大数据系列 | 日志数据采集工具Logstash的架构分析及应用
大数据系列 | 日志数据采集工具Logstash的架构分析及应用
- 1. Logstash原理分析
- 2. Logstash架构分析
- 3. Logstash的应用
- 3.1. 安装Logstash
- 3.2. Logstash采集所有日志案例实战
- 3.3. Logstash采集异常日志案例实战
1. Logstash原理分析
Logstash是Elastic公司开源的收集、解析和转换日志的工具,可以方便地把分散的、多样化的日志收集起来,然后进行自定义处理,最后将其传输到指定的目的地。Logstash是由JRuby语言编写的,使用基于消息的简单架构,在JVM上运行。
Logstash常被用于在日志关系系统中作为日志采集设备,最常被用于ELK(Elasticsearch +Logstash + Kibana)中作为日志收集器。
2. Logstash架构分析
Logstash的架构非常简单,类似于Flume,主要由Input、Filter和Output组成。Logstash收集日志的基本流程是:Input→Filter→Output,如下图:
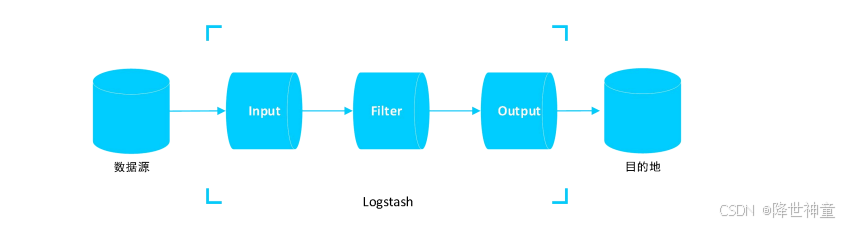
■ Input:输入数据源。
■ Filter:数据处理。
■ Output:输出目的地。
Filter 组件是可选项,Input组件和Output组件是不能缺少
● Input:用于指定数据源获取数据,常见的插件有 stdin、file、syslog、kafka,如下图:
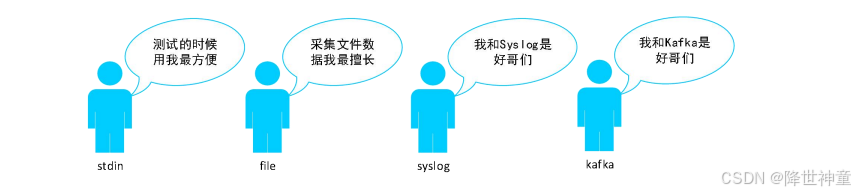
■ stdin:从标准输入(默认是键盘)读取数据,一次读取一行数据。
■ file:监控指定目录下的文件,采集文件中的新增数据。
■ syslog:采集 Syslog 日志服务器中的日志数据。
■ kafka:采集 Kafka
Filter:用于处理数据,例如格式转换、数据派生等。常见的插件有grok、mutate、drop、geoip 等,如下图
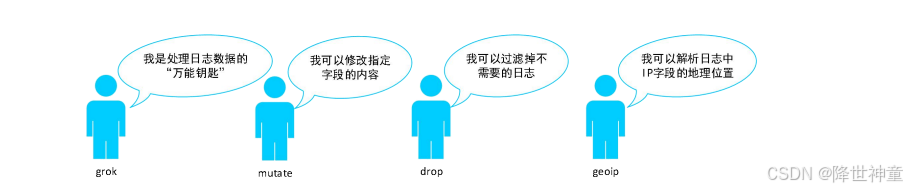
■ grok:支持 120 多种内置的表达式,在解析Syslog 日志、Apache日志、MySQL日志等格式的数据上表现是非常完美的。它也支持自定义正则表达式对数据进行处理。
■ mutate:此过滤器可以修改指定字段的内容,支持convert()、rename()、replace()、split()等函数。
■ drop:过滤掉不需要的日志。例如:Java 程序中会产生大量的日志,包括 DEBUG、INFO、WARN和 ERROR 级别的日志,如果只想保留部分级别的日志,那drop可以帮助你。
■ geoip:从日志中的IP字段获取用户访问时的所在地
● Output:用于指定数据输出目的地,常见的插件有stdout、elasticsearch、kafka、webhdfs 等,如下图:
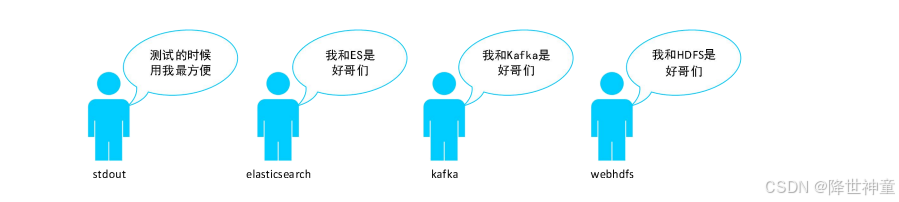
■ stdout:将数据输出到标准输出(默认是控制台)。
■ elasticsearch:将数据输出到 Elasticsearch 的指定 Index 中。
■ kafka:将数据输出到 Kafka 的指定 Topic 中。
■ webhdfs:将数据输出到 HDFS 的指定目录下
Logstash 中的 Input、Filter 和 Output 都是以插件的形式存在的
3. Logstash的应用
Logstash官方下载地址:https://www.elastic.co/cn/downloads/logstash
由于Logstash是在JVM平台上运行的,所以也需要依赖Java环境,Logstash从 7.x 版本开始内置了OpenJDK,位于Logstash下的jdk目录下,也可以使用机器中已有的jdk
3.1. 安装Logstash
[root@logstash ~]# tar xf logstash-8.14.3-linux-x86_64.tar.gz
这样就安装好了。Logstash可以实现零配置安装,使用起来非常方便,此时不需要启动任何进程,只有在配置好采集任务之后才需要启动Logstash。
3.2. Logstash采集所有日志案例实战
