JVM调优总结
本篇博客记录我的JVM调优方案和总结
-
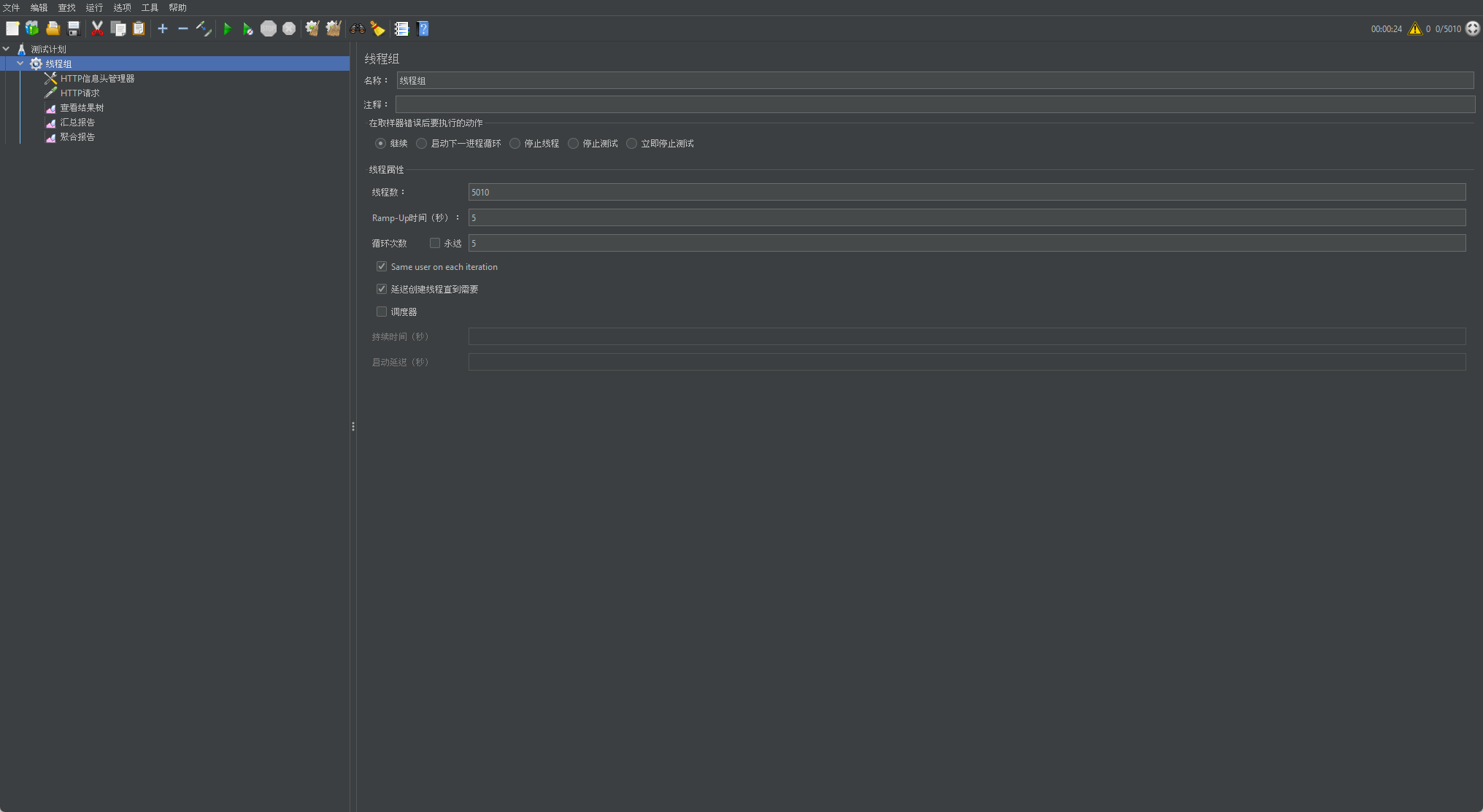
以下为我的JMeter线程组配置
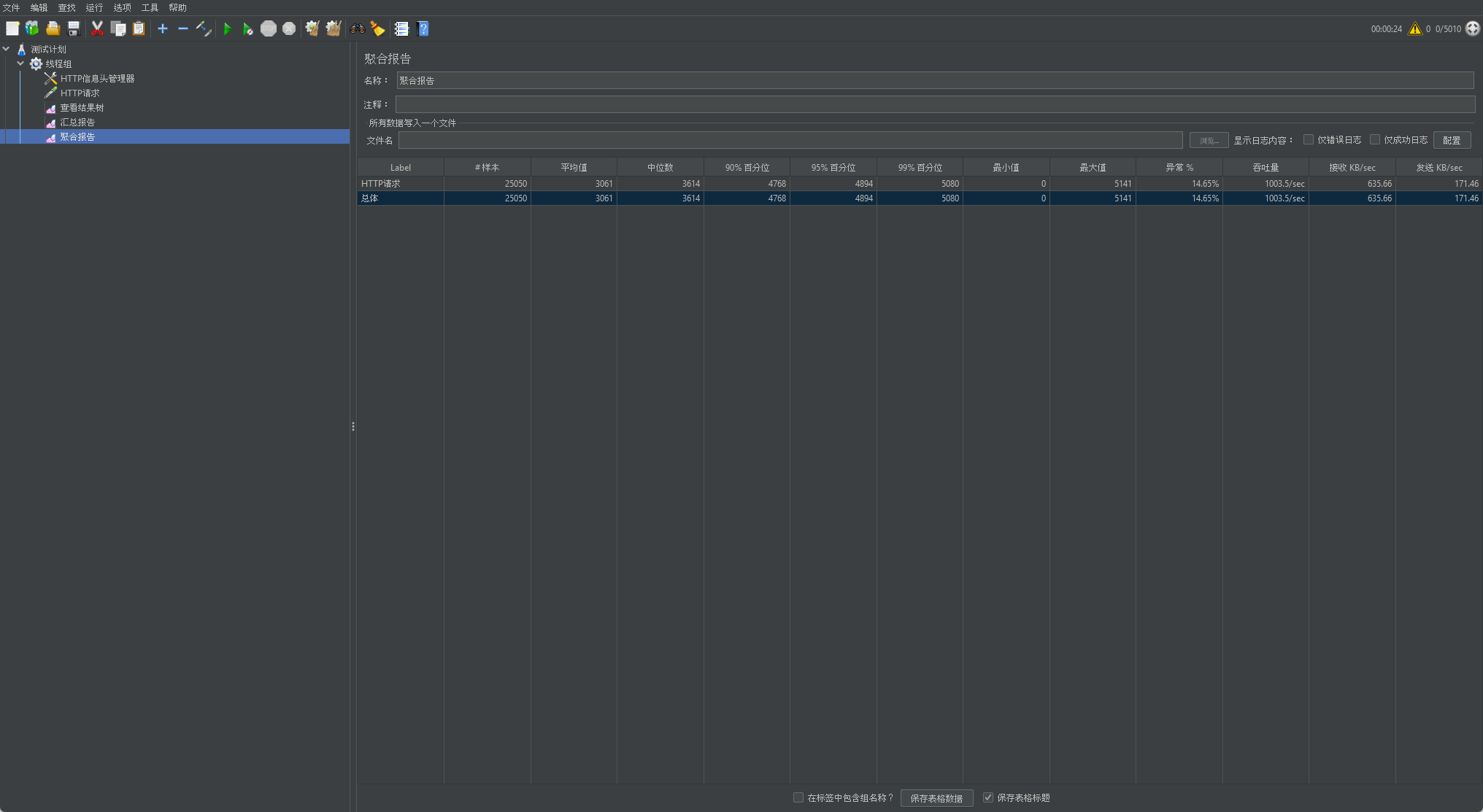
 以下为我项目未优化时的压测结果
以下为我项目未优化时的压测结果
-
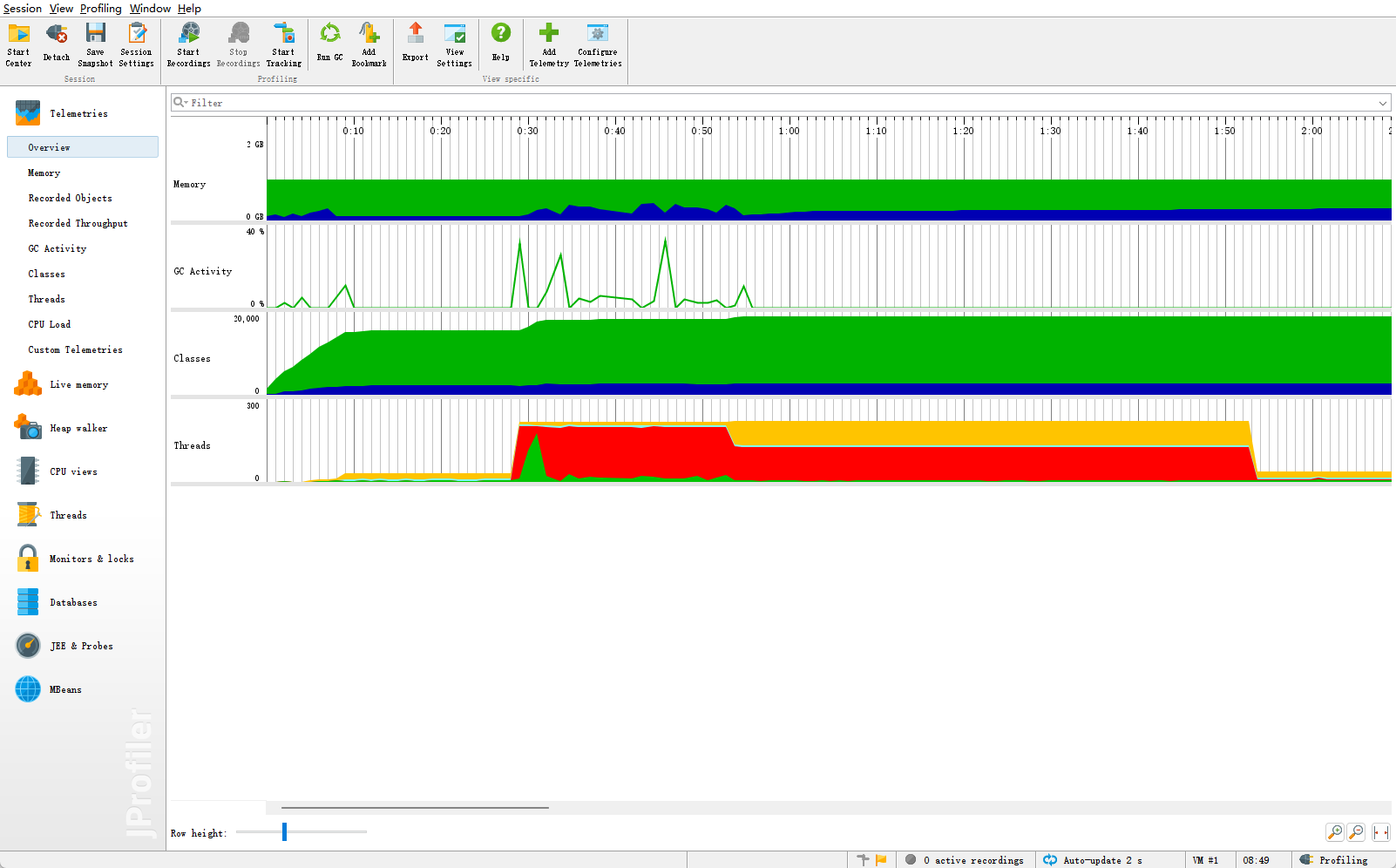
以下为JVM可视化状态图
-
以下为我项目的
jstat分析结果

-
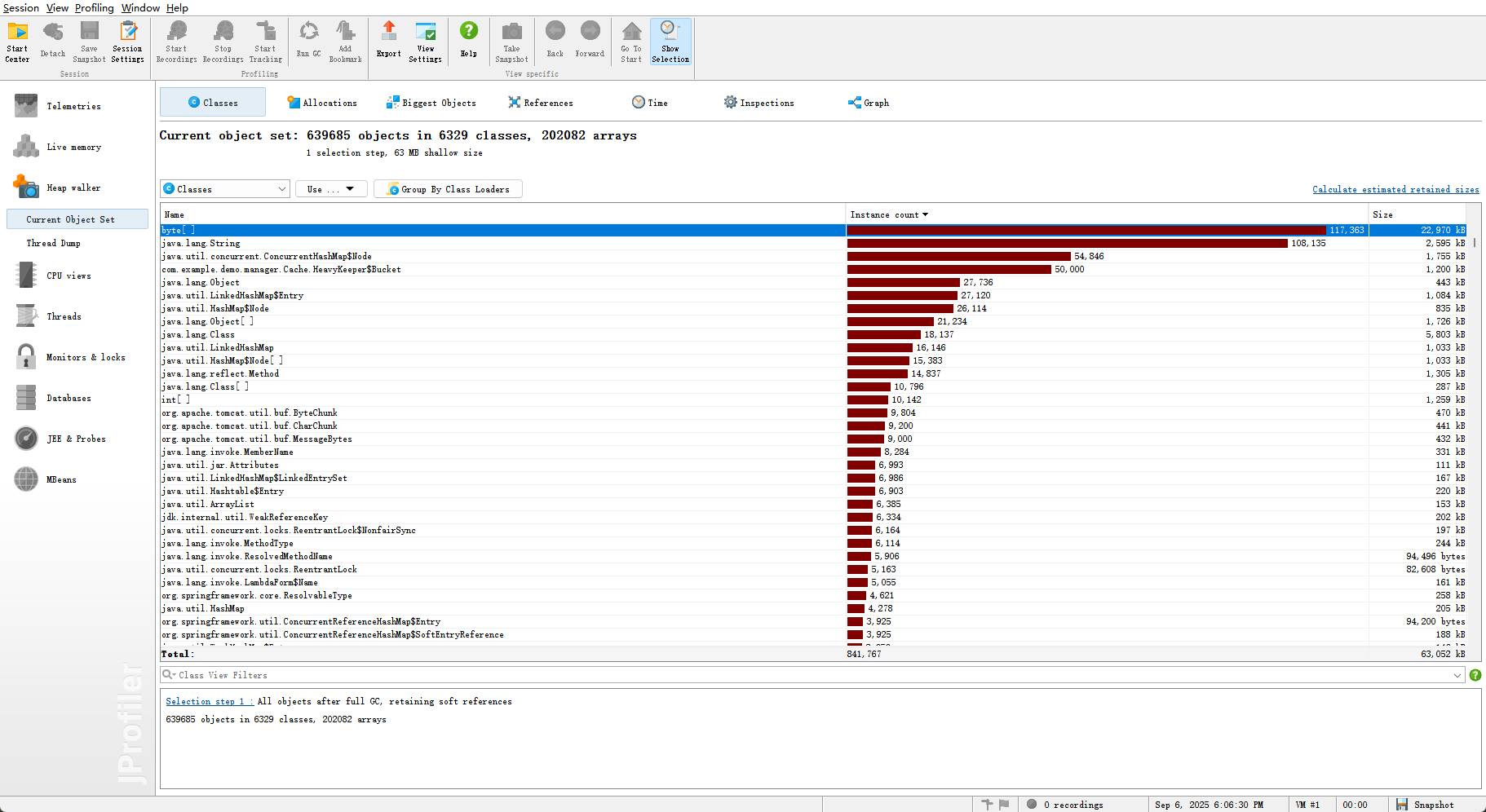
以下为堆转储状态
- JVM配置如下所示
-Xms1g -Xmx1g -XX:+UseSerialGC -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M -XX:G1HeapRegionSize=4m -XX:MaxDirectMemorySize=1g -XX:+DisableExplicitGC
问题分析
JMeter压测结果
- 平均响应时间为3s,99%分位数为5秒,这说明接口响应延迟非常高
- 正常情况下,异常率为0.但是压测显示异常率为14.5%
- 吞吐量为1000左右,并不是很高
jstat分析
| 指标 | 初始值 | 最终值 | 变化 |
|---|---|---|---|
| 年轻代GC次数(YGC) | 13 | 16 | +3次 |
| 年轻代GC时间(YGCT) | 0.765s | 0.857s | +0.092s |
| Full GC次数(FGC) | 0 | 1 | +1次 |
| Full GC时间(FGCT) | 1.257s | 1.368s | +0.111s |
