PyTorch入门-Transorforms
Transorforms
在计算机视觉和深度学习中,transforms 通常指的是对图像数据进行的各种预处理和增强操作。这些变换可以改善模型的训练效果和性能。常见的 transforms 包括:
- 调整大小 (Resize):改变图像的尺寸,以适应模型的输入要求。
- 裁剪 (Crop):从图像中提取出感兴趣的部分,去除不必要的区域。
- 翻转 (Flip):水平或垂直翻转图像,增加数据的多样性。
- 旋转 (Rotate):将图像按一定角度旋转,有助于模型学习不同方向的特征。
- 归一化 (Normalization):调整图像的像素值,使其分布更均匀,通常是减去均值并除以标准差。
- 颜色抖动 (Color Jitter):随机改变图像的亮度、对比度、饱和度等,以增强模型的鲁棒性。
- 噪声添加 (Add Noise):在图像中添加随机噪声,用于提高模型对噪声的抵抗力。
这些变换通常被应用于训练数据集,以便在训练过程中生成更多样化的数据,从而提高模型的泛化能力。在PyTorch中,torchvision.transforms模块提供了丰富的图像变换功能,可以方便地应用于数据集。
Normalize
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter# 导入SummaryWriter用于记录训练过程中的图像信息
writer = SummaryWriter("logs")
# 指定训练集中的蚂蚁图像路径
image_path = "data/train/ants_image/0013035.jpg"# 打开图像文件
img = Image.open(image_path)
# 创建一个将图像转换为张量的变换
tensor_trans = transforms.ToTensor()
# 应用变换,将图像转换为张量
tensor_img = tensor_trans(img)
