Python实战:爬取百度热搜榜,制作动态可视化报告
今天,我将带大家用Python实现一个完整的项目:爬取百度热搜榜,并生成高颜值的柱状图和词云图。这个进阶版教程不仅能让你学会基础爬虫,还将深入数据可视化,让你轻松驾驭分词、配色和自定义图形,最终效果绝对让你眼前一亮!
一、项目准备:工欲善其事,必先利其器
在开始编写代码前,我们需要安装几个强大的Python库。如果你还没有安装,请打开终端或命令提示符,执行以下命令:
pip install requests beautifulsoup4 pandas matplotlib wordcloud jieba opencv-python
requests: 强大的HTTP库,用于向百度发送请求并获取网页内容。
beautifulsoup4: 网页解析库,能够从HTML中轻松提取我们想要的数据。
pandas: 数据处理神器,将爬取的数据整理成结构化的表格,便于后续分析和保存。
matplotlib: 绘图库,我们将用它来绘制柱状图和词云图。
wordcloud: 专门用于生成词云图的库。
jieba: 中文分词库,处理中文文本时的必备工具,能准确地将句子切分成词语。
opencv-python: 用于读取图像文件,以实现词云图的自定义形状。
二、核心代码详解
这个项目的核心代码被封装在几个函数中,每个函数负责一个特定的功能,使得代码结构清晰、易于维护。
1. 爬取热搜榜单(Top 30)
我们首先定义一个get_baidu_hot_search函数,它负责访问百度热搜页面,并使用BeautifulSoup解析HTML,提取出排名前30的热搜标题和热度值。
def get_baidu_hot_search():url = "https://top.baidu.com/board?tab=realtime"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"}try:response = requests.get(url, headers=headers)response.raise_for_status()soup = BeautifulSoup(response.text, 'html.parser')hot_items = soup.find_all(class_='category-wrap_iQLoo') hot_searches = []for item in hot_items[:30]:div_title_element = item.select_one('div.content_1YWBm')title_element = div_title_element.select_one('div.c-single-text-ellipsis')hot_value_element = item.find(class_='hot-index_1Bl1a')if title_element and hot_value_element:title = title_element.get_text().strip()hot_value = hot_value_element.get_text().strip()hot_searches.append({"title": title, "hot_value": hot_value})return hot_searchesexcept requests.exceptions.RequestException as e:print(f"请求百度热搜失败: {e}")return Noneexcept Exception as e:print(f"解析热搜数据失败: {e}")return None代码要点:
使用
requests发送GET请求,并设置User-Agent模拟浏览器访问。
soup.find_all(class_='category-wrap_iQLoo'):这是爬虫最核心的部分,通过观察网页源代码,我们找到包含每个热搜信息的CSS选择器。
item.select_one()和item.find():通过这些方法精准地从每个热搜条目中提取出标题和热度值。
2. 数据处理与CSV保存
process_hot_search_data函数负责清洗数据,特别是将热度值中的“万”和“亿”转换成实际的数字,方便后续的图表绘制。save_to_csv函数则使用pandas的to_csv方法将处理好的数据保存到本地。
def process_hot_search_data(hot_searches_data):if not hot_searches_data:return Nonetitles = [item['title'] for item in hot_searches_data]hot_values = []for item in hot_searches_data:try:hot_value_str = item['hot_value']if '万' in hot_value_str:hot_values.append(float(hot_value_str.replace('万', '')) * 10000)elif '亿' in hot_value_str:hot_values.append(float(hot_value_str.replace('亿', '')) * 100000000)else:hot_values.append(float(hot_value_str))except ValueError:hot_values.append(0.0)df = pd.DataFrame({'title': titles,'hot_value': hot_values})return dfdef save_to_csv(df, filename='baidu_hot_search.csv'):if df is None or df.empty:print("没有数据可保存到 CSV。")returntry:df.to_csv(filename, index=False, encoding='utf-8-sig')print(f"数据已成功保存到 {filename}")except Exception as e:print(f"保存数据到 CSV 失败: {e}")
