机器学习4
八、指标
指标:就是用来验证模型性能的一些内容,比如准确率、召回率等,我们就可以通过这些指标直观的了解模型的一个性能情况
估计器:我们使用sklearn库中的一个模型类等创建出来的对象,就叫估计器,可以近似的把估计器理解为就是模型【当我们使用模型类创建出来估计器之后,使用估计器去拟合数据(把训练集通过fit方法,训练)的结果,就可以看作是一个模型】
sklearn 库中的方法(模型)类型比较多,那么对应的操作也是根据不同类型的模型(分类模型、回归模型)也有不同
两个方法:都是用来预测数据的方法
predict:可以用于分类、回归模型,返回预测的结果,比如分类模型就是一个标签
predict_proba:用于分类模型,返回预测的结果的一个概率值,也就是模型去对于这个输入的预测数据,判定为各个类别的一个概率值【小数】
score 方法:每一个估计器都有这一个方法,可以返回模型的性能指标
分类模型:准确率
回归模型:决定系数
score 方法的参数:x_test、y_test ---- 默认内部调用了 predict 方法,然后用预测的结果和 y_test 真是标签作比较
accuracy_score 方法:他也是返回一个准确率,需要单独导入
参数:
y_true:测试集的真实标签
y_pred:测试集的预测标签
混淆矩阵
| 真实类别 | 预测概率 |
|---|---|
| 猫 | 0.6 猫 |
| 狗 | 0.7 猫 |
| 猫 | 0.2 猫 |
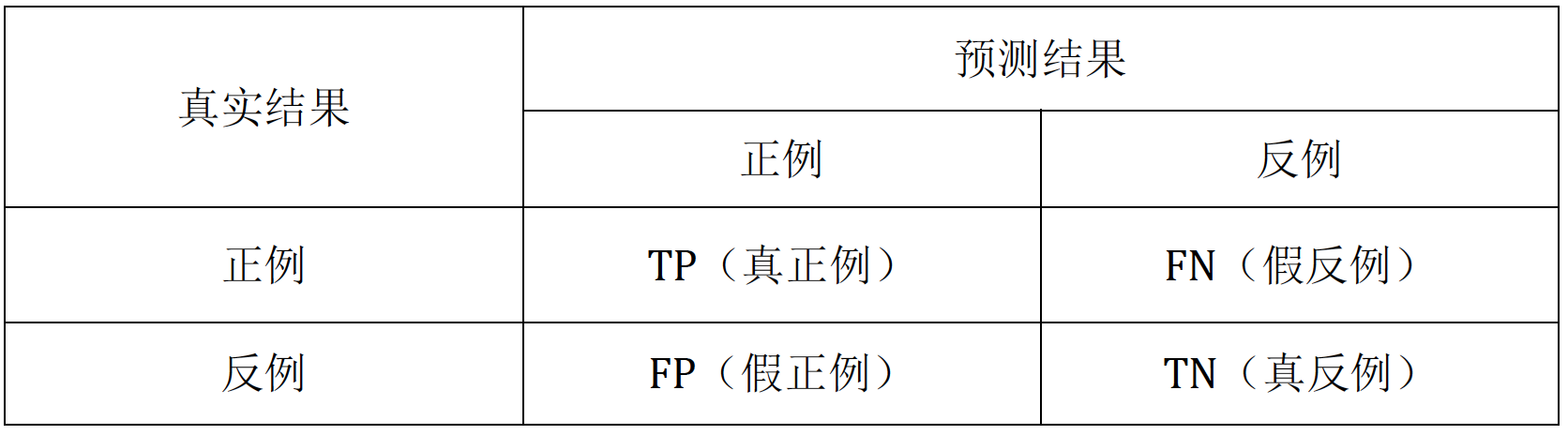
True、False、Positive、Negative
TP:实际是正例,预测结果也是正例,即真正例【重点】
FP:实际为负例,预测结果为正例,即假正例【重点】
FN:实际为正例,预测结果为负例,即假负例【重点】
TN:实际为负例,预测结果为负例,即真负例
准确率:预测正确【TP+TN】的除以总共的数量【TP+TN+FP+FN】
精确度:TP/(TP+FP) ---- 描述了预测正确的结果占有所有预测为正例的比例【查准率】
召回率:TP/(TP+FN) ---- 描述了正类样本是否被找到的一个比例【查全率】
由于我们都想让精确度和召回率都越大越好,那么通过手动的方式设置阈值等操作,无法去平衡P和R,所以就出现了一个指标叫做 F1 分数,用来平衡两个指标
ROC、AUC 两者的由来和作用:
ROC:在阈值取值不同的情况下,计算出来TPR和FPR的值,然后以FPR为横坐标,TPR为纵坐标绘制出来的图像
AUC:roc曲线和坐标轴(横)围起来的面积
总结:
score 方法、accuracy_score 方法
predict、predict_proba
混淆矩阵:TP、FN、FP、TN【重要】
假设有一个数据的结果概率值为 0.6,设置的阈值为 0.5【大于阈值就处理为正,小于就处理为负】,那么这个结果应该规划为混淆矩阵中的哪一类?
