面卡顿优化
a.安装
npm install el-virtual-transfer --save
b.使用
组件内导入注册一下即可使用:
import ElTransferVirtual from 'element-transfer-virtual'
components: { ElTransferVirtual }
c.替换组件名
直接用ElTransferVirtual替换你的el-transfer组件名就行了。其他的都不用变
<template><div class="home"><el-virtual-transferfilterable:filter-method="filterMethod"filter-placeholder="请输入城市拼音"v-model="value":data="data"></el-virtual-transfer></div>
</template><script>
import ElVirtualTransfer from 'el-virtual-transfer';
export default {name: 'HomeView',data() {const generateData = _ => {const data = [];// 生成 3000 个数据for (let i = 0; i < 3000; i++) {const label = `城市${i + 1}`;const key = i;const pinyin = `chengshi${i + 1}`;data.push({label: label,key: key,pinyin: pinyin});}return data;};return {data: generateData(),value: [],filterMethod(query, item) {return item.pinyin.indexOf(query) > -1;}};},created() {},methods: {},components: {ElVirtualTransfer}
};
</script>
d.优缺点:
优点:使用十分的简单,只需要安装依赖替换组件名即可
缺点:该组件方案只上传到了npm,但是并没有开源。我的意思是,如果你的数据是全量数据(获取全量数据不卡的话),就可以直接使用这个方案,毕竟简单。( 如果获取全量数据卡的话,你可以在用户进入页面时就去静默分批的获取这个数据,也是一种解决方案)
三:解决方案二(拓展性强):
参考: Element-UI的transfer穿梭框组件数据量大解决方案
a.在components下面新建一个文件夹,用来存放组件
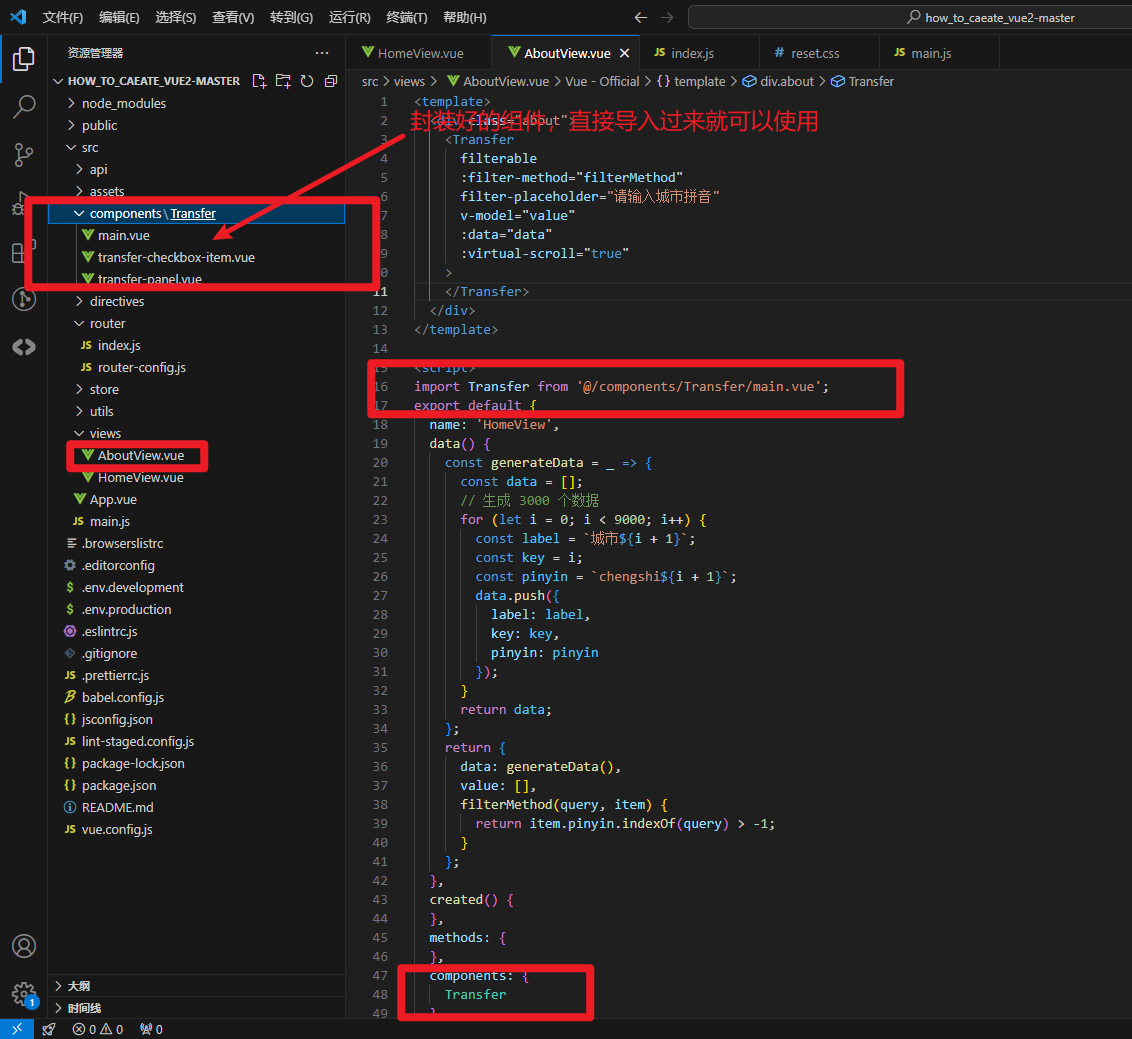
main.vue , transfer-checkbox-item.vue ,transfer-panel.vue的内容我就不贴了。可以直接去我的demo上复制过来就可以用了。
这里还要安装一个插件(代码里用到了虚拟滚动的插件):
npm i vue-virtual-scroll-list
b.自定义指令代码
因为组件内用到了一个自定义指令,所以需要把这个自定义指令的代码复制过来,在directives文件夹下,直接把我的代码(infinite-scroll整个文件夹)复制过来就行。并且在main.js上注册一下:
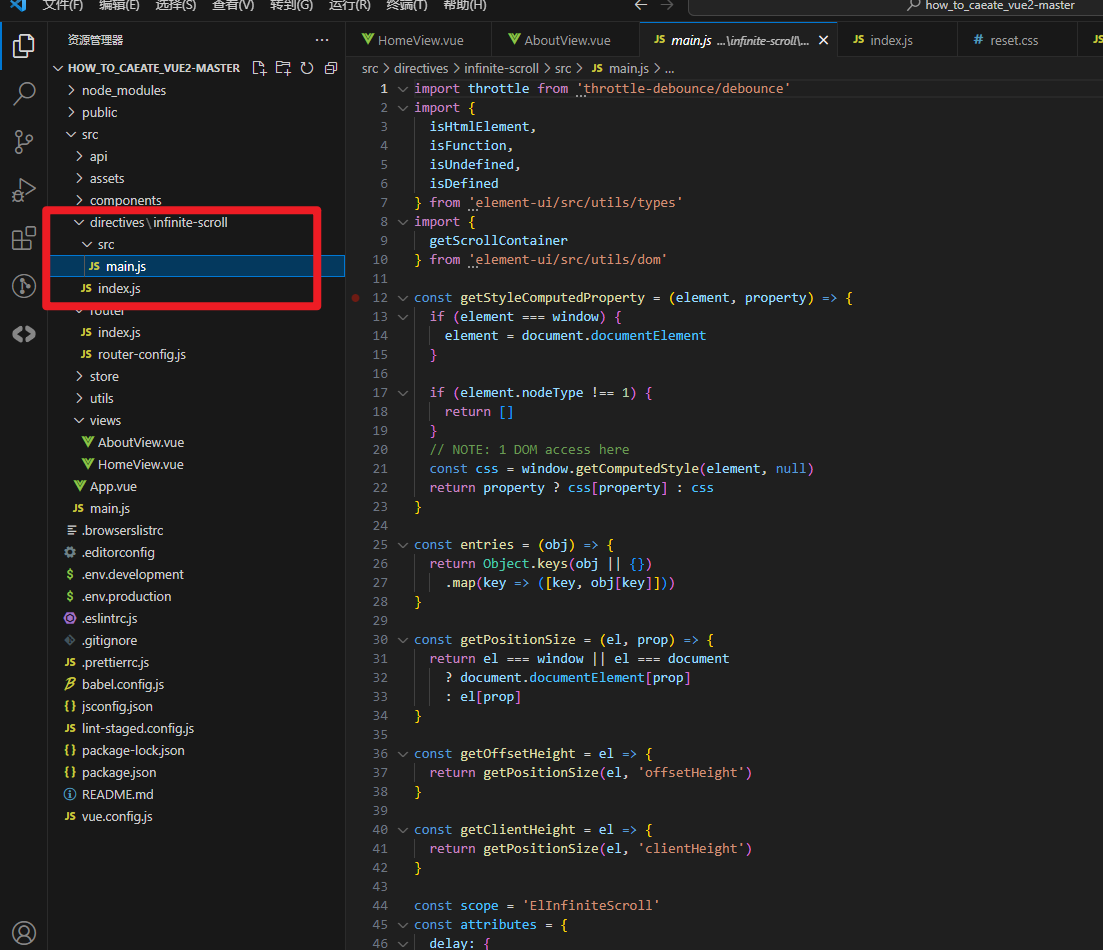
c.main.js注册自定义指令:
import InfiniteScroll from '@/directives/infinite-scroll'; // 替换为实际路径
InfiniteScroll.install(Vue);
d.替换组件名,并且传入 :virtual-scroll="true"激活虚拟列表
直接用Transfer替换你的el-transfer组件名就行了,并且一定要传入:virtual-scroll=“true”,不然跟原来的el-transfer没有区别,还是会很卡。
<template><div class="about"><Transferfilterable:filter-method="filterMethod"filter-placeholder="请输入城市拼音"v-model="value":data="data":virtual-scroll="true"></Transfer></div>
