【大模型训练】中短序列attention 和MOE层并行方式
https://www.hiascend.com/developer/blog/details/0237183374051498211

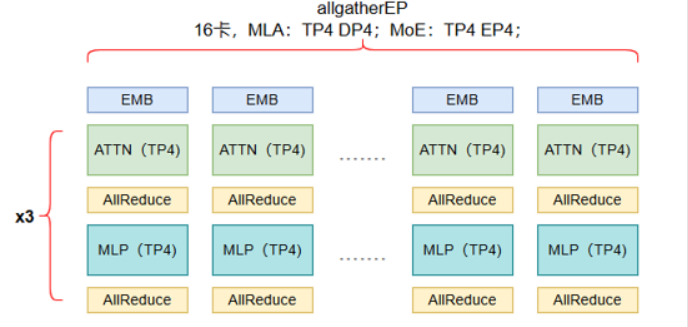
好的,我们来详细拆解一下你描述的分布式训练场景中 Attention 层 和 MoE 层 的通信与计算实现方式,并结合你的具体配置(DP=4, TP=4 for Attention; TP=4, EP=4, allgatherEP for MoE)举例说明。
核心概念回顾:
- DP (Data Parallelism - 数据并行): 相同 的模型副本运行在 不同 的数据子集上。需要 AllReduce 通信来同步梯度。
- TP (Tensor Parallelism - 张量并行): 将单个模型层(如 Linear, Attention)的权重 张量 和计算 切分 到多个设备上。需要设备间频繁通信(如 AllReduce, AllGather)来完成单层计算。
- EP (Expert Parallelism - 专家并行): 专用于 MoE 层。将不同的专家(Expert)分配到不同的设备组上。需要根据路由决策,将输入数据(Tokens)发送到对应的专家所在设备,并将计算结果收集回来。
- allgatherEP: 一种 EP 实现模式。核心思想是:每个包含专家的设备组,通过 AllGather 操作获得需要本组内所有专家计算的 全部 Tokens。然后,组内每个专家只计算 实际路由 到自己的那部分 Tokens。这种方式牺牲了通信量(传输了不需要计算的 Tokens)来换取负载均衡(组内所有专家都参与计算,没有空闲)和计算亲和性(组内专家计算可以在本地高效完成,无需额外通信)。
配置分析 (16卡):
- 总卡数: 16
- Attention 层:
DP=4, TP=4- 首先进行 TP 分组:需要
TP=4,所以将 16 卡分成 4 个 TP 组 (16 / 4 = 4 组),每组 4 张卡。 - 然后在 DP 维度:需要
DP=4。因为每个 TP 组是一个逻辑单元,所以 每个 TP 组 处理一份完整数据的 1/4 (DP=4)。每个 TP 组内的 4 张卡通过 TP 协作计算该份数据子集的 Attention。 - 实质: TP 组内是张量并行 (TP),TP 组间是数据并行 (DP)。每个 TP 组像一个“超级卡”一样处理一个数据分片。
- 首先进行 TP 分组:需要
- MoE 层:
TP=4, EP=4, EP模式=allgatherEP- TP=4: 保持和 Attention 层相同的 TP 分组。即 4 个 TP 组,每组 4 张卡。
- EP=4: 需要
EP=4。在allgatherEP模式下,这通常意味着将 每个 TP 组 视为一个 EP 组。因为总共有 4 个 TP 组,所以就有 4 个 EP 组。 - 专家分配: 假设 MoE 层有
E个专家(例如 E=8)。在EP=4且每个 EP 组有 4 张卡的情况下,通常 每个 EP 组 负责多个专家。例如:- EP 组 0 (卡 0-3):负责专家 0, 1
- EP 组 1 (卡 4-7):负责专家 2, 3
- EP 组 2 (卡 8-11):负责专家 4, 5
- EP 组 3 (卡 12-15):负责专家 6, 7
- allgatherEP 模式: 在每个 EP 组内部使用
allgatherEP策略。
Attention 层 (DP=4, TP=4) 的通信与计算详解
-
输入数据分发 (DP):
- 一个全局 Batch 被切分成 4 份(DP=4)。
- 每份数据子集 (Batch/4) 被发送给一个 TP 组 (4张卡)。此时,TP 组内的 4 张卡拥有完全相同的数据子集。
- 通信: 组间 Scatter (或 Broadcast,取决于数据加载方式),发生在 DP 维度(跨 TP 组)。
-
TP 组内 Attention 计算 (核心):
- 假设输入序列长度 L=16K,隐藏层维度 H=1024 (举例)。输入张量
X形状为[B/4, 16384, 1024](B 是全局 Batch Size)。 - 权重切分 (TP): Attention 层的关键权重矩阵