接下来看一个Hello World案例。Input使用stdin插件,Output使用stdout插件,这样就可以接收键盘输入的数据,然后将其直接输出到控制台上,如图下图所示:
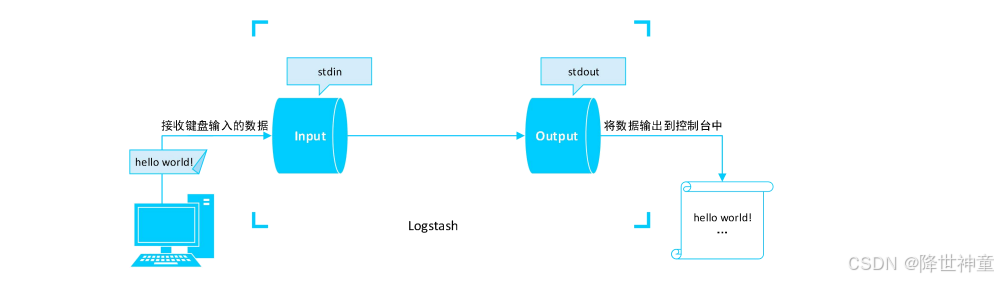
要实现此案例,最快速的方式就是使用Logstash安装目录下的bin/logstash脚本,之后通过-e 参数指定使用的插件配置信息。针对stdin和stdout插件,这里使用最精简的配置:
[root@logstash logstash-8.14.3]# bin/logstash -e 'input { stdin { } } output { stdout {} }'
Using bundled JDK: /root/logstash-8.14.3/jdk
Sending Logstash logs to /root/logstash-8.14.3/logs which is now configured via log4j2.properties
[2024-07-29T14:11:32,746][INFO ][logstash.runner ] Log4j configuration path used is: /root/logstash-8.14.3/config/log4j2.properties
[2024-07-29T14:11:32,748][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"8.14.3", "jruby.version"=>"jruby 9.4.7.0 (3.1.4) 2024-04-29 597ff08ac1 OpenJDK 64-Bit Server VM 17.0.11+9 on 17.0.11+9 +indy +jit [x86_64-linux]"}
[2024-07-29T14:11:32,751][INFO ][logstash.runner ] JVM bootstrap flags: [-Xms1g, -Xmx1g, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djruby.compile.invokedynamic=true, -XX:+HeapDumpOnOutOfMemoryError, -Djava.security.egd=file:/dev/urandom, -Dlog4j2.isThreadContextMapInheritable=true, -Dlogstash.jackson.stream-read-constraints.max-string-length=200000000, -Dlogstash.jackson.stream-read-constraints.max-number-length=10000, -Djruby.regexp.interruptible=true, -Djdk.io.File.enableADS=true, --add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED, --add-opens=java.base/java.security=ALL-UNNAMED, --add-opens=java.base/java.io=ALL-UNNAMED, --add-opens=java.base/java.nio.channels=ALL-UNNAMED, --add-opens=java.base/sun.nio.ch=ALL-UNNAMED, --add-opens=java.management/sun.management=ALL-UNNAMED, -Dio.netty.allocator.maxOrder=11]
[2024-07-29T14:11:32,752][INFO ][logstash.runner ] Jackson default value override `logstash.jackson.stream-read-constraints.max-string-length` configured to `200000000`
[2024-07-29T14:11:32,752][INFO ][logstash.runner ] Jackson default value override `logstash.jackson.stream-read-constraints.max-number-length` configured to `10000`
