[docker/大数据]Spark快速入门
[docker/大数据]Spark快速入门

1. 概述
1.1 诞生背景
Spark官方文档:https://spark.apache.ac.cn/docs/latest/
Spark 由加州大学伯克利分校 AMP 实验室于 2009 年开发,2013 年成为 Apache 顶级项目,旨在解决 MapReduce 的三大核心问题:
- 功能局限:仅支持 Map 和 Reduce 两种操作,难以处理复杂计算
- 执行效率低:频繁的磁盘 I/O 操作导致性能瓶颈
- 生态割裂:需要与 Storm/Hive/HBase 等组件组合才能完成完整数据处理流程
1.2 核心特点
| 特点 | 说明 | 优势 |
|---|---|---|
| 极速处理 | 内存计算比 MapReduce 快 10-100 倍 | 实时分析能力 |
| All-in-One | 统一引擎支持多种计算范式 | 简化技术栈 |
| 易用性 | 支持 Scala/Java/Python/R/SQL | 开发者友好 |
| 容错性 | RDD 机制保障故障恢复 | 高可靠性 |
2. 核心概念
2.1 核心组件
Spark Core主要包含四大模块:Spark SQL(结构化数据处理)、Spark Streaming(流批次处理)、MLib(机器学习库)、GraphX(图计算模块)
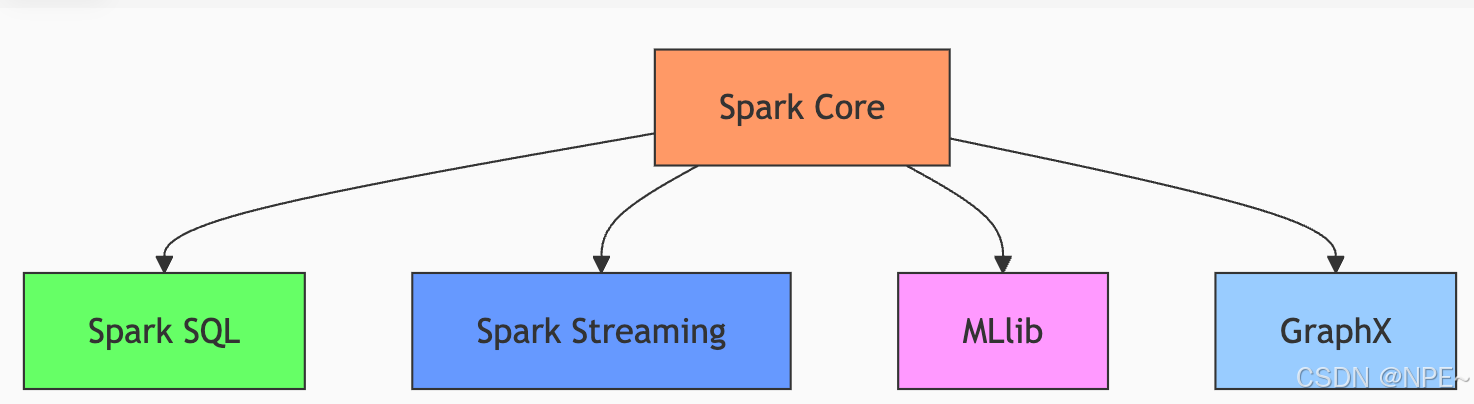
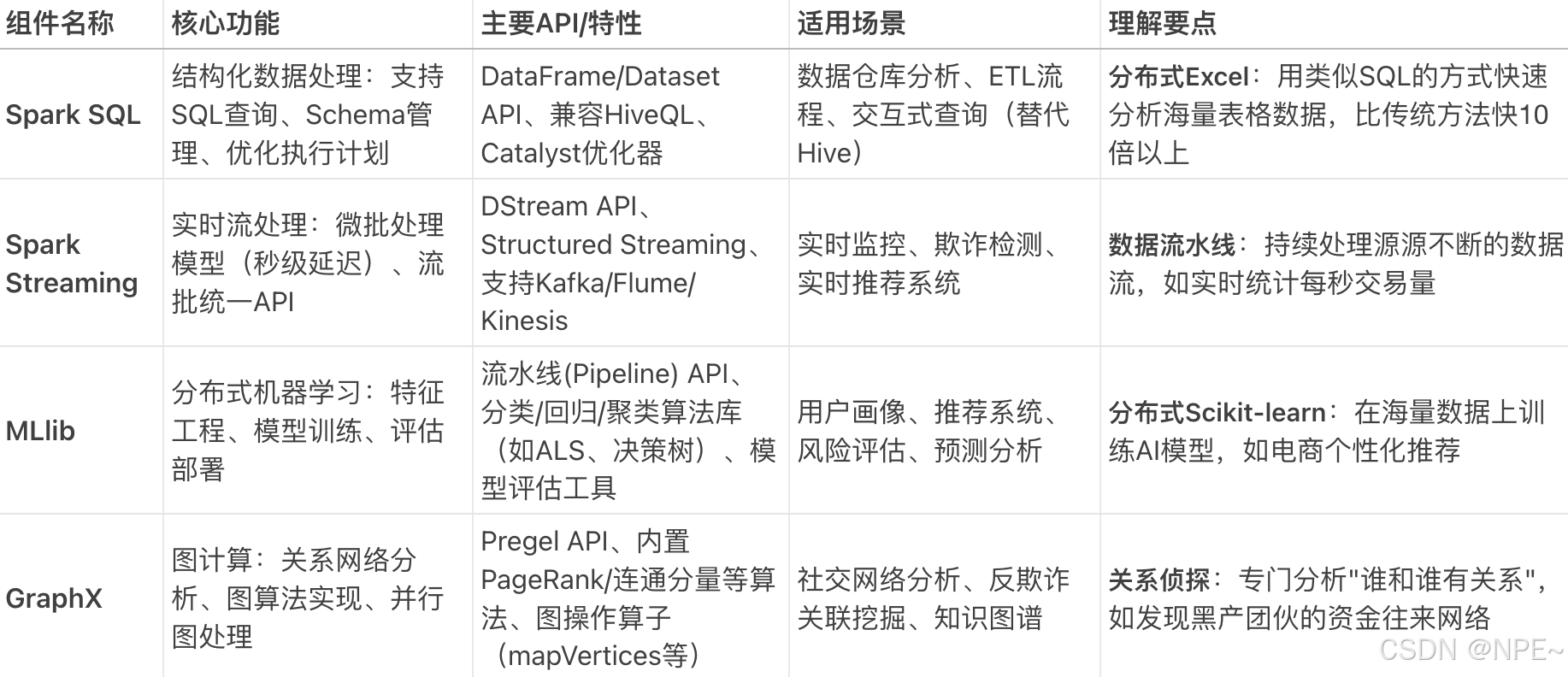
案例:比如我们要基于用户行为日志进行分析,下面是各组件的分工:

- Streaming:实时接收用户点击/购买数据流
- SQL:将数据转为结构化表格,存储到数据仓库
- MLlib:基于历史数据训练"看了又看"推荐模型
- GraphX:分析用户间的设备/IP关联,识别刷单团伙
- Core:底层支撑所有组件的分布式运行
2.2 RDD分布式数据集
RDD是Spark 最核心、最根本的数据抽象。如果说Spark是一个巨大的数据工厂,那么RDD就是工厂流水线上的一个个原材料零件、半成品。
2.2.1 特点
RDD(Resilient Distributed Dataset )弹性分布式数据集特点:
| 特性 | 说明 | 优势 |
|---|---|---|
| 分布式 | 数据分区存储在集群节点 | 并行处理 |
| 弹性 | 支持高效故障恢复 | 容错性强 |
| 不可变 | 只读数据集 | 避免并发问题 |
| 延迟计算 | 操作按需执行 | 优化执行计划 |
1.分布式:
- 概念:你的数据量非常大,一台机器存不下、算不动。RDD 会把数据自动切割成很多份(Partitions/分区),分散存储在集群的多个机器上
- 类比: 一本1000页的巨著,分给10个人一起读,每人读100页。这10个人就是一个“集群”,每个人手里的100页就是一个“分区”。
- 好处: 并行计算,速度极快。
2.数据集:
- 概念:表示是数据的集合。RDD 里面可以存储任何类型的数据,比如数字、字符串、对象等。
- 类比: 上面例子中,书里的文字内容就是“数据”。
3.弹性:
- 概念:有容错性,当有数据丢失时可以快速恢复数据,这也是 Spark 比 Hadoop MapReduce 快的关键原因,例如:集群中某个机器突然宕机了,它上面存储的那个数据分片(那100页书)丢了怎么办?传统方法需要从头重新计算。Spark的解决方案: RDD 记录了自己是如何从其他数据“计算”过来的(例如: “我是通过A文件经过filter操作再经过map操作得到的”)。这个记录叫做血统(Lineage)。
- 类比: 读第3章需要先读第1章和第2章。如果某人手里的第2章丢了,我们不需要从头开始写书,只需要根据“依赖关系”(血统),让他去找有第1章的人,重新读一遍第1章,然后自己再推导出第2章即可。
- 好处: 快速恢复数据,无需昂贵的数据复制备份。
2.2.2 RDD操作类型
RDD(Resilient Distributed Dataset )又称弹性分布式数据集,操作主要包含两类:Transformation和Action。
①Transformation(转换,只做规划):主要是规划;它会定义一个新的 RDD 是如何从现有的 RDD 计算过来的操作。它不会立即执行计算,只是在记录一个计算逻辑,而不是真正去算。
- map(): 对数据集中每个元素都执行一个函数。(例如:把每一行文字都变成大写)
- filter(): 过滤掉不符合条件的元素。(例如:筛选出所有包含“错误”关键词的日志行)
- groupByKey(): 对键值对数据按键进行分组。
- reduceByKey(): 对每个键对应的值进行聚合计算。
类比: 厨师拿到菜谱,菜谱上写着“1. 洗菜,2. 切菜,3. 炒菜”。此刻厨师只是在看菜谱,还没开始动手做。菜谱就是一系列的 Transformation。
②Action(动作,触发实际计算):实际计算;触发实际计算,并返回结果给 Driver 程序或存储到外部系统的操作。
- take(n): 取前n个元素。
- saveAsTextFile(path): 将数据集保存到文件系统(如HDFS)。
类比:顾客说“老板,上菜!”。这时厨师才真正开始执行菜谱上的所有步骤(洗、切、炒)。这句“上菜”就是 Action。
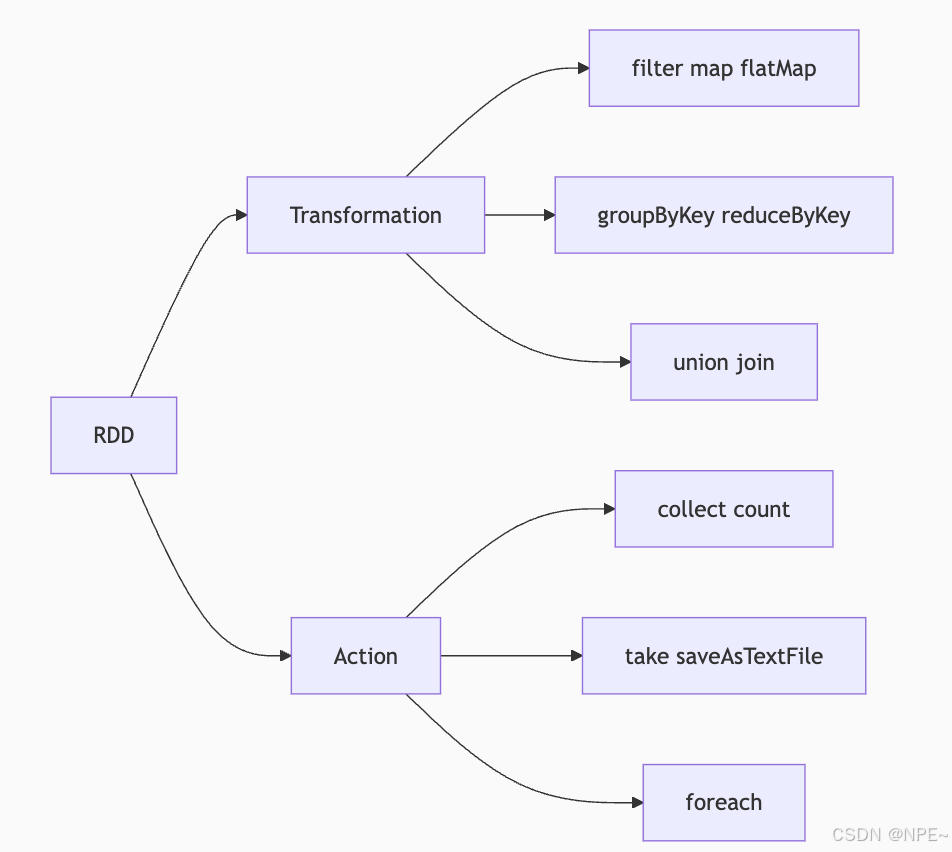
Spark计算核心流程:定义Transformations -> 最后调用Action -> Spark生成执行计划 -> 分布式计算 -> 返回结果。
Q:为什么Spark需要惰性计算,即先规划,后计算?