| 总GC时间(GCT) | 2.022s | 2.226s | +0.204s |
| Eden区使用率 | 61.3% | 1.7% | -59.6% |
| 老年代使用率 | 23.8% | 16.3% | -7.5% |
- Eden区使用波动较大,表明执行频繁的Young GC
- 老年代使用相对稳定,表明对象晋升率适中
- 元空间使用稳定,表明类加载活动趋于平稳
堆转储文件分析
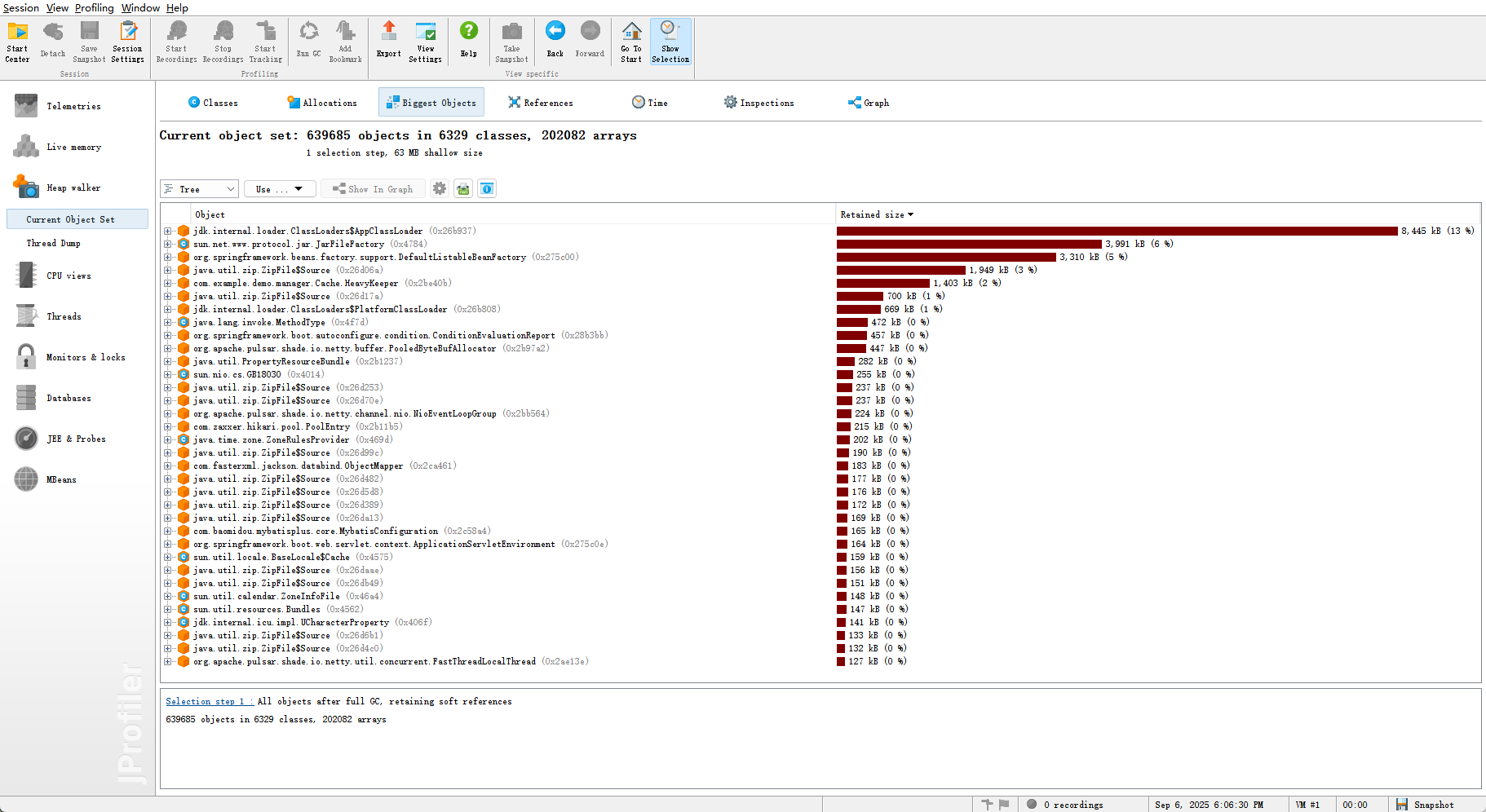
- 占比较大的为类加载器,并没有明显的内存泄漏状况
调优方案
- 针对于频繁的Young GC
- 增加 Eden区的内存大小
- 选择更合适的GC垃圾回收器
- 针对吞吐量+响应时间+异常率
- 吞吐量和响应时间 可能受到 Full GC 部分影响,但是更多的应该在锁和并发设计方面
- 异常率 可能是 频繁GC导致的连接超时
调优步骤
JVM调优
-server # 服务器模式
-Xms8g -Xmx8g # 堆内存初始和最大值-XX:+UseG1GC # 启用G1# GC日志记录
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintGCTimeStamps
-XX:+PrintGCApplicationStoppedTime # 打印应用停顿时间
-XX:+PrintTenuringDistribution # 打印年龄分布
-Xloggc:/path/to/your/logs/gc-%t.log # GC日志输出路径,%t表示时间戳
-XX:+UseGCLogFileRotation # 开启GC日志滚动