[2024-07-29T14:11:32,759][INFO ][logstash.settings ] Creating directory {:setting=>"path.queue", :path=>"/root/logstash-8.14.3/data/queue"}
[2024-07-29T14:11:32,760][INFO ][logstash.settings ] Creating directory {:setting=>"path.dead_letter_queue", :path=>"/root/logstash-8.14.3/data/dead_letter_queue"}
[2024-07-29T14:11:32,943][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2024-07-29T14:11:32,963][INFO ][logstash.agent ] No persistent UUID file found. Generating new UUID {:uuid=>"73ab0a6e-f93f-4ee8-99aa-bfbd5ac65ae5", :path=>"/root/logstash-8.14.3/data/uuid"}
[2024-07-29T14:11:33,528][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[2024-07-29T14:11:33,726][INFO ][org.reflections.Reflections] Reflections took 113 ms to scan 1 urls, producing 132 keys and 468 values
[2024-07-29T14:11:33,945][INFO ][logstash.javapipeline ] Pipeline `main` is configured with `pipeline.ecs_compatibility: v8` setting. All plugins in this pipeline will default to `ecs_compatibility => v8` unless explicitly configured otherwise.
[2024-07-29T14:11:33,977][INFO ][logstash.javapipeline ][main] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["config string"], :thread=>"#<Thread:0x21b08b10 /root/logstash-8.14.3/logstash-core/lib/logstash/java_pipeline.rb:134 run>"}
[2024-07-29T14:11:34,462][INFO ][logstash.javapipeline ][main] Pipeline Java execution initialization time {"seconds"=>0.48}
The stdin plugin is now waiting for input:
[2024-07-29T14:11:34,488][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"}
[2024-07-29T14:11:34,500][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
input { }内部指定了stdin插件。对于stdin插件可以添加一些内置支持的参数,把需要添加的参数放在stdin后面的括号内即可。
output { }内部指定了stdout插件。对于stdout插件可以添加一些内置支持的参数,把需要添加的参数放在stdout后面的括号内即可
启动成功之后就可以直接在命令行中输入“hello world!”,然后按 Enter 键,即可看到输出的结果信息
hello world!