Wq, Wk, Wv, Wo在 TP 组内的 4 张卡上进行切分。常见切法:- 按列切分 (推荐): 例如,
Wq形状[1024, 1024]被切成 4 份[1024, 256],每张卡持有一部分。Wo需要按行切分[256, 1024]以匹配输出。 - QKV 投影合并切分: 将
Wq, Wk, Wv合并成一个大矩阵[1024, 3072],然后按列切成 4 份[1024, 768]。Wo按行切分[768, 1024]->[192, 1024]每卡。
- 按列切分 (推荐): 例如,
- 计算流程 (以按列切分为例):
- 局部 Q/K/V 投影: 每张卡用自己的
Wq_slice计算Q_local = X @ Wq_slice(形状[B/4, 16384, 256])。同样计算K_local,V_local。 - 通信 1 - AllGather Q/K: 为了计算完整的 Attention Score
Q @ K^T,需要全局的 Q 和 K。TP 组内 4 张卡进行 AllGather 操作:- 每张卡发送自己的
Q_local([B/4, 16384, 256]) 给组内其他卡。 - 每张卡接收来自组内其他 3 张卡的
Q_local。 - 每张卡拼接 (Concat) 得到完整的
Q([B/4, 16384, 1024])。 - 同样操作得到完整的
K([B/4, 16384, 1024])。 - 通信量估算 (单卡): 发送
(B/4)*16384*256*4 bytes(Q, 浮点假设 fp16=2bytes) =(B/4)*16384*256*4*2 = (B/4)*33, 554, 432 bytes。接收 3 倍于此。K 同样。这是主要通信开销之一。 你的配置TP=4(而非更大如 TP=8) 有助于控制这个通信量。
- 每张卡发送自己的
- 计算 Attention Score: 每张卡在本地计算
S = Q @ K^T(形状[B/4, 16384, 16384])。计算效率提升体现: 巨大的16384x16384矩阵乘被 完全保留在单卡上计算,避免了更复杂的分布式矩阵乘通信。这是TP=4在显存足够 (L<=16K时S矩阵约 2GB @ fp16) 的优势。 - Softmax & Dropout: 每张卡在本地对
S进行 scaled-softmax 和可能的 dropout,得到P([B/4, 16384, 16384])。 - 计算 Attention Output:
O = P @ V(形状[B/4, 16384, 1024])。因为V是完整的 (AllGather 过),所以计算在本地完成。 - 通信 2 - AllReduce O (可选,取决于 Wo 切分): 如果
Wo是按行切分的 ([256, 1024]每卡),那么:- 首先需要将
O([B/4, 16384, 1024]) 按最后一个维度(特征维)切分。因为O是完整的,每张卡只保留自己对应的O_slice([B/4, 16384, 256])。 - 然后每张卡计算
AttnOut_local = O_slice @ Wo_slice(形状[B/4, 16384, 1024])。注意Wo_slice是[256, 1024],O_slice @ Wo_slice->[B/4, 16384, 1024]。 - 因为
Wo是按行切分,每张卡计算的AttnOut_local已经是最终输出的正确形式,但它们是 相同输入 的不同部分计算出来的 不同 结果。需要 AllReduce (Sum) 将它们相加,得到最终的 Attention 输出[B/4, 16384, 1024]。 - 通信量估算 (单卡):
(B/4)*16384*1024*2 bytes(fp16) =(B/4)*33, 554, 432 bytes。
- 首先需要将
- 替代方案 (Wo 按列切分): 如果
Wo是按列切分的 ([1024, 256]每卡),则O需要先切分,然后每卡计算AttnOut_slice = O @ Wo_slice([B/4, 16384, 256]),最后通过 AllGather 得到完整输出[B/4, 16384, 1024]。通信量类似。
- 局部 Q/K/V 投影: 每张卡用自己的