</template><script>
import Transfer from '@/components/Transfer/main.vue';
export default {name: 'HomeView',data() {const generateData = _ => {const data = [];// 生成 3000 个数据for (let i = 0; i < 9000; i++) {const label = `城市${i + 1}`;const key = i;const pinyin = `chengshi${i + 1}`;data.push({label: label,key: key,pinyin: pinyin});}return data;};return {data: generateData(),value: [],filterMethod(query, item) {return item.pinyin.indexOf(query) > -1;}};},created() {},methods: {},components: {Transfer}
};
</script>
e.优缺点:
优点:1.源码都已经给你了,可以根据自己的项目来自定义 2.上面那个方案只能传入全量的数据,但是这个方案因为源码都给你了,你可以修改源码,在一开始的时候只加载部分数据,然后用户下拉的时候再去加载更多的数据,搜索的话,你可以用全量数据来搜索
缺点: 需要复制的内容过多
四.原理
大家可以把项目demo跑起来看一下,其实都是修改了el-transfer的源码,然后结合虚拟列表的组件来使dom渲染的结构更少。具体虚拟列表的原理,大家可以自行百度下: 其核心思想就是在处理用户滚动时,只改变列表在可视区域的渲染部分,然后translate来让渲染的列表偏移到可视区域中,给用户平滑滚动的感觉。
其实原理都是一样的,大家如果能采用的话,还是尽量采用第一种方案,因为已经压缩过了,代码体积更小。
五.demo源码地址
github: https://github.com/rui-rui-an/el_transfer_big_data