一周学会Pandas2之Python数据处理与分析-Pandas2数据合并与对比-df.combine():元素级合并
锋哥原创的Pandas2 Python数据处理与分析 视频教程:
2025版 Pandas2 Python数据处理与分析 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili

df.combine():元素级合并
df.combine() 是 pandas 中用于 按元素合并两个 DataFrame 的灵活方法,允许通过自定义函数处理重叠或冲突的值。与 merge、join 等基于索引或列对齐的合并不同,combine() 更适用于元素级别的精细化合并逻辑。以下是详细说明及示例:
基本语法:
DataFrame.combine(other, # 另一个 DataFrame 或 Seriesfunc, # 合并函数,定义如何组合两个元素fill_value=None, # 缺失值的填充值(默认 NaN)overwrite=True # 是否用 other 的值覆盖当前 DataFrame 的非空值
)核心功能
-
元素级合并:对两个 DataFrame 的每个元素应用
func函数,决定最终值。 -
覆盖逻辑:
-
若
overwrite=True(默认),当other的值非空时,优先使用other的值。 -
若
overwrite=False,只有当当前 DataFrame 的值为空时,才使用other的值。
-
-
索引对齐:合并时按行和列索引对齐,缺失位置用
fill_value填充。
参数说明
| 参数 | 说明 |
|---|---|
func | 接受两个标量参数(当前元素和 other 的元素),返回合并后的值的函数 |
fill_value | 对齐索引时,缺失位置的填充值(默认 NaN) |
overwrite | 是否允许 other 的非空值覆盖当前 DataFrame 的非空值(默认 True) |
常用场景示例
1,基本合并(优先保留 other 的值)
import pandas as pd
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}, index=[0, 1, 2])
df2 = pd.DataFrame({'A': [10, 20, 30], 'B': [40, 50, 60]}, index=[1, 2, 3])
# 默认 overwrite=True,用 df2 的值覆盖 df1
result = df1.combine(df2, lambda x, y: y)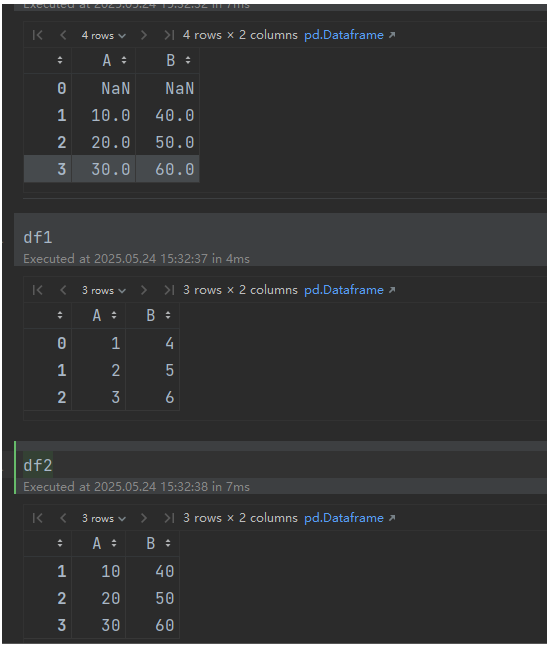
2,自定义合并函数(例如取最大值)
import pandas as pd
df1 = pd.DataFrame({'A': [1, 2, 3],'B': [4, 5, 6]
})
df2 = pd.DataFrame({'A': [3, 2, 1],'B': [6, 5, 4]
})
def diff(x, y):return x - y
result = df1.combine(df2, func=diff)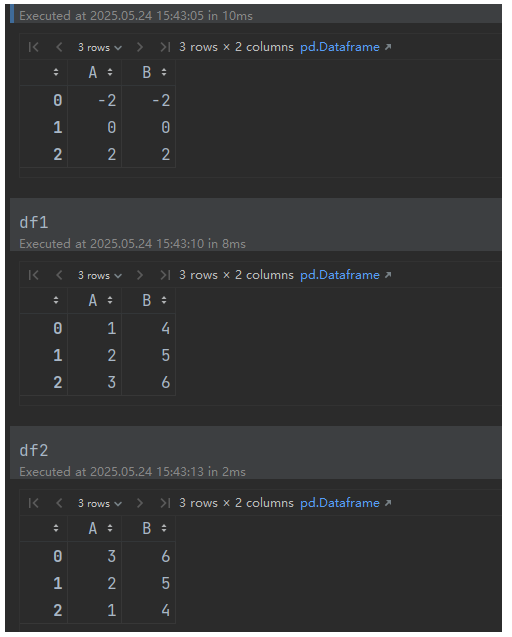
3, 处理缺失值(fill_value 参数)
import pandas as pddf1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}, index=[0, 1, 2])
df2 = pd.DataFrame({'A': [10, 20, 30], 'B': [40, 50, 60]}, index=[1, 2, 3])# 填充缺失值为0,再合并
result = df1.combine(df2, lambda x, y: x + y, fill_value=0)输出:
A B
0 1.0 4.0 # df2索引0缺失,视为0,结果1+0=1
1 22.0 55.0 # 2+20=22, 5+50=55
2 33.0 66.0 # 3+30=33, 6+60=66
3 30.0 60.0 # df1索引3缺失,视为0,结果0+30=30