配合图解 SEG-SAM: Semantic-Guided SAM for Unified Medical Image Segmentation

论文:论文下载地址
🔍 研究背景
- Segment Anything Model(SAM)在自然图像中表现出色,但在医学图像中存在挑战:
- 只能进行二值分割(前景/背景)
- 类别语义缺失,不利于区分类似结构(如肝与肾)
- 医学图像常包含模态多样性(CT、MRI 等)与多类别重叠问题
🎯 核心目标
构建一个具备语义理解能力的 SAM 变种,支持 统一医学图像分割(binary + semantic)
🎯 摘要
近年来,开发统一的医学图像分割模型引起了越来越多的关注,尤其是在Segment Anything Model (SAM)出现之后。SAM在自然领域展示了有前景的二值分割性能,然而将其迁移到医学领域仍然具有挑战性,因为医学图像通常具有显著的类别间重叠。为了解决这一问题,作者提出了语义引导的SAM (SEG-SAM),这是一个统一的医学分割模型,通过结合语义医学知识来增强医学分割性能。首先,为了避免二值预测和语义预测之间的潜在冲突,作者引入了一个独立于SAM原始解码器的语义感知解码器,专门用于图像中提示对象的语义分割和未提示对象的分类。为了进一步增强模型的语义理解能力,作者从大型语言模型中获取医学类别的关键特征,并通过文本到视觉语义模块将其融入SEG-SAM中,自适应地将语言信息转化为视觉分割任务。最后,作者引入了跨掩码空间对齐策略,以鼓励SEG-SAM的两个解码器生成的掩码之间有更大的重叠,从而使两个预测都受益。大量实验表明,SEG-SAM在统一的二值医学分割任务中优于最先进的基于SAM的方法,在语义医学分割任务中优于特定任务的方法,展示了有前景的结果和更广泛的医学应用潜力。
🧠 模型结构:SEG-SAM
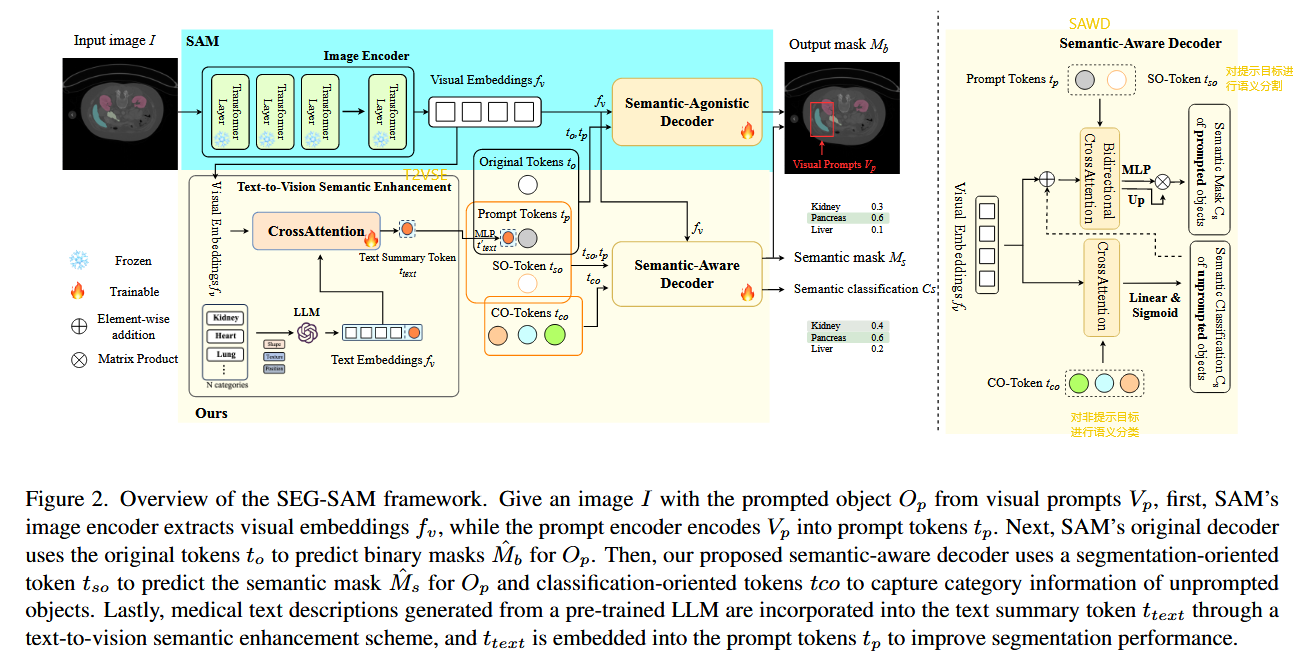
我们来看这张图(Figure 2),它完整地展示了 SEG-SAM 模型的处理流程,我会从左到右按模块流程 + 说明作用来讲解,配合图中文字你会更容易理解整个架构是如何运作的。
🧭 SEG-SAM 全流程详解(配合图解)
🟫 1. 输入部分
🔹 Input image I I I
输入一张医学图像(如 CT 腹部),目标是根据提示(点或框)对某个器官进行分割。
🟦 2. SAM 模块(蓝色区域)
🧊 Image Encoder
-
将图像 I I I 经过多个 Transformer Layer
-
输出视觉特征: f v f_v fv
-
这个部分参数被冻结,不训练(❄️)
🔥 Prompt Encoder
- 将用户输入的提示(如框选“胰腺”)编码成提示 token: t p t_p tp
🔥 Semantic-Agonistic Decoder
-
使用 SAM 原始 decoder
-
输入 t o t_o to 和 t p t_p tp 以及 f v f_v fv
-
输出:仅提示目标的 二值分割掩膜 M ^ b \hat{M}_b M^b(前景/背景)
🟨 3. SEG-SAM 增强模块(黄色区域)
🧠 Text-to-Vision Semantic Enhancement (T2VSE)
-
文本语义生成
-
通过 LLM(如 GPT)生成器官的形状/纹理/位置描述
-
转为 text embedding 向量 f t f_t ft
-
加入 Text Summary Token t text t_\text{text} ttext
-
-
Cross-Attention 融合
-
文本特征 f t + t text f_t + t_\text{text} ft+ttext 与图像特征 f v f_v fv 跨模态交互
-
输出:增强语义向量 t text ′ t'_\text{text} ttext′
-
-
融合到提示 token
-
t text ′ t'_\text{text} ttext′ 通过 MLP 融入 t p t_p tp
-
