【数据结构】-4-顺序表(上)
1、顺序表的核心结构定义
顺序表本质是基于数组实现的线性表,核心需要三个要素:存储数据的容器、记录元素个数的变量和默认容量。
public class MyArrayList {// 存储数据的数组,是顺序表的底层容器private int[] elem;// 记录有效元素的个数,也是下一个可插入位置的索引private int usedSize;// 默认容量,当不指定容量时使用private static final int DEFAULT_SIZE = 10;// ... 后续方法实现
}
这部分代码定义了顺序表的基本结构:
elem数组作为底层存储容器,利用其连续内存的特性usedSize既表示元素个数,也作为下一个元素的插入位置DEFAULT_SIZE提供默认初始容量
2、构造方法:初始化顺序表
顺序表需要初始化才能使用,我们提供两种初始化方式:
// 无参构造方法,使用默认容量初始化
public MyArrayList() {this.elem = new int[DEFAULT_SIZE];this.usedSize = 0;
}// 带参构造方法,指定容量初始化
public MyArrayList(int capacity) {if (capacity <= 0) {throw new IllegalArgumentException("容量不能为负数或零: " + capacity);}this.elem = new int[capacity];this.usedSize = 0;
}
构造方法的作用是初始化数组并设置初始元素个数为 0:
- 无参构造使用默认容量 10
- 带参构造允许自定义容量,但会检查容量合法性
- 初始时
usedSize都为 0,表示还没有元素
3、扩容机制:动态调整容量
数组容量固定,当元素存满时需要扩容:
// 检查是否需要扩容
private void checkCapacity() {if (usedSize == elem.length) {// 扩容为原来的1.5倍int newCapacity = elem.length * 3 / 2;elem = Arrays.copyOf(elem, newCapacity);}
}
扩容逻辑说明:
- 当
usedSize等于数组长度时,表示数组已满 - 新容量为原容量的 1.5 倍(
length * 3 / 2) - 使用
Arrays.copyOf()复制原数组内容到新数组 - 扩容操作的时间复杂度是 O (n),因为需要复制所有元素
4、插入操作:在指定位置添加元素
插入是顺序表的核心操作之一,分为指定位置插入和末尾插入:
// 在指定位置插入元素
public void add(int index, int data) {// 检查索引是否合法(0 ≤ index ≤ usedSize)if (index < 0 || index > usedSize) {throw new IndexOutOfBoundsException("索引越界: " + index);}// 检查是否需要扩容checkCapacity();// 将index位置及之后的元素后移,为新元素腾出位置for (int i = usedSize - 1; i >= index; i--) {elem[i + 1] = elem[i];}// 插入新元素elem[index] = data;usedSize++;
}// 在末尾添加元素(简化版)
public void add(int data) {add(usedSize, data); // 直接调用指定位置插入,位置为usedSize
}
顺序表中,每个元素(除第一个外)都必须有直接前一个元素(前驱)。如果在索引 5 插入元素,而索引 3、4 为空,那么这个新元素就没有合法的前驱元素(索引 4 的位置为空,不能作为前驱),这违反了顺序表的逻辑结构。
插入操作的关键步骤:
- 检查索引合法性,确保插入位置有效
- 检查容量,不足则扩容
- 从最后一个元素开始,将
index及之后的元素依次后移一位 - 在
index位置插入新元素,更新usedSize - 时间复杂度为 O (n),因为最坏情况下需要移动所有元素
5、删除操作:移除指定位置的元素
删除操作与插入类似,也需要移动元素:
// 删除指定位置的元素
public int remove(int index) {// 检查索引是否合法(0 ≤ index < usedSize)if (index < 0 || index >= usedSize) {throw new IndexOutOfBoundsException("索引越界: " + index);}// 保存要删除的元素,用于返回int oldData = elem[index];// 将index之后的元素前移,覆盖被删除的元素for (int i = index; i < usedSize - 1; i++) {elem[i] = elem[i + 1];}usedSize--; // 元素个数减1return oldData; // 返回被删除的元素
}
删除操作的特点:
- 索引合法性检查与插入不同,
index不能等于usedSize - 需要保存被删除的元素以便返回
- 从删除位置开始,将后面的元素依次前移一位
- 时间复杂度为 O (n),同样可能需要移动多个元素
6、查找与访问操作
顺序表支持按索引访问和按值查找:
// 查找元素的索引
public int indexOf(int data) {for (int i = 0; i < usedSize; i++) {if (elem[i] == data) {return i;}}return -1; // 找不到返回-1
}// 获取指定位置的元素
public int get(int index) {if (index < 0 || index >= usedSize) {throw new IndexOutOfBoundsException("索引越界: " + index);}return elem[index];
}// 修改指定位置的元素
public void set(int index, int data) {if (index < 0 || index >= usedSize) {throw new IndexOutOfBoundsException("索引越界: " + index);}elem[index] = data;
