Java-88 深入浅出 MySQL InnoDB 存储结构全解析:表空间、段、区、页与行格式
点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-30-新发布【1T 万亿】参数量大模型!Kimi‑K2开源大模型解读与实践,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年07月28日更新到:
Java-83 深入浅出 MySQL 连接、线程、查询缓存与优化器详解
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

InnoDB数据文件
存储结构
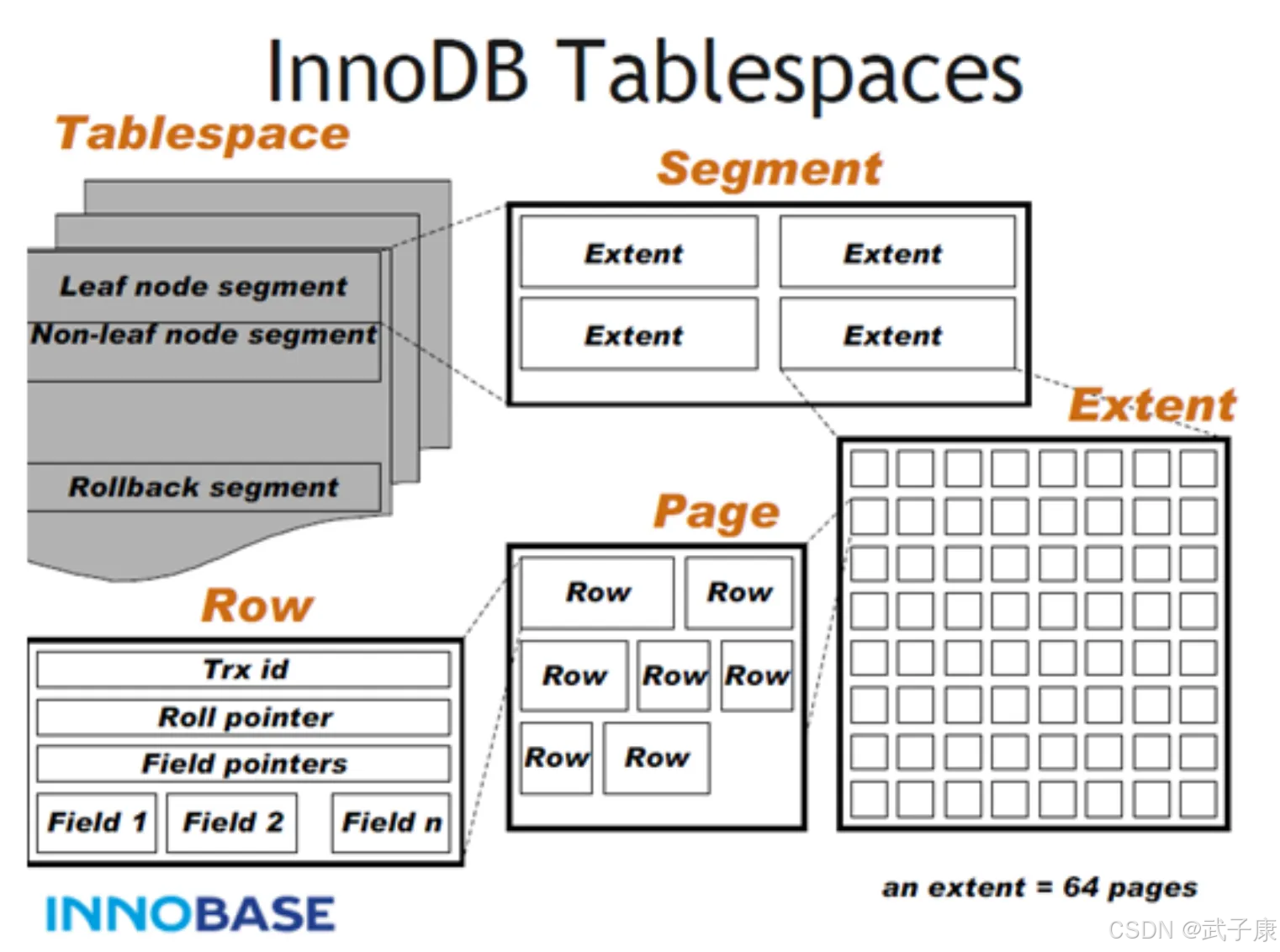
InnoDB 数据文件存储结构采用层级化管理方式,从大到小依次为:Tablespace(表空间)→ Segment(段)→ Extent(区)→ Page(页)→ Row(行)。这种层级结构设计兼顾了存储效率和管理便利性,下面详细介绍每个层级:
-
Tablespace(表空间)
- 功能:作为最高层级的存储单元,用于组织和管理多个.ibd数据文件
- 特点:
- 每个表通常对应一个独立的表空间文件(启用独立表空间时)
- 系统表空间(ibdata1)存储共享的系统信息
- 支持动态扩展,当空间不足时会自动增长
- 示例:用户表
user对应user.ibd文件,其中包含该表的所有数据和索引
-
Segment(段)
- 类型划分:
- 数据段(Leaf Node Segment):存储B+树的叶子节点数据
- 索引段(Non-leaf Node Segment):存储B+树的非叶子节点数据
- 回滚段(Rollback Segment):存储事务回滚所需信息
- 管理机制:
- 每个索引会创建2个段(数据段+索引段)
- 主键索引默认占用2个段
- 每新增一个二级索引就增加2个段
- 应用场景:当执行
ALTER TABLE ADD INDEX时,会立即分配新的段空间
- 类型划分:
-
Extent(区)
- 物理特性:
- 固定大小1MB(64个连续页×16KB/页)
- 采用预分配策略,减少碎片化
- 分配策略:
- 新建表时分配32个碎片页(Fragement Pages)和少量区
- 当碎片页用完时,改为按区分配
- 大表会直接分配多个完整的区
- 优势:批量分配减少I/O操作,提高空间管理效率
- 物理特性:
-
Page(页)
- 基本参数:
- 固定大小16KB(可通过参数调整)
- 是InnoDB磁盘管理的最小单位
- 主要类型:
- 数据页:存储实际行记录
- Undo页:存储事务回滚日志
- 系统页:存储数据字典等元信息
- 事务数据页:存储事务系统信息
- BLOB页:存储大对象数据
- 结构特点:
- 包含文件头、页头、行记录、页目录等组成部分
- 采用槽位(Slot)机制管理行记录
- 基本参数:
-
Row(行)
- 核心组成:
- 事务ID(Trx Id):记录最后修改该行的事务ID
- 回滚指针(Roll Pointer):指向Undo日志的指针
- 字段指针:指向各列数据的偏移量
- 实际列数据:包括用户定义的所有列值
- 存储格式:
- 支持COMPACT和DYNAMIC两种行格式
- 变长字段会额外存储长度信息
- NULL值有特殊的标记位处理
- 核心组成:
补充说明:
- 这种层级结构通过B+树索引组织数据,其中:
- 非叶子节点段存储索引导航信息
- 叶子节点段存储实际数据记录
- 空间分配采用"懒加载"策略,初始只分配必要空间,随数据增长逐步扩展
- 页内的行记录通过单向链表连接,同时页目录使用二分查找提高检索效率
Page 是文件最基本的单位,无论何种类型的 Page,都是由 Page Header,Page trailer 和 Page body 组成:
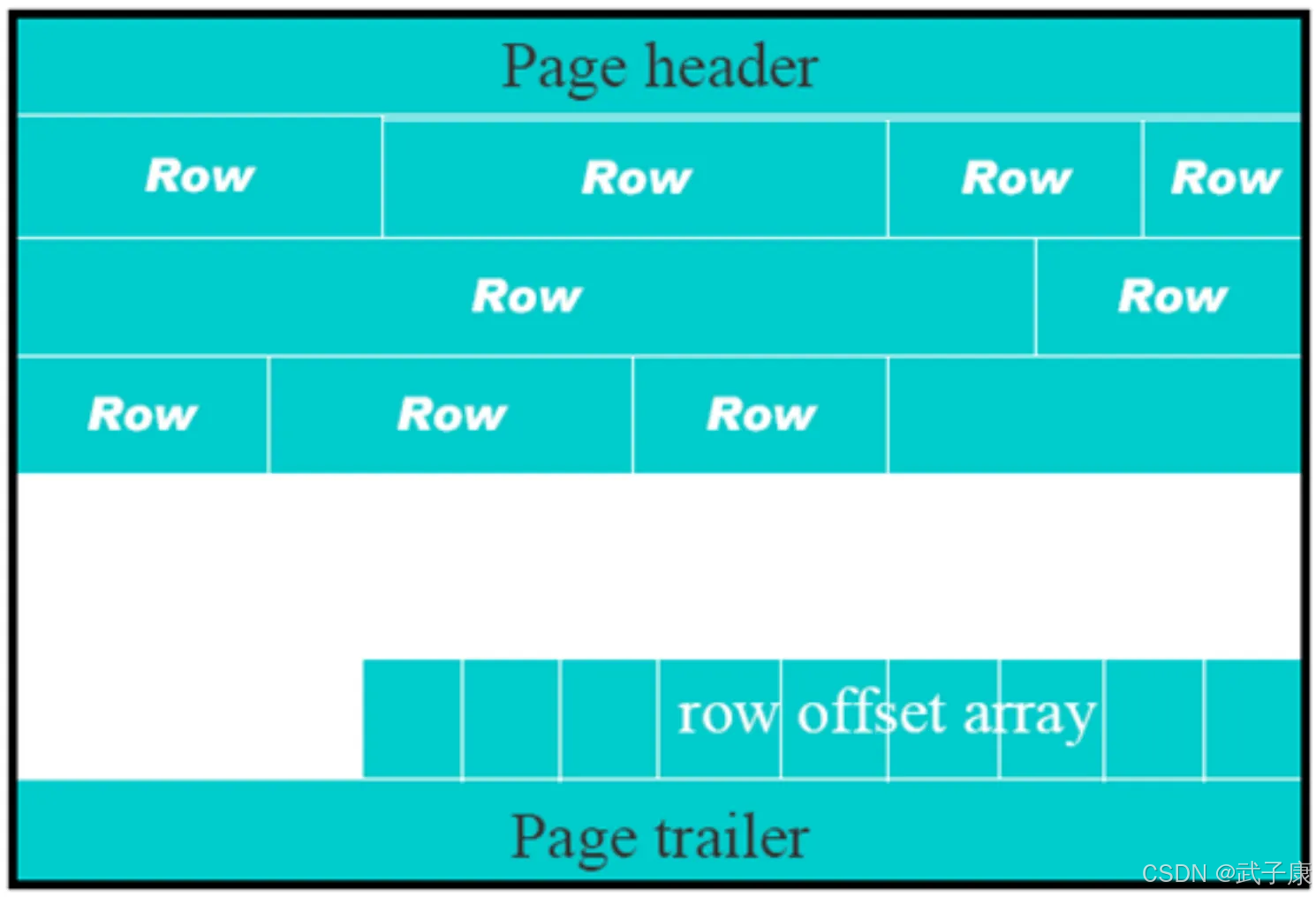
存储格式
SHOW TABLE STATUS
对应的内容如下所示:
MySQL 存储引擎 InnoDB 支持两种文件格式:Antelope 和 Barracuda,它们的主要区别在于对行存储格式的支持程度。
-
文件格式与行格式的关系:
- Antelope 文件格式:支持较旧的行格式
REDUNDANT:兼容性最好的行格式,但存储效率较低COMPACT:默认行格式,相比 REDUNDANT 节省约 20% 存储空间
- Barracuda 文件格式:支持更先进的行格式
DYNAMIC:针对可变长度列优化,适合包含 TEXT、BLOB 等大字段的表COMPRESSED:支持表和索引数据压缩,可节省存储空间
- Antelope 文件格式:支持较旧的行格式
-
查看文件格式的方法:
可以通过查询 information_schema 数据库中的系统表来获取表的文件格式信息:
-- 查看所有 InnoDB 表的文件格式
SELECT name, format FROM information_schema.innodb_sys_tables;-- 查看特定表的文件格式(示例查找 test 数据库中的表)
