某东 h5st第8个参数 指纹加密纯算解析
声明:
本文章中所有内容仅供学习交流使用,不用于其他任何目的,不提供完整代码,抓包内容、敏感网址、数据接口等均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关!
本文章未经许可禁止转载,禁止任何修改后二次传播,擅自使用本文讲解的技术而导致的任何意外,作者均不负责,若有侵权,请私信作者立即删除!
逆向目标:
京西h5st浏览器指纹加密算法

H5st一共由10个字段组成,下文分别有P1-P10代表,本文主要讲解的P8参数的加密算法。
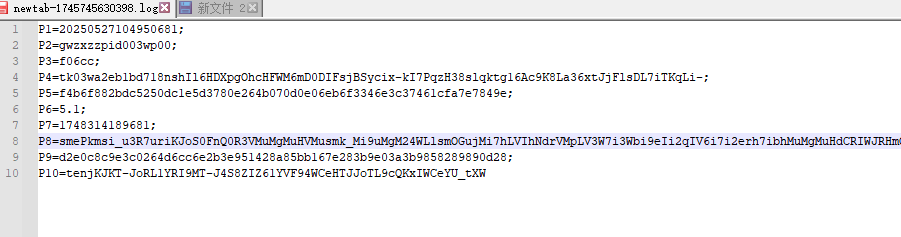
定位H5st:全局搜索即可,打上断点后定位到此处。
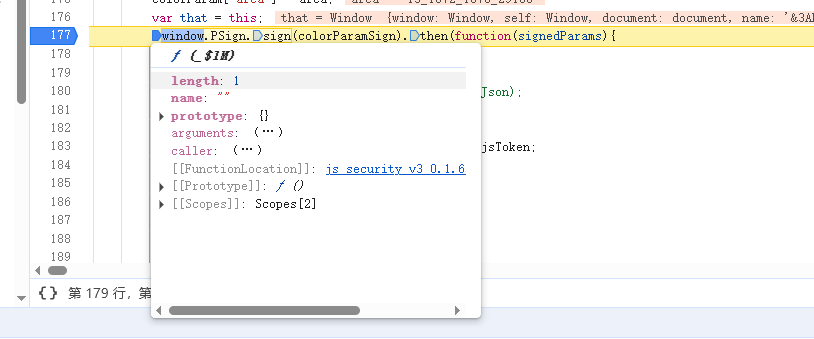
继续跟栈,进入到_$sdnmd函数中,在有call的代码处打上断点。
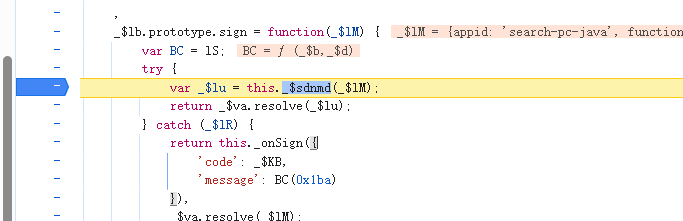
发现是这串代码生成了P8值,继续跟栈。进入_$clt函数

_$clt函数:也是在所有call的代码中打上断点。
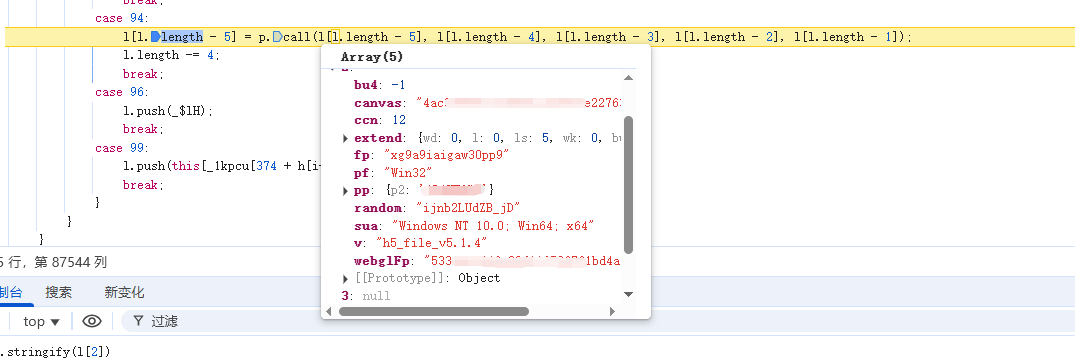
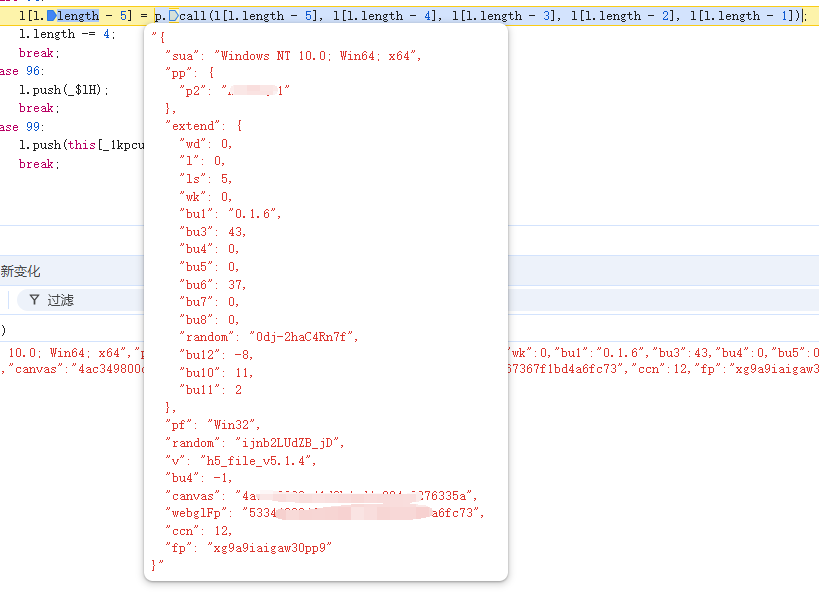
可以发现这一步对l[2]进行了json序列化

其中有两个random随机值,其他都是固定值,canvas和webglFp都是浏览器指纹相关,固定写死的。
继续执行,发现在case 89的位置,该文本本转成了32位数组
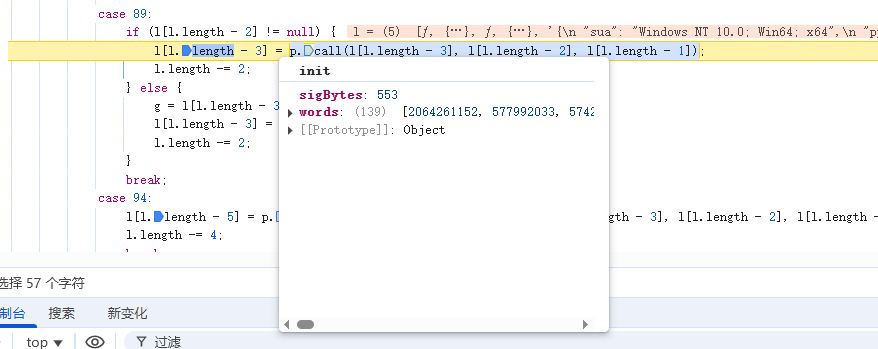
我们写一个代码复现一下:
function textToUint32Array(text) {// 将文本编码为 UTF - 8 字节数组const encoder = new TextEncoder();const uint8Array = encoder.encode(text);const uint32Array = [];// 每 4 个字节一组转换为 32 位整数for (let i = 0; i < uint8Array.length; i += 4) {let num = 0;// 处理每个字节for (let j = 0; j < 4; j++) {if (i + j < uint8Array.length) {// 将字节左移相应位数并累加num |= uint8Array[i + j] << (24 - 8 * j);}}uint32Array.push(num);}return uint32Array;
}text=`{"sua": "Windows NT 10.0; Win64; x64","pp": {"p2": "wwwwwww"},"extend": {"wd": 0,"l": 0,"ls": 5,"wk": 0,"bu1": "0.1.6","bu3": 34,"bu4": 0,"bu5": 0,"bu6": 39,"bu7": 0,"bu8": 0,"random": "lnHB2LqPPm8nd","bu12": -8,"bu10": 11,"bu11": 2},"pf": "Win32","random": "_PDD2odbYe1b1","v": "h5_file_v5.1.4","bu4": -1,"canvas": "4ac349802f4h70b4ad4a894e2276335a","webglFp": "533s48334f42s21167w67f1bdza6fc73","ccn": 12,"fp": "xg9a9iaigaw30pp9"
}`
const result = textToUint32Array(text);
console.log(result.toString());和浏览器执行结果对比,是一模一样的,所以第一步:将明文转成32位数组
