Hadoop伪分布式模式搭建全攻略:从环境配置到实战测试
引言
作为大数据生态的基石,Hadoop凭借其高可靠性、扩展性成为分布式计算的首选框架。本文将手把手带你完成Hadoop伪分布式模式部署,通过单节点模拟集群环境,为后续学习MapReduce、YARN等核心组件打下基础
目录
引言
Hadoop 发展历史
1.1 起源(2002–2005)
1.1 安装JDK 1.8
3.3 伪分布式模式
3.3.1 环境准备
3.3.2 配置 SSH 免密登录
3.3.3 修改 Hadoop 配置文件
3.3.4 格式化 HDFS
Hadoop 发展历史
1.1 起源(2002–2005)
Google 的三大论文:Hadoop 的核心思想来源于 Google 的分布式技术论文:
2003年:Google 发表《The Google File System》(GFS),提出分布式文件系统。
2004年:Google 发表《MapReduce: Simplified Data Processing on Large Clusters》,提出分布式计算模型。
2006年:Google 发表《Bigtable: A Distributed Storage System for Structured Data》,启发后续 NoSQL 数据库发展。
Doug Cutting 的贡献:受 Google 论文启发,Doug Cutting 和 Mike Cafarella 在 2002年 开始开发开源搜索引擎 Nutch,并在 2006年 将其分布式计算模块独立为 Hadoop(名称来源于 Doug Cutting 儿子的玩具大象)。
成为 Apache 项目(2006–2008)
2006年:Hadoop 正式成为 Apache 开源项目。
2008年:Hadoop 成为 Apache 顶级项目,同年 Yahoo! 成功用 Hadoop 集群处理 1TB 数据排序任务(仅需 209秒),验证其大规模数据处理能力。
Hadoop 1.0 时代(2009–2012)
2009年:Hadoop 1.0 发布,核心模块包括 HDFS(分布式文件系统) 和 MapReduce(分布式计算框架)。
生态初现:Apache Hive(数据仓库)、Apache Pig(脚本化数据处理)等项目加入生态。
Hadoop 2.0 与 YARN(2012–2015)
2012年:Hadoop 2.0 发布,引入 YARN(Yet Another Resource Negotiator),将资源管理与计算框架解耦,支持多种计算模型(如 Spark、Tez)。
商业化兴起:Cloudera、Hortonworks、MapR 等公司推出企业级 Hadoop 发行版。
生态爆发与挑战(2015–2020)
计算引擎多样化:Spark(内存计算)、Flink(流处理)等框架崛起,部分替代 MapReduce。