3. 增强型数据可视化
这是本项目的亮点所在,我们精心设计的图表,能让数据一目了然。
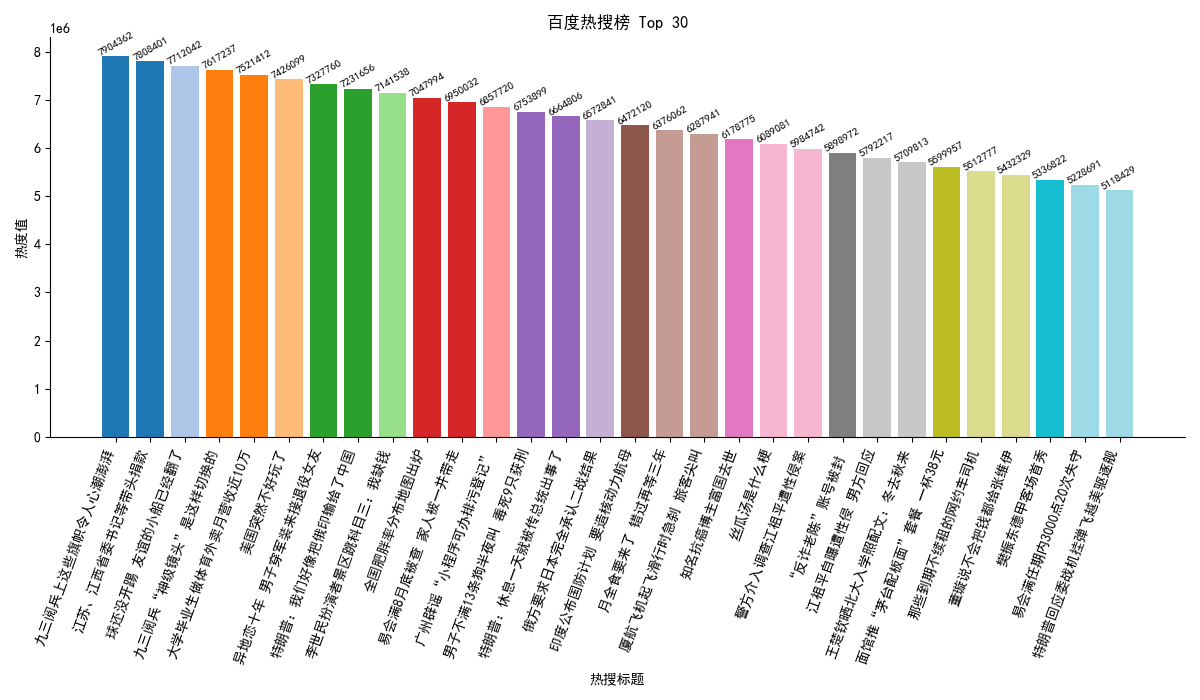
a) 绘制炫彩柱状图
我们对柱状图进行了三处增强:
每个柱子不同颜色:通过
plt.cm.tab20配色方案为每个热点分配了不同的颜色。热度值标签:在每个柱子上方显示热度值,让数据更加直观。
移除多余边框:隐藏了图表上部和右侧的边框,使图表更加简洁、专业。
def plot_bar_chart(df, font_path):if df is None or df.empty:print("没有数据可用于绘制柱状图。")returntry:my_font = fm.FontProperties(fname=font_path)plt.rcParams['font.sans-serif'] = [my_font.get_name()]plt.rcParams['axes.unicode_minus'] = Falseexcept Exception as e:print(f"加载字体失败,请检查字体路径或安装中文字体: {e}")print("图表中的中文可能无法正常显示。")df_sorted = df.sort_values(by='hot_value', ascending=False)plt.figure(figsize=(12, 7), dpi=100)colors = plt.cm.tab20(np.linspace(0, 1, len(df_sorted)))bars = plt.bar(df_sorted['title'], df_sorted['hot_value'], color=colors)for bar in bars:height = bar.get_height()plt.text(bar.get_x() + bar.get_width() / 2, height, f'{int(height)}', ha='center', va='bottom', fontsize=8, rotation=30)ax = plt.gca()ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)plt.xlabel("热搜标题")plt.ylabel("热度值")plt.title("百度热搜榜 Top 30")plt.xticks(rotation=70, ha='right')plt.tight_layout()plt.show()b) 智能词云图(分词+自定义形状)
为了让词云图更具表现力,我们引入了两个关键技术:
中文分词与停用词过滤:
使用
jieba.cut()对热搜标题进行精确分词。定义一个
stopwords列表,将“的”、“了”、“啊”等无意义的词语过滤掉,确保词云图中的词语都是有价值的核心词汇。自定义图片形状:
WordCloud库支持用图片作为词云的形状蒙版(mask)。我们使用
imread函数读取你指定的图片。
def plot_wordcloud(df, font_path, mask_image_path=None):if df is None or df.empty:print("没有数据可用于绘制词云图。")return# 获取所有热搜标题并拼接成一个长字符串long_text = ' '.join(df['title'].tolist())# 1. 中文分词# jieba.cut 返回一个生成器,用 list() 转换为列表seg_list = jieba.cut(long_text, cut_all=False) # 精确模式分词# 2. 定义或加载停用词# 你可以添加更多你觉得无用的词语,例如:'...', '!', '?' 等stopwords = ['的', '了', '啊', '我', '你', '是', '在', '就', '也', '和', '有', '都', '这些', '好像', '这些'] # 3. 过滤停用词,并重新拼接成一个字符串filtered_words = [word for word in seg_list if word not in stopwords and len(word) > 1] # 过滤掉停用词和单个字的词final_text = ' '.join(filtered_words)# 如果过滤后没有词语,则直接返回if not final_text.strip():print("警告:分词和过滤后没有有效词语,无法生成词云。")returntry:fm.FontProperties(fname=font_path)except Exception as e:print(f"加载字体失败,请检查字体路径: {e}")font_path = Nonemask = Noneif mask_image_path:try:# 这里的 mask 读取方式可以保持不变,或者使用PIL库mask = imread(mask_image_path)except FileNotFoundError:print(f"警告:找不到词云 Mask 图片文件: {mask_image_path}")except Exception as e:print(f"警告:加载词云 Mask 图片失败: {e}")mask = Nonewordcloud = WordCloud(font_path=font_path,width=800,height=600,background_color='white',colormap='tab10',mask=mask,max_words=300).generate(final_text) # 使用过滤后的 final_textplt.figure(figsize=(10, 7), dpi=100)plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')ax = plt.gca()ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)plt.title("百度热搜词云图")plt.show()c) 本项目所用词云