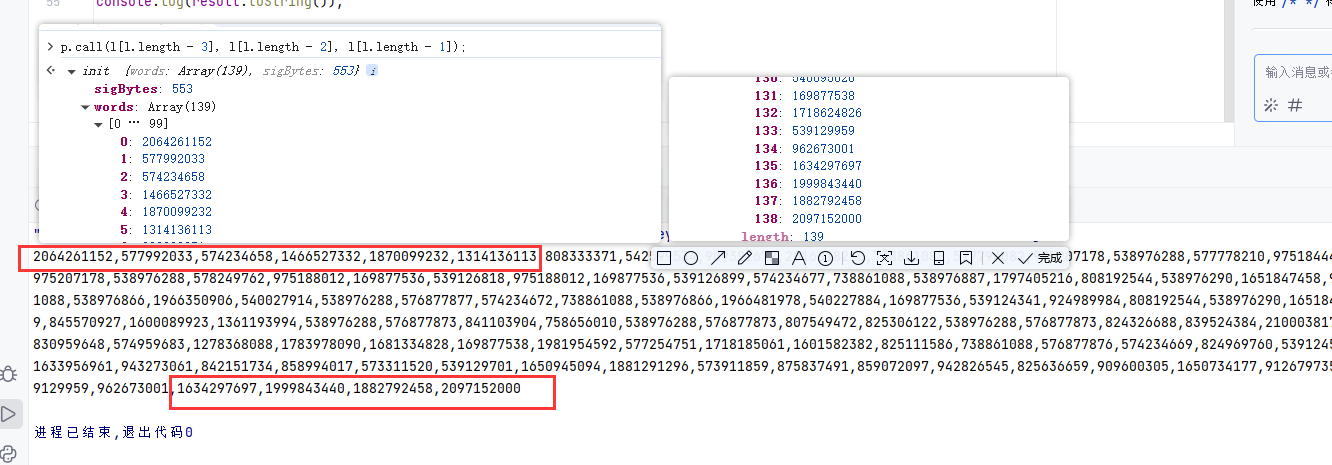
放开断点,继续执行,发现还是在case 89这一步,生成了指纹参数。查看代码可以发现,是进入了encode函数,并且刚才生成的32位数组作为参数进行调用。
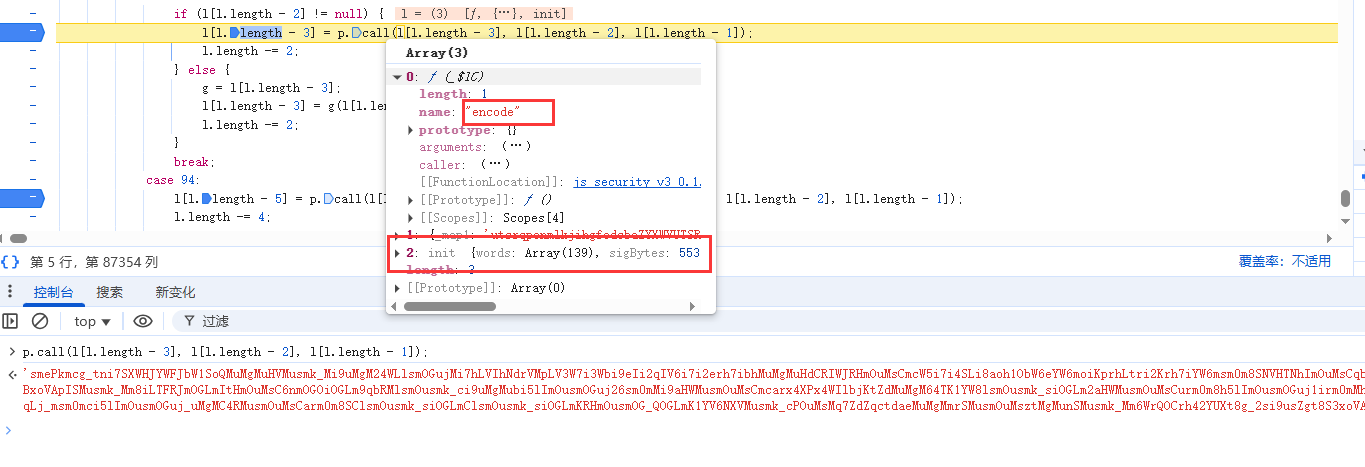
跟进去encode函数,再所有call方法处下断点,继续执行分析代码。
在encode函数内,case9的位置,发现32位数组变成了长度553的Uint8Arrary。对于Uint8Arrary的解释如下:
Uint8 代表 “无符号 8 位整数”,Array 表示数组。因此,Uint8Array 表示一个由 8 位无符号整数组成的数组,数组中的每个元素的取值范围是 0 到 255(因为 8 位二进制数能表示的范围是 0000 0000 到 1111 1111,对应十进制就是 0 到 255)。
所以该数组内存放的都是ASCII码字符集。可以使用String.fromCharCode验证一下发现结果和32位数组还原后的结果一致。

所以第二步:数组转为ASCII码数组,其实就是将第一步的文本,将文本转换为 ASCII 码数组
继续执行代码,断点分析
继续执行,代码在case 9 处断住,查看分析一下
应该是往数组中push了一个2进去
继续执行,还是在这里断住,仍然是push一个2进去。
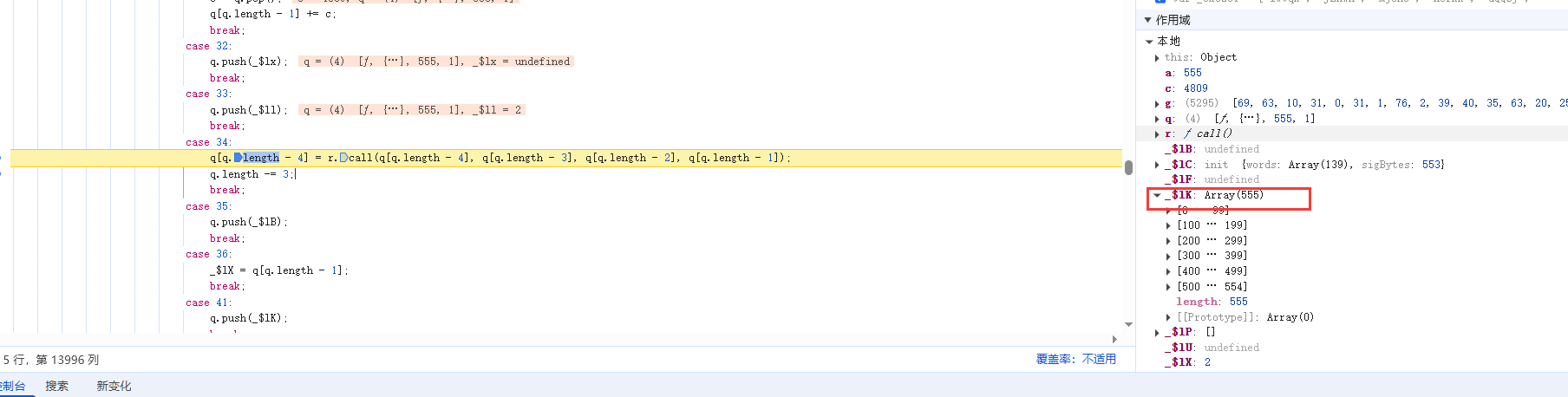
继续执行,在case 34处断住,并且观察右侧的作用于发现,数组长度变成了555
长度由553-->555, 观察可以得知push 2到数组中,到数组长度为3的倍数。
写一个文本转ascii码数组代码还原验证一下:
function textToAsciiArray(text) {const asciiArray = [];for (let i = 0; i < text.length; i++) {// 获取当前字符的 Unicode 码点const codePoint = text.charCodeAt(i);// 检查码点是否在 ASCII 范围内if (codePoint <= 127) {asciiArray.push(codePoint);} else {// 非 ASCII 字符可根据需求处理,这里简单添加 -1 表示asciiArray.push(-1);}}return asciiArray;
}text=`{"sua": "Windows NT 10.0; Win64; x64","pp": {"p2": "ADAHEQW1"},"extend": {"wd": 0,"l": 0,"ls": 5,"wk": 0,"bu1": "0.1.6","bu3": 34,"bu4": 0,"bu5": 0,"bu6": 39,"bu7": 0,"bu8": 0,"random": "EPd-2fco__oCQ","bu12": -8,"bu10": 11,"bu11": 2},"pf": "Win32","random": "E0CL2YXjUXjd7","v": "h5_file_v5.1.4","bu4": -1,"canvas": "4ac349800c41d0b4ad4a894e2276335a","webglFp": "533448334fa82d1167367f1bd4a6fc73","ccn": 12,"fp": "xg9a9iaigaw30pp9"
}`// result = textToUint32Array(text);
result2 = textToAsciiArray(text)
console.log(result2.toString());执行结果对比是一致的。下面需要处理补齐长度的流程,需要判断数组长度,当长度不为3的倍数时,需要补一个2进去,直到长度为3的倍数为止。