-XX:NumberOfGCLogFiles=2 # 保留2个文件
-XX:GCLogFileSize=100M # 每个文件100M-XX:MaxGCPauseMillis=200 # 目标最大停顿时间(毫秒)
-XX:InitiatingHeapOccupancyPercent=35 # 触发Mixed GC的堆占用阈值(默认45%)
-XX:ConcGCThreads=8 # 并发GC线程数,约为总CPU核数的1/4
-XX:ParallelGCThreads=16 # 并行GC线程数,通常等于CPU核数-XX:MetaspaceSize=256M # 元空间初始大小,避免运行时动态扩容带来的GC
-XX:MaxMetaspaceSize=256M # 元空间最大大小,限制其无限增长
-XX:G1HeapRegionSize=4m # 设置Region大小-XX:+DisableExplicitGC # 禁止显式System.gc(),防止误调用引发Full GC
-XX:MaxDirectMemorySize=2g # 设置直接内存(堆外内存)大小,防止OOM。
-XX:+HeapDumpOnOutOfMemoryError # OOM时生成Dump文件
-XX:HeapDumpPath=/path/to/your/logs/heapdump.hprof # Dump文件路径
-
-server- 启用JVM的“服务器”模式。该模式会进行更多的运行时优化(如更激进的JIT编译),旨在获得最高的运行速度,但启动稍慢。
-
-Xms8g -Xmx8g- 初始堆内存和最大堆内存设置为相同的值。
- 如果不相等,JVM会在使用时动态向操作系统申请内存,这个过程本身就有开销,并且在内存压力大时可能引发不必要的GC。固定大小后,JVM可以一次性向操作系统申请好全部内存,并在内部进行最优的堆布局,消除了运行时扩容带来的性能波动。