}
这些操作的特点:
get()和set()按索引操作,时间复杂度为 O (1)indexOf()按值查找,需要遍历元素,时间复杂度为 O (n)- 都需要先检查索引合法性
7、辅助方法
一些常用的工具方法:
// 判断顺序表是否为空
public boolean isEmpty() {return usedSize == 0;
}// 获取顺序表的长度
public int size() {return usedSize;
}// 清空顺序表(仅重置元素个数,不释放内存)
public void clear() {usedSize = 0;
}// 打印顺序表
public void display() {for (int i = 0; i < usedSize; i++) {System.out.print(elem[i] + " ");}System.out.println();
}
这些方法提供了顺序表的基本管理功能:
isEmpty()和size()用于判断状态和获取长度clear()清空操作非常高效,只需重置usedSizedisplay()用于查看顺序表内容
8、使用示例
public static void main(String[] args) {MyArrayList list = new MyArrayList();// 添加元素list.add(1);list.add(2);list.add(3);list.add(1, 4); // 在索引1的位置插入4System.out.print("顺序表元素: ");list.display(); // 输出: 1 4 2 3 // 获取元素System.out.println("索引2的元素: " + list.get(2)); // 输出: 2// 修改元素list.set(2, 5);System.out.print("修改后元素: ");list.display(); // 输出: 1 4 5 3 // 查找元素System.out.println("元素5的索引: " + list.indexOf(5)); // 输出: 2// 删除元素list.remove(1);System.out.print("删除后元素: ");list.display(); // 输出: 1 5 3 // 顺序表长度System.out.println("顺序表长度: " + list.size()); // 输出: 3
}
通过这个完整实现,我们可以清晰地看到顺序表的工作原理:基于数组存储,通过索引快速访问,插入删除需要移动元素,支持动态扩容。这种结构适合频繁访问但不频繁插入删除的场景。
二、异常处理(自定义异常 PosIllegality)
代码里自定义了 PosIllegality 异常类,用于处理顺序表插入时的下标非法问题,核心逻辑拆解:
1. 自定义异常类 PosIllegality
public class PosIllegality extends RuntimeException{public PosIllegality(String msg) {super(msg); }
}
- 继承
RuntimeException,属于运行时异常(无需强制try-catch,但建议主动处理)。 - 构造方法接收错误信息
msg,调用父类构造传递信息,方便抛出时提示 “哪里错了”。
2. 异常触发:checkPosOnAdd 方法
private void checkPosOnAdd(int pos) throws PosIllegality{if(pos < 0 || pos > usedSize) { System.out.println("不符合法!");throw new PosIllegality("插入元素下标异常:"+pos); }
}
- 作用:检查插入位置
pos是否合法(范围[0, usedSize],因为顺序表允许 “尾部插入”,pos == usedSize是末尾新增)。 - 触发条件:
pos小于 0,或大于当前有效元素个数usedSize(比如顺序表已有 3 个元素,usedSize=3,pos=4合法,是末尾插入;但pos=5就非法)。 - 执行逻辑:一旦非法,先打印提示,再抛出
PosIllegality异常,中断正常流程,告诉调用者 “这里出错了”。
3. 异常捕获与处理
@Override
public void add(int pos, int data) {try {checkPosOnAdd(pos); // 尝试执行,可能抛异常}catch (PosIllegality e) { // 捕获自定义异常e.printStackTrace(); // 打印异常堆栈(方便调试,看哪里错)return; // 直接返回,不执行后续插入逻辑}checkCapacity(); // ... 省略未写完的插入逻辑
}
try-catch作用:拦截checkPosOnAdd抛出的PosIllegality异常,避免程序崩溃。- 处理方式:
e.printStackTrace():打印异常信息到控制台(包含异常类型、错误信息、调用栈),方便开发者定位问题。return:捕获异常后直接返回,跳过后续插入逻辑(因为下标非法,插入无法正确执行)。
异常处理流程总结:
- 1.执行
checkPosOnAdd,检查下标合法性 - → 2. 非法则抛出
PosIllegality - → 3. 被
add方法的try-catch捕获 - → 4. 打印异常并终止插入流程。
作用是提前拦截非法操作,用自定义异常清晰提示 “下标有问题”,让程序更健壮、报错更直观。
三、contains 方法与 equals 重写
图三代码是判断顺序表是否包含某个元素:
public boolean contains(int toFind) {if(isEmpty()) {return false;}for (int i = 0; i < usedSize; i++) {// 如果是查找引用数据类型 一定记住 重写方法if(elem[i] == toFind) { return true;}}return false;
}
当前用 == 比较,只适合 基本数据类型(如 int、char 等)。如果存储引用数据类型(如 String、自定义类 Person 等),必须重写 equals,否则会出错!
