25高教社杯数模国赛【C题顶流思路+问题解析】第三弹
注:本内容由”数模加油站“ 原创出品,虽无偿分享,但创作不易。
欢迎参考teach,但请勿抄袭、盗卖或商用。
问题分析
问题一的模型的建立和求解
具体分析
本问旨在分析男胎样本中胎儿 Y 染色体浓度(列 V)与孕周(列 J)和 BMI(列 K)等指标之间的相关特性,建立显著的定量关系模型以刻画浓度随孕期推进和体型差异的变化趋势 . 数据层面存在如下特点:其一,部分孕妇存在多次采血(列 I)导致同一个体纵向重复观测;其二,浓度是比例型变量(阈值 4% 为达标判据),天然受限于 [0,1] 区间;其三,测序质量与技术协变量(如读段数 L、比对比例 M、重复比例 N、唯一比对数 O、GC 含量 P/ X/Y/Z、过滤比例 AA 等)可能对观测浓度引入系统性偏倚;其四,孕妇年龄(C)、身高(D)、体重(E)、妊娠方式(G)等亦可能作为混杂因素影响 Y 浓度的生物学可见度 . 因此模型需同时处理(i)非线性影响(孕周—浓度常呈上升-平台)、(ii)比例型响应的界约束、(iii)个体级重复测量的相关性、(iv)质量因子引起的测量误差与批次效应 . 基于此,采用带随机效应的广义可加模型(GAMM)或分层 Beta/Logit 回归建模,并辅以显著性检验(似然比/Wald/平滑项近似 F 检验)与多重比较校正 .
模型建立
(1) 变量与预处理 设第 i 位孕妇在第 t 次检测的 Y 浓度为 yit ∈ (0,1),孕周(单位:周)为 git,BMI 为 bi,质量协变量向量为 qit(如 L,M,N,O,P,AA,…),混杂协变量为 zi (如年龄、妊娠方式等) . 为处理边界值,采用连续压缩变换 为样本量)或加 10−4 的夹紧,以适配 Beta/Logit 链路 . 孕周可居中并标准化,BMI 分位数归一以提升数值稳定性 .
(2) 分层 Beta-GAMM(首选) 令 yit ∼ Beta(µitϕ, (1 − µit)ϕ),其均值经 Logit 链路与协变量关联:
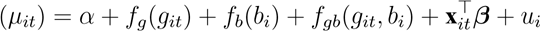
其中 fg,fb 为三次样条/薄板样条平滑项,fgb 为张量积平滑以刻画孕周 ×BMI 交互的非线性;xit = [qit,zi] 汇聚质量与混杂协变量;ui ∼ N(0,σu2) 为个体随机截距以吸收重复观测相关性;ϕ > 0 为精度参数 . 对平滑项采用 REML 估计与惩罚选择,显著性通过近似 F 检验和似然比检验评估 .
(3) 鲁棒替代:Logit-GAMM 若以 Logit 近似处理比例:
logit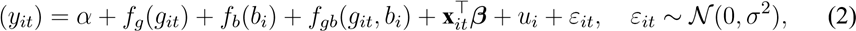
并采用 Huber/M-估计或对异常质量样本设权重 wit = w(qit) 以提升鲁棒性 .
(4) 显著性与解释 报告(i)主效应 fg,fb 的有效自由度(edf)与显著性,判断上升平台或阈值区间;(ii)交互平面 fgb 的增益与等高线,展示不同 BMI 下的孕周—浓度等概率带;(iii)质量协变量的系数方向性(如读段数 L 增加是否显著提升 µit) . 由此得到
“孕周—BMI—Y 浓度”的定量关系,为后续达标时点推断与分组提供依据 .
问题二的模型的建立和求解
具体分析
本问目标是在男胎人群中,针对 BMI 进行合理分组并给出各组的最佳 NIPT 时点,使孕妇潜在风险最小 . 关键点包括:(i)达标判据:Y 浓度 ≥ 4%;(ii)观测是离散采样的纵向过程,最早达标时间 T⋆ 仅能区间定位(两次采样之间);(iii)过早检测会导致失败与复检,从而拖延诊断并提高风险;(iv)题面给出风险分区:12 周以内风险低、
13–27 周高、28 周以后极高,应纳入决策代价 . 因此需要把“达标时间分布”与“检测时间带来的风险”在分组层面进行联合最优化 .
模型建立
(1) 达标时间建模(区间删失生存/AFT) 基于问题一的拟合均值与方差,定义“达到
4%”的事件时间 T⋆(单位:周) . 若个体仅在若干周 {git} 有观测,则 T⋆ 落在相邻两次观测区间 (gi,t−,gi,t+] 内,形成区间删失数据 . 令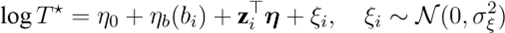
得到对 BMI 与协变量(如年龄、妊娠方式等)的 AFT(加速失效)模型 . 亦可以补充
Cox-比例风险作敏感性分析 .
(2)BMI合理分组(基于风险的最优分段)设需将 BMI 连续轴划分为G个区间B1,…,BG,每组对应达标时间分布 Fg(t)(由 AFT 模型在该组 BMI 条件分布下得到) . 定义在组 g 于孕周 t 进行 NIPT 的期望风险函数:
E[Riskg(t)] = cearly · Pr(T⋆ > t, t ≤ 12) + cmid · Pr(T⋆ > t, 13 ≤ t ≤ 27)
+ clate · Pr(T⋆ > t, t ≥ 28) + cretest · Pr(T⋆ > t),
其中 cearly < cmid < clate 反映题面风险递增原则,cretest 为复检代价 . 组内最优检测时点为
arg min E[Riskg(t)]. (5) t∈[tmin,tmax]
为确定分组边界,采用动态规划/最优分段或基于 T⋆ 的单调聚类(e.g. k-means on predicted T⋆),以全局风险最小为准则:
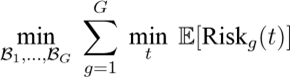
s.t. [Bg = BMI 轴, Bg ∩ Bg′ = ∅.