三、完整代码与运行
1. 完整代码
下面是整合了所有功能的完整代码。请将此代码保存为 baidu-tops.py 文件。在运行前,请务必根据你的系统,修改 CHINESE_FONT_PATH 变量为你的中文字体路径,并确保词云图的 MASK_IMAGE_PATH 指向一个有效的图片文件。
import requests, jieba
from bs4 import BeautifulSoup
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
from wordcloud import WordCloud
import numpy as np
from cv2 import imreaddef get_baidu_hot_search():url = "https://top.baidu.com/board?tab=realtime"headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"}try:response = requests.get(url, headers=headers)response.raise_for_status()soup = BeautifulSoup(response.text, 'html.parser')hot_items = soup.find_all(class_='category-wrap_iQLoo') hot_searches = []for item in hot_items[:30]:div_title_element = item.select_one('div.content_1YWBm')title_element = div_title_element.select_one('div.c-single-text-ellipsis')hot_value_element = item.find(class_='hot-index_1Bl1a')if title_element and hot_value_element:title = title_element.get_text().strip()hot_value = hot_value_element.get_text().strip()hot_searches.append({"title": title, "hot_value": hot_value})return hot_searchesexcept requests.exceptions.RequestException as e:print(f"请求百度热搜失败: {e}")return Noneexcept Exception as e:print(f"解析热搜数据失败: {e}")return Nonedef process_hot_search_data(hot_searches_data):if not hot_searches_data:return Nonetitles = [item['title'] for item in hot_searches_data]hot_values = []for item in hot_searches_data:try:hot_value_str = item['hot_value']if '万' in hot_value_str:hot_values.append(float(hot_value_str.replace('万', '')) * 10000)elif '亿' in hot_value_str:hot_values.append(float(hot_value_str.replace('亿', '')) * 100000000)else:hot_values.append(float(hot_value_str))except ValueError:hot_values.append(0.0)df = pd.DataFrame({'title': titles,'hot_value': hot_values})return dfdef plot_bar_chart(df, font_path):if df is None or df.empty:print("没有数据可用于绘制柱状图。")returntry:my_font = fm.FontProperties(fname=font_path)plt.rcParams['font.sans-serif'] = [my_font.get_name()]plt.rcParams['axes.unicode_minus'] = Falseexcept Exception as e:print(f"加载字体失败,请检查字体路径或安装中文字体: {e}")print("图表中的中文可能无法正常显示。")df_sorted = df.sort_values(by='hot_value', ascending=False)plt.figure(figsize=(12, 7))colors = plt.cm.tab20(np.linspace(0, 1, len(df_sorted)))bars = plt.bar(df_sorted['title'], df_sorted['hot_value'], color=colors)for bar in bars:height = bar.get_height()plt.text(bar.get_x() + bar.get_width() / 2, height, f'{int(height)}', ha='center', va='bottom', fontsize=8, rotation=30)ax = plt.gca()ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)plt.xlabel("热搜标题")plt.ylabel("热度值")plt.title("百度热搜榜 Top 30")plt.xticks(rotation=70, ha='right')plt.tight_layout()plt.show()def plot_wordcloud(df, font_path, mask_image_path=None):if df is None or df.empty:print("没有数据可用于绘制词云图。")