A:Spark可以在看到所有“计划”(Transformation链)和一个最终“目标”(Action)后,对整个计算过程进行整体优化(比如合并一些操作),然后再执行,这样效率更高。
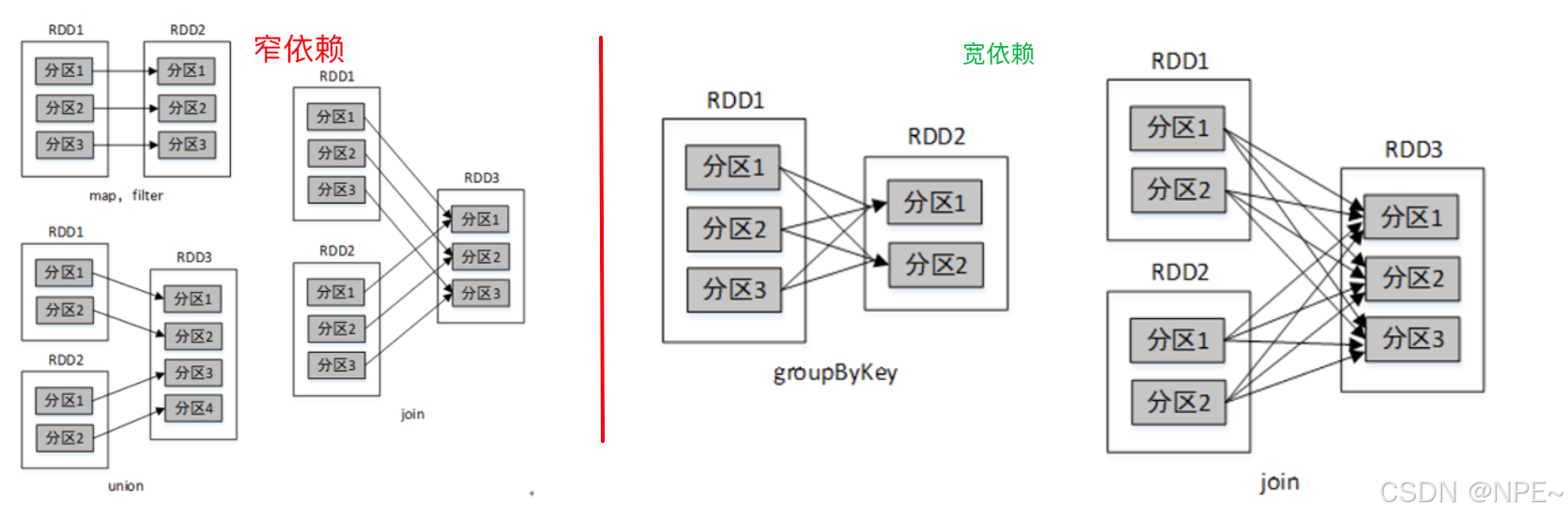
2.2.3 RDD依赖关系(宽窄依赖)
概念:一个 RDD 是由另一个或多个 RDD 通过 Transformation 计算得来的。这种“父子关系”就是依赖关系。
Spark 需要记录这种关系(即血统 Lineage),目的有两个:
- 容错:如果某个分区的数据丢了,可以根据血统关系重新计算。
- 任务调度:根据依赖类型来规划最有效的执行方式(这导致了 Stage 的划分)。
RDD的依赖关系分为两种:窄依赖(Narrow Dependency) 和 宽依赖(Wide Dependency / Shuffle Dependency):
1. 窄依赖(窄关系):
- 一对一:父 RDD 的每一个分区最多被子 RDD 的一个分区所使用。像一对一的护送,数据不需要在不同机器间移动(无需 Shuffle)。即:上游的RDD数据最多只会流到下游的一个RDD中,一对一的关系。
- 比如:map()、filter()、union() 这些
2. 宽依赖(宽关系):
- 一对多:父RDD的一个分区被子RDD的多个分区所用。即:上游的RDD数据会流向下游多个RDD
- 比如:groupByKey()、reduceByKey()、sortByKey()这些
2.3 Spark 运行详解
2.3.1 运行架构
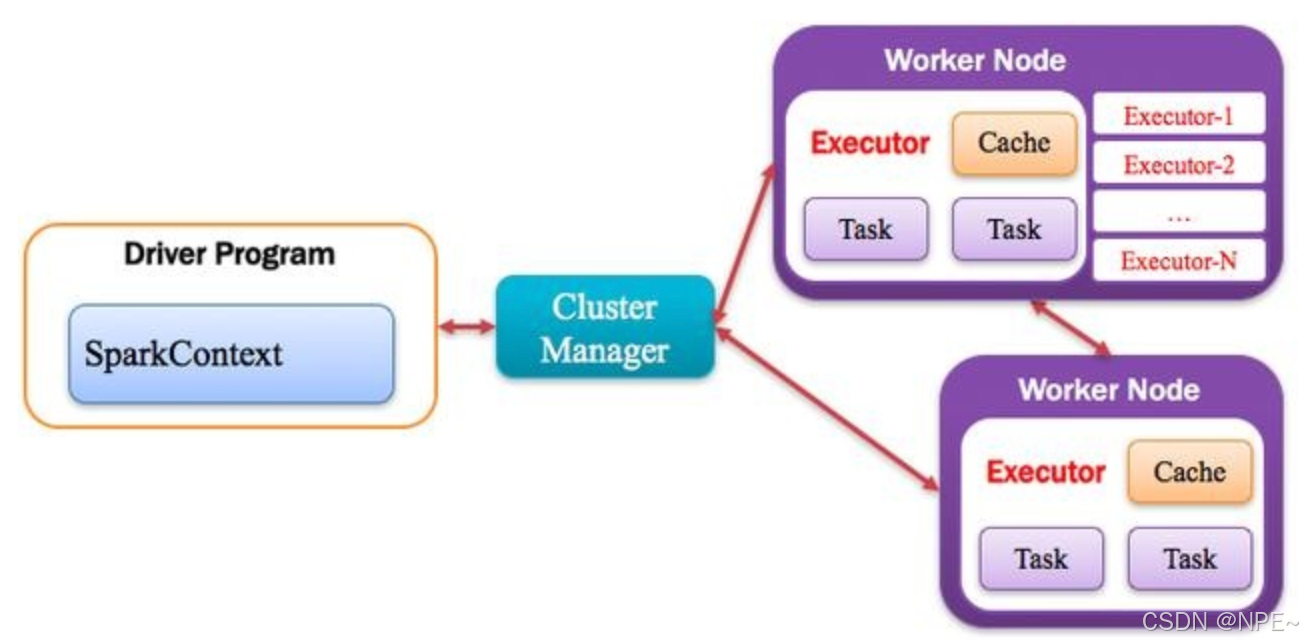
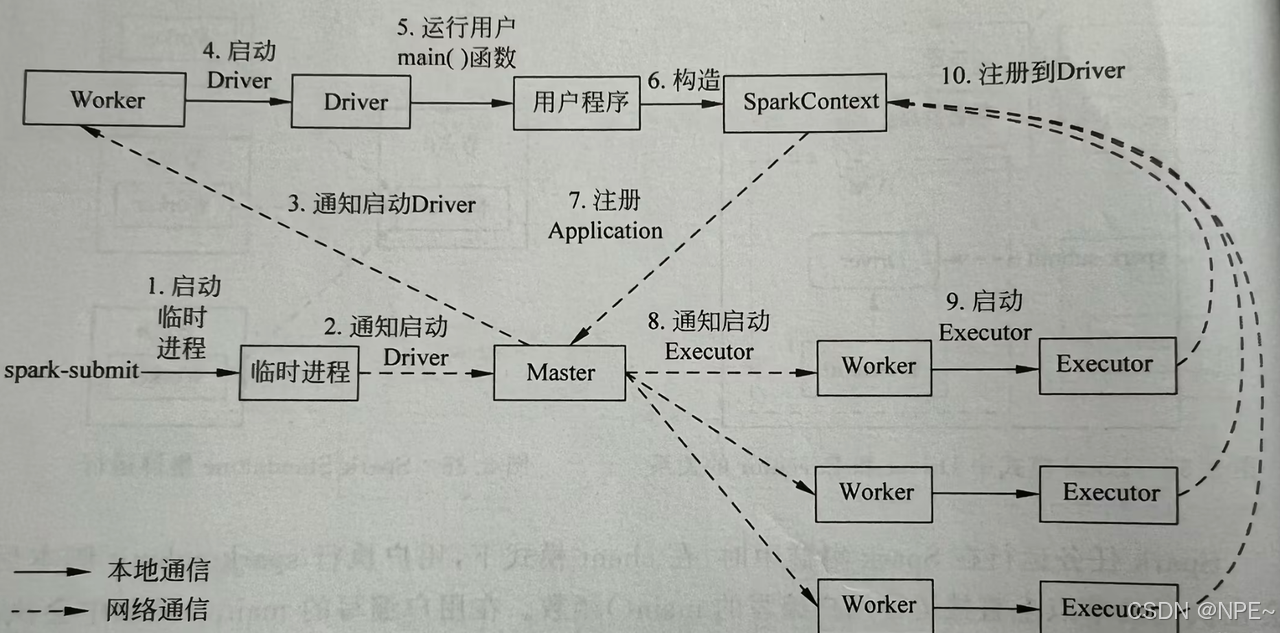
Spark应用程序以进程集合为单位在分布式集群上运行,通过driver程序的main方法创建的SparkContext对象与集群交互。
1、Spark通过SparkContext向Cluster manager(资源管理器)申请所需执行的资源(cpu、内存等)
2、Cluster manager分配应用程序执行需要的资源,在Worker节点上创建Executor
3、SparkContext 将程序代码(jar包或者python文件)和Task任务发送给Executor执行,并收集结果给Driver。
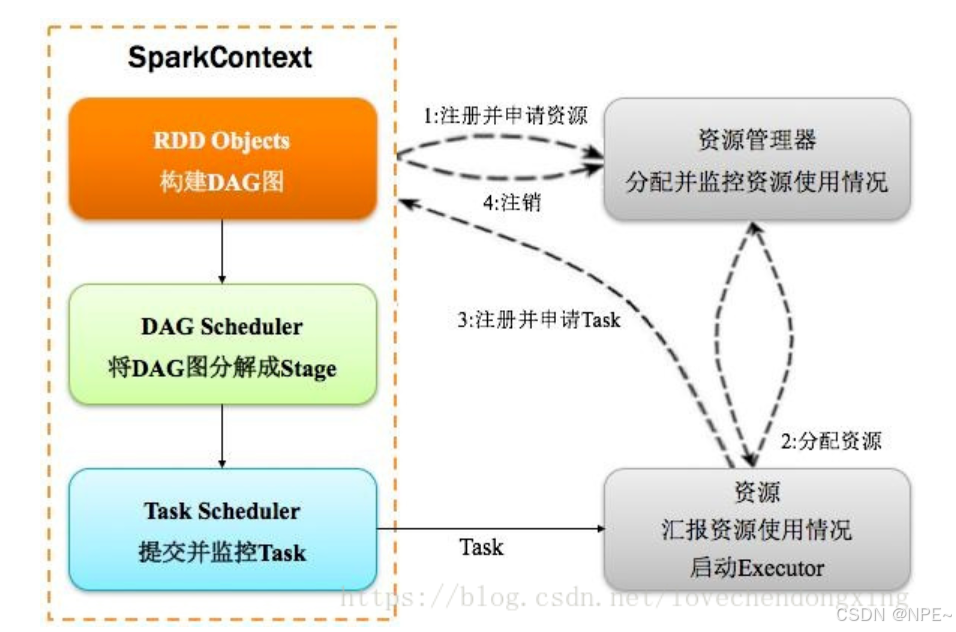
2.3.2 运行流程
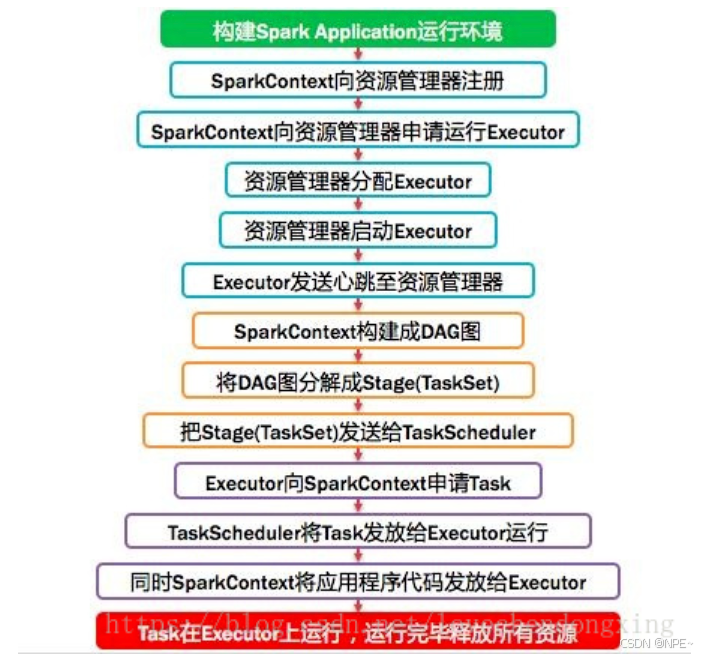
2.3.3 功能介绍
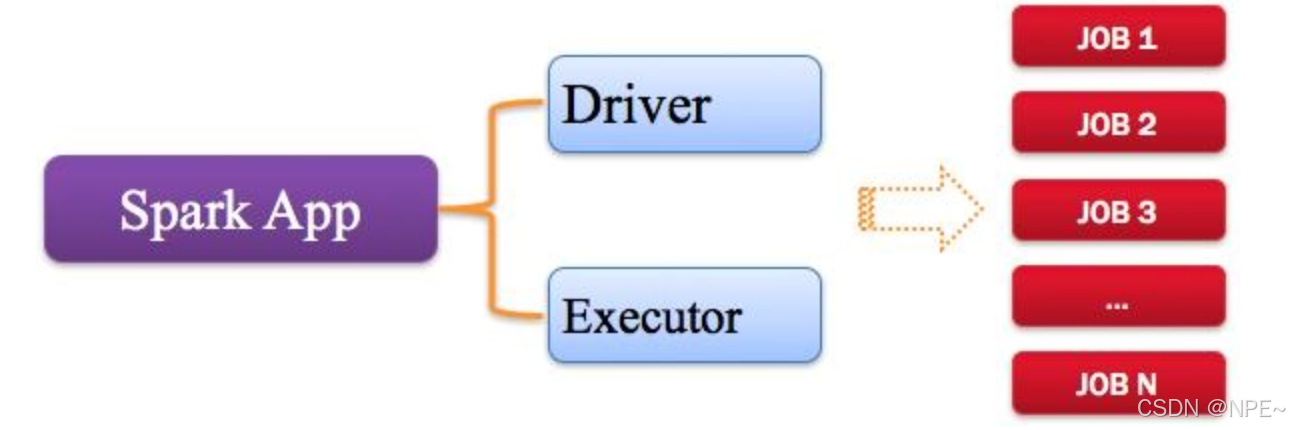
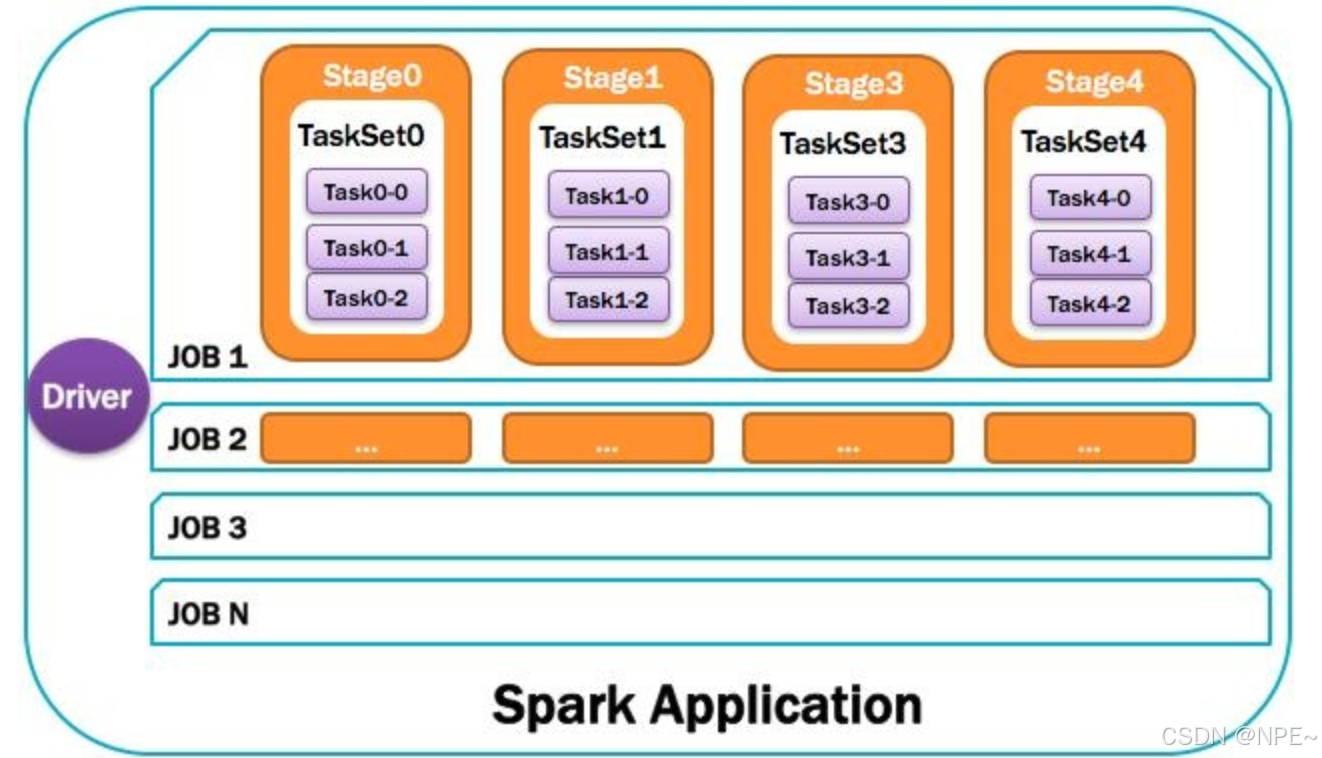
1. Application[用户编写的应用程序]
指的是用户编写的Spark应用程序,包含了Driver功能代码和分布在集群中多个节点上运行的Executor代码。
Spark应用程序,由一个或多个作业JOB组成,如下图所示。
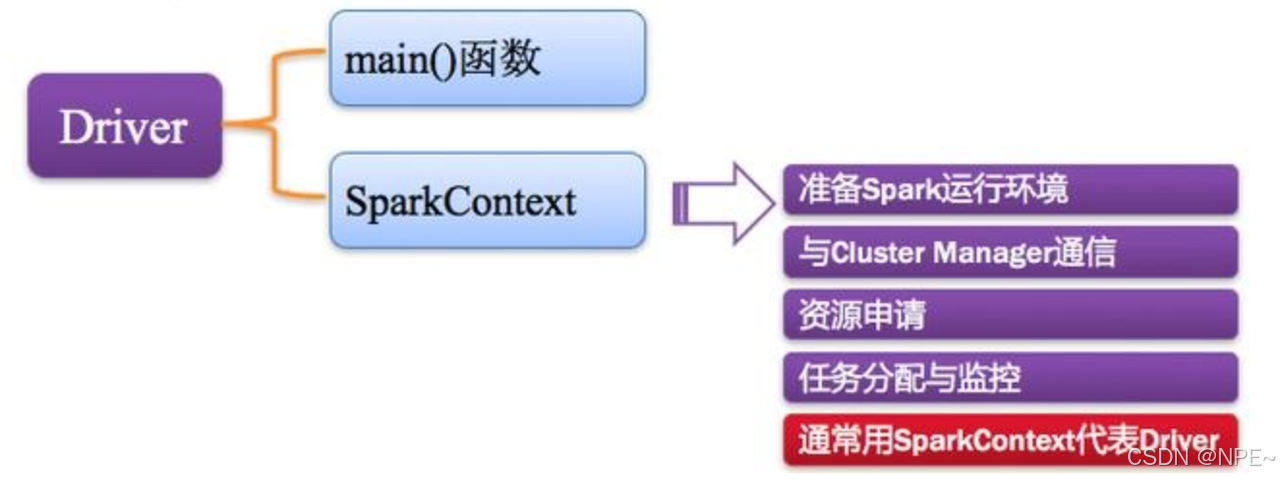
2. Driver:驱动程序
Spark中的Driver即运行上述Application的Main()函数并且创建SparkContext,其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;
当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常SparkContext代表Driver,如下图所示。
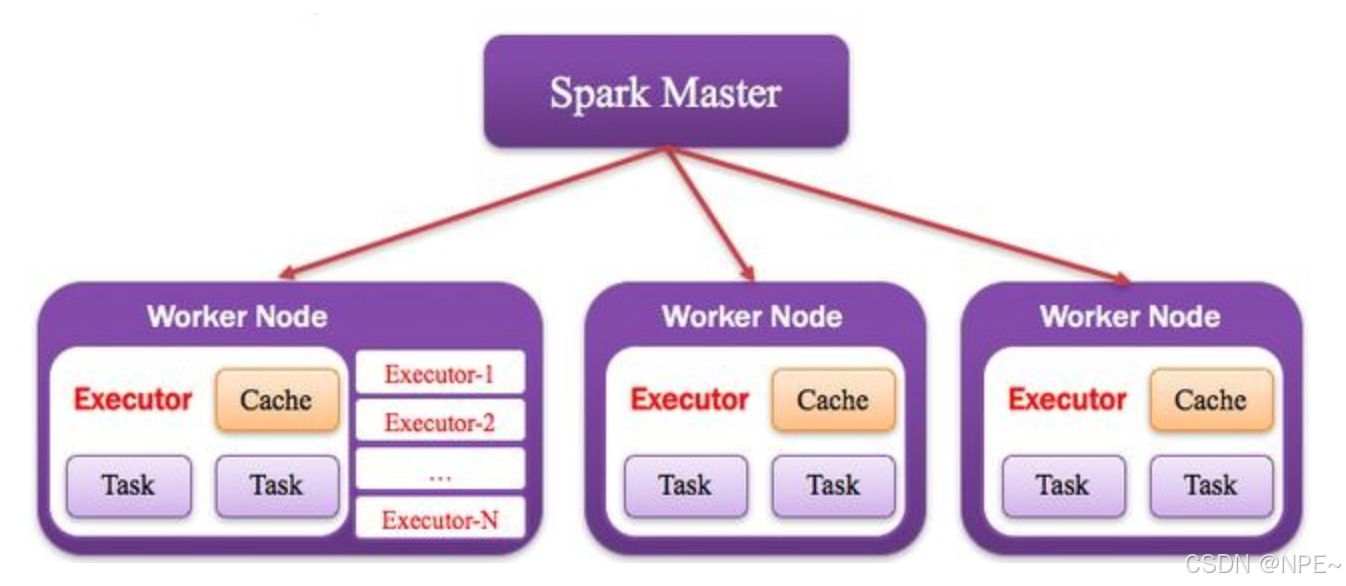
3. Cluster Manager:资源管理器
指的是在集群上获取资源的外部服务,常用的有:Standalone,Spark原生的资源管理器,由Master负责资源的分配;Haddop Yarn,由Yarn中的ResearchManager负责资源的分配;Messos,由Messos中的Messos Master负责资源管理。
4. Executor:执行器