由于预测的概率值大于阈值,那么就要考虑真实的标签是什么
如果预测结果的概率值大于了阈值,就会被当作一个正类样本处理,我们计算的结果经过阈值处理之后才是最终的结果,并不是说预测的结果为正就一定为正,为负就一定为负
真实为正 ---- TP
真实为负 ---- FP
ROC、AUC【了解】
混淆矩阵是如何计算出来多个 TP、TN、FN、FP 值的,就是基于设置的阈值,如果大于阈值就当作正类样本处理,小于阈值就当作负类样本处理
混淆矩阵:
sklearn中计算出混淆矩阵的函数
函数介绍
| 项目 | 内容 |
|---|---|
| 函数名 | confusion_matrix |
| 所属模块 | sklearn.metrics |
| 功能说明 | 计算分类模型的混淆矩阵,用于评估分类性能。矩阵中的每个元素表示预测类别与实际类别的样本数量。 |
| 调用格式 | confusion_matrix(y_true, y_pred, *, labels=None, sample_weight=None, normalize=None) |
参数说明
| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
y_true | array-like of shape (n_samples,) | — | 真实标签(ground truth) |
y_pred | array-like of shape (n_samples,) | — | 模型预测的标签(predicted labels) |
labels | array-like, optional | None | 标签列表,用于定义矩阵中类别的顺序;若为 None,则自动按出现顺序排列 |
sample_weight | array-like of shape (n_samples,), optional | None | 样本权重,可用于加权计算混淆矩阵 |
normalize | {'true', 'pred', 'all'}, optional | None | 是否对矩阵进行归一化: - 'true': 每行归一化 - 'pred': 每列归一化 - 'all': 整体归一化 |
返回值:
| 返回值 | 类型 | 描述 |
|---|---|---|
| 混淆矩阵 | ndarray of shape (n_classes, n_classes) | 返回一个二维数组,其中第 i 行 j 列的值表示真实为类别 i,预测为类别 j 的样本数 |
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix
iris = load_iris()
data, target = iris.data, iris.target
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(data, target, shuffle=True, test_size=0.2, random_state=42)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# 预测
y_pred = knn.predict(X_test)
# 输出混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print(cm)ROC和AUC:
| 函数名 | 所属模块 | 描述 | 输入参数 | 输出内容 |
|---|---|---|---|---|
roc_curve | sklearn.metrics | 计算 ROC 曲线所需的假正类率(FPR)和真正类率(TPR)以及对应的阈值 | - 真实标签 y_true - 预测正类概率 y_score | - FPR 数组 - TPR 数组 - 阈值数组 |
predict_proba | sklearn.model_selection 或各类分类器模型本身(如 LogisticRegression, RandomForestClassifier 等) | 返回每个样本属于各个类别的预测概率 | 样本数据 X | 形状为 (n_samples, n_classes) 的概率数组 |
auc | sklearn.metrics | 根据 FPR 和 TPR 计算 ROC 曲线下面积(AUC),用于评估分类器整体性能 | - FPR 数组 - TPR 数组 | AUC 值(浮点数),表示分类器判别能力 |
"""roc:在阈值取值不同的情况下,计算出来TPR和FPR的值,然后以FPR为横坐标,TPR为纵坐标绘制出来的图像auc:roc曲线和坐标轴(横)围起来的面积api:from sklearn.metrics import roc_curve, auc
"""
import numpy as np
from sklearn.metrics import roc_curve, auc
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
cancer = load_breast_cancer()
data, target = cancer.data, cancer.target
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(data, target, shuffle=True, test_size=0.2, random_state=42)
