Jenkins全链路教程——并行任务与超时控制

在Jenkins流水线(Pipeline)中,“效率”与“稳定性” 是两大核心诉求。当面对“多模块独立构建”“跨环境并行测试”等场景时,并行任务能大幅缩短整体耗时;而对于“可能卡住的脚本”“资源密集型操作”,超时控制则是防止流水线无限期阻塞的“安全网”。今天我们就来拆解这两个实用技巧。
一、并行与超时的“底层逻辑”
1.1 并行任务(Parallel):让流水线“多线程”运行
核心定义:通过parallel关键字,让多个独立的阶段(Stage)或步骤(Steps)同时执行,而非按顺序等待。
适用场景:
• 多模块项目构建(如前端、后端、移动端可并行构建);
• 跨环境测试(如测试环境A、测试环境B同时执行用例);
• 资源隔离的独立任务(如同时生成文档和打包镜像)。
优势:
• 缩短总耗时:假设3个任务各需10分钟,串行需30分钟,并行仅需10分钟;
• 资源利用率最大化:充分利用Jenkins节点的CPU/内存资源。
1.2 超时控制(Timeout):给任务“设置安全边界”
核心定义:通过timeout指令,为指定任务设置最大运行时长,超时后自动终止并标记失败。
适用场景:
• 第三方接口调用(防止接口无响应导致阻塞);
• 复杂脚本执行(如数据同步、大文件传输可能超时);
• 不稳定的测试用例(避免单个用例拖垮整个流水线)。
关键参数:
•
time:超时时间数值(如5);•
unit:时间单位(支持SECONDS秒、MINUTES分钟、HOURS小时,默认MINUTES)。
二、实践:从基础并行到超时防护
🌰 场景1:多模块并行构建(声明式Pipeline)
假设我们有一个全栈项目,包含前端(Web) 和后端(API) 两个独立模块,可并行构建以节省时间。
示例代码(可直接复制到Jenkins运行):
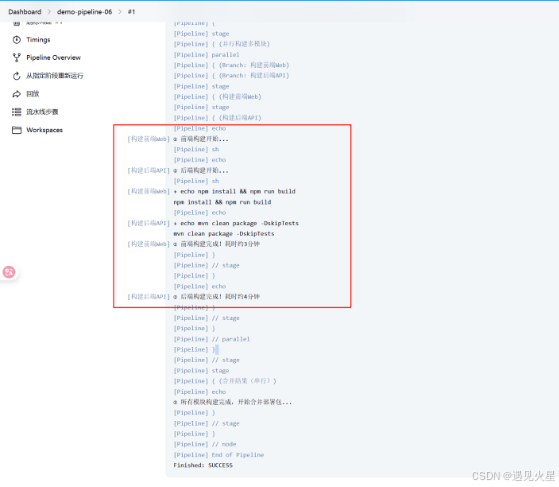
pipeline {agent anystages {stage('并行构建多模块') {parallel { // 并行块:内部阶段同时执行stage('构建前端Web') {steps {echo "① 前端构建开始..."//sh 'echo "npm install && npm run build" # 模拟前端构建'// 模拟真实构建耗时(原3分钟 -> 简化为10秒)sleep(time:10, unit:'SECONDS') echo "① 前端构建完成!耗时约3分钟"}}stage('构建后端API') {steps {echo "② 后端构建开始..."//sh 'echo "mvn clean package -DskipTests" # 模拟后端构建'// 模拟真实构建耗时(原4分钟 -> 简化为15秒)sleep(time:15, unit:'SECONDS') echo "② 后端构建完成!耗时约4分钟"}}}}stage('合并结果(串行)') { // 并行任务后需串行执行的步骤steps {echo "③ 所有模块构建完成,开始合并部署包..."}}}
}关键说明:
•
parallel块内的stage会同时启动,日志中会标记[前端构建][后端构建]区分输出;• 并行任务的总耗时≈耗时最长的单个任务(而非总和),上述示例总耗时≈4分钟(后端耗时较长);
• 并行任务中的任一阶段失败,整个
parallel块会终止,未完成的任务会被取消。
 🌰 场景2:为并行任务添加超时控制
🌰 场景2:为并行任务添加超时控制
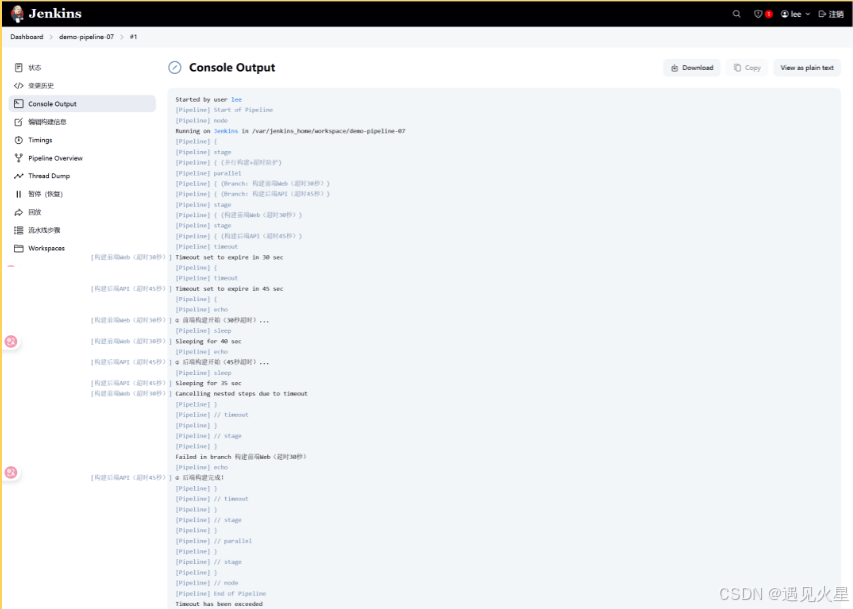
如果并行任务中某个模块可能“卡住”(如后端依赖的Maven仓库响应慢),可给单个并行阶段添加超时控制,避免影响整体流程。
示例代码:
pipeline {agent anystages {stage('并行构建+超时防护') {parallel {stage('构建前端Web(超时30秒)') {options {timeout(time:30, unit:'SECONDS') // 改为30秒超时,便于测试}steps {echo "① 前端构建开始(30秒超时)..."// 模拟一个耗时40秒的任务(将超时)sleep(time:40, unit:'SECONDS') echo "前端构建成功!"// 如果超时,这行不会执行}}stage('构建后端API(超时45秒)') {options {timeout(time:45, unit:'SECONDS') // 改为45秒超时}steps {echo "② 后端构建开始(45秒超时)..."// 模拟一个耗时35秒的任务(不会超时)sleep(time:35, unit:'SECONDS') echo "② 后端构建完成!"}}}}}
}
 🌰 场景3:步骤级超时与并行任务的组合
🌰 场景3:步骤级超时与并行任务的组合
除了阶段级超时,还可在steps内为单个命令设置超时(更细粒度控制)。以下示例模拟“并行执行3个测试用例,每个用例最多运行2分钟”。
示例代码:
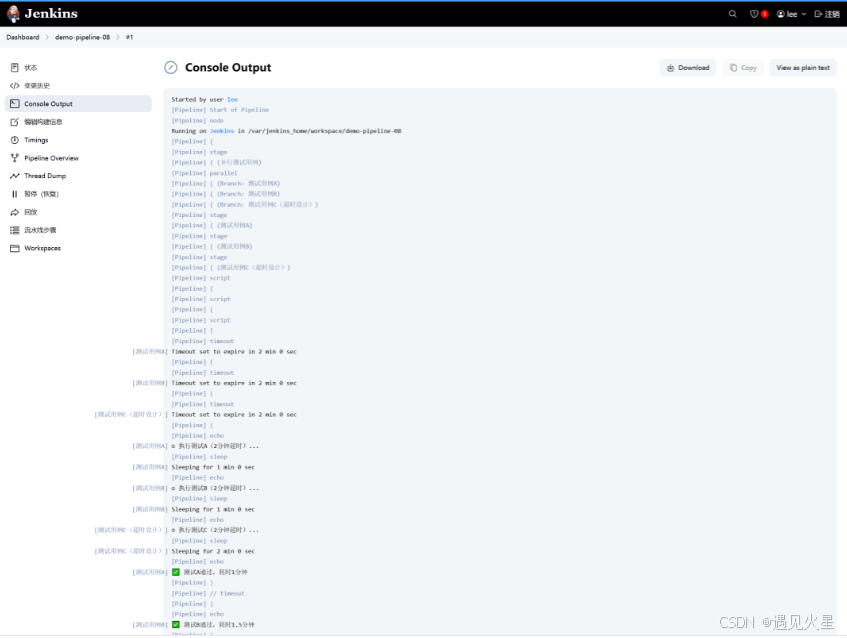
pipeline {agent anystages {stage('并行测试用例') {parallel {stage('测试用例A') {steps {script {timeout(time:2, unit:'MINUTES') {echo "① 执行测试A(2分钟超时)..."// 模拟1分钟测试sleep(time:1, unit:'MINUTES') echo "✅ 测试A通过,耗时1分钟"}}}}stage('测试用例B') {steps {script {timeout(time:2, unit:'MINUTES') {echo "② 执行测试B(2分钟超时)..."// 模拟1.5分钟测试sleep(time:1.5, unit:'MINUTES') echo "✅ 测试B通过,耗时1.5分钟"}}}}stage('测试用例C(超时设计)') {steps {script {timeout(time:2, unit:'MINUTES') {echo "③ 执行测试C(2分钟超时)..."// 故意超时:2.5分钟 > 2分钟限制sleep(time:2.5, unit:'MINUTES') echo "❌ 这行永远不会执行(已超时中断)"}}}}}}}post {failure {echo "⚠️ 流水线失败:可能有任务超时或执行错误"}success {echo "🎉 所有测试用例通过!"}}
}关键说明:
• 测试用例C因耗时2.5分钟超过2分钟超时设置,会被Jenkins自动终止,日志中显示
Timeout has been exceeded;• 单个并行任务超时失败后,其他已完成的任务不受影响,但整个
parallel块会标记为失败,触发post阶段的failure操作。
三、避坑指南 ⚠️
1. 并行任务的资源限制:避免在单个Jenkins节点上并行过多任务(如10个以上),可能导致CPU/内存耗尽。建议通过
agent { label 'node1' }分配不同节点执行并行任务。2. 超时单位的隐蔽坑:
timeout默认单位是MINUTES(分钟),若需秒级控制需显式指定unit: 'SECONDS'(如timeout(time: 30, unit: 'SECONDS'))。3. 并行任务的日志可读性:并行输出的日志会交织显示,建议在
echo中添加阶段标识(如[前端][后端]),便于定位问题。4. 不可并行的场景:若任务间有依赖(如“必须先构建后端才能测试前端”),禁止并行!强行并行会导致资源竞争或数据不一致。
通过parallel实现并行提速,通过timeout保障流程稳定,两者结合能让你的流水线效率与可靠性“双在线”~