Application运行在Worker节点上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上,每个Application都有各自独立的一批Executor,如下图所示。
5. Worker:计算节点
集群中任何可以运行Application代码的节点,类似于Yarn中的NodeManager节点。在Standalone模式中指的就是通过Slave文件配置的Worker节点,在Spark on Yarn模式中指的就是NodeManager节点,在Spark on Messos模式中指的就是Messos Slave节点,如下图所示。
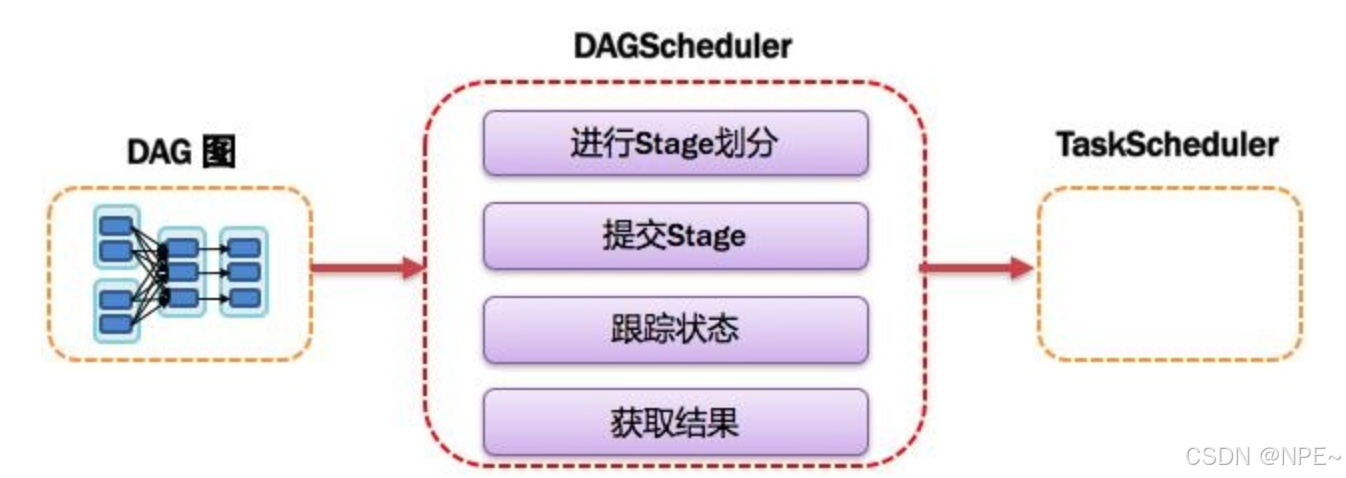
6. DAGScheduler:有向无环图调度器
基于DAG划分Stage 并以TaskSet的形式提交Stage给TaskScheduler;负责将作业拆分成不同阶段的具有依赖关系的多批任务;最重要的任务之一就是:计算作业和任务的依赖关系,制定调度逻辑。在SparkContext初始化的过程中被实例化,一个SparkContext对应创建一个DAGScheduler。
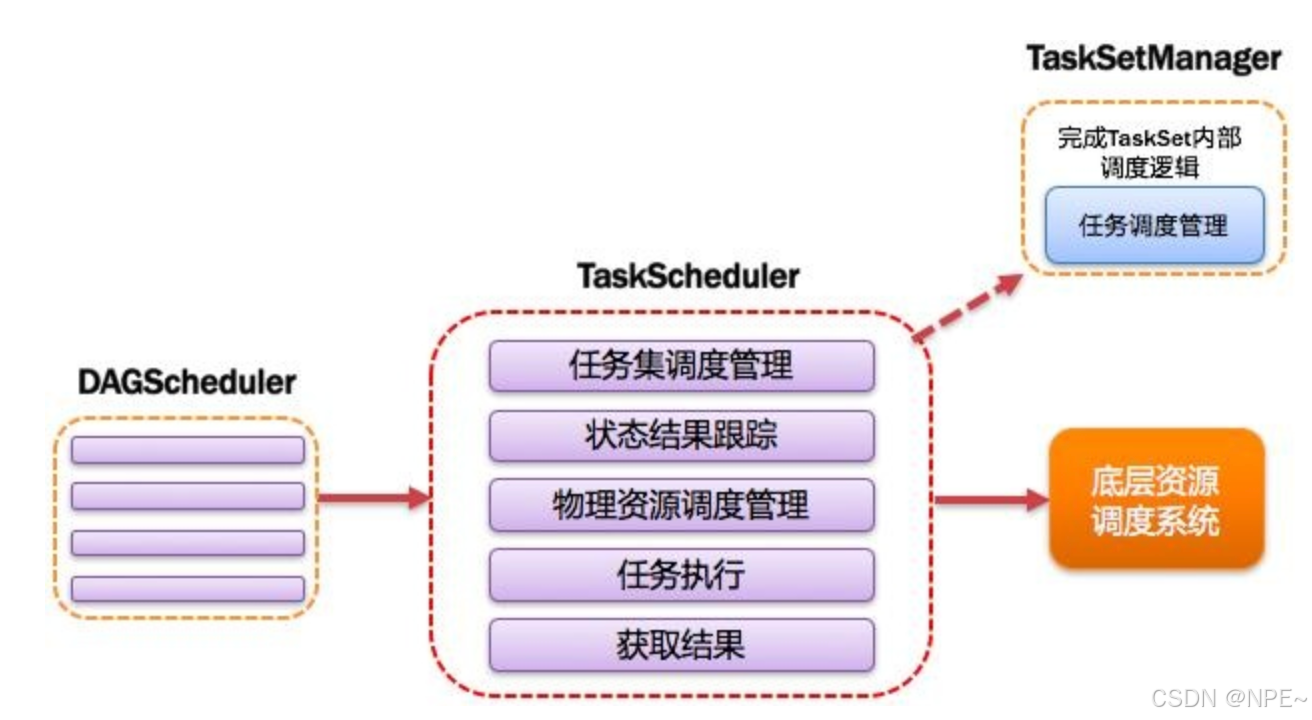
7. TaskScheduler:任务调度器
将Taskset提交给worker(集群)运行并回报结果;负责每个具体任务的实际物理调度。如图所示。
8. Job:作业
由一个或多个调度阶段所组成的一次计算作业;包含多个Task组成的并行计算,往往由Spark Action催生,一个JOB包含多个RDD及作用于相应RDD上的各种Operation。如图所示。
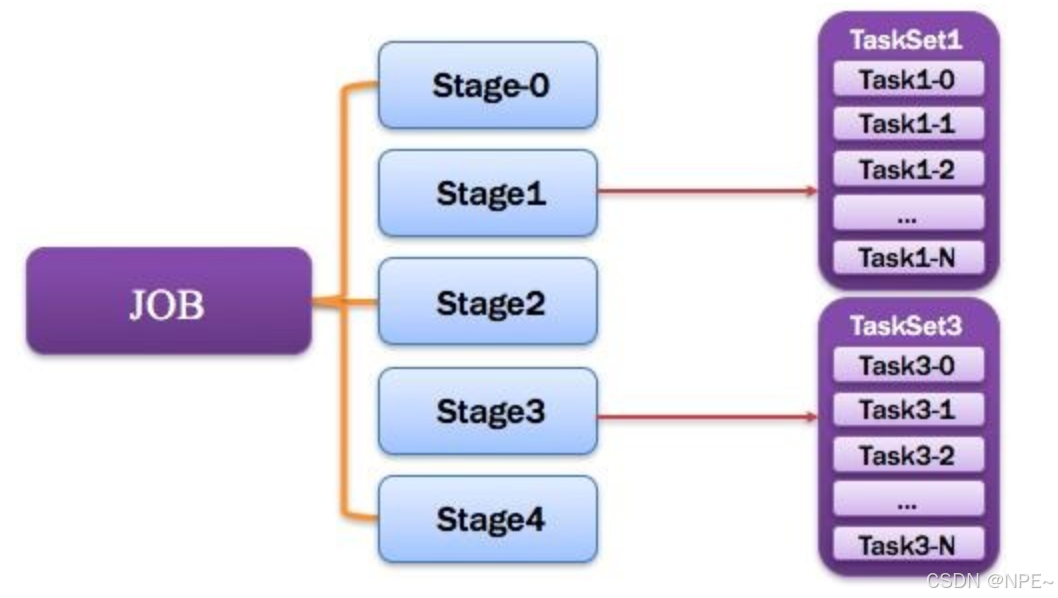
9. Stage:调度阶段
一个任务集对应的调度阶段;每个Job会被拆分很多组Task,每组任务被称为Stage,也可称TaskSet,一个作业分为多个阶段;Stage分成两种类型ShuffleMapStage、ResultStage。如图所示。
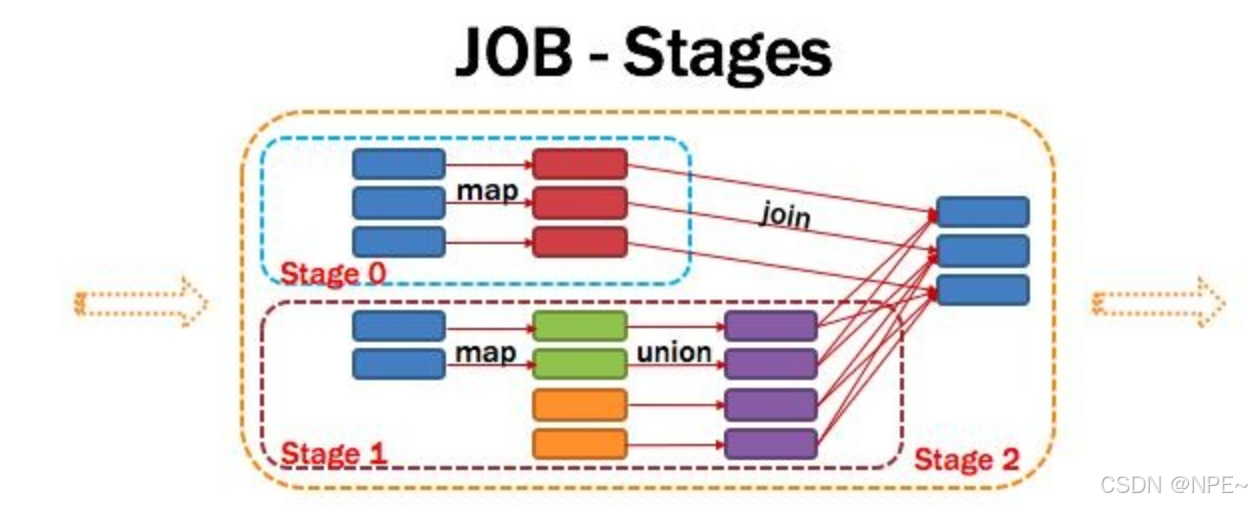
Application多个job多个Stage:Spark Application中可以因为不同的Action触发众多的job,一个Application中可以有很多的job,每个job是由一个或者多个Stage构成的,后面的Stage依赖于前面的Stage,也就是说只有前面依赖的Stage计算完毕后,后面的Stage才会运行。
划分依据:Stage划分的依据就是宽依赖,何时产生宽依赖,reduceByKey, groupByKey等算子,会导致宽依赖的产生。
核心算法:从后往前回溯,遇到窄依赖加入本stage,遇见宽依赖进行Stage切分。Spark内核会从触发Action操作的那个RDD开始从后往前推,首先会为最后一个RDD创建一个stage,然后继续倒推,如果发现对某个RDD是宽依赖,那么就会将宽依赖的那个RDD创建一个新的stage,那个RDD就是新的stage的最后一个RDD。然后依次类推,继续继续倒推,根据窄依赖或者宽依赖进行stage的划分,直到所有的RDD全部遍历完成为止。
将DAG划分为Stage剖析:如上图,从HDFS中读入数据生成3个不同的RDD,通过一系列transformation操作后再将计算结果保存回HDFS。可以看到这个DAG中只有join操作是一个宽依赖,Spark内核会以此为边界将其前后划分成不同的Stage. 同时我们可以注意到,在图中Stage2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作,通过map操作生成的partition可以不用等待整个RDD计算结束,而是继续进行union操作,这样大大提高了计算的效率。
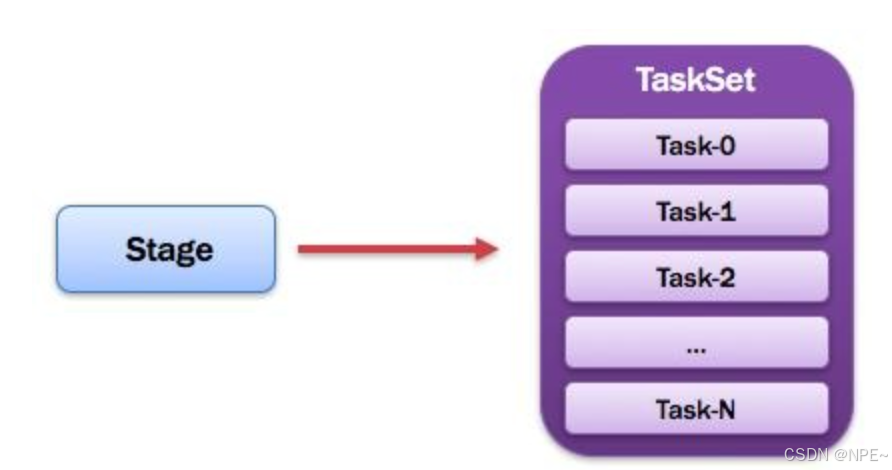
10. TaskSet:任务集
由一组关联的,但相互之间没有Shuffle依赖关系的任务所组成的任务集。如图所示。
PS:
1)一个Stage创建一个TaskSet;
2)为Stage的每个Rdd分区创建一个Task,多个Task封装成TaskSet
