板卡如何安装在主机系统(刀片服务器或计算节点)
✅ 板卡(如 GPU、FPGA)本身没有操作系统
- 它们是硬件加速器,不具备独立运行操作系统的能力。
- 它们需要依附于**主机系统(通常是刀片服务器或计算节点)**来运行。
- 操作系统(如 Linux)安装在主机上,主机通过驱动程序和运行时环境(如 CUDA、OpenCL)来调用这些加速卡。
🔗 这些卡如何与刀片服务器连接?
1. 本地直连(最常见)
- GPU 或 FPGA 卡直接插在刀片服务器或计算节点的 PCIe 插槽 上。
- 这种方式延迟低、带宽高,是超算中最常见的连接方式。
2. 外部扩展(GPU Box / JBOG)
- 如果刀片服务器本身空间不足,可以通过 PCIe 扩展线缆 或 NVLink 连接外部 GPU 机箱(如 NVIDIA HGX、Supermicro GPU Box)。
- 这些扩展箱通过高速互联(如 PCIe Gen4/Gen5、CXL、NVLink)与主机通信。
3. 网络连接(较少见)
- 某些 FPGA 卡或智能网卡(如 SmartNIC)可以通过 以太网或 InfiniBand 与主机通信,适用于分布式计算或网络加速场景。
🧠 使用流程简化如下:
[GPU/FPGA 卡] ←PCIe/NVLink→ [刀片服务器] ←驱动/软件→ [操作系统]- 用户编写的程序运行在操作系统上,调用驱动程序(如 NVIDIA 驱动)与加速卡通信。
- 加速卡执行计算任务并将结果返回主机。
🖼️ 简化结构图描述

这个结构图展示了:
- 刀片服务器作为主机,运行操作系统和驱动;
- 加速卡通过高速总线(如 PCIe 或 NVLink)连接到主机;
- 主机再通过网络或存储接口与其他节点或系统通信。
🖥️ 主机与板卡的关系
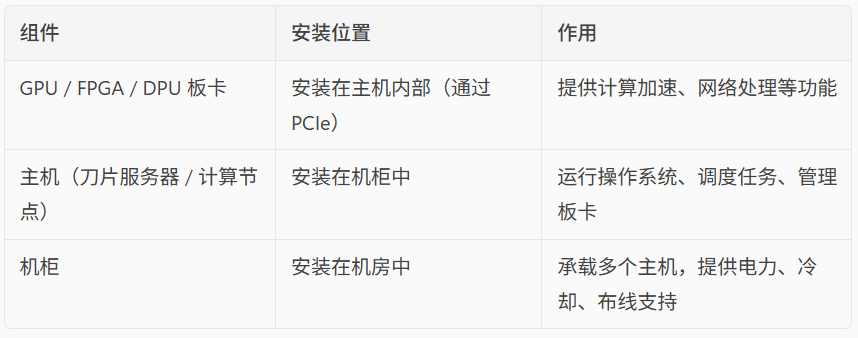
📌 举个例子
假设一个超算中心有一个机柜,里面安装了 10 台刀片服务器,每台服务器配有 4 张 NVIDIA A100 GPU 卡:
- GPU 卡是插在每台服务器的主板上;
- 服务器是安装在机柜的托架上;
- 机柜通过电源和冷却系统保障这些服务器稳定运行。