{"event" => {"original" => "hello world!"},"message" => "hello world!","@version" => "1","host" => {"hostname" => "logstash"},"@timestamp" => 2024-07-29T06:42:24.351046661Z
}
此时我们会发现输出的数据是JSON格式的,其中包含4个字段,我们输入的数据保存在message字段中,其余几个字段是 Logstash默认产生的,这就是Logstash默认的数据输出格式
logstack运行在5044端口上:
ss -tnlp | grep 5044
LISTEN 0 128 [::]:5044 [::]:* users:(("java",pid=21417,fd=99))
stdin插件参数:
在使用stdin和stdout插件时还可以添加一些参数。
首先来看一下stdin插件。stdin插件支持的参数包括add_field、codec、enable_metric、id、tags和type。这些参数都不是必填参数,我们在使用时可以省略它们。add_field参数表示可以向原始数据中添加一个字段,该参数的值是 hash 类型的。查阅官网资料可知,hash 类型其实就是 key→value这种格式的数据。
下面以add_field参数为例来演示一下插件中参数的使用。需求是向原始数据中添加一个字段data_type,值为 video,表示Logstash采集的这份数据是视频数据。
[root@logstash logstash-8.14.3]# bin/logstash -e 'input { stdin {add_field=>{"data_type"=>"video"} } } output { stdout { } }'
***********************************省略部分************************************************
hello logstash!
{"event" => {"original" => "hello logstash!"},"@timestamp" => 2024-07-29T06:54:19.618952990Z,"data_type" => "video","message" => "hello logstash!","@version" => "1","host" => {"hostname" => "logstash"}
}
在Logstash启动之后输入“hello logstash!”,查看输出的数据,发现其中多了一个data_type 字段,值为video。
Logstash支持把这些配置保存到一个配置文件中,然后在“bin/logstash”脚本后面通过-f 参数指定这个配置文件的位置:
[root@logstash logstash-8.14.3]# cat config/stdin-stdout.conf
input{stdin{add_field=>{"data_type"=>"video"}}
}
output{stdout{ }
}[root@logstash logstash-8.14.3]# bin/logstash -f config/stdin-stdout.conf
***********************************省略部分************************************************
{"@timestamp" => 2024-07-29T07:00:56.674284123Z,"event" => {"original" => ""},"message" => "","host" => {"hostname" => "logstash"},"@version" => "1","data_type" => "video"
}
stdout插件参数:
stdout插件支持的参数包括codec、enable_metric 和 id。
这些参数也都不是必填参数。其中的codec参数可以对数据进行格式化,主要用来编码、解码事件,所以它常用在Input组件和 Output组件中。
下面来演示一下stdout插件中codec参数的使用,以plain为例。plain主要用于输出普通的纯文本数据。
例如:Logstash中默认的codec参数为JSON格式,如果我们想把采集的原始数据保存到第三方存储介质中,则需要修改codec参数的值,否则向第三方存储介质中存储的就是一个JSON字符串,包含默认的host、message、@version 和@timestamp 字段信息。
可以在plain中设置format参数,以解析接收到的字符串中的message字段的值。
[root@logstash logstash-8.14.3]# cat config/stdin-stdout.conf
input{stdin{add_field=>{"data_type"=>"video"}}
}
output{stdout{codec=> plain{format=>"%{message}"}}
}
此时,启动Logstash,输入“hello logstash!”,会发现输出的结果还是“hello logstash!“
[root@logstash logstash-8.14.3]# bin/logstash -f config/stdin-stdout.conf
***********************************省略部分************************************************
hello world!