# 创建估计器
lr = LogisticRegression(max_iter=10000)
# 拟合数据 --- 类似于训练
lr.fit(X_train, y_train)
# 预测
"""predict:返回预测结果的标签predict_proba:返回预测结果的各个标签的概率值
"""
np.set_printoptions(suppress=True) # 关闭科学计数法
y_pred = lr.predict_proba(X_test)[:, 1]
print(y_pred)
# 计算 roc
"""thresholds:阈值的结果就从y_pred中筛选出来的,他筛选了能够引起结果变化的值作为阈值但是第一个值不是从阈值中来的:是 max(y_pred) + 1
"""
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
print(thresholds)
# 计算 auc
auc_value = auc(fpr, tpr)
print(auc_value)九、KNN算法
KNN:K 近邻算法
原理:根据距离来判定输入的样本属于哪一个类别,我们首选确定需要计算输入样本其他已知样本的距离,选择距离最近的 k 个样本,然后统计 k 个样本中类别的信息
第一种情况,k 个样本都是不一样的类别,那么新样本就类似于随机选择一个类别
第二种情况,k 个样本中有一个类别的统计数量大于其他样本,那么新的样本就属于这个类别
少数服从多数
重点:
首选计算新样本和每一个已知样本的距离
设置 k 值,筛选 k 个最近的样本最为参照
通过筛选的 k 个样本中的类别信息
最后把新样本划分为通过的 k 个已知样本中最多的一个类别
两个距离公式:假设 a(x,y) b(x1,y1),d = ?
欧氏距离:
曼哈顿距离:城市街区距离,
| 方法 | 模块 | 参数 | 说明 |
|---|---|---|---|
| KNeighborsClassifier | sklearn.neighbors | n_neighbors: 指定 k 值的大小,默认值 5 weights: 预测时权重方式,默认 'uniform'(等权重),可选 'distance'(距离倒数为权重) algorithm: 计算最近邻的算法,如 'ball_tree', 'kd_tree', 'brute' 等 p: 距离度量的幂参数,默认 2(欧氏距离) | 使用 KNN 算法解决分类问题,适用于多分类与样本较均衡的场景,需注意调参以提升性能 |
"""流程:- 首选计算新样本和每一个已知样本的距离- 设置 k 值,筛选 k 个最近的样本最为参照- 通过筛选的 k 个样本中的类别信息- 最后把新样本划分为通过的 k 个已知样本中最多的一个类API:from sklearn.neighbors import KNeighborsClassifier超参数:n_neighbors=5 --- 设置 k 值,即以多少个最近距离的已知样本作为参照物
"""
import numpy as np
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
# 加载数据集
wine = load_wine()
# 数据集、标签
data, target = wine.data, wine.target
np.set_printoptions(suppress=True)
print(data[: 5])
print(wine.feature_names)
# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(data, target, test_size=0.2, random_state=42)
# 创建估计器 --- knn --- 设置 k 值等于 5
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train) # 投喂数据、拟合数据、训练模型
# 模型得分 score 方法
score = knn.score(X_test, y_test)
print("score:", score)
# 模型得分 accuracy_score 方法
y_pred = knn.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print("acc:", acc)
# 混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print(cm)
# 分类报告
cr = classification_report(y_test, y_pred)
print(cr)
# 随机设置一个数据,用来预测 --- 二维数据,一条数据,13 个特征值
my_data = np.array([[15, 1.5, 3.0, 18, 115, 2, 3, 0.20, 3, 6, 1.5, 4, 1001]])
# 预测
result = knn.predict(my_data)
print(result)
print(wine.target_names[result])
print(knn.predict_proba(my_data))