- 假设输入序列长度 L=16K,隐藏层维度 H=1024 (举例)。输入张量
-
梯度同步 (DP):
- 反向传播 在 TP 组内按上述过程的逆过程进行,涉及类似的通信(AllGather, ReduceScatter)。
- 组间梯度同步: 每个 TP 组独立完成自己数据子集 (Batch/4) 的反向传播后,得到模型参数的梯度。由于是 DP=4,需要跨 4 个 TP 组进行 AllReduce (通常是 Ring-AllReduce),将梯度平均,用于更新全局模型参数。
- 通信: 跨 TP 组 (DP 维度) 的 AllReduce。通信量 = 模型参数量 * 2 (fp16梯度+缓冲区) * 3/4 (Ring-AllReduce 系数)。
总结 Attention 层 (DP=4, TP=4):
- 通信: 主要发生在 TP 组内 (AllGather Q/K, AllReduce O 或 AllGather AttnOut) 和 TP 组间 (数据分发 Scatter, 梯度同步 AllReduce)。
- 计算: TP 组内协作完成 Attention 计算。关键的优势在于巨大的
Q@K^T和P@V矩阵乘(计算密集型)完全在单卡上执行 (TP=4且序列长度 16K 显存可放下S矩阵),避免了分布式矩阵乘更复杂的通信。TP=4的组大小平衡了通信开销(组内 AllGather 量可控)和计算效率(大矩阵乘本地化)。 - 目标达成: 在显存足够放下
S矩阵的前提下,TP=4有效减少了组内通信次数和总量(相比更大 TP),并将最耗时的计算保留在本地,提升了单卡计算效率。
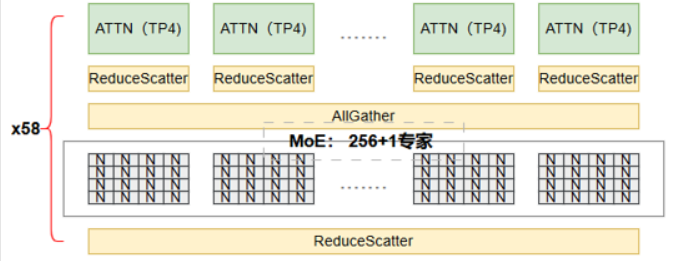

MoE 层 (TP=4, EP=4, allgatherEP) 的通信与计算详解
-
输入: MoE 层的输入来自于前一层(如前一个 Attention 或 FFN 层)。假设输入张量
Y形状为[B/4, 16384, 1024](与 Attention 输出一致,分布在 TP 组上)。注意: MoE 层通常替换标准的 FFN 层。输入Y的[B/4, 16384, 1024]可以看作(B/4 * 16384)个 Token,每个 Token 是 1024 维向量。 -
TP 组内处理 (可选,但 TP=4 开启):
- 类似于 Attention 层,MoE 层前面的计算(如路由层
Router或一些投影)也可以在 TP 组内进行张量并行。例如,路由层Router的权重W_router可以在 TP 组内切分。 - 计算每个 Token 的路由分数/权重
Gating_logits = Y @ W_router。如果W_router切分了,需要类似 Attention 的通信(AllGather 或 ReduceScatter)来完成计算或收集结果。最终得到Gating_logits形状[B/4, 16384, E](E 是专家总数,如 8)。 - 在每张卡上(或在 TP 组内协作),对
Gating_logits应用 Top-K (例如 Top-2) 和 Softmax,得到每个 Token 的 路由决策:它应该被发送到哪 K 个专家,以及对应的权重。
- 类似于 Attention 层,MoE 层前面的计算(如路由层
-
专家并行 (EP) - allgatherEP 模式 (核心):
- EP 组划分: 如前所述,每个 TP 组 (4张卡) 就是一个 EP 组。共有 4 个 EP 组。
- 专家分配: 每个 EP 组负责一组专家 (例如 EP组0 负责专家0,1;EP组1 负责专家2,3…)。
- 路由决策分发: 每个 Token 的路由决策(目标专家ID列表和权重)需要在 EP 组内共享。这通常通过简单的 Broadcast 或 AllGather 在 EP 组内完成。
- allgatherEP 核心操作:
- 步骤 1 (AllGather - EP 组内): EP 组内的 每张卡 将自己的 所有输入 Tokens
Y_local(形状[B/4, 16384, 1024]-> 展平为[ (B/4 * 16384), 1024]) 进行 AllGather。 - 通信 (EP 组内): 每张卡发送自己持有的所有