11. Task:任务
被送到某个Executor上的工作任务;单个分区数据集上的最小处理流程单元(单个stage内部根据操作数据的分区数划分成多个task)。如图所示。
总体如图所示:
2.4 Spark 运行模式
Spark主要分为以下几种运行模式:
- 本地模式;
- standalone模式;
- spark on yarn 模式,又细分为两种子模式:yarn-client和yarn-cluster;
- spark on mesos 模式
- spark on cloud 模式
本文主要介绍前四种模式。
| 运行模式 | 资源管理者 | 核心特点 | 主要应用场景 |
|---|---|---|---|
| 本地模式 | 本地JVM | 单机多线程模拟分布式计算,简单易用 | 开发、测试、学习 |
| Standalone模式 | Spark自带Master | Spark自带的独立集群模式,无需依赖其他资源管理系统 | 中小规模Spark专属集群 |
| Spark on YARN | Hadoop YARN | 利用Hadoop YARN进行资源调度,与Hadoop生态集成紧密,生产环境最常用 | 共享Hadoop集群的大规模生产环境 |
| Spark on Mesos | Apache Mesos | 更灵活的通用集群管理,支持细粒度调度(但细粒度模式已被弃用) | 混合负载集群(如同时运行Spark、MPI等) |
本地模式
概念:Spark不一定非要跑在hadoop集群,可以在本地,起多个线程的方式来指定。将Spark应用以多线程的方式直接运行在本地,一般都是为了方便调试,本地模式分三类
- local:只启动一个executor
- local[k]:启动k个executor
- local[*]:启动跟cpu数目相同的executor
应用场景:一般用于开发测试。
执行流程:以 local[2] 为例
- 在IDE或Spark Shell中提交应用程序。
- Spark会在本地启动一个JVM进程,这个进程既充当Driver(指挥者),又充当Executor(工作者)。
- Driver会创建 SparkContext,并初始化调度器(如 TaskScheduler)。
- SparkContext 会启动指定数量(此处为2个)的线程作为执行线程(Executor threads)。
- 所有的任务(Tasks)会在这2个线程中并行执行。
- 任务执行完毕后,结果返回到Driver,或写入本地文件系统。
Standalone模式
概念:它是一个主从式架构,包含Master(主节点)和Worker(从节点)。Master负责管理整个集群的资源,Worker负责在节点上启动Executor进程来执行具体任务。
应用场景:适用于中小规模的、专用的Spark集群。如果你不想依赖Hadoop YARN等其他资源管理系统,希望Spark独享集群资源,那么可以选择Standalone模式。
运行流程:
- 启动集群:事先在集群的每个节点上启动Spark的Master和Worker守护进程。
- 提交应用:用户通过spark-submit脚本或代码向Master提交应用程序。
- 资源申请:应用程序中的SparkContext向Master注册并申请资源(CPU和内存)。
- 启动Executor:Master根据Worker的心跳报告(汇报自身资源情况),在资源充足的Worker节点上启动Executor进程。
- 任务调度与执行:
- Executor启动后,会向SparkContext反向注册。
- SparkContext将应用程序代码(JAR包或Python文件)发送给Executor。
- SparkContext根据程序中的RDD操作构建DAG图,并由DAGScheduler将其划分为Stage,再由TaskScheduler将每个Stage转化为一批Task,然后分发到各个Executor上执行。
- 结果与释放:Task执行完毕后,将结果返回给Driver或写入外部存储。所有任务完成后,SparkContext向Master注销,释放资源。
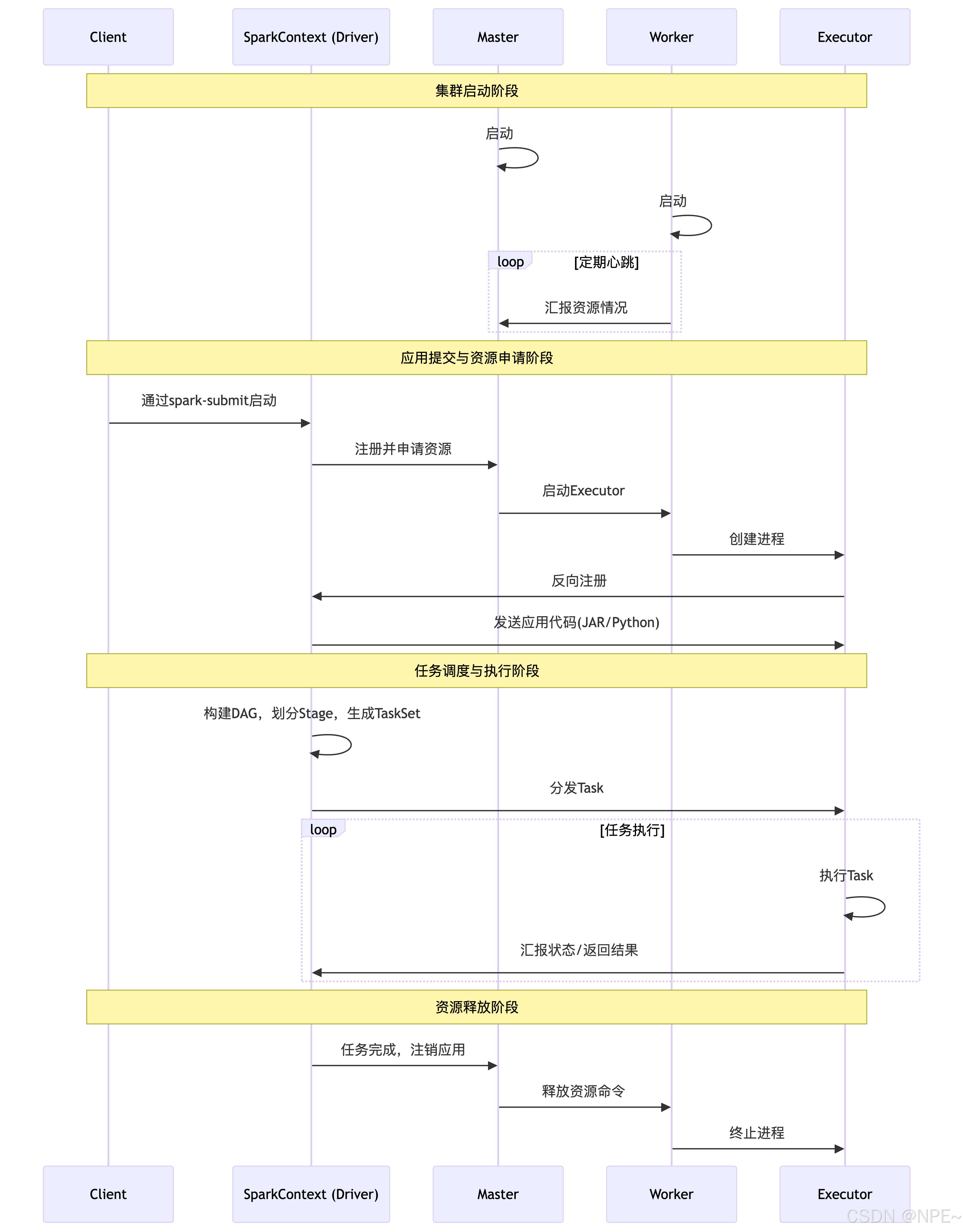