为什么引用类型要重写 equals?
- 基本类型(
int):==比较值是否相等。 - 引用类型(如
String、自定义类):==比较地址(是否是同一个对象),而非内容。
举个栗子(假设存储 String):
String s1 = new String("abc");
String s2 = new String("abc");
System.out.println(s1 == s2); // false!因为是两个不同对象,地址不同
此时用 == 判断 “包含”,即使内容相同,也会返回 false,逻辑错误。
如何重写 equals(以自定义类 Person 为例)
假设顺序表存 Person 对象,需要判断是否包含 “相同内容” 的 Person
自定义类 Person
class Person {private String name;private int age;public Person(String name, int age) {this.name = name;this.age = age;}// 必须重写equals!@Overridepublic boolean equals(Object obj) {if (this == obj) return true; // 地址相同,直接返回trueif (obj == null || getClass() != obj.getClass()) return false; // 类型不同,返回falsePerson person = (Person) obj; // 强转成Person// 比较内容(name和age是否相等)return age == person.age && Objects.equals(name, person.name); }
}
修改 contains 方法(适配引用类型)
如果顺序表存 Person,contains 要改成:
public boolean contains(Person toFind) {if(isEmpty()) {return false;}for (int i = 0; i < usedSize; i++) {// 用equals比较内容,而非==if(elem[i].equals(toFind)) { return true;}}return false;
}
四、clear()方法
基本数据类型数组可以直接usedSize置零,12 23 这些数字虽然还在里面,但是后续添加数组就会把他们挤掉。就像领导想裁员,也没必要直接叫牛马走,招来新人了直接就给换了,换不换人不在乎人是否还在工位上,而是领导想换人的那个心思(usedSize就是领导的心思)
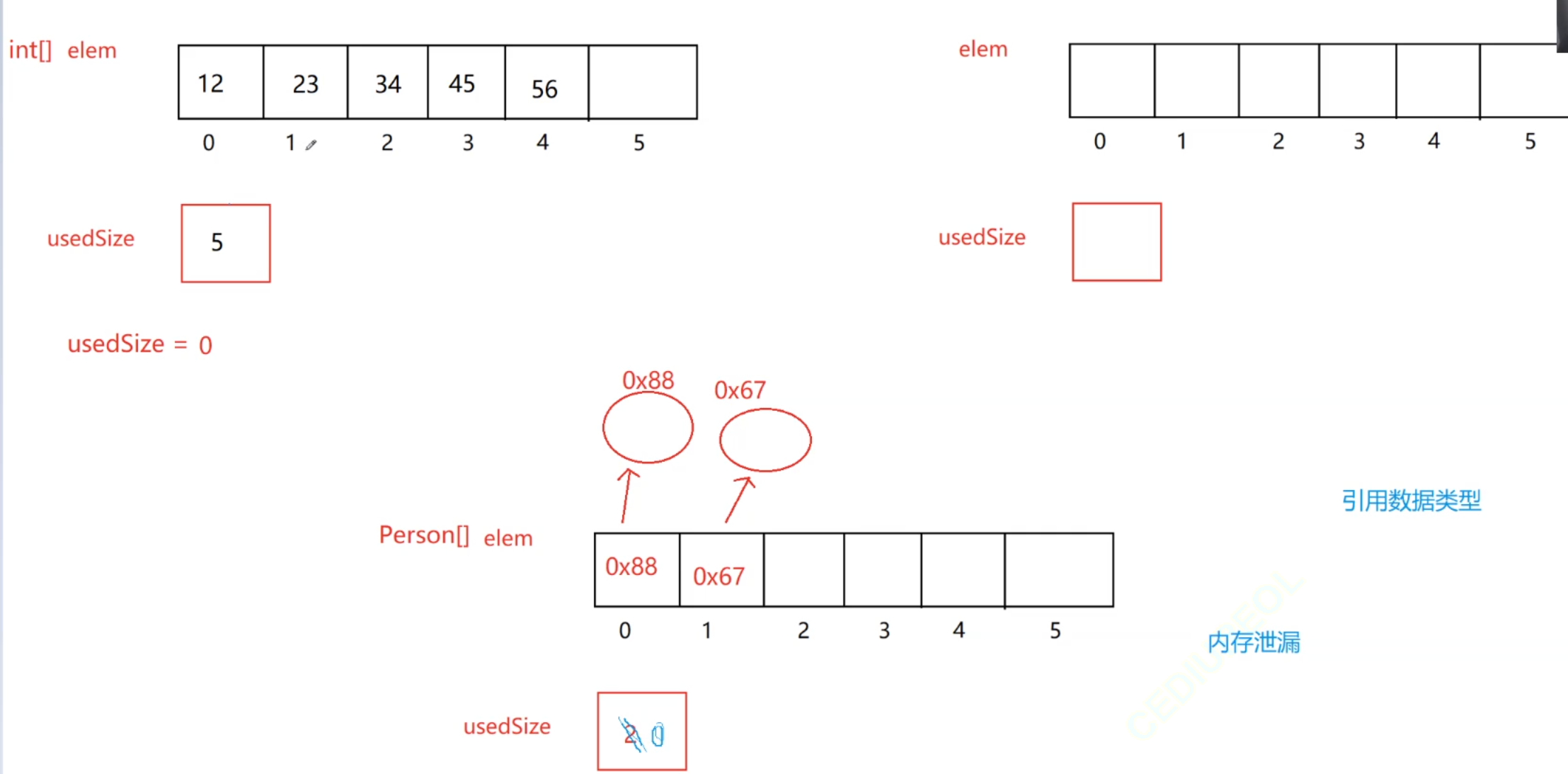
但要是引用数据类型的数组,每个元素的下标会指向一个对象,对象的空间是存堆上的,给usedSize置零的意图就是不用这些引用了,但是他们的对象又有引用指着,不会被回收,占用内存。
1、核心场景:顺序表存引用类型(Person[] elem)
顺序表底层用数组 elem 存 Person 对象,但数组里存的是 对象的引用(地址),而非对象本身。
- 比如图中
elem[0]存0x88,elem[1]存0x67,这些是堆中Person对象的地址。 - 堆里的
Person对象(标0x88、0x67的椭圆),真正存着name、age等数据。
2、“清空顺序表” 的内存问题:为何要手动置 null?
如果直接把 usedSize 置 0(只改有效元素个数),数组里的引用还在(elem[0] 仍指向 0x88,elem[1] 仍指向 0x67)。
- 这些