SELECT name, format
FROM information_schema.innodb_sys_tables
WHERE name LIKE 'test/%';
- 实际应用场景:
- 使用
COMPACT格式适合大多数常规表 - 当表中包含大量可变长度数据时,建议使用
DYNAMIC格式 - 对存储空间敏感的应用可以考虑
COMPRESSED格式 REDUNDANT格式主要用于向后兼容
- 使用
注意:要使用 Barracuda 文件格式,需要在 MySQL 配置文件中设置 innodb_file_format=Barracuda 并重启服务。
对应的内容如下所示:
文件格式
在数据库存储领域,文件格式的选择直接影响着数据存储效率、压缩性能和功能支持。下面详细介绍InnoDB的文件格式发展及其特性:
文件格式发展历程
早期版本的InnoDB只支持单一的文件格式,随着存储需求的复杂化和性能要求的提高,MySQL开发团队逐步引入了新的文件格式来满足不同场景的需求。目前InnoDB主要支持以下两种文件格式:
-
Antelope格式(原未命名的基础格式)
- 这是InnoDB最初采用的文件格式
- 支持两种行格式:
- COMPACT:紧凑型存储格式,优化了存储空间
- REDUNDANT:冗余格式,保留更多元数据信息
- 兼容性说明:
- MySQL 5.6及更早版本默认使用此格式
- 适用于简单的事务处理场景
- 示例应用:早期版本迁移过来的系统可能仍使用此格式
-
Barracuda格式(新增强格式)
- 引入时间:随着InnoDB引擎的重大更新而加入
- 支持所有行格式,包括:
- COMPRESSED:支持表压缩功能
- DYNAMIC:优化大字段(BLOB/TEXT)存储
- 优势特性:
- 支持更大的页大小(如16KB)
- 更好的BLOB处理能力
- 支持表压缩功能
配置与版本变化
- 配置参数:
innodb_file_format - 默认值变化:
- 5.6及之前版本:Antelope
- 从MySQL 5.7开始:Barracuda
- 设置方法示例:
SET GLOBAL innodb_file_format='Barracuda';
实际应用建议
- 新项目建议使用Barracuda格式以获得完整功能支持
- 迁移注意事项:
- 检查表兼容性
- 可能需要使用ALTER TABLE转换格式
- 性能影响评估:
- Barracuda格式可能需要更多内存
- 但能提供更好的大字段处理能力
行格式
Row format
表的行格式决定了它的行是如何物理存储的,这反过来又会影响查询和DML操作的性能。如果在单个Page页中容纳更多行,查询和索引可以更快地工作,缓冲池汇总需要的内存更少,写入更新时所需要的 IO更少。
InnoDB 存储引擎支持四行格式:REDUNDANT、COMPACT、DYNAMIC、COMPRESSED。
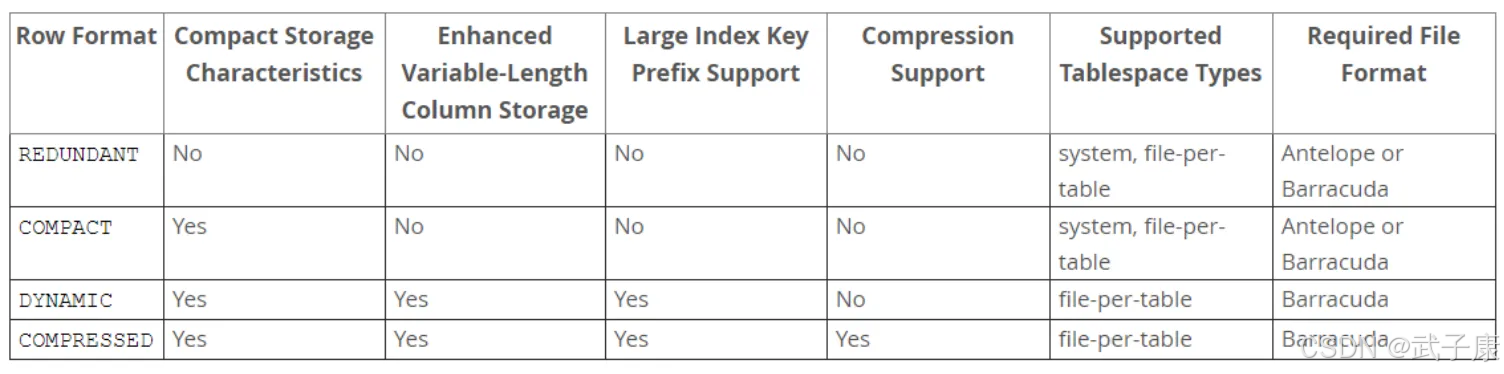
InnoDB存储引擎提供了四种行格式(ROW_FORMAT)选项,其中DYNAMIC和COMPRESSED是较新的格式,引入了一系列优化功能:
- 数据存储机制
每个表的数据被划分为固定大小的页(默认为16KB),采用B+树结构组织数据。当字段数据过大时会出现以下情况:
- 普通存储:数据直接存储在B+树节点中
- 溢出存储:当数据超过节点容量时,会分配额外的溢出页(off-page),这类字段被称为页外列
- 各格式详细对比
● REDUNDANT(冗余格式):
- 存储方式:变长列值的前768字节存储在B+树节点中,剩余部分存储在溢出页
- 特殊处理:对于>=768字节的固定长度字段(如CHAR(255))会自动转换为变长字段
- 示例场景:适合历史遗留系统或需要向后兼容的情况
● COMPACT(紧凑格式):
- 空间优化:相比REDUNDANT节省约20%存储空间
- 性能特点:
- 优势:在I/O密集型场景(缓存命中率低/磁盘速度受限)下表现更好
- 劣势:在CPU密集型场景下可能变慢
- 实现原理:通过更紧凑的字段编码减少存储空间
● DYNAMIC(动态格式):
- 存储创新:
- 变长列值完全存储在页外
- 索引记录仅保留20字节的指针指向溢出页
- 特殊处理:>=768字节的固定长度字段自动转为变长字段
- 大索引支持:
- 支持最大3072字节的索引前缀
- 通过innodb_large_prefix参数控制(MySQL 5.7.7+默认启用)
- 适用场景:包含大量TEXT/BLOB字段或超长VARCHAR字段的表
● COMPRESSED(压缩格式):
- 核心特性:
- 继承DYNAMIC格式所有功能
- 增加透明页压缩功能
- 压缩方式:
- 使用zlib算法压缩表和索引数据
- 支持多种压缩级别(KEY_BLOCK_SIZE可配置)
- 典型应用:存储密集型场景,如日志表、归档数据等
- 技术演进
从REDUNDANT到COMPRESSED的演进体现了存储引擎的优化方向:
- 存储效率:逐步提高空间利用率
- 大对象处理:从部分页外存储到完全页外存储
- 功能扩展:增加压缩等高级特性
- 配置建议
在生产环境中,DYNAMIC通常是最佳选择,除非:
- 需要极致压缩 → 选择COMPRESSED
- 兼容旧版本 → 选择REDUNDANT
- 平衡CPU和I/O → 考虑COMPACT
在创建表和索引时,文件格式都是被用于每个 InnoDB 表数据文件(其名称与 ibd 匹配)。修改文件格式的方法是重新创建表及其索引,最简单的方法是对要修改的每个表使用以下命令:
ALTER TABLE 表名 ROW_FORMAT = 格式类型
表的行格式详解
行格式概述
表的行格式(Row Format)定义了表中每一行数据的物理存储方式,这种存储方式会直接影响数据库的查询性能、DML(数据操纵语言)操作效率以及存储空间利用率。常见的行格式包括COMPACT、DYNAMIC、COMPRESSED和REDUNDANT等。
行格式的重要性
- 存储密度影响性能:当单个数据页(Page)能够容纳更多行时,查询和索引操作会更快
- 内存利用率:更高的存储密度意味着缓冲池(Buffer Pool)中需要的内存更少
- I/O效率:写入和更新操作所需的I/O次数会减少
行格式的工作原理
- 固定长度字段:如INT、DATE等类型会按照固定长度存储
- 可变长度字段:如VARCHAR、TEXT等类型会使用可变长度存储
- NULL值处理:不同的行格式对NULL值的存储方式不同
- 溢出页处理:当行数据超过页大小时的处理机制
不同行格式的比较
| 行格式 | 特点 | 适用场景 |
|---|---|---|
| COMPACT | 节省空间,支持动态列 | 通用场景 |
| DYNAMIC | 对大行处理更好,支持在线变更 | 大字段多的表 |
| COMPRESSED | 支持压缩存储 | 存储空间受限的环境 |
| REDUNDANT | 兼容旧版本 | 向后兼容需求 |
实际应用考量
- 行格式选择:需要根据表的访问模式和数据特征选择
- 修改行格式:ALTER TABLE语句可以修改现有表的行格式
- 性能测试:不同行格式在不同负载下表现不同,建议进行基准测试
最佳实践建议
- 对于主要包含小字段的表,使用COMPACT格式
- 对于包含大量可变长度字段或大字段的表,考虑DYNAMIC格式
- 在存储空间受限的环境中,COMPRESSED格式可以显著减少空间使用
- 定期监控表空间使用情况,必要时调整行格式