云原生趋势:AWS、Azure 等云厂商推出托管 Hadoop 服务(如 EMR),但 Hadoop 本地部署市场份额受云存储(如 S3)冲击。
当前阶段(2020至今)
Hadoop 3.x:支持 Erasure Coding(节省存储)、GPU 加速、容器化部署(Kubernetes 集成)。
生态融合:Hadoop 与云原生技术(如 Kubernetes)、实时计算(Flink)结合,适应现代数据湖架构。
1.1 安装JDK 1.8
# 查询已安装的 JDK 包
rpm -qa | grep 'java\|jdk\|gcj\|jre'
# 卸载指定包(替换为实际查询结果)
yum -y remove java*
安装jdk
百度云盘
通过网盘分享的文件:张家界学院
链接: https://pan.baidu.com/s/1IQgOZFa29gceR-eyUdZj2Q?pwd=w3rd 提取码: w3rd
jdk-8u181-linux-x64.tar.gz
解压到opt
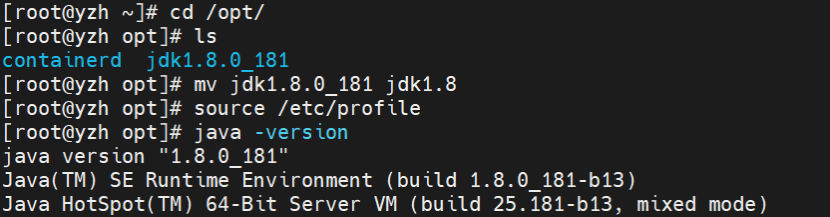
tar -zxvf jdk-8u181-linux-x64.tar.gz -C /opt/
ln -s /opt/jdk1.8.0_181 /opt/jdk1.8 # 创建软链接便于维护
配置环境变量
sudo vi /etc/profile
echo 'export JAVA_HOME=/opt/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH' >> /etc/profile
source /etc/profile
或者手动加入
export JAVA_HOME=/opt/jdk1.8 #填写自己的jdk路径
export PATH=$JAVA_HOME/bin:$PATH
环境生效
source /etc/profile
Hadoop 版本:选择稳定版本(如 Hadoop 3.3.6)
从 Apache 官网下载二进制包(以 Hadoop 3.3.6 为例):
wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
安装
# 解压到指定目录(例如 /opt/hadoop)
tar -zxvf hadoop-3.3.6.tar.gz -C /opt/
mv /opt/hadoop-3.3.6 /opt/hadoop
# 配置环境变量(编辑 ~/.bashrc 或 ~/.zshrc)
export HADOOP_HOME=/opt/hadoopexport PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
# 使配置生效
source ~/.bashrc