Person对象因被数组引用,无法被 JVM 垃圾回收(GC 只回收 “无任何引用指向” 的对象)。 - 长期这样会导致 内存泄漏(无用对象占着内存不释放,消耗资源)。
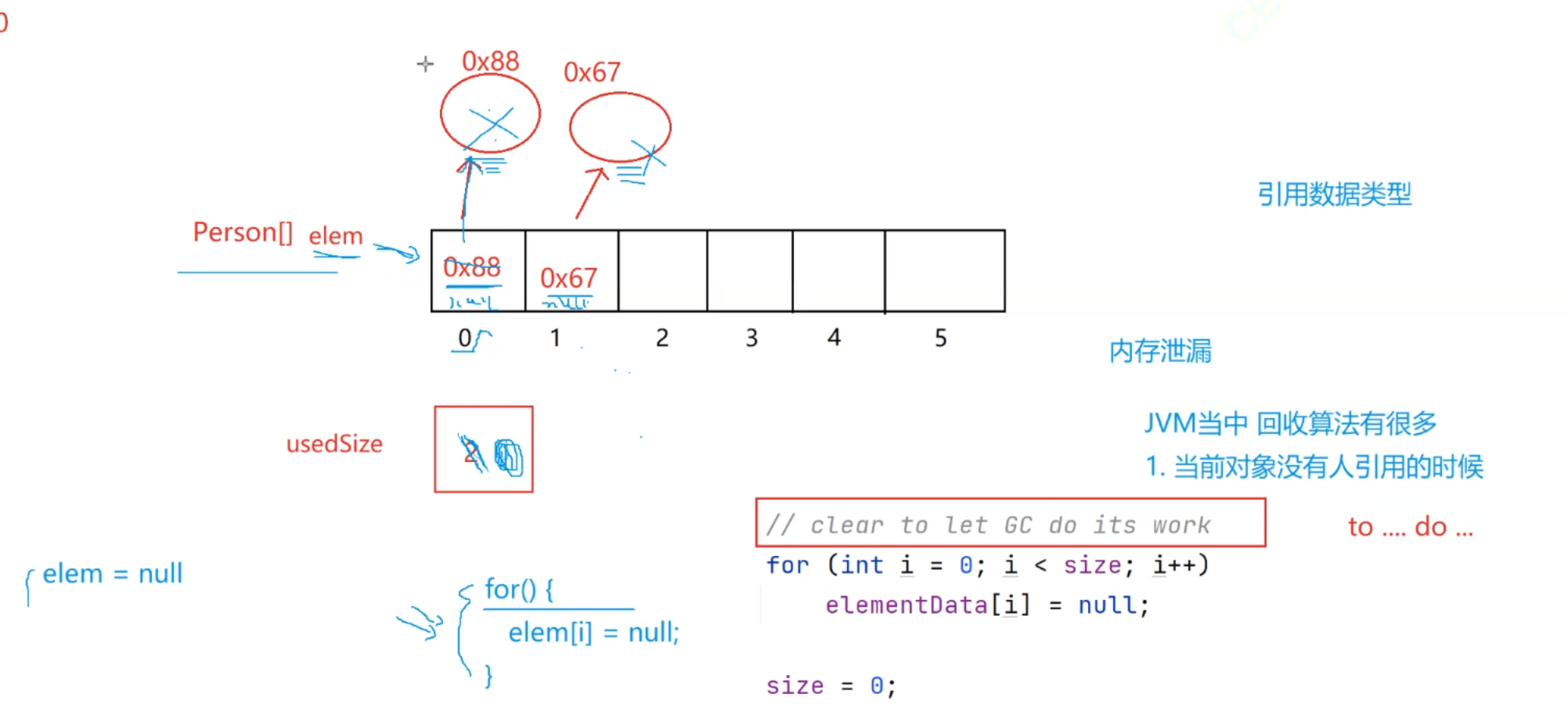
3、正确的 “清空” 逻辑(让 GC 能回收对象)
要让 GC 回收这些 Person 对象,需切断数组对它们的引用,步骤:
遍历数组,手动置
null:for (int i = 0; i < usedSize; i++) {elem[i] = null; // 切断引用,让Person对象失去“指向” }这样,堆中的
Person对象(如0x88、0x67)就没有引用指向它们了。重置
usedSize:usedSize = 0; // 标记顺序表“无有效元素”(可选)置空数组引用:
elem = null; // 连数组本身的引用也切断(极端情况用,一般步骤1+2足够)
五、ArrayList 无参构造方法
1、无参构造初始化:空数组占位,延迟分配内存
// 无参构造方法
public ArrayList() {this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
// 静态空数组,作为无参构造的初始值
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
- 初始化行为:调用
new ArrayList<>()时,并不会直接分配默认容量(10)的数组,而是让elementData指向空数组DEFAULTCAPACITY_EMPTY_ELEMENTDATA。 - 设计意图:这是一种延迟初始化策略 —— 先占个 “空数组” 的位置,等真正需要存数据(调用
add)时,再分配内存,避免创建空列表时浪费空间。
2、第一次 add 元素:触发内存分配(默认容量 10)
当执行 list.add(1) 这类添加操作时,会进入 add 方法核心逻辑:
public boolean add(E e) {// 计算最小需要的容量,第一次 add 时 size=0,minCapacity=1ensureCapacityInternal(size + 1); // 赋值并递增 sizeelementData[size++] = e; return true;
}
关键方法 ensureCapacityInternal:
private void ensureCapacityInternal(int minCapacity) {// 计算真正需要的容量(第一次 add 时触发特殊逻辑)minCapacity = calculateCapacity(elementData, minCapacity); ensureExplicitCapacity(minCapacity);
}private static int calculateCapacity(Object[] elementData, int minCapacity) {// 如果是无参构造的空数组(DEFAULTCAPACITY_EMPTY_ELEMENTDATA)if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) { // 返回默认容量(10)和 minCapacity 的较大值return Math.max(DEFAULT_CAPACITY, minCapacity); }return minCapacity;
}
- 第一次
