【笔记】大模型业务场景流程综述
前言
大模型是指具有大规模参数和复杂计算结构的深度学习模型,这些模型通常由众多神经网络构建而成,拥有数十亿甚至数千亿个参数。本章将围绕大模型概念及特点展开,介绍模型算法的分类、典型大模型及应用、大模型训练流程和大模型业务流程。
目标
学完本课程后,您将能够:
了解大模型应用发展。
了解大模型特点和主流大模型应用。
了解大模型业务流程。
目录
1.AI应用发展现状
2.大模型分类和特点
3.主流大模型介绍
4.大模型应用
5.大模型训练及推理流程介绍
6.大模型业务流程
1.AI应用发展现状
AI应用发展
当前AI应用进入大模型时代,智能化水平有了质的飞跃。从自然语言处理到图像识别,从自动驾驶到医疗健康,大模型技术的应用正在不断地提高我们对AI的认知和期待。
于此同时,各类算法和技术也在日新月异地发展。深度学习、强化学习等算法和开发框架、工具的不断优化和完善,是的AI在处理复杂问题时更加高效和准确。
思考1
AI带来了哪些改变?
AI可以适用于哪些行业?
大模型时代的AI应用有哪些变化?
大模型AI应用如何开发?
未来的AI应用会走向何方?
思考2
你是一位架构师,现在你将主导团队AI应用的开发,你会如何进行开发,又会思考哪些问题?
模型那么多,选哪个?大模型还是小模型?
该为微调和推理准备多少算力?
应用上线时,模型应该怎么部署?
要是模型在回答时乱说话怎么办?
如何保证模型上线后的安全问题?
。。。。。。
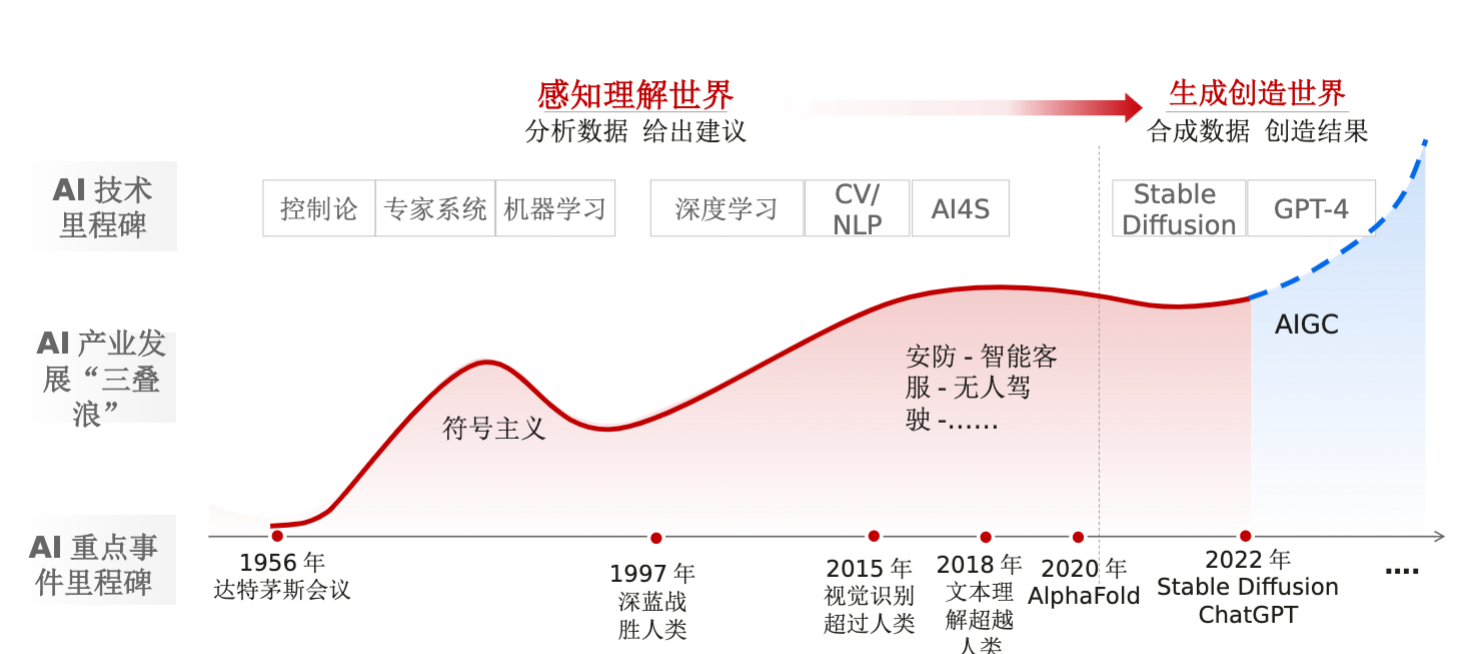
AI应用发展历程
从 感知理解世界(分析数据,给出建议),到 生成创造世界(合成数据,创造结果)。
AI重点事件里程碑:
1956年达特茅斯会议
1997年深蓝战胜人类
2015年视觉识别超过人类
2018年文本理解超越人类
2020年AlphaFold
2022年Stable Diffusion ChatGPT
AI产业发展“三叠浪”:
符号主义
安防-智能客服-无人驾驶-。。。。。。
AIGC
AI技术里程碑:
控制论、专家系统、机器学习
深度学习、CV/NLP、AI4S
Stable Diffusion GPT-4
由小到大
算法:参数量膨胀,单位由Million到Billion
数据:训练数据增加,单个模型训练数据集可多达万亿token
算力:算力规模提升至EFLOPs
AlexNET-VGG-ResNet-ELMO-Transformer-ViT-GPT-LLaMA-GLM-...