下面这个图也非常经典:
spark on yarn 模式
概念:Spark客户端直接连接Yarn。不需要额外构建Spark集群。 分布式部署集群,资源和任务监控交给yarn管理,但是目前仅支持粗粒度资源分配方式。它根据Driver程序运行位置的不同分为cluster和client运行模式,cluster适合生产,driver运行在集群子节点,具有容错功能,client适合调试,dirver运行在客户端。
- yarn-client模式:Driver程序运行在提交任务的客户端机器上。
- yarn-cluster模式:Driver程序运行在YARN集群的某个NodeManager节点上(作为ApplicationMaster的一部分)。
应用场景:适用于公司已有Hadoop YARN集群,希望Spark与其他计算框架(如MapReduce)共享集群资源,统一管理的大规模生产环境。spark on yarn-client模式适合交互和调试(如:通过spark-shell),on yarn-Cluster模式更适合生产环境。
运行流程: (以 yarn-cluster 模式为例):
- 提交应用:用户通过spark-submit脚本,指定–master yarn和–deploy-mode cluster,向YARN的ResourceManager提交应用程序。
- 启动ApplicationMaster:ResourceManager在某个NodeManager上分配一个Container,并在其中启动ApplicationMaster(AM)。注意:在cluster模式下,AM本身就包含了Spark Driver。
- 申请资源:AM(Driver)向ResourceManager申请运行Executor所需的资源。
- 启动Executor:ResourceManager分配Container后,AM与对应的NodeManager通信,在Container中启动Executor进程。
- 任务执行:Executor启动后,会向AM(Driver)注册。AM(Driver)中的SparkContext将Task分发给Executor执行。
- 完成与清理:应用运行完成后,AM会向ResourceManager注销并关闭自己,其占用的资源也随之释放。
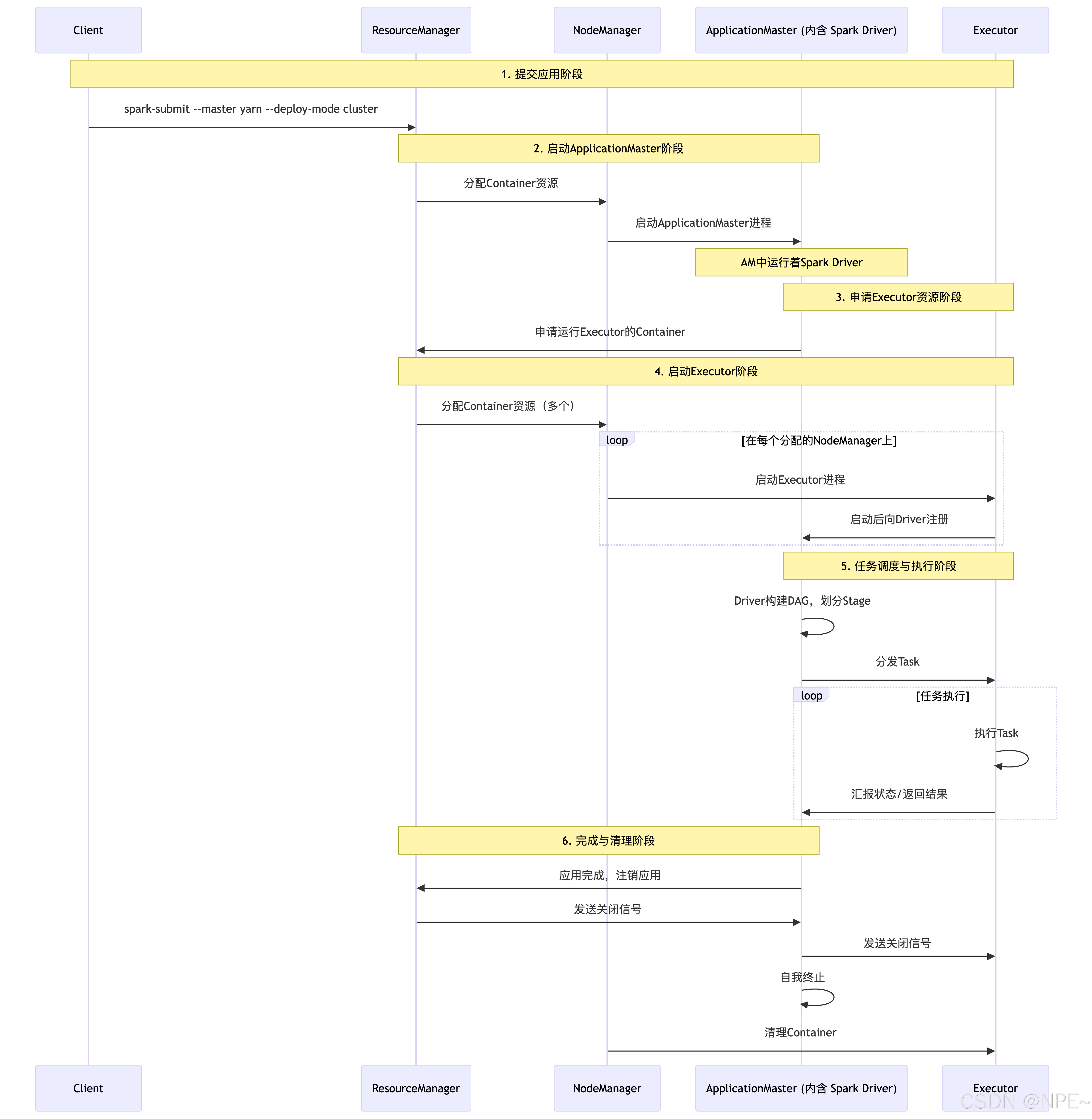
PS:client模式与cluster模式区别
| 特性 | YARN-Client 模式 | YARN-Cluster 模式 | 核心提示 |
|---|---|---|---|
| Driver 位置 | 客户端机器上 | 集群中的 ApplicationMaster 里 | 最根本的区别,决定了其他所有不同。 |
| Application Master 角色 | 轻量,仅负责申请 Executor 资源 | 重量,就是 Driver 本身,负责全部调度 | Cluster 模式的 AM 权力更大。 |
| 客户端要求 | 必须保持在线,直到应用结束 | 提交后即可断开 | 想关电脑就用 Cluster。 |
| 日志输出 | 直接输出到客户端控制台,便于调试 | 需要通过 yarn logs 命令或 Web UI 查看 | 调试用 Client,生产用 Cluster。 |
| 性能 | 网络通信可能跨网段,性能较差 | Driver 在集群内,网络通信效率高 | Cluster 模式性能更优。 |
| 应用场景 | 测试、调试、交互式查询 | 生产环境、长时间运行的任务 | 开发用 Client,上线用 Cluster。 |
yarn-client:
- 用于测试,因为driver运行在本地客户端,负责调度application,会与yarn集群产生超大量的网络通信。好处是直接执行时,本地可以看到所有的log,方便调试。
- Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开。
yarn-cluster:
- 生产环境使用, 因为driver运行在nodemanager上,缺点在于调试不方便,本地用spark-submit提价以后,看不到log,只能通过yarn application-logs application_id这种命令查看,很麻烦
- Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业;
spark on mesos 模式
概念:Spark可以作为Mesos框架上的一个应用程序运行,由Mesos来负责资源调度和分配。
应用场景:适用于需要运行多种类型计算框架(如同时运行Spark、MPI作业等)的混合负载集群,Mesos可以提供更灵活和通用的资源调度。
运行流程:(以粗粒度模式为例)
- 用户向Mesos Master提交Spark应用。
- Mesos Master将资源offer发送给Spark的调度器(Driver)。
- Spark Driver接受offer,并指示Mesos在提供资源的Slave节点上启动Executor。
- Executor启动后,直接与Spark Driver通信,注册并申请Task。
- Driver分配Task给Executor执行。
- 执行过程中,Executor直接向Driver汇报状态。
2.5 Stage 划分
划分原理
可以把 Spark 的任务执行想象成一个工厂的流水线:
- DAG(有向无环图):这是整个产品的生产流程图,由一系列步骤(RDD 转换操作)组成。
- Stage(阶段):流程图会被划分成几个大的生产阶段。划分的原则是:能否在流水线上不间断地完成一系列加工。
- 宽窄依赖:这是划分 Stage 的依据。
- 窄依赖:一个父零件只用来生产一个子零件。好比在同一个工位上对零件进行打磨、抛光。这些操作可以合并成一个 Stage,无需移动零件(无 Shuffle),效率极高。
- 宽依赖:需要把所有父零件打乱重组。好比把所有零件运到一个集中的装配区(Shuffle),按新的规则分组后才能进行下一步组装。这里必须划分成一个新的 Stage。
核心思想:Spark 的 DAGScheduler 会从最终结果倒推这个“流程图”,一旦遇到宽依赖(Shuffle),就画上一条分界线,形成一个新 Stage。每个 Stage 内部都是一连串的窄依赖,可以进行流水线优化(Pipeline),在内存中连续计算。
优化建议[调优]
| 优化方向 | 目标 | 具体方法 | 代码示例(不推荐 → 推荐) |
|---|---|---|---|
| 减少 Shuffle | 降低网络/磁盘IO | 使用预聚合算子;使用广播Join | rdd.groupByKey().mapValues(sum) → rdd.reduceByKey(_ + _) |
| 持久化 (Cache) | 避免重复计算 | 对多次使用的RDD进行缓存 | “val transformed = rdd.map(…)transformed.count(); transformed.reduce() → transformed.persist().count(); .reduce()” |
| 并行度 | 充分利用资源 | 调整Shuffle后的分区数 | 使用 spark.sql.shuffle.partitions 参数 |
| 数据倾斜 | 避免长尾任务 | 对倾斜Key进行加盐处理 | join(skewRdd) → addRandomPrefix(skewRdd).join(…).removePrefix() |
PS:优化原理
- 减少与避免 Shuffle
为什么? Shuffle 是分布式计算中最昂贵操作,涉及磁盘 I/O、网络 I/O、序列化/反序列化。减少一次 Shuffle,性能提升立竿见影。Stage 数量 ≈ Shuffle 次数。减少 Stage 数量本质上就是减少 Shuffle 次数。- 持久化(缓存)的正确使用
为什么? 如果一个 RDD 会被多个 Action 操作重用(例如一个循环里),默认情况下每次 Action 都会从头重新计算整个 RDD,极其浪费。- 解决数据倾斜
为什么? 如果某个 Task 的数据量远远超过其他 Task,导致绝大多数任务早就完成了,却在等那一个“慢哥”,会导致资源闲置。
建议:
- 写代码时时刻思考:“我这一步操作会不会引起 Shuffle?”