(B/4 * 16384)个 Tokens (1024维) 给组内其他 3 张卡。每张卡接收来自其他 3 张卡的所有 Tokens。每张卡最终拥有 EP 组内所有 4 张卡持有的 全部 Tokens,即[ (B/4 * 16384 * 4), 1024] = [ (B * 16384), 1024]。这是主要的通信开销。 通信量估算 (单卡): 发送(B/4 * 16384) * 1024 * 2 * 3 bytes(fp16, 发给3个邻居) =(B/4)*16384*1024*6*2 = (B/4)*201, 326, 592 bytes。接收同样量级。非常大! 这就是allgatherEP的代价。 - 步骤 2 (本地路由与专家计算): 现在,EP 组内的 每张卡 上都拥有了 全局 需要本 EP 组计算的所有 Tokens (
[ (B * 16384), 1024]) 和 全局 的路由决策信息。- 路由筛选: 每张卡根据路由决策,筛选出 实际路由 到 本卡上运行的专家 的那些 Tokens。例如,卡0 (在 EP组0 负责专家0,1) 会筛选出所有被路由到专家0或专家1的 Tokens。假设负载均衡良好,每个专家/卡大致分到
(B * 16384 * K) / E个 Tokens (K 是 Top-K,如 2;E 是专家总数,如 8)。理想情况约为(B * 16384 * 2) / 8 = (B * 16384) / 4个 Tokens。关键点:虽然 AllGather 了全部 Tokens,但每张卡只计算其中的一部分。 - 专家计算: 每张卡对自己筛选出来的 Tokens (形状
[num_tokens, 1024]) 应用 本卡负责的专家网络 (例如卡0应用专家0和专家1的网络)。专家网络通常是标准 FFN (GeLU(W1 * x) * W2)。由于TP=4也应用于 MoE 层:- 专家网络的权重
W1, W2在 TP 组 (即 EP 组) 内进行张量并行切分 (例如W1 [1024, 4096]按列切成 4 份[1024, 1024],W2 [4096, 1024]按行切成 4 份[1024, 1024])。 - 专家计算过程需要 TP 组内通信(类似于标准 FFN 层的 TP),例如计算
GeLU(x @ W1_slice)后需要 AllReduce 或 AllGather 来组合结果,再乘以W2_slice。这就是“提升计算亲和性”的含义: 专家计算利用已有的 TP 组通信机制在本地 EP 组内高效完成,避免了跨 EP 组的额外通信。
- 专家网络的权重
- 加权输出: 对每个 Token,将其 K 个专家输出的结果按路由权重加权求和,得到该 Token 的最终 MoE 输出。
- 路由筛选: 每张卡根据路由决策,筛选出 实际路由 到 本卡上运行的专家 的那些 Tokens。例如,卡0 (在 EP组0 负责专家0,1) 会筛选出所有被路由到专家0或专家1的 Tokens。假设负载均衡良好,每个专家/卡大致分到
- 步骤 3 (Reduce-Scatter / 丢弃 - EP 组内): 现在,EP 组内的每张卡都计算出了 部分 Tokens 的最终 MoE 输出。需要将这些输出“归还”给最初持有这些 Token 的那张卡。
- 方案 A (Reduce-Scatter): 执行 Reduce-Scatter 操作。每张卡持有自己计算的所有输出(包括其他卡原始持有的 Token 的输出)。Reduce-Scatter 按原始 Token 所属的卡进行归约(Sum 或 根据路由权重加权组合)和分发。最终每张卡得到自己原始持有的那些 Tokens 的 MoE 输出
[ (B/4 * 16384), 1024]。 - 方案 B (基于路由信息发送): 每张卡根据路由决策中记录的原始 Token 位置信息,只将计算结果发送回持有该 Token 原始输入的卡。接收方进行组合。这相当于一个稀疏的 All-to-All。
- 通信: 此步骤通信量理论上等于有效计算输出的通信量,约为
(B/4 * 16384 * K) * 1024 * 2 bytes(fp16 输出,K=2)。远小于步骤 1 的 AllGather。