# 将图像张量记录到日志中
writer.add_image("tensor_img", tensor_img)# 打印图像张量的第一个像素值,以验证张量内容
print(tensor_img[0][0][0]) # tensor(0.3137)
# 创建一个标准化变换,将图像像素值标准化到(-1, 1)区间
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
# 应用标准化变换
img_norm = trans_norm(tensor_img)
# 打印标准化后的图像张量的第一个像素值,以验证标准化效果
print(img_norm[0][0][0]) # tensor(-0.3725)# 将标准化后的图像记录到日志中
writer.add_image("Normalize", img_norm)
# 关闭SummaryWriter
writer.close()
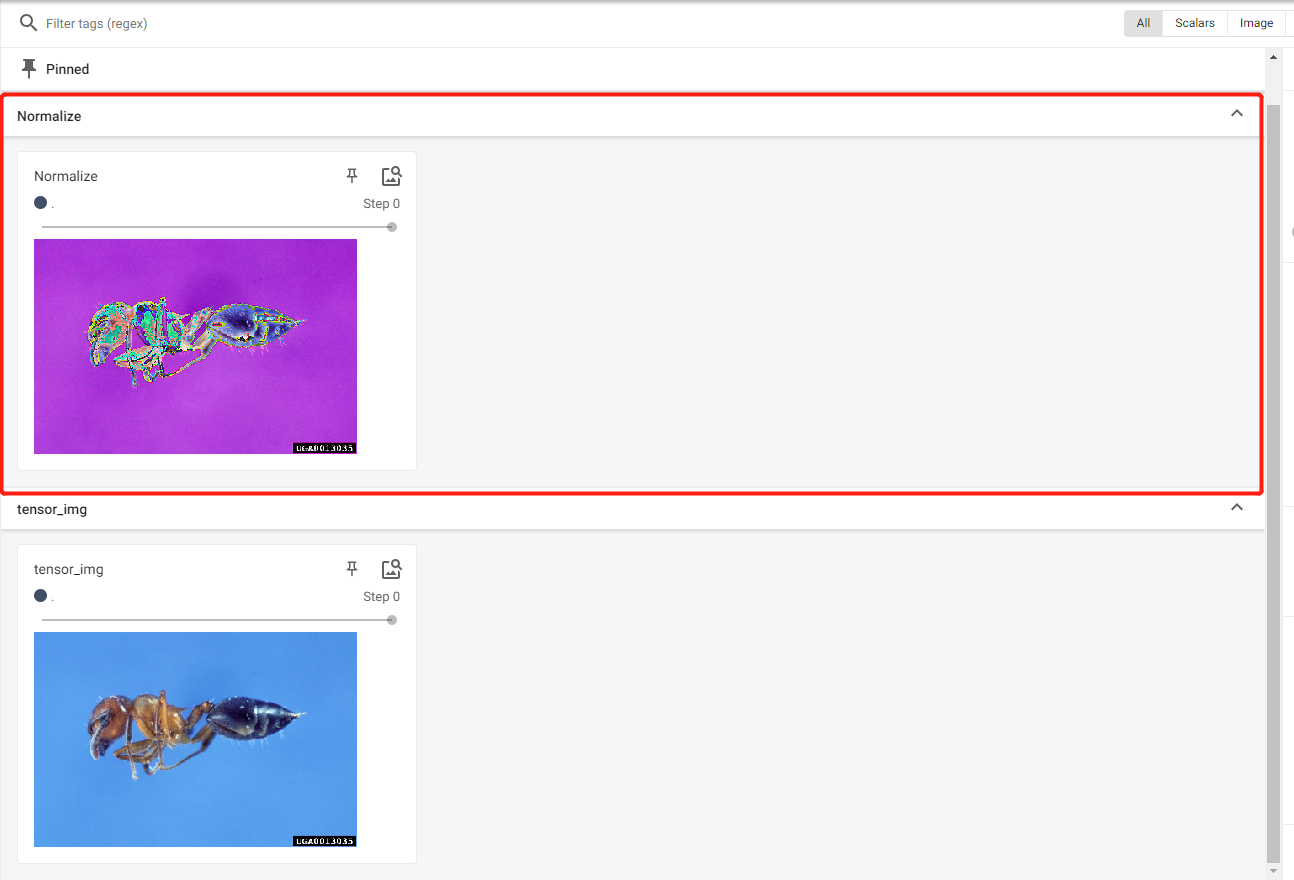
可以看到归一化后的图片
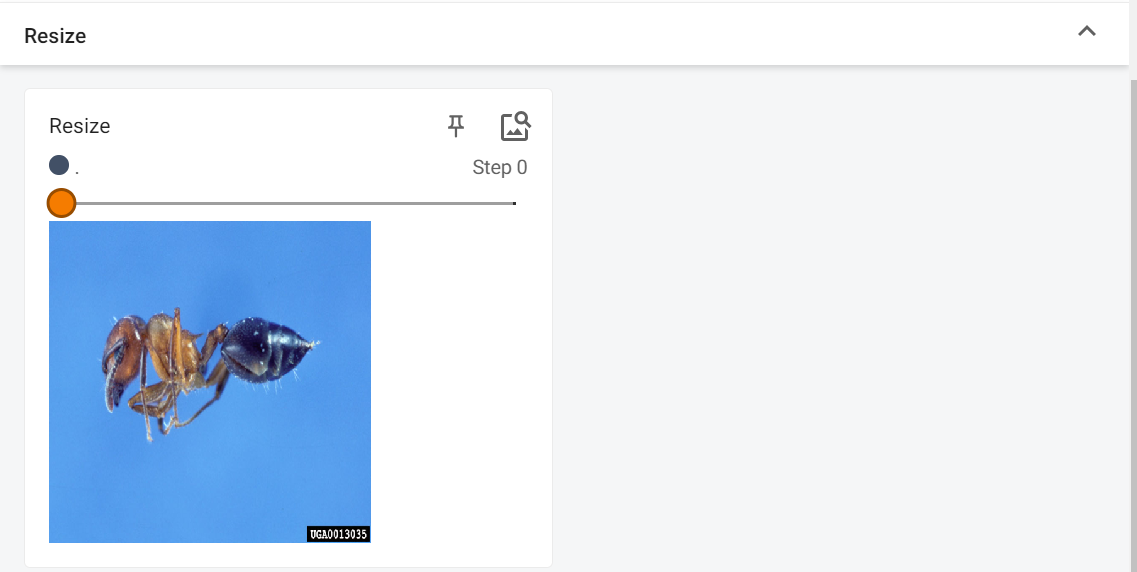
Resize
# 实例化了一个名为img的图像对象,打印出其原始信息:格式为JPEG,RGB模式,尺寸为768x512
print(img) # <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=768x512 at 0x20638BB10F0>
# 创建一个图像变换对象trans_resize,将所有图像resize到512x512
trans_resize = transforms.Resize((512, 512))
# 使用trans_resize对img进行处理,得到resize后的图像img_resize
img_resize = trans_resize(img)
# 打印出resize后图像的信息:RGB模式,尺寸为512x512
print(img_resize) # <PIL.Image.Image image mode=RGB size=512x512 at 0x206334FA9B0>