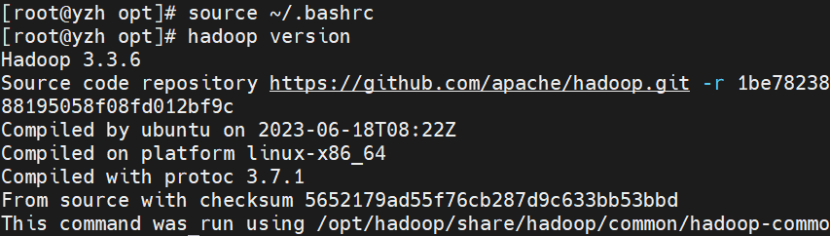
查看
hadoop version
测试
准备输入文件
# 创建输入目录
mkdir -p ~/hadoop-input
# 写入测试文本
echo "Hello World Hello Hadoop" > ~/hadoop-input/test.txt
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar \
wordcount ~/hadoop-input ~/hadoop-output
查看结果
cat ~/hadoop-output/part-r-00000

3.3 伪分布式模式
以下是 Hadoop 伪分布式模式(Pseudo-Distributed Mode)的环境搭建步骤。伪分布式模式下,Hadoop 的各个组件(如 HDFS、YARN、MapReduce)以独立进程运行,但所有服务均部署在单台机器上,模拟多节点集群的行为。这是学习和开发中最常用的模式。
3.3.1 环境准备
操作系统:Linux(如 Ubuntu/CentOS)或 macOS(Windows 需通过 WSL 或虚拟机)。
前置条件:
完成 Hadoop 单机模式 的安装(JDK 和 Hadoop 解压配置)。
配置 SSH 免密登录(用于启动 Hadoop 服务)。
3.3.2 配置 SSH 免密登录
Hadoop 需要通过 SSH 启动本地进程
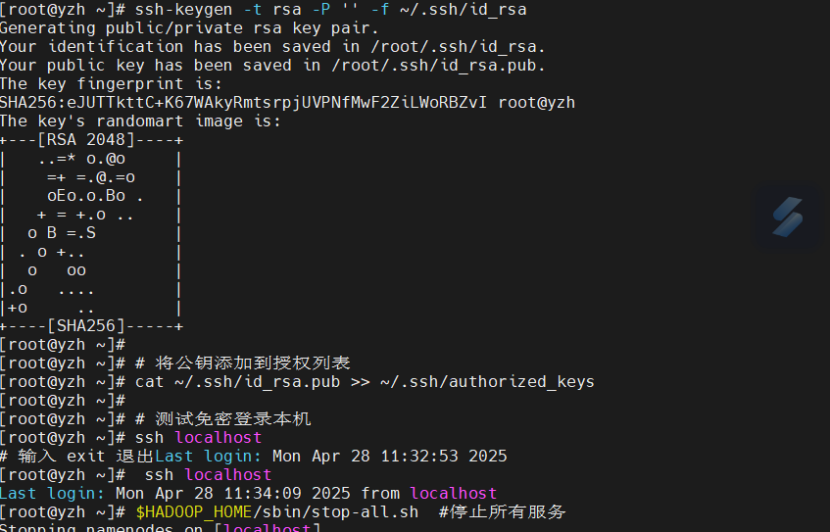
# 生成 SSH 密钥(如果已有密钥可跳过)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
# 将公钥添加到授权列表
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 测试免密登录本机
ssh localhost
# 输入 exit 退出
3.3.3 修改 Hadoop 配置文件
cd /opt/hadoop/etc/hadoop
编辑 core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><property><name>hadoop.tmp.dir</name><value>/tmp/hadoop-tmp</value></property>
</configuration>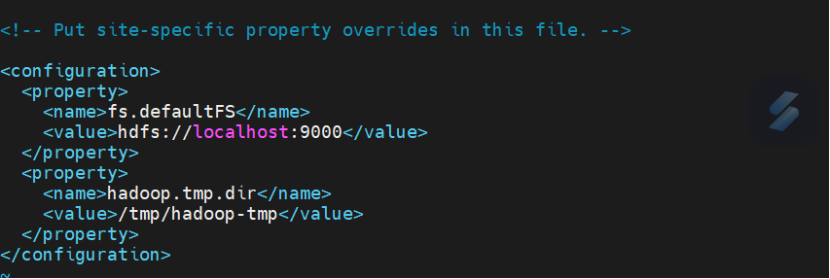
编辑 hdfs-site.xml
配置 HDFS 副本数(伪分布式设为 1):
<configuration><property><name>dfs.replication</name><value>1</value></property><!-- 启用 Web 访问接口 --><property><name>dfs.namenode.http-address</name><value>localhost:9870</value></property>