hello world!hello logstash
hello logstash
3.3. Logstash采集异常日志案例实战
Codec 还支持多种数据格式,其中有一个multiline格式大家需要关注一下。multiline格式一般用在Input组件中,用于在采集日志数据时合并多行日志数据。
例如:应用程序在运行时会产生一些异常日志信息,每一条异常日志信息都会有多行。如果使用传统的采集思路一行行地采集,那么后期是无法查看某一条异常日志的详细堆栈信息的。multiline格式可以解决这个问题,它可以根据一定的规则把多行日志信息保存到一行中。
下面来看一个案例:通过Logstash采集服务器中应用程序运行期间产生的日志信息,特别是异常日志信息,采集到之后将其存储到 Elasticsearch(简称 ES)中,对外提供异常日志检索服务。
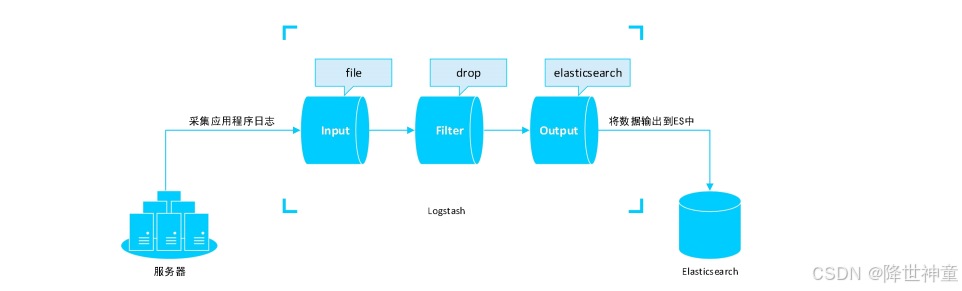
对于此案例,Input使用file插件,采集指定日志文件中的新增日志数据;Filter使用drop插件,过滤掉DEBUG和INFO级别的日志数据;Output使用elasticsearch插件,将采集到的数据保存到ES中。(由于本实验我没有ES环境,所以直接将Output输出到终端)
在使用 file 插件采集日志文件数据时,需要将属于同一个异常的多行日志数据整合到一行中,以便于后期查询分析异常日志
此案例中对应的配置文件 file-drop-es.conf内容如下:
[root@logstash config]# cat file-drop-output.conf
input{file{path=>"/data/log/proj1.log"start_position=>"beginning"codec=>multiline{pattern=>"^%{TIMESTAMP_ISO8601}"negate=>truewhat => "previous"}}
}
filter{if [message] =~ "DEBUG" {drop{}} else if [message] =~ "INFO" {drop{}}
}
output{stdout{codec=> plain{format=>"%{message}"}}
}
配置文件核心参数分析:
在input中的file插件中指定了codec→multiline,其中指定了以下 3 个参数。
■ pattern:必填参数,设置要匹配数据的正则表达式,这里面用到了TIMESTAMP_ISO8601这个时间变量,再加上^,表示匹配每一行前面不是以时间开头的日志数据,因为异常日志的详细堆栈信息都不是以日期开头的。
■ negate:可选参数,值为true或者false,默认值为false。true表示不满足 pattern 中指定规则的数据将被保留下来,被下面的what参数应用。
■ what:必填参数,值为previous或者next。如果pattern中指定的规则与数据匹配,当值为previous时,表示指定将匹配到的那一行数据与前一行数据合并;当值为next 时,表示指定将匹配到的那一行数据与后一行数据合并
通过这3个参数的配合,可以将任何不以时间戳开头的日志数据与前一行数据进行合并,这样即可将同一个异常日志的多行堆栈信息都整合到一行
在filter中用到了drop插件,使用if和else if,通过“=~”实现模式匹配,将DEBUG和INFO级别的日志数据过滤掉。
启动 Logstash 执行此采集任务:
[root@logstash logstash-8.14.3]# bin/logstash -f config/file-drop-output.conf
Using bundled JDK: /root/logstash-8.14.3/jdk
Sending Logstash logs to /root/logstash-8.14.3/logs which is now configured via log4j2.properties
[2024-08-01T14:09:35,112][INFO ][logstash.runner ] Log4j configuration path used is: /root/logstash-8.14.3/config/log4j2.properties
[2024-08-01T14:09:35,114][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"8.14.3", "jruby.version"=>"jruby 9.4.7.0 (3.1.4) 2024-04-29 597ff08ac1 OpenJDK 64-Bit Server VM 17.0.11+9 on 17.0.11+9 +indy +jit [x86_64-linux]"}
[2024-08-01T14:09:35,117][INFO ][logstash.runner ] JVM bootstrap flags: [-Xms1g, -Xmx1g, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djruby.compile.invokedynamic=true, -XX:+HeapDumpOnOutOfMemoryError, -Djava.security.egd=file:/dev/urandom, -Dlog4j2.isThreadContextMapInheritable=true, -Dlogstash.jackson.stream-read-constraints.max-string-length=200000000, -Dlogstash.jackson.stream-read-constraints.max-number-length=10000, -Djruby.regexp.interruptible=true, -Djdk.io.File.enableADS=true, --add-exports=jdk.compiler/com.sun.tools.javac.api=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED, --add-exports=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED, --add-opens=java.base/java.security=ALL-UNNAMED, --add-opens=java.base/java.io=ALL-UNNAMED, --add-opens=java.base/java.nio.channels=ALL-UNNAMED, --add-opens=java.base/sun.nio.ch=ALL-UNNAMED, --add-opens=java.management/sun.management=ALL-UNNAMED, -Dio.netty.allocator.maxOrder=11]