-
-XX:+UseG1GC- G1是面向服务端、大内存、多处理器机器的收集器,其核心优势是可预测的停顿时间模型。
- 优势
- 低延迟:它通过将堆划分为多个Region,每次只收集部分Region(增量收集),可以尽可能地避免一次回收整个堆,从而将STW停顿时间控制在一个可控范围内(通过
MaxGCPauseMillis参数设定)。 - 高吞吐:在尽力满足延迟目标的同时,也能提供很高的吞吐量。
- 自动碎片整理:在回收过程中会通过复制算法自动进行压缩,避免内存碎片。这比CMS的“标记-清除”后再进行Full GC整理要高效得多。
- 低延迟:它通过将堆划分为多个Region,每次只收集部分Region(增量收集),可以尽可能地避免一次回收整个堆,从而将STW停顿时间控制在一个可控范围内(通过
-
**GC日志相关参数 **
- 出现问题必须依赖详细的GC日志。它可以告诉你每一次GC的确切时间、持续时间、回收了多少内存、停顿了多久。
-
-XX:MaxGCPauseMillis=200- G1会努力尝试达成这个目标(比如200毫秒)。设置太小(如50ms)会迫使G1更频繁地做少量回收,反而会牺牲整体吞吐量。200ms是一个对高并发应用相对安全的起始值。
-
-XX:InitiatingHeapOccupancyPercent=45- 这个参数决定了何时启动并发标记周期(Mixed GC)。默认45%意味着当整个堆的使用率达到45%时,G1就开始后台标记垃圾了。
- 我这里调低到35% 是一种预防性策略,让G1更早地开始后台垃圾标记工作,为即将到来的内存分配高峰预留出足够的安全空间和回收时间,避免因为回收启动太晚而被迫触发STW时间更长的Full GC。