- 充分利用 Spark UI:提交任务后,一定要打开 Spark UI(通常是 http://:4040)。这是你最好的老师!在里面你可以看到:
- 整个执行的 DAG 可视化图,清晰看到有几个 Stage。
- 每个 Stage 的详情,有多少个 Task,花了多少时间。
- Shuffle 读写的数据量,如果看到某个 Stage 写入了大量数据,就要警惕了。
- 从模仿开始:先记住 reduceByKey 比 groupByKey 好,broadcast join 比普通 join 好,在实际代码中先用起来。
3. 快速入门
搭建Spark环境
这里通过docker-compose搭建集群,如果没有的可以通过github下载。
docker compose github:https://github.com/docker/compose
- 查看本地是否有docker-compose
docker-compose version

2. 创建spark集群挂载目录
# 创建主目录
mkdir -p /Users/ziyi/docker-home/spark-cluster# 创建数据目录
mkdir -p /Users/ziyi/docker-home/spark-cluster/data# 创建 Spark Ivy 缓存目录
mkdir -p /Users/ziyi/docker-home/spark-cluster/spark-ivy# 设置权限
chmod -R 777 /Users/ziyi/docker-home/spark-cluster/
- 进入目录,创建docker-compose.yml文件
cd /Users/ziyi/docker-home/spark-cluster/
vi docker-compose.yml
docker-compose.yml:
networks:spark-net:driver: bridgeipam:config:- subnet: 172.30.0.0/16 # 这里子网需要是docker本地没有被使用过的。可通过docker network ls + docker network inspect <network-id>查看services:# ================= Spark 集群配置 =================spark-master:image: bitnami/spark:3.5platform: linux/amd64container_name: spark-masterhostname: spark-masternetworks:spark-net:environment:- SPARK_MODE=master- SPARK_MASTER_HOST=spark-master- SPARK_MASTER_PORT=7077- SPARK_MASTER_WEBUI_PORT=8080- SPARK_USER=sparkvolumes:- /Users/ziyi/docker-home/spark-cluster/data:/tmp/data- /Users/ziyi/docker-home/spark-cluster/spark-ivy:/home/spark/.ivy2ports:- "8080:8080"- "7077:7077"- "6066:6066"spark-worker1:image: bitnami/spark:3.5platform: linux/amd64container_name: spark-worker1hostname: spark-worker1networks:spark-net:environment:- SPARK_MODE=worker- SPARK_WORKER_CORES=1- SPARK_WORKER_MEMORY=1g- SPARK_MASTER_URL=spark://spark-master:7077- SPARK_WORKER_PORT=8881- SPARK_WORKER_WEBUI_PORT=8081- SPARK_USER=sparkdepends_on:- spark-mastervolumes:- /Users/ziyi/docker-home/spark-cluster/data:/tmp/data- /Users/ziyi/docker-home/spark-cluster/spark-ivy:/home/spark/.ivy2ports:- "8081:8081"spark-worker2:image: bitnami/spark:3.5platform: linux/amd64container_name: spark-worker2hostname: spark-worker2networks:spark-net:environment:- SPARK_MODE=worker- SPARK_WORKER_CORES=1- SPARK_WORKER_MEMORY=1g- SPARK_MASTER_URL=spark://spark-master:7077- SPARK_WORKER_PORT=8882- SPARK_WORKER_WEBUI_PORT=8082- SPARK_USER=sparkdepends_on:- spark-mastervolumes:- /Users/ziyi/docker-home/spark-cluster/data:/tmp/data- /Users/ziyi/docker-home/spark-cluster/spark-ivy:/home/spark/.ivy2ports:- "8082:8082"spark-worker3:image: bitnami/spark:3.5platform: linux/amd64container_name: spark-worker3hostname: spark-worker3networks:spark-net:environment:- SPARK_MODE=worker- SPARK_WORKER_CORES=1- SPARK_WORKER_MEMORY=1g- SPARK_MASTER_URL=spark://spark-master:7077- SPARK_WORKER_PORT=8883- SPARK_WORKER_WEBUI_PORT=8083- SPARK_USER=sparkdepends_on:- spark-mastervolumes:- /Users/ziyi/docker-home/spark-cluster/data:/tmp/data- /Users/ziyi/docker-home/spark-cluster/spark-ivy:/home/spark/.ivy2ports:- "8083:8083"