add时:elementData是DEFAULTCAPACITY_EMPTY_ELEMENTDATA(空数组),所以calculateCapacity会返回Math.max(10, 1)→ 10(DEFAULT_CAPACITY是 10)。 - 效果:第一次添加元素时,才真正分配容量为 10 的数组,体现 “延迟分配” 的设计,避免空列表占内存。
3、扩容逻辑:1.5 倍扩容,应对容量不足
当添加元素导致 elementData 装满时(如第 11 次 add),会触发扩容:
private void ensureExplicitCapacity(int minCapacity) {modCount++;// 如果需要的容量 > 数组当前长度,触发扩容if (minCapacity - elementData.length > 0) { grow(minCapacity);}
}private void grow(int minCapacity) {int oldCapacity = elementData.length; // 新容量 = 旧容量 + 旧容量的 1/2 → 1.5 倍扩容int newCapacity = oldCapacity + (oldCapacity >> 1); // 如果新容量不够(比如旧容量是 0 时),直接用 minCapacityif (newCapacity - minCapacity < 0) { newCapacity = minCapacity;}// 超过最大限制(Integer.MAX_VALUE - 8)时,特殊处理if (newCapacity - MAX_ARRAY_SIZE > 0) { newCapacity = hugeCapacity(minCapacity);}// 复制数组到新容量elementData = Arrays.copyOf(elementData, newCapacity);
}
- 核心规则:扩容时新容量是旧容量的 1.5 倍(通过位运算
oldCapacity >> 1实现,等价于除以 2 取整)。 - 边界处理:
- 若 1.5 倍扩容后仍不够,直接用
minCapacity(比如初始空数组第一次扩容)。 - 若超过
MAX_ARRAY_SIZE(Integer.MAX_VALUE - 8,避免内存溢出),则用Integer.MAX_VALUE或抛出异常。
- 若 1.5 倍扩容后仍不够,直接用
4、完整流程总结(无参构造 + 添加元素)
- 初始化:
new ArrayList<>()→elementData指向空数组DEFAULTCAPACITY_EMPTY_ELEMENTDATA,不分配实际内存。 - 第一次
add:- 调用
ensureCapacityInternal→ 触发calculateCapacity,因是空数组,返回默认容量 10。 - 分配容量为 10 的数组,存入元素,
size变为 1。
- 调用
- 后续
add:- 若数组未满(
size < elementData.length),直接存数据。 - 若数组已满(
size == elementData.length),触发grow方法,1.5 倍扩容后复制数组,再存数据。
- 若数组未满(
核心设计亮点:
- 延迟初始化:无参构造不占内存,第一次
add才分配默认容量,节省空间。 - 动态扩容:1.5 倍扩容平衡了性能(减少扩容次数)和内存消耗(避免过度分配)。
- 边界处理:针对极端情况(容量过小、过大)做了防护,保证稳定性。
六、ArrayList 接收 Collection 参数的构造方法
用于从其他集合快速初始化 ArrayList
1、构造方法定义与泛型通配符
public ArrayList(Collection<? extends E> c) {// ... 构造逻辑
}
泛型通配符