-
-XX:ConcGCThreads=4&-XX:ParallelGCThreads=8- 为什么? 这是对CPU资源的精细化控制。假设是一台8核机器。
ParallelGCThreads=8:STW期间,并行GC线程用满所有CPU核心,以求最快速度完成回收,缩短停顿。ConcGCThreads=4:并发标记阶段(与应用线程同时运行),只使用一半的CPU核心(4个),这是为了减少GC线程对业务线程的CPU资源争抢,保证业务吞吐量。这是一种典型的用吞吐量换延迟的权衡。
-
*
-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M- 元空间存放类元数据等信息。如果不设置,元空间会根据使用情况动态扩容,每次扩容都可能触发FGC。设置为固定且足够大的值(256M通常足够),可以避免在运行时因元空间不足而触发不可预期的Full GC,提高稳定性。
-
-XX:G1HeapRegionSize=4m- G1将堆划分为等长的Region。Region大小影响回收的粒度。
- 2MB是默认值。设置为4MB意味着更少的总Region数,可以减少GC时需要管理的元数据开销,对大堆应用更友好。
-
-XX:+DisableExplicitGC&-XX:MaxDirectMemorySize=2gDisableExplicitGC:禁止代码中调用System.gc()。很多第三方库(比如Netty, 我的项目于使用的Pulsar正基于Netty)会误触发,导致一次长时间的Full GC。MaxDirectMemorySize=2g:显式设置堆外内存大小上限。这样当堆外内存耗尽时,会抛出OOM异常,而不是默默地吃光所有内存。这既是保护措施,也让问题更容易被发现。