大模型 VS 小模型
| 小模型 | 大模型 |
| 学习能力上限低 | 学习能力强 |
| 不同任务需要不同模型 | 一个模型解决多个任务 |
| 训练数据上限低 | 训练数据上限高 |
| 单一多模态数据 | 多模态能力强 |
| Few-shot能力差 | Few-shot能力强 |
使用AI模型获取数据中的知识 -》“知识”学习的更好
服务器/云侧AI应用
随着AI模型的不断膨胀(网络深度、参数量),所需要的算力也是成倍的增加,当前大模型大多数为云侧应用,如盘古、ChatGPT、文心一言等
优点:算力相对充足、扩展性强
缺点:数据安全问题、网络延迟、计算中心维护复杂
AI端边应用
AI边缘侧应用:摄像头、开发板等。
AI移动端应用:平板、手机等。
ChatGPT等AIGC应用一直以来都伴随着强烈的隐私安全争议,但如果完全在短侧运行,就能够完全避免这一问题。
相比传统的PC或者服务器,移动终端最大的挑战就是如何平衡好体验和能耗。
批注:
在部署深度学习模型时,推理效率是一个关键考虑因素。目前,AI技术运用在越来越多的边缘设备中,例如,智能手机,智能手环,VR眼镜,Atlas200等等,由于边缘设备资源的限制,我们需要考虑到模型的大小、推理的速度,并且在很多情况下还需要考虑耗电量,因此模型大小和计算效率成为一个主要考虑因素。
华为终端BG AI与智能全场景业务部总裁贾永利解释,一方面,大语言模型具备泛化能力,能够帮助手机智能助手提升理解能力。另一方面,大模型Plug-in的插件能力,可以在手机内部打通各应用之间的壁垒,借助工具拓展能力。
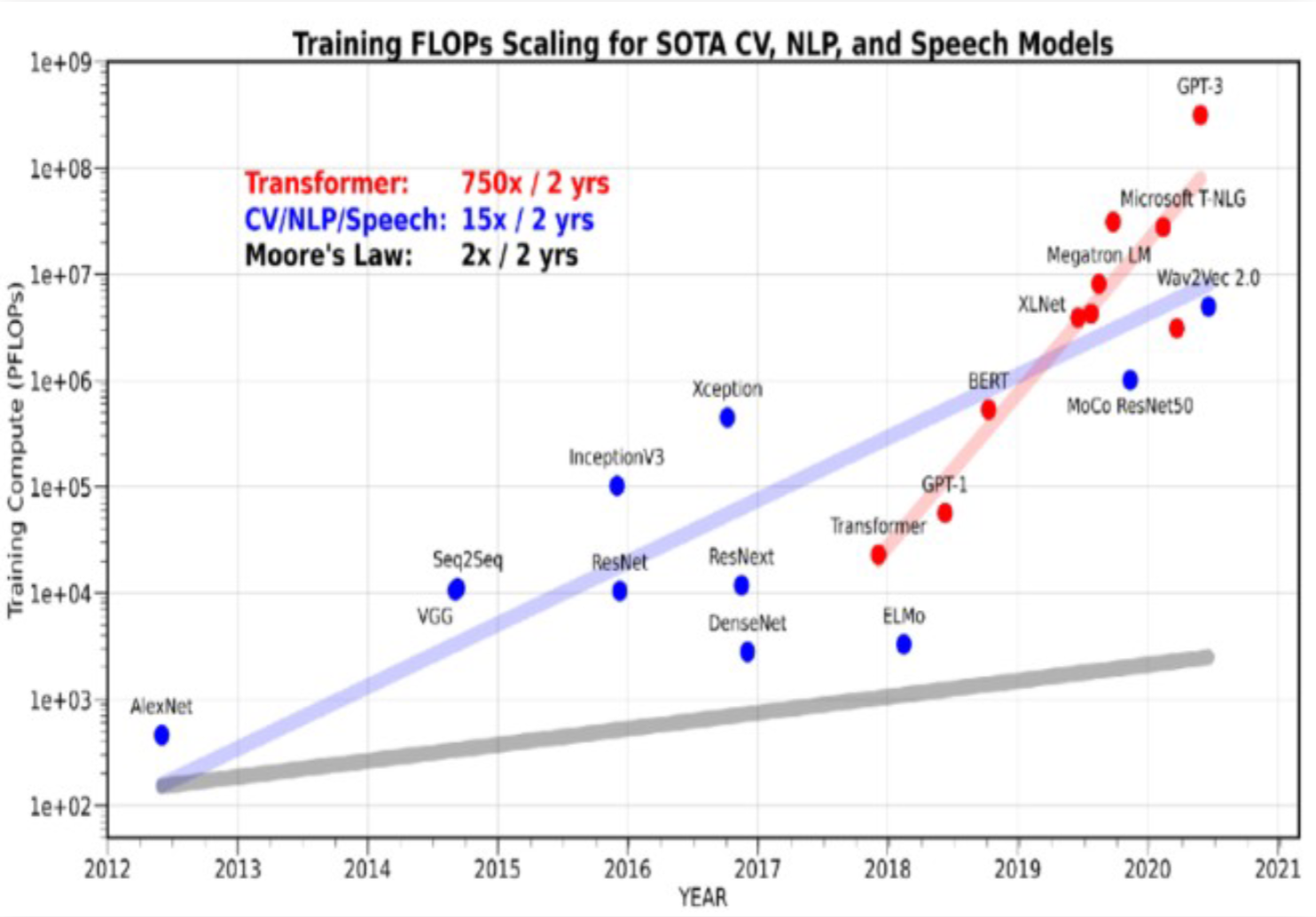
算力挑战
集群是必然选择
算力的“需”比“供”大200倍+
大模型算力需求指数级膨胀,750倍每2年
硬件算力供给仅线性增长,3倍每2年
万级参数时代:2015~2018
典型模型:参数:ResNet-50 2500万
计算需求:百TF级平台 1张GPU卡
网络需求:无互联网
存储需求:GB级存取-服务器硬盘
亿级参数时代:2018~2022
典型模型:参数:GPT-1 1.7亿
计算需求:PF级平台单服务器,8卡(百TF*10倍)
网络需求:节点内卡间互联
存储需求:TB级存取-服务器硬盘
万亿级参数时代:2023~
典型模型:参数:GPT-4 1-1.7万亿