<? extends E>:
表示传入的Collection集合,其元素类型必须是E的子类(或E本身)。这是上界通配符,保证类型兼容,让ArrayList能接收 “元素类型是E及其子类” 的集合。比如示例中:
list是ArrayList<Integer>(E为Integer)。list12是ArrayList<Number>(E为Number),而Integer是Number的子类,所以list能传给list12的构造方法(满足? extends Number)。
2、构造方法核心逻辑
构造方法内部做了这些事,把传入的 Collection 转成 ArrayList 内部数组:
elementData = c.toArray(); // 1. 转成数组
if ((size = elementData.length) != 0) { // 2. 检查数组长度// 修复 toArray 可能返回非 Object[] 的问题(比如某些集合实现的特殊情况)if (elementData.getClass() != Object[].class) elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {// 空集合,直接指向空数组this.elementData = EMPTY_ELEMENTDATA;
}
- 转成数组:
c.toArray()把传入的集合c转成数组,存入elementData(ArrayList底层存储数组)。 - 处理长度:
- 若数组长度
size != 0:- 额外检查
elementData的类型是否是Object[](防止某些集合的toArray返回特殊类型数组,比如String[]转成ArrayList<Object>时的兼容问题)。 - 不匹配则用
Arrays.copyOf转成标准Object[],保证后续操作安全。
- 额外检查
- 若数组长度
size == 0:直接让elementData指向静态空数组EMPTY_ELEMENTDATA,节省内存。
- 若数组长度
3、示例代码关联
// list 是 ArrayList<Integer>,元素类型 Integer(E 为 Integer)
ArrayList<Integer> list = new ArrayList<>();
list.add(1); list.add(2); list.add(3);// list12 是 ArrayList<Number>,元素类型 Number(E 为 Number)
// 因 Integer 是 Number 的子类,满足 <? extends Number>,所以 list 能传入构造方法
ArrayList<Number> list12 = new ArrayList<>(list);
- 类型兼容:
list的元素是Integer(Number的子类),符合ArrayList<Number>构造方法中Collection<? extends Number>的要求。 - 效果:
list12会把list的元素(1、2、3)复制过来,底层通过c.toArray()转成数组,再初始化elementData,实现从其他集合快速构建ArrayList。
4、设计意图与作用
这个构造方法主要解决 “从已有集合快速初始化 ArrayList” 的需求:
- 灵活兼容:通过
<? extends E>通配符,允许传入 “元素是E子类” 的集合,拓宽使用场景(比如用Integer集合初始化Number集合的ArrayList)。 - 处理边界:修复
toArray可能返回非Object[]的问题,保证ArrayList底层数组类型正确,避免后续操作(如添加、遍历)报错。 - 性能优化:直接基于已有集合的数组转换,减少额外拷贝(除特殊情况的