-
-XX:+HeapDumpOnOutOfMemoryError- OOM是线上最严重的问题之一。事后复盘必须知道“是什么对象占用了内存”。这个参数可以在发生OOM的瞬间自动生成堆转储文件(heapdump)。保证存在导致故障的可排查文件。
架构调优
- 以下是处理业务的旧代码
@Overridepublic Boolean doThumb(DoThumbRequest doThumbRequest, HttpServletRequest request) {ThrowUtils.throwIf(doThumbRequest == null || request == null, ErrorCode.PARAMS_ERROR);user loginUser = userService.getLoginUser(request);synchronized (StrUtil.toString(loginUser.getId()).intern()) {return transactionTemplate.execute(status -> {Long blogId = doThumbRequest.getBlogId();Boolean exists = this.hasThumb(blogId, loginUser.getId());if (exists) {throw new RuntimeException("已点赞");}String hashKey = ThumbConstant.USER_THUMB_KEY_PREFIX + loginUser.getId();String fieldKey = blogId.toString();Long realThumbId = thumb.getId();stringRedisTemplate.opsForHash().put(hashKey, fieldKey, realThumbId.toString());cacheManager.putIfPresent(hashKey, fieldKey, realThumbId);pulsarTemplate.sendAsync("thumb-topic", thumbEvent).exceptionally(ex -> {redisTemplate.opsForHash().delete(userThumbKey, blogId.toString(), true);log.error("点赞事件发送失败: userId={}, blogId={}", loginUserId, blogId, ex);return null;});return success;});}}
可以看出
- 没有充分利用Pulsar的优势
- 锁粒度大
调优后代码
if (doThumbRequest == null || doThumbRequest.getBlogId() == null) {throw new RuntimeException("参数错误");}user loginUser = userService.getLoginUser(request);Long loginUserId = loginUser.getId();Long blogId = doThumbRequest.getBlogId();String userThumbKey = RedisKeyUtil.getUserThumbKey(loginUserId);long