- 检测误差影响(概率达标约束) 考虑测量误差与技术偏倚,令有效达标概率 pg(t) =
Pr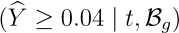
对 tg⋆ 加入置信达标约束: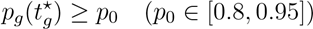
- 或作为惩罚加入目标函数,以平衡“尽早检测”与“通过率/复检率” .
问题三的模型的建立和求解
具体分析
在问题二的基础上进一步综合多因素(身高 D、体重 E、年龄 C、读段与比对质量
L/M/N/O/P、GC 相关 X/Y/Z、过滤比例 AA、采血次数 I 等),同时考虑检测误差与达标比例
(群体中达到或超过 4% 的比例) . 我们需在 BMI 条件下给出新的合理分组与各组最佳时点,使潜在风险最小 . 由于达标事件受多维因素影响且观测为离散时间的区间删失,宜采用多因素层次生存模型或联合纵向-生存模型,以同时利用浓度轨迹与达标时间信息;并在分组与时点决策中纳入“目标达标比例阈值”的硬/软约束 .
模型建立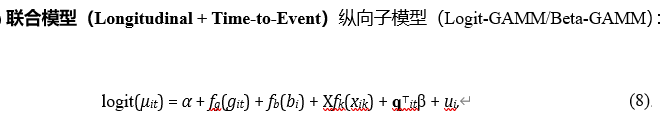
其中 xik 包含年龄、身高、体重等个体级特征;qit 为时间变技术协变量 .
生存子模型(区间删失 AFT/Cox):
λi(t) = λ0(t) exp(γb bi + Xγkxik + γµ mi(t)),其中 mi(t) 为由纵向子模型预测的瞬时均值/增长率,γµ 刻画“浓度水平 → 达标风险” 的关联 . 以 EM/贝叶斯 MCMC 估计联合参数并通过 WAIC/LOO-CV 比较 .
(2) 达标比例与误差约束 给定某 BMI 组 g 在时点 t 的达标比例预测 πg(t) = Pr(Y ≥0.04 | Bg,t),要求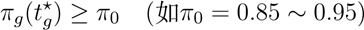
并将检测误差(假阳/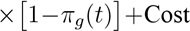
假阴率)以有效风险修正:Risk ← RiskFN Pr(FN)+
CostFP Pr(FP) . 在分组最优化时,目标与约束同时考虑
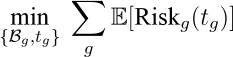
s.t. πg(tg) ≥ π0, pg(tg) ≥ p0.
(3) 分组求解与稳健性 采用二层优化:外层枚举/搜索 BMI 分段(动态规划或基于 T⋆ 的一维最优分段),内层在每个分段内求解 tg 使目标最小;以交叉验证/时序留一法评估泛化,辅以参数扰动(权重与成本系数)做敏感性分析,输出稳健的区间与时点建议 .
问题四的模型的建立和求解
具体分析
本问针对女胎异常判定(列 AB 为金标准标签),需综合 X 染色体及 13/18/21 号染色体的 Z 值(列 T/Q/R/S),GC 含量(X/Y/Z)、读段与比例(L/M/N/O/AA)、X 染色体浓度(W)、BMI(K)等信息构建判别方法 . 经典做法以 Z 值阈值(|Z|≥ 3)判定单染色体异常,但单一阈值易受 GC 偏差、测序质量与 BMI 的系统影响 . 因此采用判别式多变量模型(如 L1-Logistic/梯度提升/随机森林)或层次贝叶斯判别,在控制质量偏倚与类不平衡的前提下做联合判定,并同时给出个体化风险概率 .
模型建立
(1) 特征工程与标准化 构造输入向量
f 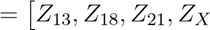
, GC13, GC18, GC21, L,M,N,O,AA, W, BMI, 交互项(Z×GC), QC 指标对计数/比例特征做对数或 Logit 变换并标准化;基于 QC 规则剔除极端测序失败样本
(如 GC ∈/ [0.4,0.6] 且异常分布、L 过低、AA 过高). 采用 SMOTE/权重调节缓解类不平衡 .
(2) 判别模型与校准 以 L1-Logistic 作为主模型(便于可解释性),并以 XGBoost 作对照提高非线性拟合
Pr(Abn 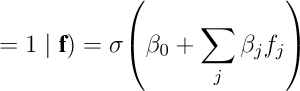
其中对 β 加 L1 惩罚以进行特征选择;输出概率经 Platt/Isotonic 进行概率校准 . 以交叉验证评估 ROC-AUC、PR-AUC、灵敏度/特异度,并根据应用代价确定最优阈值 τ⋆ = arg maxτ Youden(τ) 或代价敏感目标 .
(3) 规则集融合与灰区复检 为增强稳健性,融合“阈值规则 + 模型概率”的混合策略:若 max(|Z13|,|Z18|,|Z21|) ≥ 3.5 则直接判异常;若 2.5 ≤ max |Z| ≤ 3.5 且模型概率处于灰区(如 0.4 ∼ 0.6),则建议复检并结合 QC 指标与 BMI 分层做个体化复核时点建议;否则按模型概率阈值输出 .
(4) 解释与不确定性 对 Logistic 提供系数方向与置信区间,对树模型输出 SHAP 重要度以解释“哪些指标驱动异常判定”,并给出个体级不确定性区间(经自助法或贝叶斯后验) .