function pushToArray(arr) {const remainder = arr.length % 3;if (remainder !== 0) {const elementsToAdd = 3 - remainder;for (let i = 0; i < elementsToAdd; i++) {arr.push(2);}}return arr;
}放开断点,继续往下分析
在case 85处断住,分析代码:
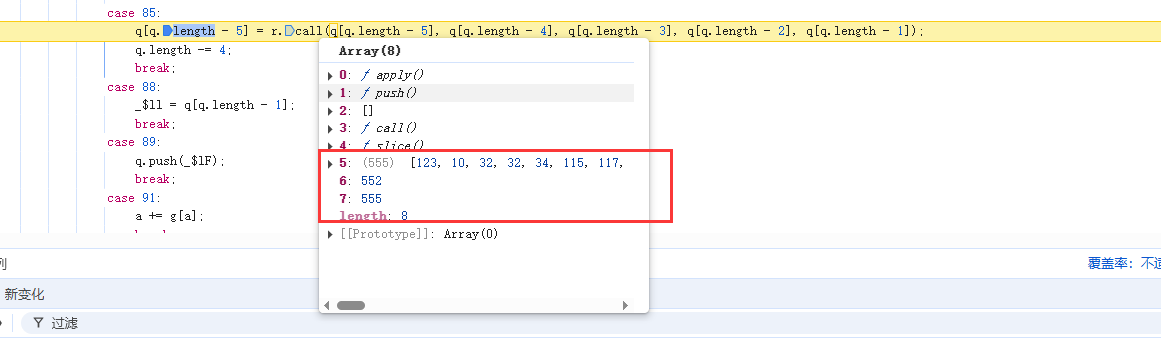
通过push、slice、数组以及552、555这几个参数,可以大概猜测一下流程:
取数组中索引552至555位置的内容。并push到一个新数组中。
继续执行代码,看看下面代码如何执行:
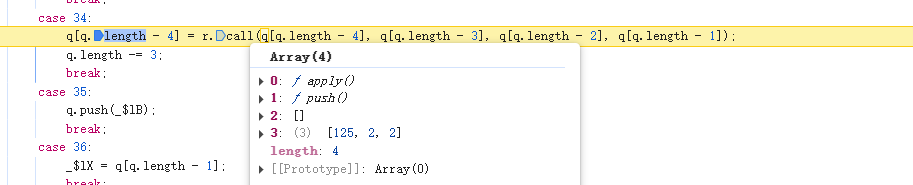
在case 34处断住,并且数组552-555的索引位置刚好是125,2,2,此时被添加到一个新数组中
继续执行,此时发现索引变成了549-552,对应的结果是57,34,10
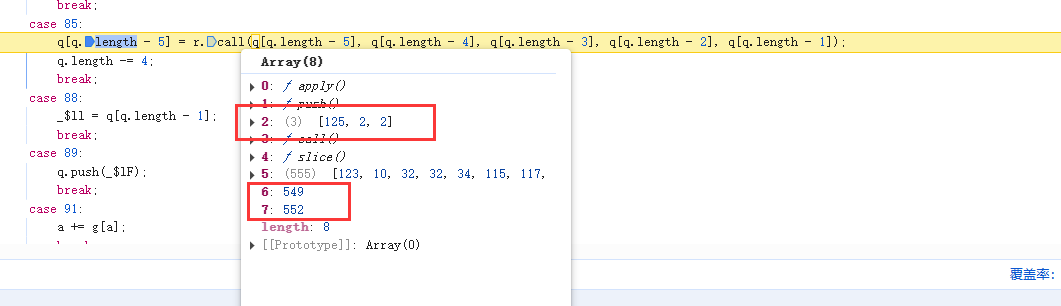
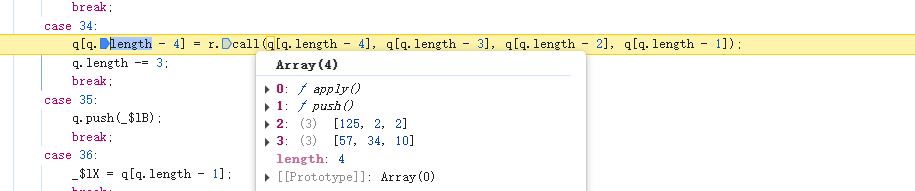
到这里基本和我们猜测的一致,不放心的可以多跟几次验证。
这里case 85 和 case34 会重复调用多次,直到数组计算完成为止,这里我们直接跳过,到最后生成新数组的位置断点,可以加一个条件断点,判断新数组的长度是否大于550,这样我们可以在新数组补齐到555之前断住,从而更好的分析。
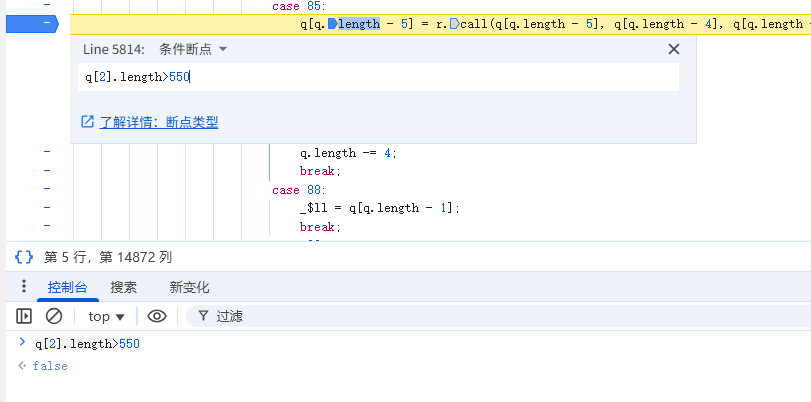
断住之后发现和我们猜想一模一样。

新数组是由老数组,从后往前每3个长度提取一次,添加到新数组中,直到全部提取为止。这也刚好可以解释之前我们为何补齐老数组长度为3的倍数。
