7.6 Finetuning the LLM on instruction data
Chapter 7-Fine-tuning to follow instructions
7.6 Finetuning the LLM on instruction data
-
本节我们开始微调当前模型

-
让我们在开始训练之前计算初始训练和验证集损失(与前几章一样,目标是最小化损失)
model.to(device)torch.manual_seed(123)with torch.no_grad():train_loss = calc_loss_loader(train_loader, model, device, num_batches=5)val_loss = calc_loss_loader(val_loader, model, device, num_batches=5)print("Training loss:", train_loss) print("Validation loss:", val_loss)"""输出""" Training loss: 3.8259095668792726 Validation loss: 3.761933755874634 -
请注意,这次的训练比之前的章节要稍微昂贵一些,因为我们正在使用一个更大的模型(有 3.55 亿个参数,而不是 1.24 亿个参数)。
各种设备的运行时间如下所示以供参考(在兼容的 GPU 设备上运行此笔记本无需对代码进行任何更改)。
| Model | Device | Runtime for 2 Epochs |
|---|---|---|
| gpt2-medium (355M) | CPU (M3 MacBook Air) | 15.78 minutes |
| gpt2-medium (355M) | GPU (M3 MacBook Air) | 10.77 minutes |
| gpt2-medium (355M) | GPU (L4) | 1.83 minutes |
| gpt2-medium (355M) | GPU (A100) | 0.86 minutes |
| gpt2-small (124M) | CPU (M3 MacBook Air) | 5.74 minutes |
| gpt2-small (124M) | GPU (M3 MacBook Air) | 3.73 minutes |
| gpt2-small (124M) | GPU (L4) | 0.69 minutes |
| gpt2-small (124M) | GPU (A100) | 0.39 minutes |
-
3060 12G运行
import timestart_time = time.time()torch.manual_seed(123)optimizer = torch.optim.AdamW(model.parameters(), lr=0.00005, weight_decay=0.1)num_epochs = 2train_losses, val_losses, tokens_seen = train_model_simple(model, train_loader, val_loader, optimizer, device,num_epochs=num_epochs, eval_freq=5, eval_iter=5,start_context=format_input(val_data[0]), tokenizer=tokenizer )end_time = time.time() execution_time_minutes = (end_time - start_time) / 60 print(f"Training completed in {execution_time_minutes:.2f} minutes.")"""输出""" Ep 1 (Step 000000): Train loss 2.637, Val loss 2.626 Ep 1 (Step 000005): Train loss 1.174, Val loss 1.102 Ep 1 (Step 000010): Train loss 0.872, Val loss 0.944 Ep 1 (Step 000015): Train loss 0.857, Val loss 0.906 Ep 1 (Step 000020): Train loss 0.776, Val loss 0.881 Ep 1 (Step 000025): Train loss 0.754, Val loss 0.859 Ep 1 (Step 000030): Train loss 0.799, Val loss 0.836 Ep 1 (Step 000035): Train loss 0.714, Val loss 0.808 Ep 1 (Step 000040): Train loss 0.672, Val loss 0.806 Ep 1 (Step 000045): Train loss 0.633, Val loss 0.789 Ep 1 (Step 000050): Train loss 0.663, Val loss 0.783 Ep 1 (Step 000055): Train loss 0.760, Val loss 0.763 Ep 1 (Step 000060): Train loss 0.719, Val loss 0.743 Ep 1 (Step 000065): Train loss 0.653, Val loss 0.735 Ep 1 (Step 000070): Train loss 0.532, Val loss 0.729 Ep 1 (Step 000075): Train loss 0.569, Val loss 0.728 Ep 1 (Step 000080): Train loss 0.605, Val loss 0.725 Ep 1 (Step 000085): Train loss 0.509, Val loss 0.709 Ep 1 (Step 000090): Train loss 0.562, Val loss 0.691 Ep 1 (Step 000095): Train loss 0.501, Val loss 0.682 Ep 1 (Step 000100): Train loss 0.503, Val loss 0.677 Ep 1 (Step 000105): Train loss 0.564, Val loss 0.670 Ep 1 (Step 000110): Train loss 0.555, Val loss 0.666 Ep 1 (Step 000115): Train loss 0.508, Val loss 0.664 Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is prepared every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: Ep 2 (Step 000120): Train loss 0.435, Val loss 0.672 Ep 2 (Step 000125): Train loss 0.451, Val loss 0.686 Ep 2 (Step 000130): Train loss 0.447, Val loss 0.682 Ep 2 (Step 000135): Train loss 0.405, Val loss 0.681 Ep 2 (Step 000140): Train loss 0.409, Val loss 0.681 Ep 2 (Step 000145): Train loss 0.368, Val loss 0.681 Ep 2 (Step 000150): Train loss 0.382, Val loss 0.675 Ep 2 (Step 000155): Train loss 0.413, Val loss 0.675 Ep 2 (Step 000160): Train loss 0.415, Val loss 0.683 Ep 2 (Step 000165): Train loss 0.379, Val loss 0.685 Ep 2 (Step 000170): Train loss 0.323, Val loss 0.681 Ep 2 (Step 000175): Train loss 0.337, Val loss 0.669 Ep 2 (Step 000180): Train loss 0.392, Val loss 0.656 Ep 2 (Step 000185): Train loss 0.415, Val loss 0.657 Ep 2 (Step 000190): Train loss 0.341, Val loss 0.648 Ep 2 (Step 000195): Train loss 0.329, Val loss 0.635 Ep 2 (Step 000200): Train loss 0.310, Val loss 0.635 Ep 2 (Step 000205): Train loss 0.352, Val loss 0.631 Ep 2 (Step 000210): Train loss 0.367, Val loss 0.630 Ep 2 (Step 000215): Train loss 0.395, Val loss 0.634 Ep 2 (Step 000220): Train loss 0.302, Val loss 0.648 Ep 2 (Step 000225): Train loss 0.348, Val loss 0.661 Ep 2 (Step 000230): Train loss 0.295, Val loss 0.656 Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Convert the active sentence to passive: 'The chef cooks the meal every day.' ### Response: The meal is cooked every day by the chef.<|endoftext|>The following is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: What is the capital of the United Kingdom Training completed in 2.23 minutes.共使用2.23分钟
正如我们根据上面的输出所看到的,模型训练得很好,我们可以根据不断减少的训练损失和验证损失值来判断
此外,根据每个epoch后打印的响应文本,我们可以看到模型正确地遵循指令将输入句子 `'The chef cooks the meal every day.‘转换为被动语态’The meal is cooked every day by the chef.’(我们将在后面的部分中正确格式化和评估响应) -
最后,让我们看一下训练和验证损失曲线
from previous_chapters import plot_lossesepochs_tensor = torch.linspace(0, num_epochs, len(train_losses)) plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)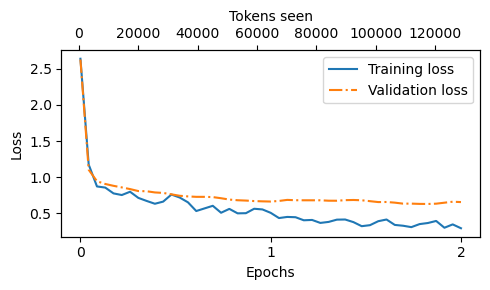
如我们所见,损失在第一个epoch开始时急剧减少,这意味着模型开始快速学习.我们可以看到在第一个epoch后轻微的过度拟合。