# 将resize后的图像img_resize转换为Tensor格式
img_resize = trans_toTensor(img_resize)
# 使用writer对象将resize后的图像添加到日志中,标记为"Resize",这是第0步
writer.add_image("Resize", img_resize,0)# 初始化一个transforms.Resize对象,将图像大小调整到512
trans_resize_2 = transforms.Resize(512)
# 初始化一个transforms.Compose对象,将多个transforms操作组合在一起
# 这里组合的操作包括上一步的resize和接下来的将图像转换为张量的操作
trans_compose = transforms.Compose([trans_resize_2, trans_toTensor])
# 使用组合的操作对图像进行预处理
# 这里img是一个PIL图像对象,经过resize和toTensor操作后,得到img_resize_2
img_resize_2 = trans_compose(img)
# 使用TensorBoard的writer对象添加图像到TensorBoard的可视化图表中
# 这里"Resize"是图表中的图像标签,img_resize_2是处理后的图像数据,1是全局步数
writer.add_image("Resize", img_resize_2, 1)
启动TensorBoard,查看Resize下的图片,拖动Step,可以看到0,1 的图片对比
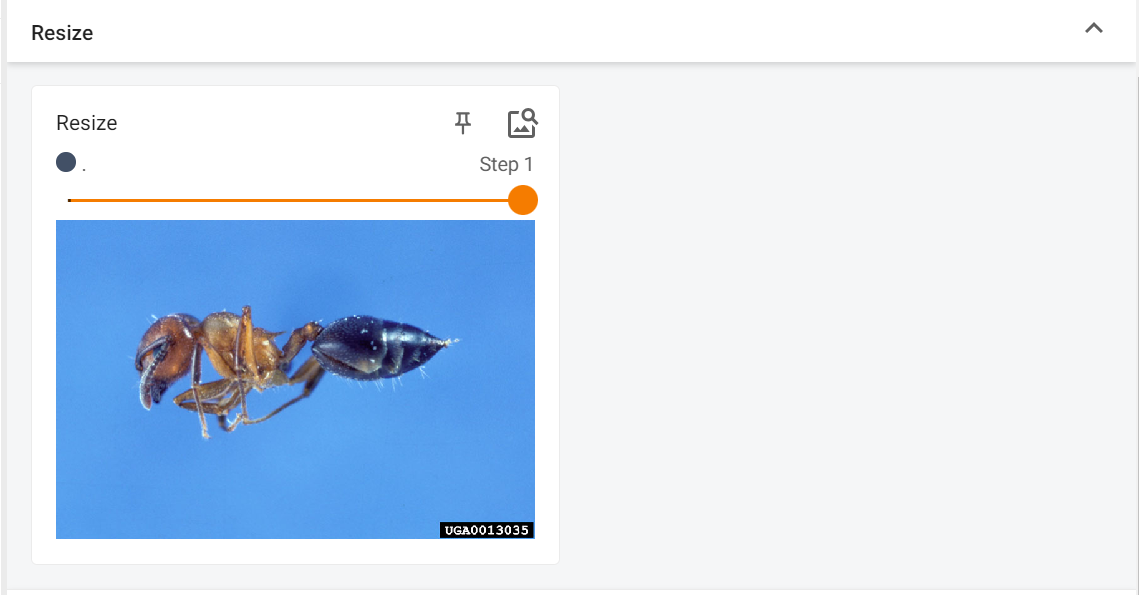
上述案例运用了transforms.Compose在深度学习中,transforms.Compose 是一个常用的工具,尤其是与 PyTorch 框架搭配使用时。它的主要功能是将多个图像转换操作组合在一起,以便在数据预处理或增强阶段简化代码。
主要用途:
- 组合多个变换:
Compose允许用户将多个数据变换操作(如缩放、裁剪、归一化等)一次性应用于输入数据。这样,用户可以按顺序应用这些变换,而不需要单独调用每个变换。 - 简化数据预处理:通过使用
Compose,代码更加整洁和易读,尤其是在需要对训练和测试数据应用相同变换时。 - 灵活性:用户可以根据需要自由添加、删除或更改变换操作的顺序,从而方便地调整数据处理流程。
from torchvision import transforms# 定义一系列变换
transform = transforms.Compose([transforms.Resize((256, 256)), # 缩放到256x256transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 转换为张量transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 归一化
])
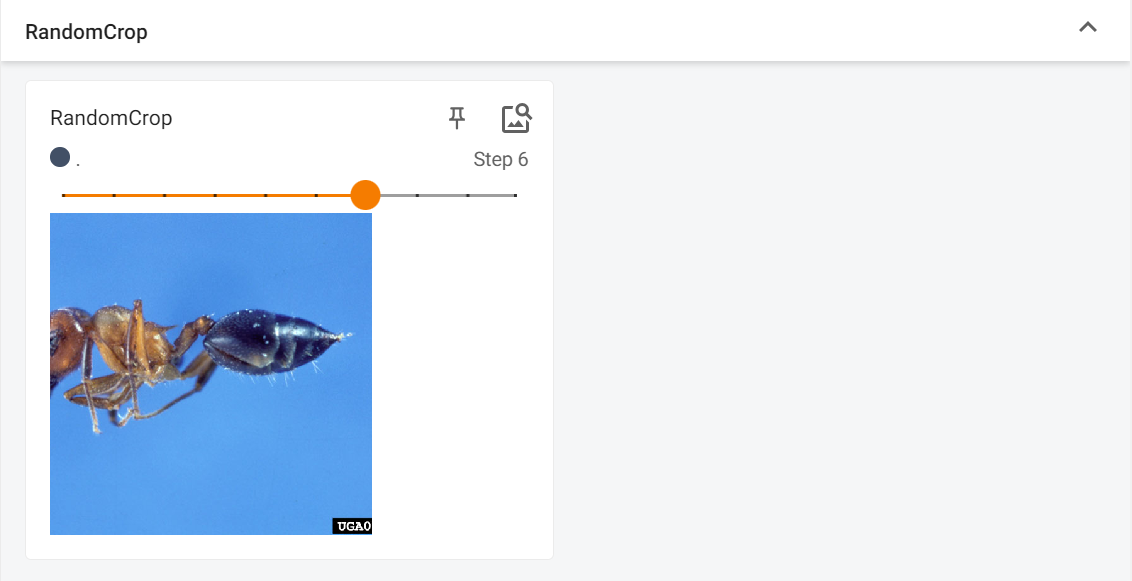
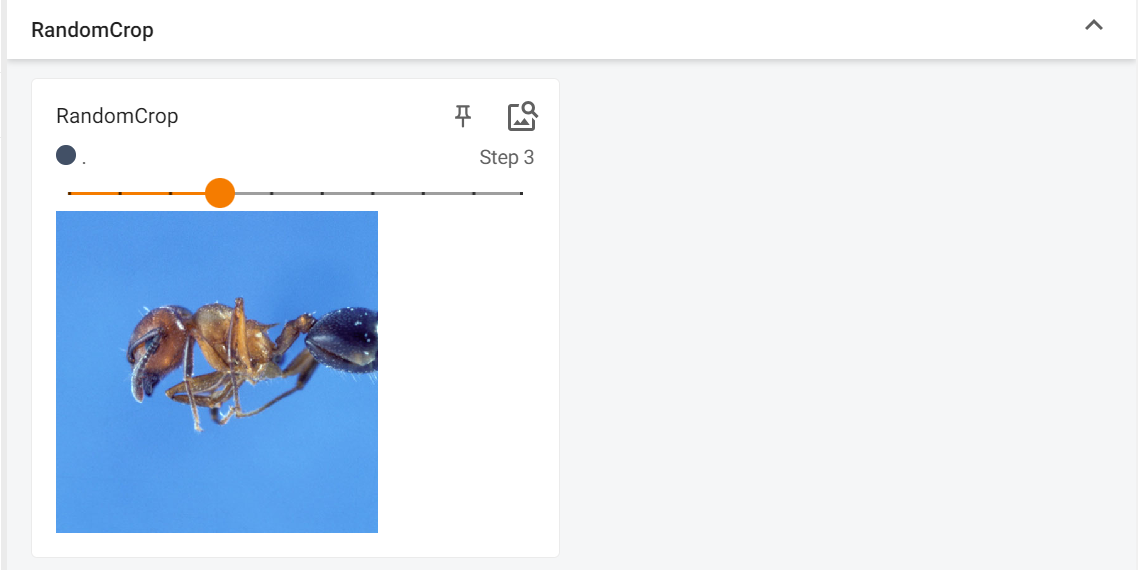
RandomCrop
下方的代码片段中,我们对一张图片进行随机裁剪,重复10次,可以通过TensorBoard看到我们处理过的图片
# 使用RandomCrop类初始化一个随机裁剪转换器,目标尺寸为512x512像素
trans_randomCrop = transforms.RandomCrop((512,512))
# 构建一个包含随机裁剪和转为张量操作的转换流程
trans_compose_2 = transforms.Compose([trans_randomCrop, trans_toTensor])
# 循环10次,每次对图像进行随机裁剪并记录结果
for i in range(10):img_randomCrop = trans_compose_2(img)writer.add_image("RandomCrop", img_randomCrop, i)