result = redisTemplate.execute(RedisLuaScriptConstant.THUMB_SCRIPT_MQ,List.of(userThumbKey),blogId);if (LuaStatusEnum.FAIL.getValue() == result) {throw new RuntimeException("用户已点赞");}ThumbEvent thumbEvent = ThumbEvent.builder().blogId(blogId).userId(loginUserId).type(ThumbEvent.ThumbType.INCREASE).localDateTime(LocalDateTime.now()).build();pulsarTemplate.sendAsync("thumb-topic", thumbEvent).exceptionally(ex -> {redisTemplate.opsForHash().delete(userThumbKey, blogId.toString(), true);log.error("点赞事件发送失败: userId={}, blogId={}", loginUserId, blogId, ex);return null;});return true;
最终调优结果
- 吞吐量提升至 2800
- 异常率降低为0
- 平均响应时间降低至0.5s,最大响应时间0.9s
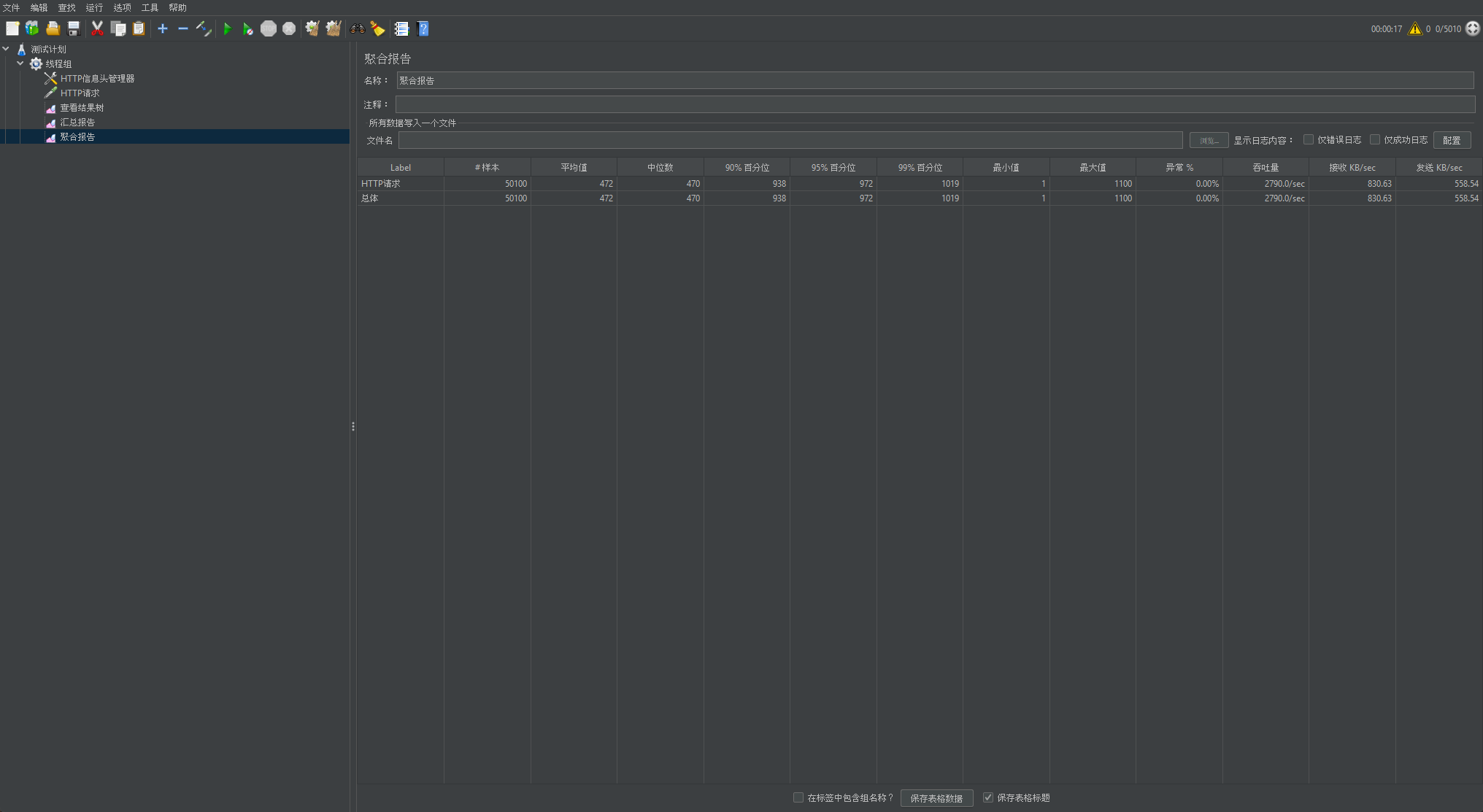
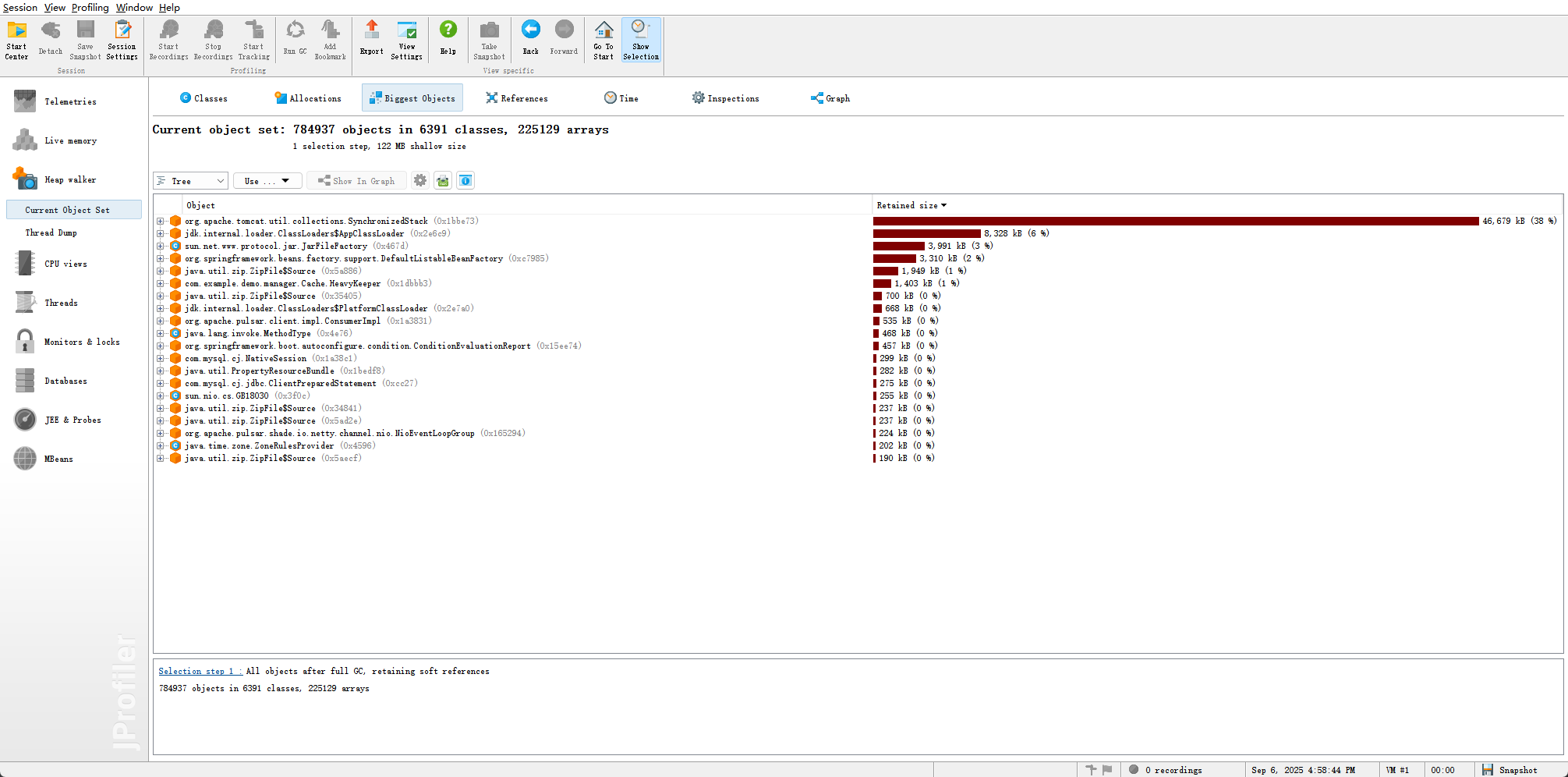
- 成功避免Full GC,降低Young GC次数