得到增强的提示 token: t p ′ t'_p tp′
-
🟨 4. Semantic-Aware Decoder(右侧浅黄色区域)
SEG-SAM 的核心组件,功能分为两部分:
✅ 4.1 分割提示目标(使用 SO-Token)
-
输入:提示 token t p t_p tp + 图像特征 f v f_v fv + 分割 token t s o t_{so} tso
-
通过:
-
Self-Attention
-
Bidirectional CrossAttention
-
-
输出:语义掩膜 M ^ s \hat{M}_s M^s(可区分类别)
✅ 4.2 分类非提示目标(使用 CO-Tokens)
-
每个 CO-Token 代表一个类别(如肝脏、胰腺、肾脏…)
-
仅做类别是否存在的二分类(不是分割)
-
通过 CrossAttention 与 f v f_v fv 交互 → 输出概率分布 C ^ s \hat{C}_s C^s
🔁 信息融合
-
C ^ s \hat{C}_s C^s → 通过 MLP → 融入 t s o t_{so} tso
-
提供语义先验信息用于优化主目标的语义分割
✅ 5. 输出结果(图右侧)
- M ^ b \hat{M}_b M^b:前景/背景的 二值掩膜
- M ^ s \hat{M}_s M^s:具有类别标签的 语义掩膜
- C ^ s \hat{C}_s C^s:非提示对象的 类别概率
🎯 小结一句话:
SEG-SAM 的整个流程是:
-
编码图像 + 提示
-
注入文本语义信息
-
用两个解码器分别处理:
-
一个负责分割(提示对象)
-
一个负责分类(非提示对象)
-
-
输出掩膜 + 类别信息
⚙️ 模型训练策略
🔧 输入/输出配置
- 使用 SAM 的点/框提示方式
- 每张图随机采样 5 个目标进行训练
🧮 损失函数
- L b i n L_{bin} Lbin:二值分割损失(Focal + Dice)
- L s e m L_{sem} Lsem:语义分割损失(CE + Dice)
- L b c e L_{bce} Lbce:非提示目标的二分类损失
- L c o n s L_{cons} Lcons:Cross-mask 一致性损失
L_{cons} = 1 - \frac{|M_s ∩ M_b|}{|M_s ∪ M_b|}
🧪 实验结果
🔹 数据集
- 主数据集:Med2D-16M(3.6M 图像 / 8种模态 / 200 类别)
- 泛化评估:KiTS23, BTCV, AMOS
📈 主指标
- DSC:二值分割性能(Dice Similarity Coefficient)
- mDSC:多类别平均 DICE(mean Dice)
🔥 主结果汇总
| 方法 | Binary DSC | Semantic mDSC |
|---|---|---|
| SAM-Med2D | 77.3 | 66.78 |
| MedSAM | 77.4 | 65.18 |
| Med-SA | 77.2 | 69.38 |
| SEG-SAM | 81.46 | 75.28 |
🔍 消融实验分析
| 模块 | DSC ↑ | mDSC ↑ |
|---|---|---|
| Baseline(SAM) | 65.45 | - |
| + SO-Token | 68.53 | 70.14 |
| + CO-Tokens | 69.88 | 71.68 |
| + 全图语义(无效) | 67.69 | 69.03 |
| + T2VSE | 71.70 | 73.67 |
| + Cross-mask Align | 73.15 | 75.28 |
🧩 可插拔性验证
将 SEG-SAM 的 SAWD 插入到 MedSAM / Med2D 等框架中,也能带来提升。
✅ 结论
- SEG-SAM 是第一个结合语义引导与 SAM 的统一医学图像分割框架
- 提供:
- 准确的语义掩膜
- 强泛化能力
- 可扩展性好(可插拔进现有 SAM 系列)
- 未来工作:拓展到视频场景 / 更细粒度的文本指导