[2024-08-01T14:09:35,119][INFO ][logstash.runner ] Jackson default value override `logstash.jackson.stream-read-constraints.max-string-length` configured to `200000000`
[2024-08-01T14:09:35,119][INFO ][logstash.runner ] Jackson default value override `logstash.jackson.stream-read-constraints.max-number-length` configured to `10000`
[2024-08-01T14:09:35,318][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2024-08-01T14:09:36,124][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[2024-08-01T14:09:36,553][INFO ][org.reflections.Reflections] Reflections took 128 ms to scan 1 urls, producing 132 keys and 468 values
[2024-08-01T14:09:37,064][INFO ][logstash.javapipeline ] Pipeline `main` is configured with `pipeline.ecs_compatibility: v8` setting. All plugins in this pipeline will default to `ecs_compatibility => v8` unless explicitly configured otherwise.
[2024-08-01T14:09:37,107][INFO ][logstash.javapipeline ][main] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>250, "pipeline.sources"=>["/root/logstash-8.14.3/config/file-drop-output.conf"], :thread=>"#<Thread:0x2b163b16 /root/logstash-8.14.3/logstash-core/lib/logstash/java_pipeline.rb:134 run>"}
[2024-08-01T14:09:37,821][INFO ][logstash.javapipeline ][main] Pipeline Java execution initialization time {"seconds"=>0.71}
[2024-08-01T14:09:37,835][INFO ][logstash.inputs.file ][main] No sincedb_path set, generating one based on the "path" setting {:sincedb_path=>"/root/logstash-8.14.3/data/plugins/inputs/file/.sincedb_6d84e1a858fb64cf30adc801e0a9b809", :path=>["/data/log/proj1.log"]}
[2024-08-01T14:09:37,844][INFO ][filewatch.observingtail ][main][e4bbcfb25b391c5cf7c0f767bd6d9b81753403ad55c97ab95c7abc13833d084c] START, creating Discoverer, Watch with file and sincedb collections
[2024-08-01T14:09:37,857][INFO ][logstash.javapipeline ][main] Pipeline started {"pipeline.id"=>"main"}
[2024-08-01T14:09:37,870][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}然后,向“/data/log/proj1.log”日志文件中模拟产生异常日志数据,即通过 vi 命令向文件中添加数据并保存文件。
[root@logstash ~]# vim /data/log/proj1.log
2024-08-24 12:15:54,985 [main] [test.applog.LogPruducer] [DEBUG] - 初始化链接成功!
2024-08-24 12:15:55,985 [main] [test.applog.LogPruducer] [INFO] - 开始执行计算操作!
2024-08-24 12:15:56,985 [main] [test.applog.LogPruducer] [ERROR] - 除零异常。java.lang.ArithmeticException: / by zero at xuwei.applog.LogPruducer.main(LogPruducer.java:12)
2024-08-24 12:15:57,988 [main] [test.applog.LogPruducer] [ERROR] - 计算执行失败!
2024-08-24 12:15:58,985 [main] [test.applog.LogPruducer] [DEBUG] - 释放链接!
然后就可以在控制台看到如下输出:
2024-08-24 12:15:56,985 [main] [test.applog.LogPruducer] [ERROR] - 除零异常。java.lang.ArithmeticException: / by zero at xuwei.applog.LogPruducer.main(LogPruducer.java:12)2024-08-24 12:15:57,988 [main] [test.applog.LogPruducer] [ERROR] - 计算执行失败!
最后,查看此链接返回数据中的message字段,可以看到ERROR级别的多行异常日志数据被整合到了一行,并且过滤掉了 DEBUG和INFO级别的日志数据。