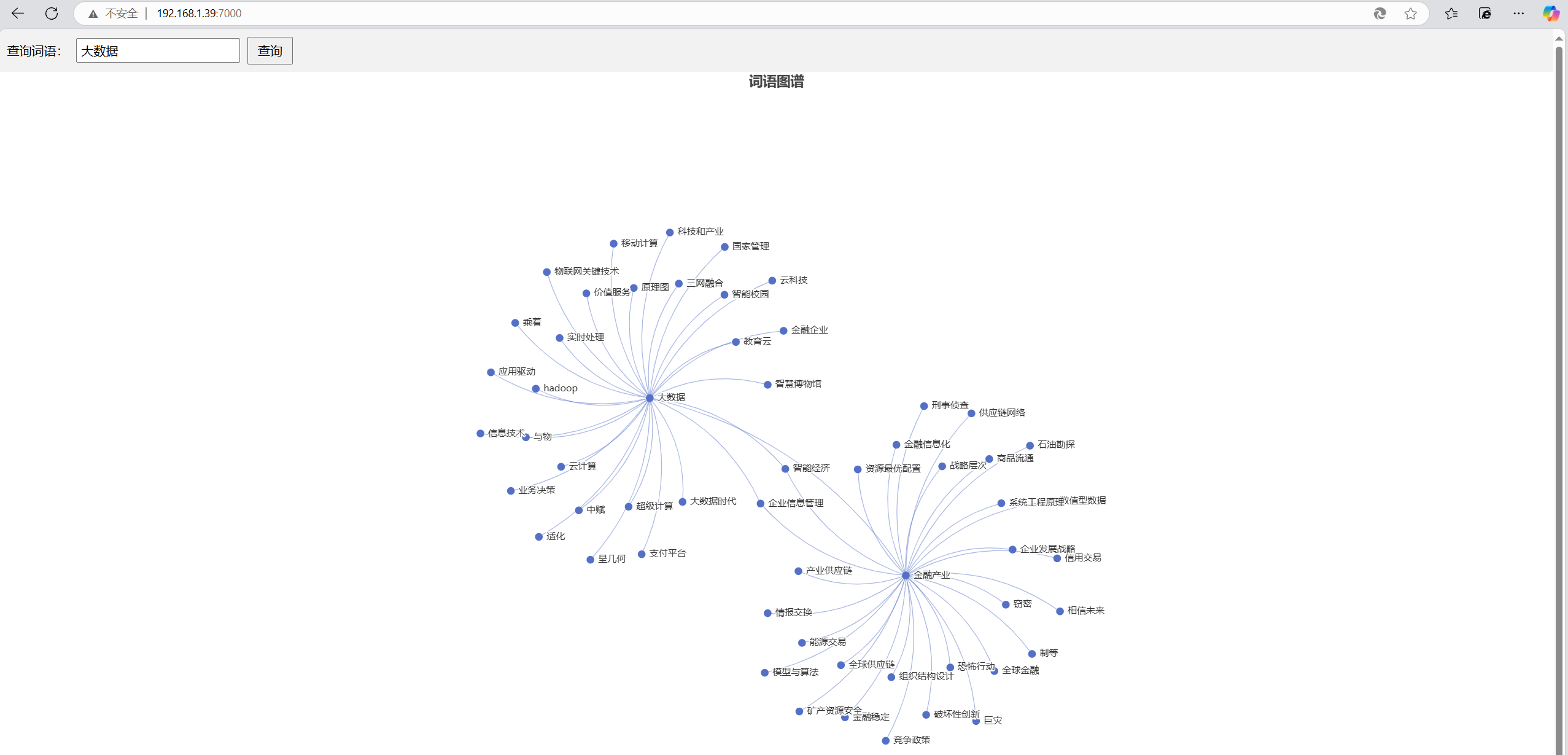
词语关系图谱模型
参数配置说明
sentences, # 分词后的语料(列表嵌套列表)
vector_size=100, # 每个词的向量维度
window=5, # 词与上下文之间的最大距离(滑动窗口大小)
min_count=5, # 忽略出现次数小于5的词
workers=4, # 用于训练的线程数(多线程加速)
sg=0, # 训练算法:0 = CBOW;1 = Skip-gram
hs=0, # 是否使用层次Softmax(和 negative 二选一)
negative=5, # 负采样的数量(常用5~20之间)
epochs=5, # 训练轮数
sample=1e-3, # 高频词下采样的阈值(越小,越容易下采样)
seed=42, # 随机种子,确保可复现
callbacks=None # 自定义训练回调函数(如记录每轮日志)
fangfa 如果是0使用余玄相似度 如果是1使用欧式距离
port 启动前端页面端口
停用词库使用的正则可修改
r'exclude|stopwords|badwords|delete'
包含词库使用的正则
数据文件分隔符{|}