写一个排序函数:
function OrderByArray(arr) {const result = [];// 从数组末尾开始,每次递减 3 个元素进行遍历for (let i = arr.length; i > 0; i -= 3) {// 提取从 i - 3 到 i 的元素,如果不足 3 个则提取剩余元素const group = arr.slice(Math.max(0, i - 3), i);result.push(...group);}return result;
}下面可以看一下新数组解析后的结果,并和最初的文本进行对比:
看着很乱,但是观察可以发现,和我们之前猜的逻辑一模一样。
继续执行代码,在encode函数中 case 9的位置断住,进行分析:
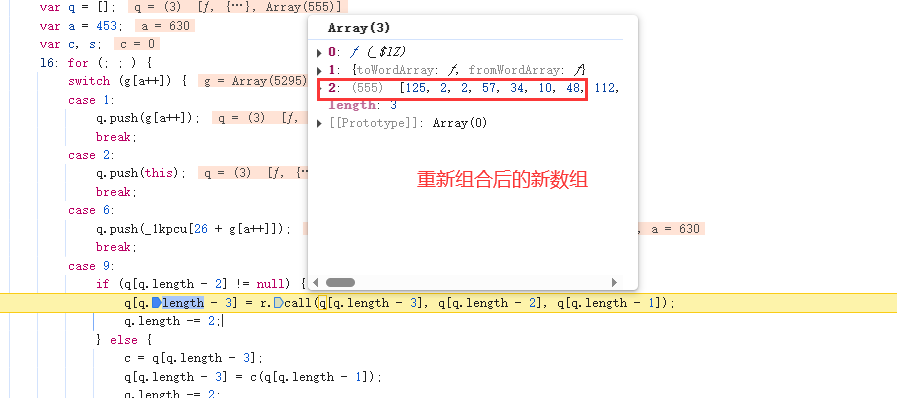
新数组作为参数,调用toWordArray函数后,又生成了一个32位数组。
这里我们把toWordArray函数抠出来
function toWordArray(_$lZ) {for (var _$lF = [], _$lx = 0x1123 + 0x1042 + -0x2165; _$lx < _$lZ.length; _$lx++)_$lF[_$lx >>> 0x182f * -0x1 + -0x7b1 + 0x1fe2] |= _$lZ[_$lx] << -0x24ae + 0xf46 + -0x40 * -0x56 -((_$lx % (-0x20 * 0x56 + 0x118 + 0x9ac))*( -0x2176 + 0x1a53 + 0x1 * 0x72b));return {'words':_$lF,'sigBytes': _$lZ.length};}验证函数结果,数据一致。
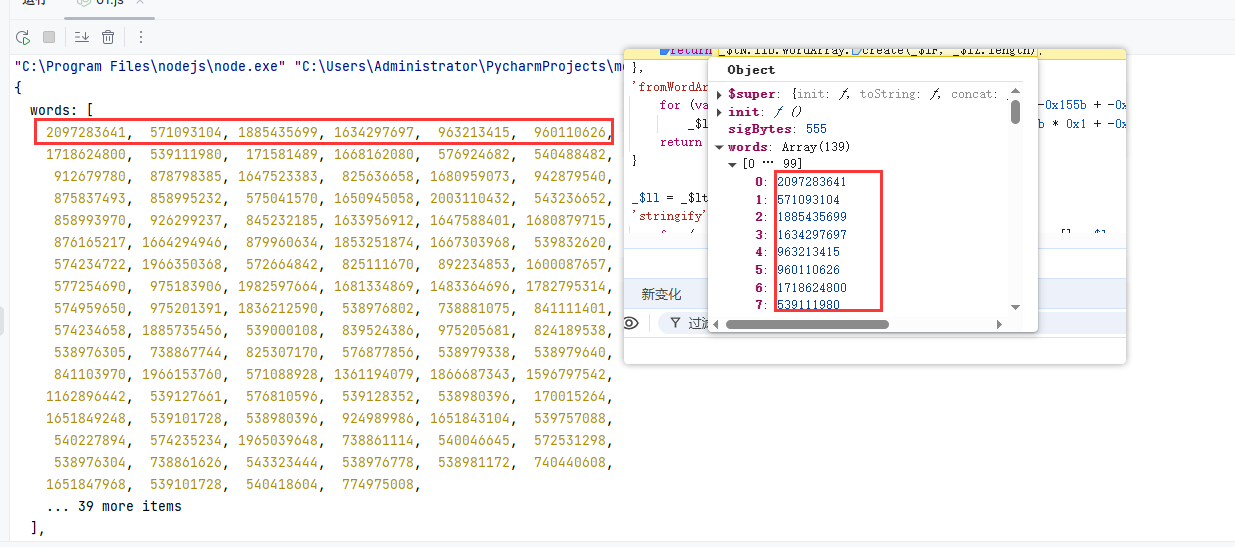