return# 获取所有热搜标题并拼接成一个长字符串long_text = ' '.join(df['title'].tolist())# 1. 中文分词# jieba.cut 返回一个生成器,用 list() 转换为列表seg_list = jieba.cut(long_text, cut_all=False) # 精确模式分词# 2. 定义或加载停用词# 你可以添加更多你觉得无用的词语,例如:'...', '!', '?' 等stopwords = ['的', '了', '啊', '我', '你', '是', '在', '就', '也', '和', '有', '都', '这些', '好像', '这些'] # 3. 过滤停用词,并重新拼接成一个字符串filtered_words = [word for word in seg_list if word not in stopwords and len(word) > 1] # 过滤掉停用词和单个字的词final_text = ' '.join(filtered_words)# 如果过滤后没有词语,则直接返回if not final_text.strip():print("警告:分词和过滤后没有有效词语,无法生成词云。")returntry:fm.FontProperties(fname=font_path)except Exception as e:print(f"加载字体失败,请检查字体路径: {e}")font_path = Nonemask = Noneif mask_image_path:try:# 这里的 mask 读取方式可以保持不变,或者使用PIL库mask = imread(mask_image_path)except FileNotFoundError:print(f"警告:找不到词云 Mask 图片文件: {mask_image_path}")except Exception as e:print(f"警告:加载词云 Mask 图片失败: {e}")mask = Nonewordcloud = WordCloud(font_path=font_path,width=800,height=600,background_color='white',colormap='tab10',mask=mask,max_words=300).generate(final_text) # 使用过滤后的 final_textplt.figure(figsize=(10, 7), dpi=100)plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')ax = plt.gca()ax.spines['top'].set_visible(False)ax.spines['right'].set_visible(False)plt.title("百度热搜词云图")plt.show()def save_to_csv(df, filename='baidu_hot_search.csv'):if df is None or df.empty:print("没有数据可保存到 CSV。")returntry:df.to_csv(filename, index=False, encoding='utf-8-sig')print(f"数据已成功保存到 {filename}")except Exception as e:print(f"保存数据到 CSV 失败: {e}")# --- 主程序 ---
if __name__ == '__main__':CHINESE_FONT_PATH = 'C:/Windows/Fonts/simhei.ttf' MASK_IMAGE_PATH = 'test.png' print("正在爬取百度热搜数据...")hot_searches_data = get_baidu_hot_search()if hot_searches_data:print("数据爬取成功,正在处理数据...")df_hot_search = process_hot_search_data(hot_searches_data)if df_hot_search is not None:print("数据处理完成,开始生成图表...")plot_bar_chart(df_hot_search, CHINESE_FONT_PATH)plot_wordcloud(df_hot_search, CHINESE_FONT_PATH, MASK_IMAGE_PATH)save_to_csv(df_hot_search)print("\n--- 爬取与可视化过程全部完成! ---")else:print("数据处理失败,无法进行可视化。")else:print("未能成功爬取到百度热搜数据,请检查网络或网页结构。")
2. 运行结果
正在爬取百度热搜数据...
数据爬取成功,正在处理数据...
数据处理完成,开始生成图表...
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\ADMINI~1\AppData\Local\Temp\jieba.cache
Loading model cost 0.563 seconds.
Prefix dict has been built successfully.
数据已成功保存到 baidu_hot_search.csv--- 爬取与可视化过程全部完成! ---a) 生成的柱状图