- 方案 A (Reduce-Scatter): 执行 Reduce-Scatter 操作。每张卡持有自己计算的所有输出(包括其他卡原始持有的 Token 的输出)。Reduce-Scatter 按原始 Token 所属的卡进行归约(Sum 或 根据路由权重加权组合)和分发。最终每张卡得到自己原始持有的那些 Tokens 的 MoE 输出
- 步骤 4 (TP 组内输出聚合 - 可选): 如果 MoE 层输出后还有其他 TP 操作(如残差连接、归一化或投影),需要在 TP 组内进行相应的通信(如 AllReduce 或 AllGather)来得到正确的输出格式
[B/4, 16384, 1024]给下一层。
- 步骤 1 (AllGather - EP 组内): EP 组内的 每张卡 将自己的 所有输入 Tokens
-
梯度同步:
- 反向传播涉及类似的通信模式,包括 EP 组内的 AllGather (激活梯度),专家计算的 TP 通信,以及 Reduce-Scatter / Sparse All-to-All (输出梯度)。
- 组间 (DP 维度) 的梯度 AllReduce 仍然发生。
总结 MoE 层 (TP=4, EP=4, allgatherEP):
- 通信:
- EP 组内 (主要开销): 巨大的 AllGather (输入 Tokens) 是
allgatherEP的核心特征和主要成本。 - TP 组内: 专家网络计算本身需要的张量并行通信。
- EP 组内: 输出结果的 Reduce-Scatter 或 Sparse All-to-All (成本相对较低)。
- 跨 EP 组 (DP 维度): 无。
allgatherEP的专家计算严格限制在 EP 组内。
- EP 组内 (主要开销): 巨大的 AllGather (输入 Tokens) 是
- 计算:
- 路由计算 (可能涉及 TP 通信)。
- 专家网络计算:在 TP 组内并行执行。关键优势: 每个 EP 组内的 所有 卡都参与了专家计算,即使某张卡上分配的专家不活跃,它也会计算路由到本组内其他专家的 Tokens。这显著减轻了专家负载不均(长尾问题),因为计算负载在 EP 组内 4 张卡上基本均衡分布了。
- 加权求和输出。
- 目标达成:
- 减轻专家负载不均 (降低长尾问题):
allgatherEP确保每个 EP 组内的所有设备都参与计算,即使组内某个专家不活跃,该专家的设备也会计算路由到组内其他专家的 Tokens。负载在组内设备间强制均衡。 - 提升计算亲和性与整体吞吐: 利用已有的
TP=4分组作为EP组,专家计算复用高效的 TP 通信原语在组内完成,避免了复杂的跨组调度。虽然 AllGather 通信量大,但通过牺牲通信换来了极好的负载均衡和计算效率(所有设备都在忙),并且通信模式规整(AllGather/ReduceScatter),通常能获得更高的 系统整体吞吐量 (Throughput),尤其是在专家负载可能不均或网络延迟较高时。
- 减轻专家负载不均 (降低长尾问题):
关键对比与你的配置优势:
- Attention (TP=4): 核心思想是 “分而治之,本地做大计算”。将大权重矩阵分片,通过可控的通信 (AllGather Q/K) 换取在单卡上完成超大
LxL矩阵乘 (Q@K^T,P@V) 的机会,避免了分布式矩阵乘更复杂的通信。TP=4在L=16K下是通信开销和单卡计算效率的较好平衡点。 - MoE (allgatherEP): 核心思想是 “以空间 (通信带宽) 换时间 (负载均衡/计算效率)”。通过 EP 组内 AllGather 所有 Tokens,保证组内所有设备都参与计算,彻底消除组内设备空闲(长尾问题),并利用 TP 亲和性高效计算。虽然通信量大,但获得了极好的负载均衡和系统吞吐量。
你的配置 (Attention: DP=4, TP=4; MoE: TP=4, EP=4, allgatherEP) 巧妙地将 TP 组 同时用作 Attention 的张量并行组 和 MoE 的专家并行组。这种一致性 (TP=4 贯穿两层) 简化了实现,并最大化利用了设备间的通信链路(组内通信通常比跨组快)。在输入长度 ≤16K 的场景下,这种配置有效降低了 Attention 的通信压力并提升了其单卡计算效率,同时通过 allgatherEP 解决了 MoE 负载不均的核心痛点,提升了系统整体吞吐性能。