继续执行代码,还是在encode函数 case 9处断住:
生成了一个文本数组
注意:之前添加的条件断点,当代码跑过去之后,记得改成普通断点,否则后续无法在原位置断住了
继续执行代码,在encode函数 case 34处断住:
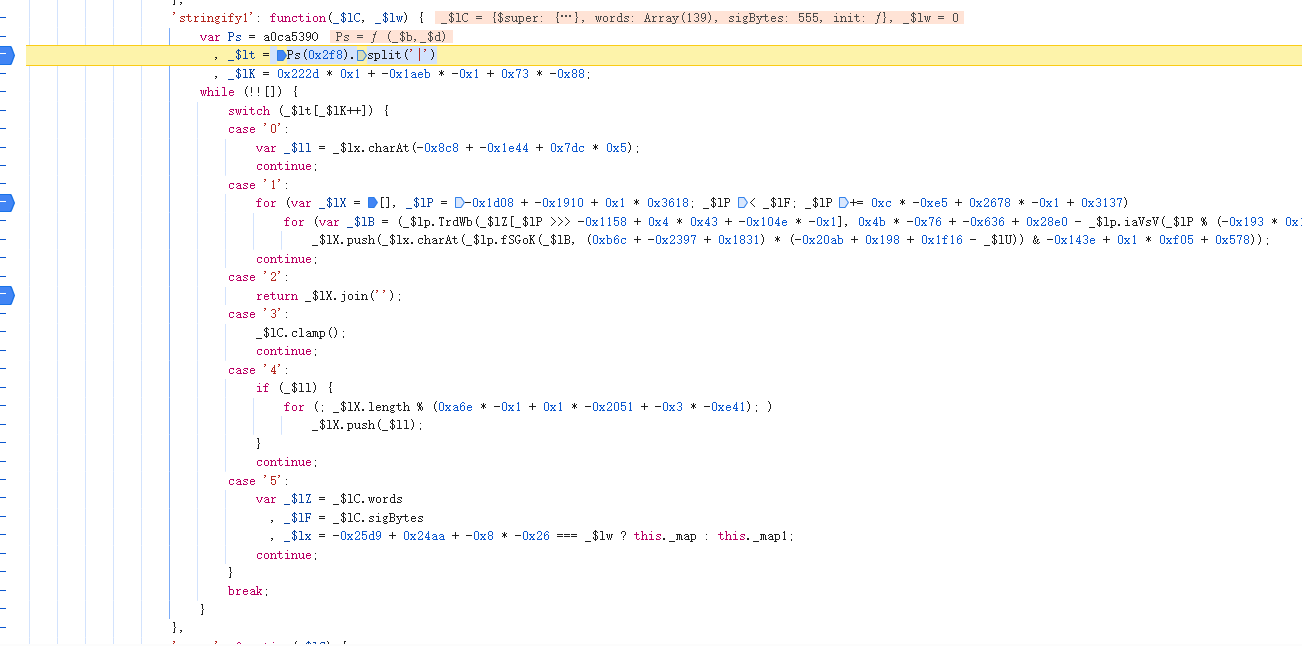
调用了stringfy1函数,生成一串文本。需要跟进去stringfy1函数查看一下
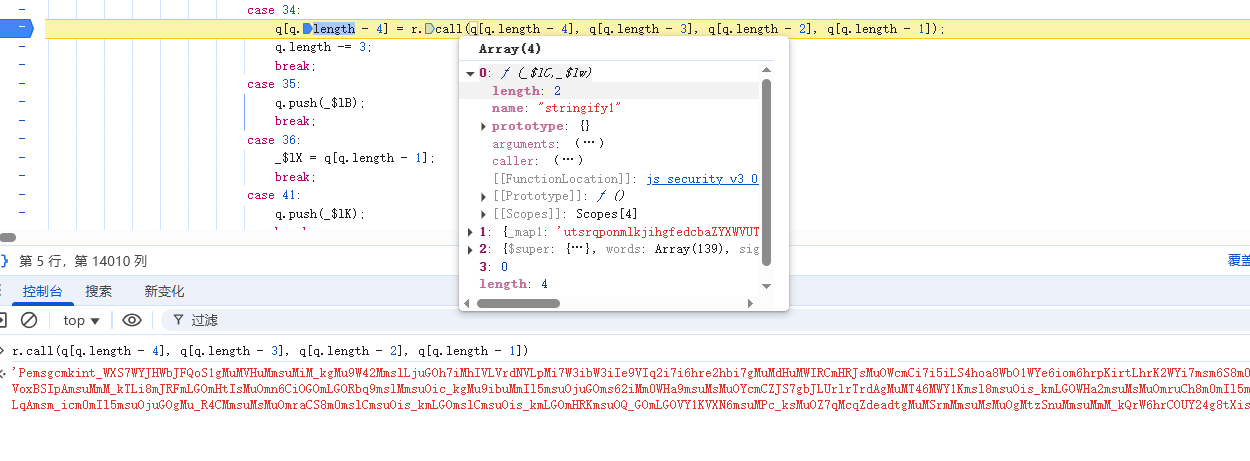
stringfy1函数,是一个switch循环,switch循环的值是_$lt来决定的,我们可以查看_$lt,从而得到函数整体执行顺序。
直接全扣,运行代码缺啥补啥
第一个报错是 _$lC.clamp is not a function,在浏览器中断在这里执行发现返回undefined,直接注释掉就行
第二个报错是_$lp is not defined, 直接把_$lp扣下来
第三个报错是

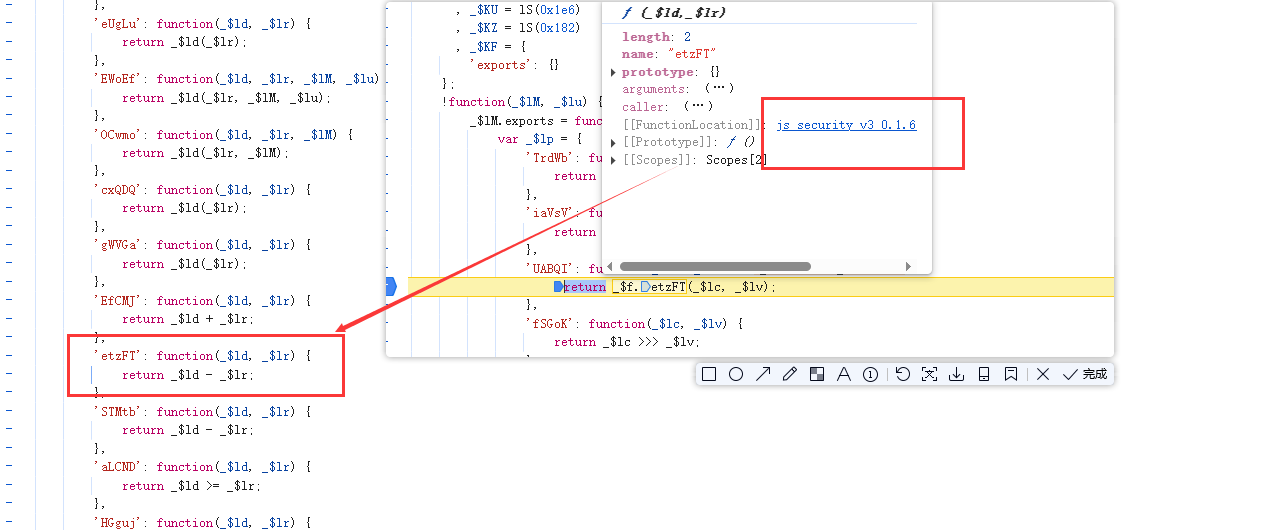
这里不用扣_$f, 可以断在这里查看这个函数的代码
发现就是两个参数相减,直接把函数调用改成相减即可

第四个报错是
代码中 _$lx = -0x25d9 + 0x24aa + -0x8 * -0x26 === _$lw ? this._map : this._map1;
是一个三目运算,其实就是等于 this._map1,而 this._map1是有值的,直接写死即可
最终执行结果如下,和浏览器结果一样:
下面继续分析代码,还是在encode函数,case 9的位置断住了
调用了split函数,把字符串拆分成长数组
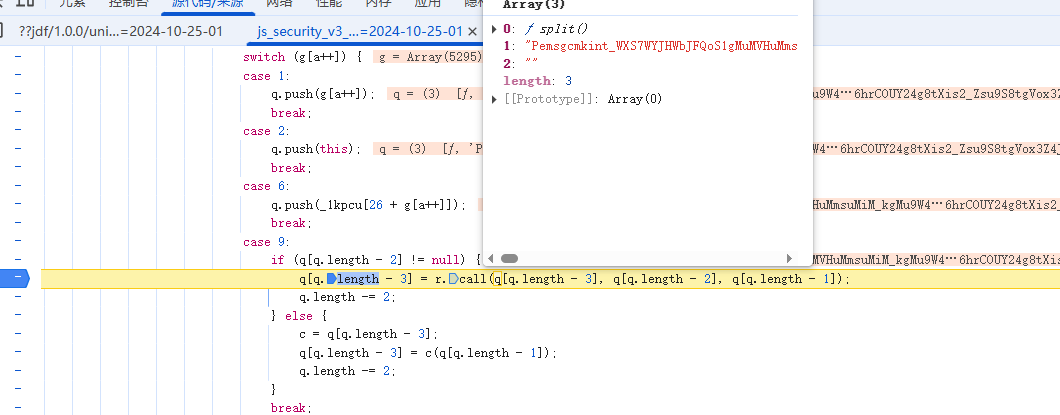
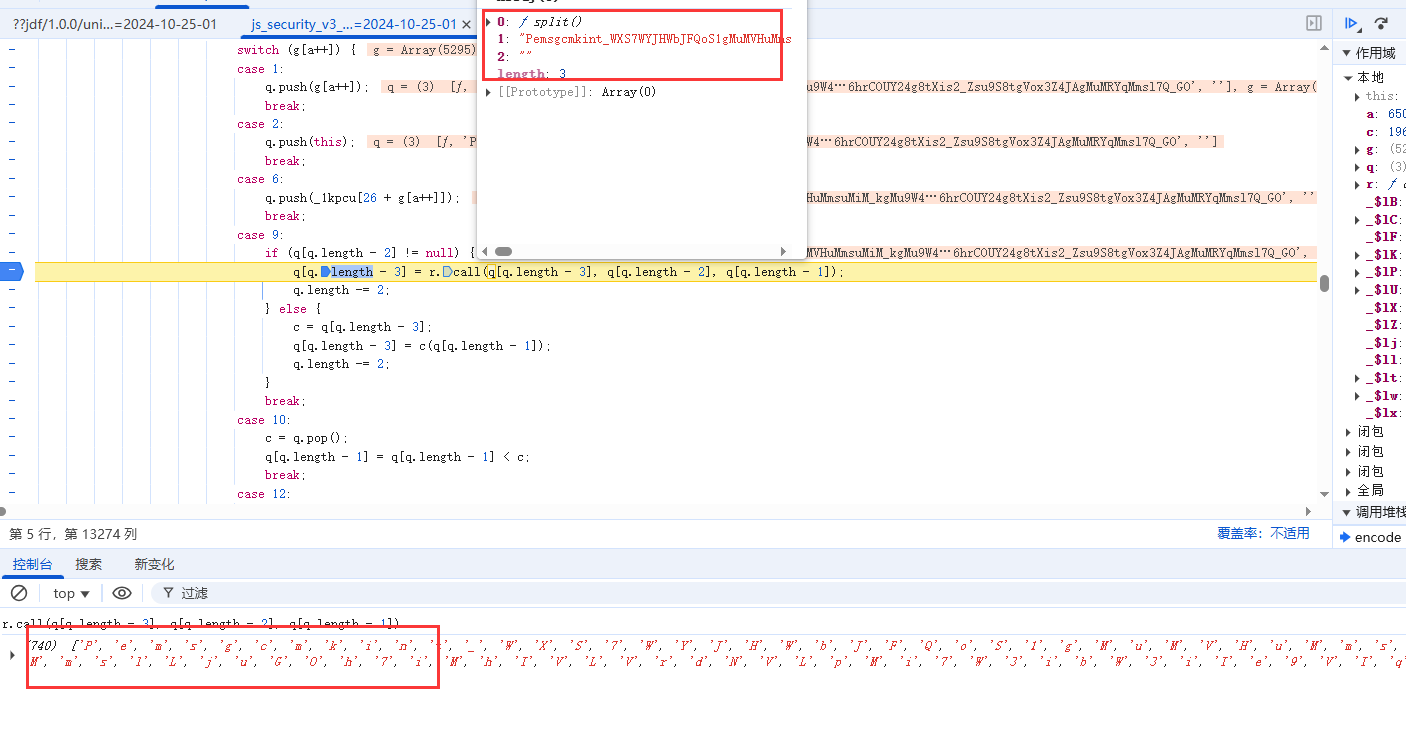
继续执行,在case 85 处断住:
这里看起来就很熟悉了,和之前ASCII数组重新排序一样,只不过这次是从前往后,每4个长度提取一次并添加到新数组中
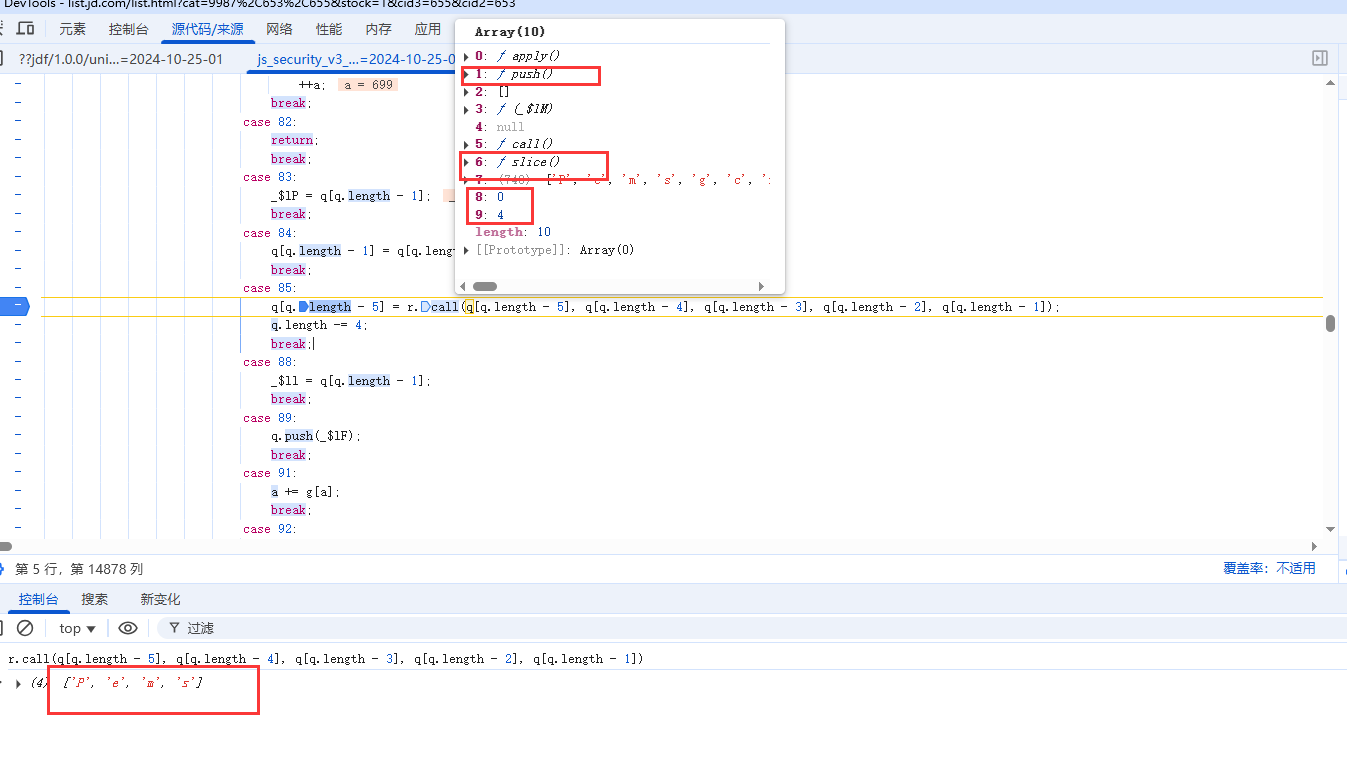
继续执行,在encode函数 case 9 中断住:
发现调用了reverse函数,重新排序后,又添加到新数组
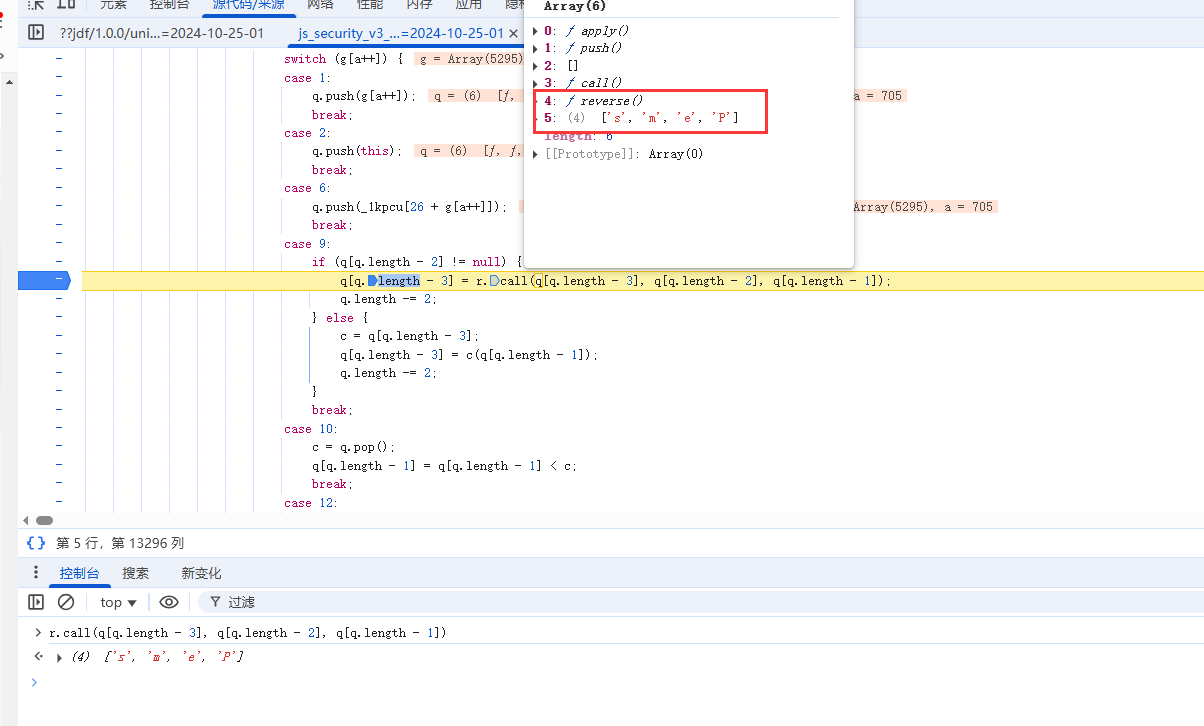
所以可以得到一个规律:
经过stringfy1函数得到文本数组后,从前往后每4个长度提取一次,并且提取后需要倒序排列,然后添加到新数组中。然后数组拼接,得到最终的p8参数
还原代码如下:
function str_orderby(arr) {const result = [];// 从前往后按每 4 个元素一组进行遍历for (let i = 0; i < arr.length; i += 4) {// 提取从 i 到 i + 4 的元素,如果不足 4 个则提取剩余元素const group = arr.slice(i, i + 4);// 将提取的元素组倒序后添加到结果数组result.push(...group.reverse());}return result;
}到这里为止,我们先初步总结一下指纹参数的加密流程:
① 文本转32位数组
② 32位数组转ASCII码,得到arr1
③ 经过验证, 1、2步可以直接合并为 文本转ASCII码 得到arr2

④ 补数组长度直到3的倍数为止,不足则push 2

⑤从后往前,每3个单位提取一次,并添加到新数组中,得到arr3

⑥arr3调用toWordArray函数,得到新的32位数组 arr4

⑦arr4 调用stringfy1函数,得到文本

⑧文本转成数组之后,重新排序(从前往后每4个长度提取一次,并且提取之后倒序排列,添加到新数组中),得到最终结果

后面会继续讲解h5st其他参数的纯算版本,在JS逆向进阶案例中发布