计算需求:EF级平台AI集群,~万卡(PF*1000倍)
网络需求:超节点+网络互联(节点内卡间互联*100倍)
存储需求:PB级存取-高并发多级存储
集群系统创新,加速中国AI创新
批注:
大模型对于算力的需求是呈指数级膨胀式增长的,而硬件算力的供给能力是呈线性增长的,因此,目前对于算力的需求量要比硬件算力供给量高出200倍以上。
那么,同时伴随着模型参数的不断增长,在万亿参数时代下的模型训练中,不仅需要大算力,同时对于网络、存储的协同诉求也与日剧增。
所以,单机的服务器已经不能够满足万亿参数时代下的大模型训练,只有通过AI集群的方式,才能够更好的满足大规模分布式训练场景诉求。
因此,集群是大规模时代下的必然选择,集群系统的创新,也必然会加速中国AI的创新。
算力需求
根据业界论文理论推算,端到端训练AI大模型的理论时间为E_t = 8 * T * p / (n * X)。其中E_t为端到端训练理论时间,T为训练数据的token数量,P为模型参数量,n为AI硬件卡数,X为每块卡的有效算力。
| 参数量P(B) | 训练阶段 | 数据量T(B tokens) | 卡数n | 训练时长(天) |
| 175(e.g. GPT3) | 预训练 | 3500 | 8192 | 49 |
| 二次训练 | 100 | 2048 | 5.5 | |
| 65(e.g. LLaMA) | 预训练 | 1300 | 2048 | 27 |
| 二次训练 | 100 | 512 | 8 | |
| 13(e.g. LLaMA) | 预训练 | 1000 | 256 | 34 |
| 二次训练 | 100 | 128 | 7 |
批注:
以GPT3为例,参数量175B(750亿)规模下,在预训练阶段,数据量35000亿,使用8192张卡,其训练时长为49天。
华为AI算力底座支持国内外主流开源大模型,实测性能持平业界最佳
国内唯一已完成训练千亿参数大模型的技术路线,训练效率10倍领先其他国产友商

2.大模型分类和特点
大模型分类
大语言模型发展史
2017,Transformer诞生
2018,Google推出Bert
2018,OpenAI推出GPT
2019,OpenAi推出GPT2
2020,OpenAI推出GPT3
2022,OpenAI推出ChatGPT
期