</configuration>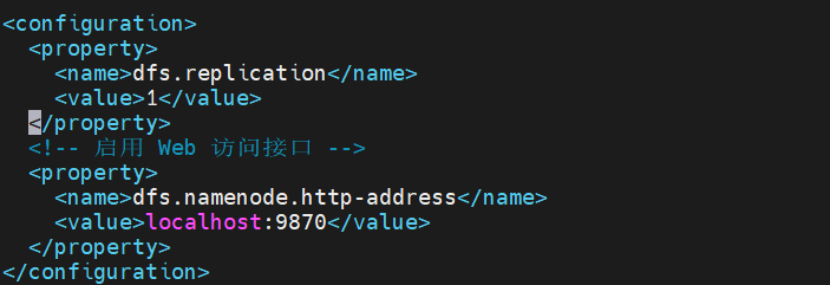
编辑 mapred-site.xml
指定 MapReduce 使用 YARN 框架
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
编辑 yarn-site.xml
配置 YARN 资源管理:
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>localhost</value></property>
</configuration>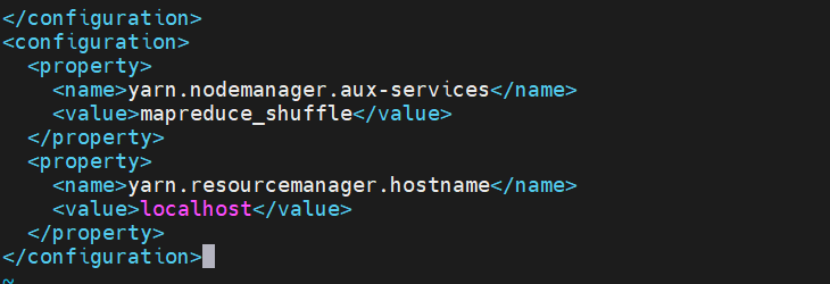
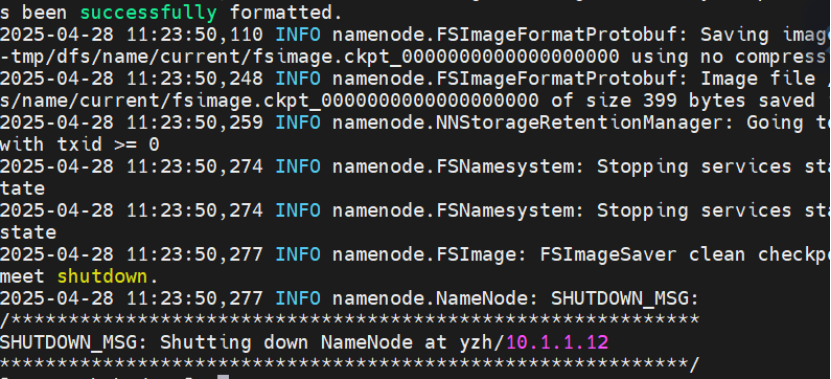
3.3.4 格式化 HDFS
首次启动前需格式化 NameNode:
hdfs namenode -format
编辑 Hadoop 环境配置文件
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
export JAVA_HOME=/opt/jdk1.8 # 替换为你的实际路径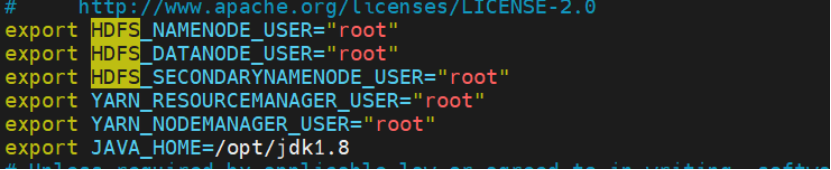
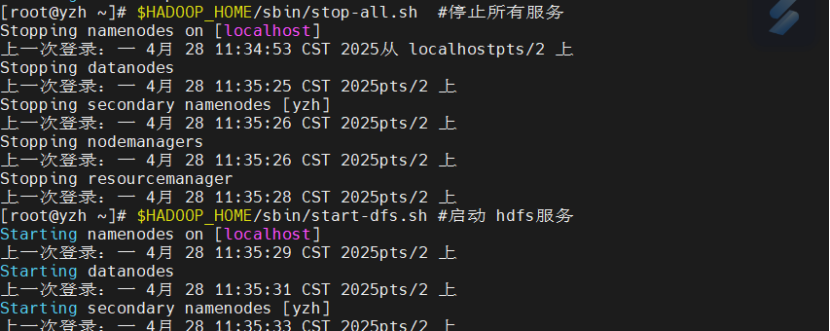
启动服务
$HADOOP_HOME/sbin/stop-all.sh
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
查看
输入jps
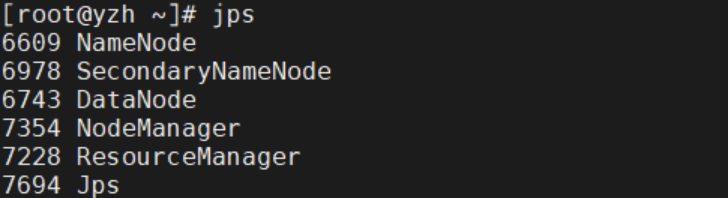
分布式安装已经完成
停止服务
# 停止 YARN
$HADOOP_HOME/sbin/stop-yarn.sh
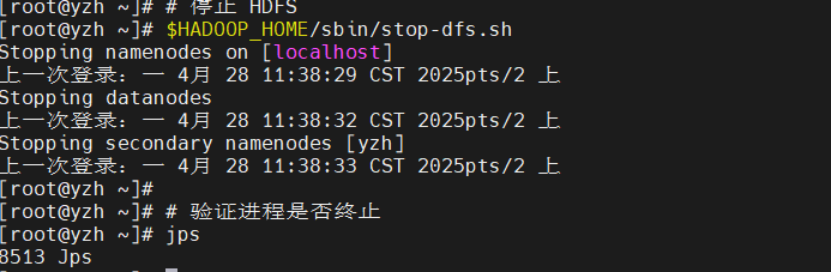
# 停止 HDFS
$HADOOP_HOME/sbin/stop-dfs.sh
# 验证进程是否终止
jps
# 应仅剩余 Jps 进程(或无 Hadoop 相关进程)
通过本文的步骤,你已完成:
- 单节点模拟集群环境搭建
- HDFS + YARN + MapReduce核心组件配置
- 经典WordCount任务验证
- 常见问题排查方法
此环境可作为学习:
- HDFS文件操作(
hdfs dfs -put/get/ls) - YARN资源调度
- Spark on Hadoop集成
- Hive数据仓库搭建
的基础平台。建议后续通过修改workers文件并配置多节点SSH免密登录,逐步扩展为完全分布式集群。