Arrays.copyOf),提升初始化效率。
三、集合底层数组接收 需要类型转换原理
Java 中,Collection 接口的 toArray() 方法默认返回 Object[] 数组,但某些集合的实现类(如 ArrayList 的子类,或自定义集合)可能重写 toArray(),返回具体类型的数组(比如 String[]、Integer[])。
// 创建一个存储 String 的 ArrayList
ArrayList<String> strList = new ArrayList<>();
strList.add("a");
strList.add("b");// 调用 toArray(),返回的实际是 String[] 类型(而非 Object[])
Object[] arr = strList.toArray();
System.out.println(arr.getClass()); // 输出:class [Ljava.lang.String;(String数组)
toArray()方法的源码逻辑是:直接返回底层数组的 “拷贝”,而拷贝的数组类型会保留元素的实际类型。
简单说:
ArrayList<String> 中存的都是 String,它的 toArray() 会返回一个 “装着 String 的数组”,这个数组在内存中就是 String[] 类型(即使编译时声明为 Object[])。
冲突场景:当用 String[] 初始化 ArrayList<Object> 时
假设我们用上面的 strList 去初始化一个 ArrayList<Object>:
// 用 String 集合初始化 Object 类型的 ArrayList
ArrayList<Object> objList = new ArrayList<>(strList);
此时,strList.toArray() 返回的是 String[] 数组,而 objList 的底层数组 elementData 理论上应该是 Object[] 类型(因为要存储任意 Object 子类对象)。
如果不做处理,objList.elementData 会直接指向 String[] 数组,后续操作会出问题:
// 尝试往 objList 中添加一个 Integer 对象(合法,因为 Integer 是 Object 子类)
objList.add(123); // 编译通过,但运行时会报错!
报错原因:String[] 数组只能存储 String 类型,强行存入 Integer 会触发 ArrayStoreException(数组存储异常)。
解决方案:额外检查并转换为 Object[]
正是为了避免上述问题,ArrayList 的构造方法中加入了类型检查:
// 如果原数组不是 Object[] 类型,就转换为 Object[]
if (elementData.getClass() != Object[].class) elementData = Arrays.copyOf(elementData, size, Object[].class);
- 当
toArray()返回的是String[]时,elementData.getClass() != Object[].class成立,触发转换。 Arrays.copyOf(..., Object[].class)会创建一个新的Object[]数组,并复制原数组元素,保证elementData是Object[]类型。
这个细节体现了 Java 泛型和数组类型系统的严谨性,避免了因类型不匹配导致的运行时异常。