- 启动集群
# 后台拉取镜像并启动集群
docker-compose up -d
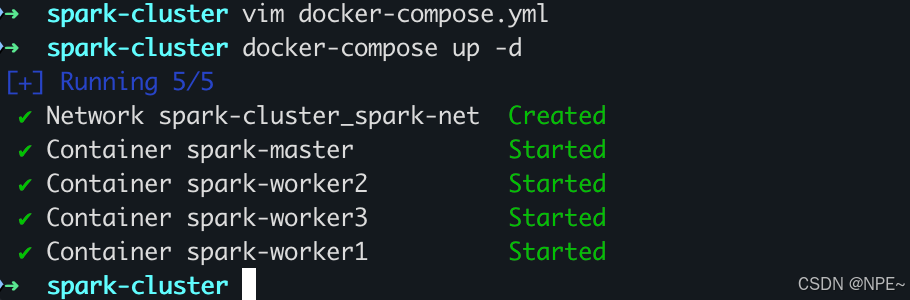
5. 查看集群状态
docker-compose ps -a

可以看到所有容器状态都为Up,接下来可以访问UI页面:
- Spark Master UI页面: http://localhost:8080
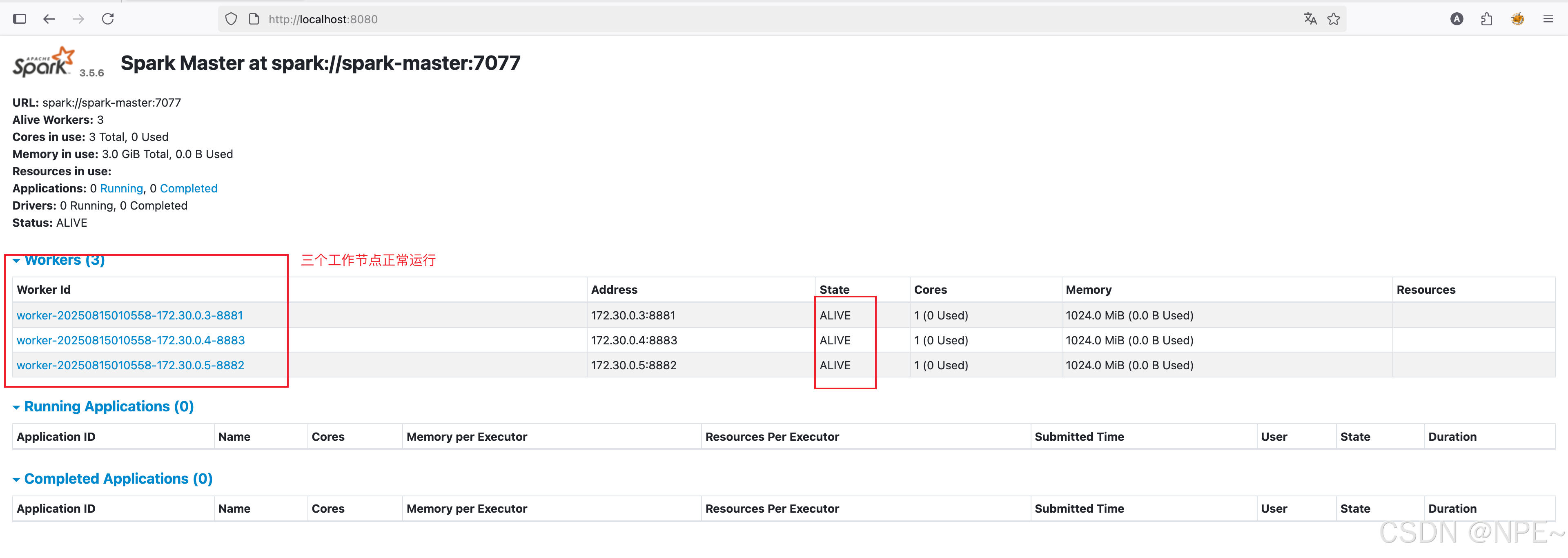
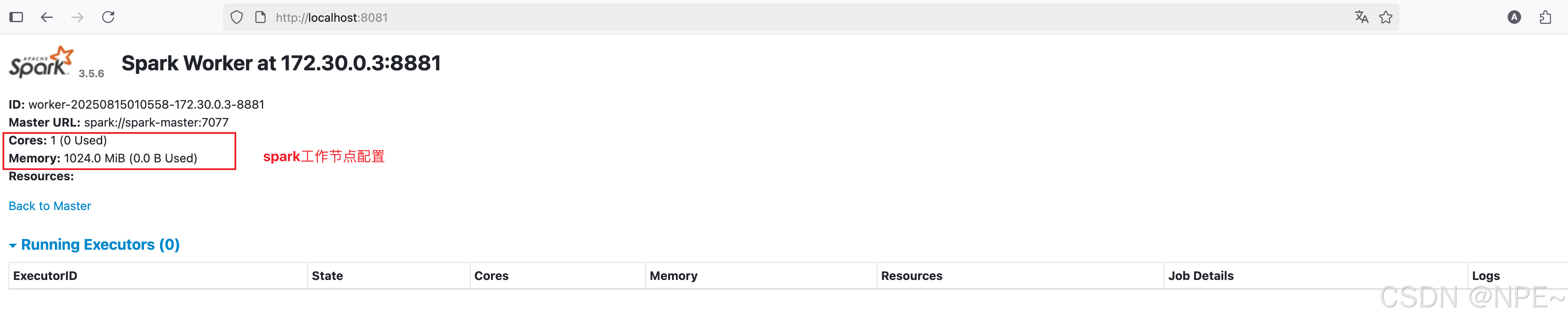
- Spark 工作节点UI页面:
- Worker 1 Web UI: http://localhost:8081
- Worker 2 Web UI: http://localhost:8082
- Worker 3 Web UI: http://localhost:8083
Spark功能测试
方式一:使用spark-submit测试jar包
# 以 root 用户身份进入容器
docker exec -it -u root spark-master /bin/bash# 执行命令,提交运行spark测试任务
/opt/bitnami/spark/bin/spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://spark-master:7077 \--deploy-mode client \/opt/bitnami/spark/examples/jars/spark-examples*.jar 10
效果:
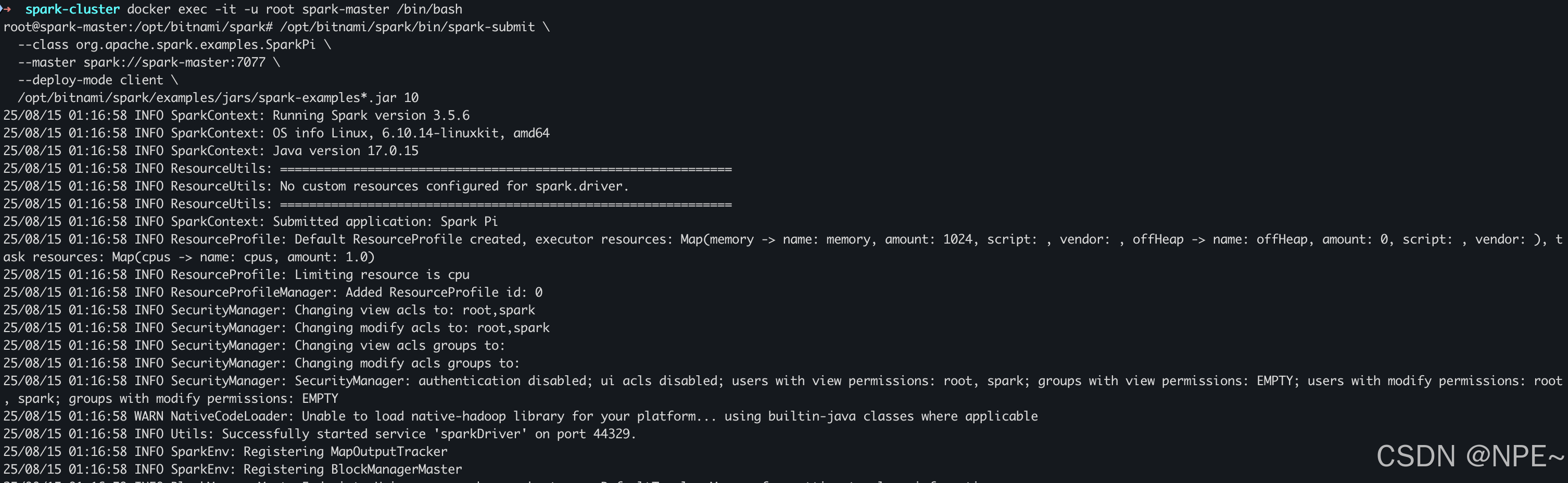
在Spark管理台上也可以看到作业运行状态:http://localhost:8080/
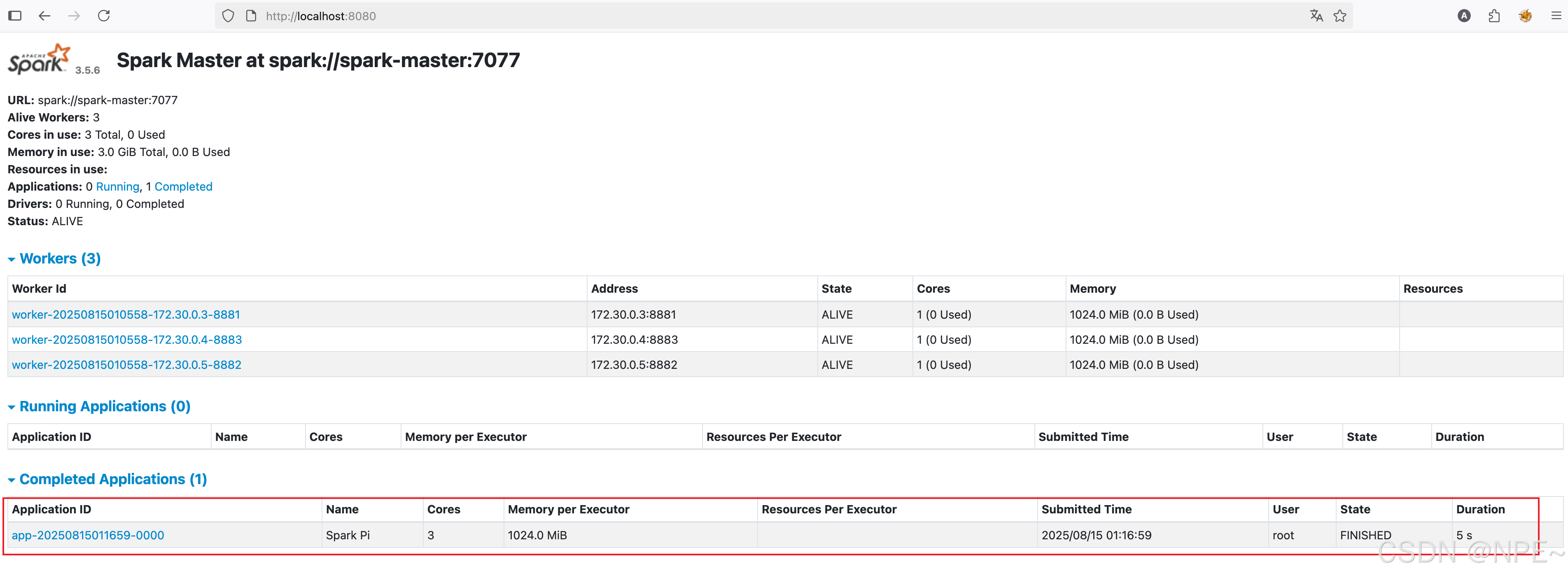
方式二:使用spark命令行验证
# 进入 spark-master 容器
docker exec -it -u root spark-master /bin/bash# 启动 Spark Shell
/opt/bitnami/spark/bin/spark-shell --master spark://spark-master:7077# 通过spark代码测试
scala> val rdd = spark.sparkContext.parallelize(1 to 1000)
scala> println(s"Count: ${rdd.count()}")
scala> val sum = rdd.reduce(_ + _)
scala> println(s"Sum: $sum")
scala> :quit
效果:
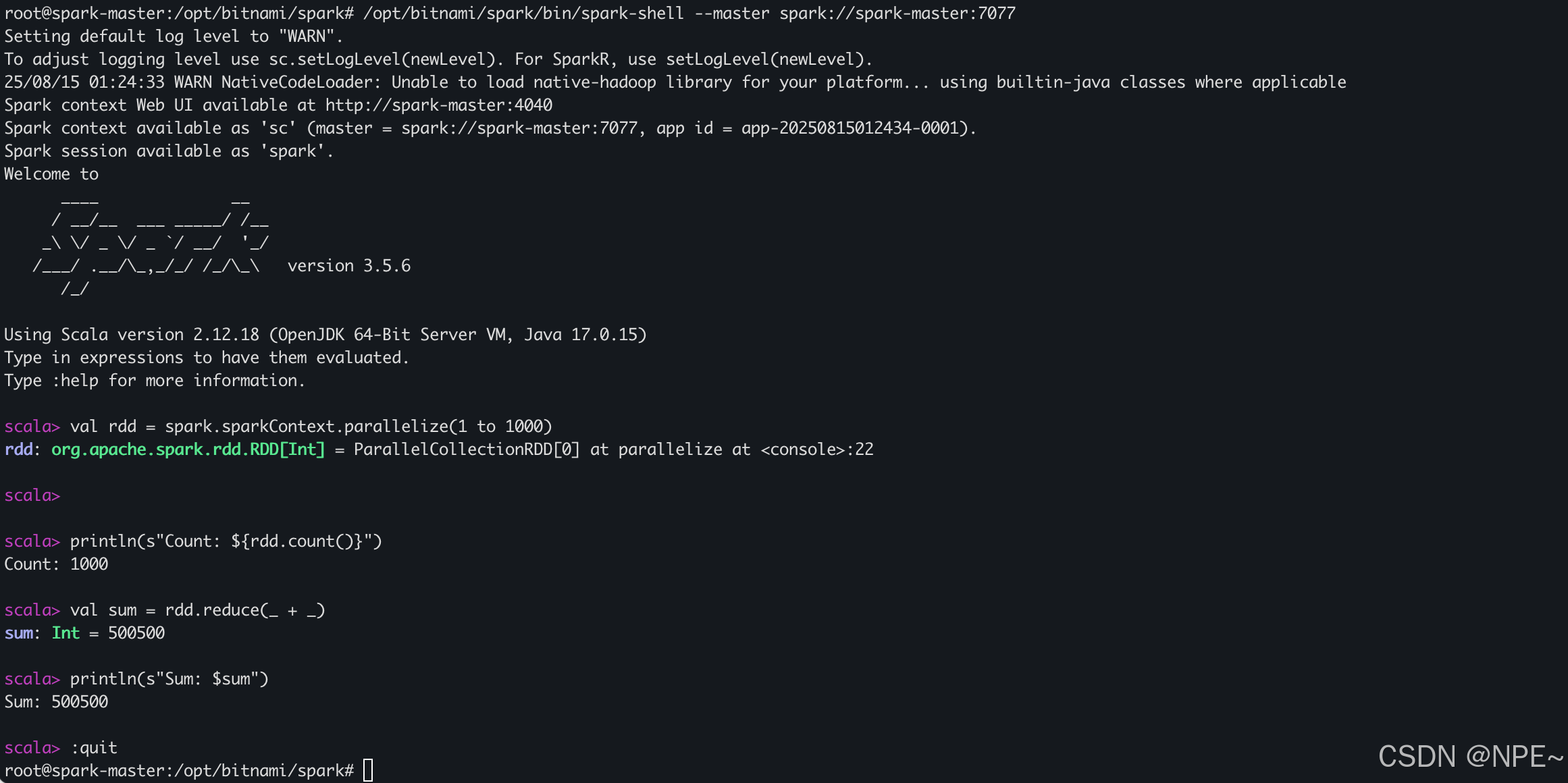
Spark Scala 案例:电商数据分析
官方API:https://spark.apache.org/docs/3.5.3/api/scala/org/apache/spark/index.html
- 案例文件创建
# 在主机上创建测试文件创建销售数据文件,因为我们集群搭建时将本地目录挂载到了容器内部的/tmp/data
# 所以容器/tmp/data/目录下可直接访问sales.csv文件
cat > /Users/ziyi/docker-home/spark-cluster/data/sales.csv << 'EOF'
id,product,category,price,quantity,date
1,ProductA,Electronics,100.0,2,2024-01-15
2,ProductB,Clothing,50.0,3,2024-01-16
3,ProductC,Electronics,200.0,1,2024-01-17
4,ProductD,Books,30.0,5,2024-01-18
5,ProductE,Clothing,80.0,2,2024-01-19
6,ProductF,Electronics,150.0,1,2024-01-20
7,ProductG,Books,25.0,4,2024-01-21
8,ProductH,Clothing,60.0,2,2024-01-22
EOF
- 进入容器,启动spark-shell
## 进入容器
docker exec -it -u root spark-master /bin/bash
## 进入spark-shell
/opt/bitnami/spark/bin/spark-shell --master spark://spark-master:7077
- 编写Scala语言,加载并分析数据
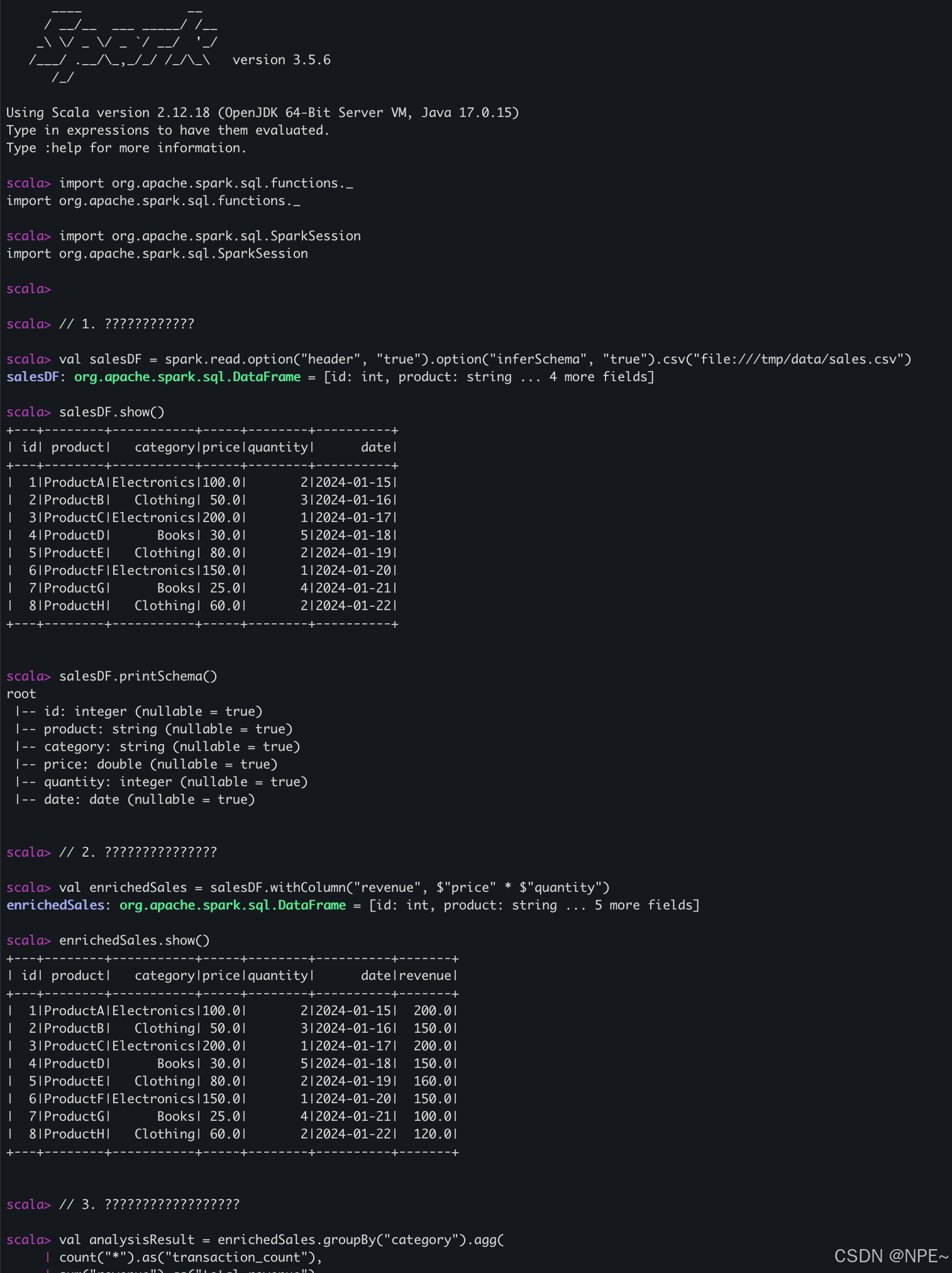
案例:电商销售数据分析。读取本地文件并分析
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession// 1. 读取数据
// 通过file协议读取本地CSV 文件 (后续有hdfs可直接通过hdfs://读取hdfs数据分析)
val salesDF = spark.read.option("header", "true").option("inferSchema", "true").csv("file:///tmp/data/sales.csv")
salesDF.show()
salesDF.printSchema()
// 2. 添加计算列
val enrichedSales = salesDF.withColumn("revenue", $"price" * $"quantity")
enrichedSales.show()
// 3. 执行聚合分析
val analysisResult = enrichedSales.groupBy("category").agg(
count("*").as("transaction_count"),
sum("revenue").as("total_revenue"),
avg("revenue").as("avg_revenue"))// 4. 排序并显示最终结果
analysisResult.orderBy(desc("total_revenue")).show()
运行效果:
参考文章:
https://blog.csdn.net/lovechendongxing/article/details/81746988
https://spark.apache.org/streaming/