配置spark
1.把spark安装包复制到你存放安装包的目录下,例如我的是/opt/software
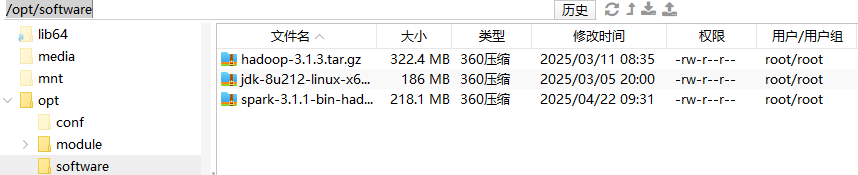
cd /opt/software,进入到你存放安装包的目录
然后tar -zxvf 你的spark安装包的完整名字 -C /opt/module,进行解压。例如我的spark完整名字是spark-3.1.1-bin-hadoop3.2.tgz,所以我要输入的命令是
tar -zxvf spark-3.1.1-bin-hadoop3.2.tgz -C /opt/module

2.配置spark的环境变量
进入到/etc/profile.d目录下
自己新建一个存放修改spark环境变量的文件,例如我的是my_env.sh,在里面添加配置的内容
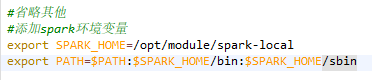
添加以下内容
保存修改,回到输入命令界面,输入source /etc/profile,重新刷新环境变量,让修改的环境变量生效。
在输入 echo $PATH回车,出现spark-local/bin:/opt/module/spark-local/sbin说明我们已经配置好spark的环境变量了

最后我们在通过一个命令查看是否真的配置完成
回到命令界面,输入spark-submit --version
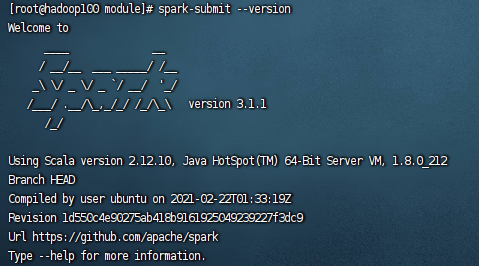
出现图片中的内容说明完成spark的配置