R语言学习--Day08--bootstrap原理及误区
今天我们来学习统计学中一个很有意思的方法:bootstrap
bootstrap(自助法)
bootstrap是一种重采样统计方法,其核心思想是:
-
从原始数据中有放回地随机抽取样本,形成新的"虚拟"样本(称为bootstrap样本);
-
在每个bootstrap样本上计算我们感兴趣的统计量;
-
重复这个过程很多次(通常1000次或更多);
-
用这些统计量的分布来估计原始统计量的抽样分布。
操作听起来很简单,但我们要理解其背后的思想,这样才能知道什么时候用它以及,能带给我们什么帮助。
一般来讲,bootstrap只运用在数据量较少的样本集上,大概在30,极端点的话,5也有可能。那么这就会抛出一个疑问:既然是为了了解数据的分布,为什么还要多次有放回的抽取呢?
事实上,多次有放回的抽取,是为了避免数据中个别离散值对我们计算得到的统计指标的影响,因为是有放回的抽样,所以我们在多次的bootstrap抽样中,会出现同个数据点被多次采集的情况,相对应的,也就会削弱离散值的影响。
当然,到这里,我们依然无法解释为什么要抽样去看这些分布,可能有的人会问:明明数据量都这么少了,为什么不选择直接画图呢,这样可以更清晰地观察到数据本身的特点。让我们把重点放在“数据本身”,这就是bootstrap的核心使用意义了。
如果我们把关注的重点放在指标的可靠程度上,也就是置信度,那么我们也就不难理解bootstrap的操作步骤中,为什么要进行有放回的抽样,这是为了模拟我们在一个大样本中,抽样得到的样本集的置信区间,也就是模拟抽样这个过程的不确定性。举一个恰当点的例子说明就是,假如我是一名生态学家,我要在一片森林中布置五个样方用于测量生物量,实际上得到的数据,也就只有手头的五个指标的均值,而如果使用bootstrap对这五个指标进行计算,我们就可以估算出,在这篇森林中的不同位置设置5个样方,得到的均值会跟我们测算的均值差距有多大;如果用气温比喻,则是比如我们今天统计了气象站的数据得到了今天的平均气温是22℃,但全年的日平均气温的分布,会告诉我们22℃这个值是否属于异常值,是代表太热还是太冷。
下面我们照例生成一组数据来演示如何使用bootstrap:
set.seed(123)
# 真实总体:混合分布(主体分布+离群值)
true_strength <- c(rweibull(80, shape=2, scale=50), # 主体数据rweibull(20, shape=1, scale=120)) # 离群组分# 研究者实际获得的样本(n=15)
sample_strength <- sample(true_strength, 15)
print(sample_strength)par(mfrow=c(1,2))# 传统正态近似法
hist(sample_strength, main="原始数据分布", xlab="断裂强度", col="lightblue")
abline(v=median(sample_strength), col="red", lwd=2)# Bootstrap中位数分布
boot_medians <- replicate(1000, {new_sample <- sample(sample_strength, length(sample_strength), replace=TRUE)median(new_sample)
})
hist(boot_medians, main="Bootstrap中位数分布", xlab="中位数", col="lightgreen")
abline(v=median(sample_strength), col="red", lwd=2)# 基本Bootstrap
cat("原始中位数:", median(sample_strength), "\n")
cat("Bootstrap 95% CI:", quantile(boot_medians, c(0.025, 0.975)), "\n")# 使用boot包更精确计算
library(boot)
median_func <- function(data, indices) median(data[indices])
boot_results <- boot(sample_strength, statistic=median_func, R=1000)
boot.ci(boot_results, type="bca") # 偏差校正加速区间输出:
[1] 32.482421 45.166161 30.290634 14.461087 16.031943 80.447642 1.818878 96.234774[9] 60.469666 69.219757 44.472626 9.705244 244.186035 56.860091 37.333281
原始中位数: 44.47263
Bootstrap 95% CI: 30.29063 60.46967
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 1000 bootstrap replicates
95% (16.03, 56.86 )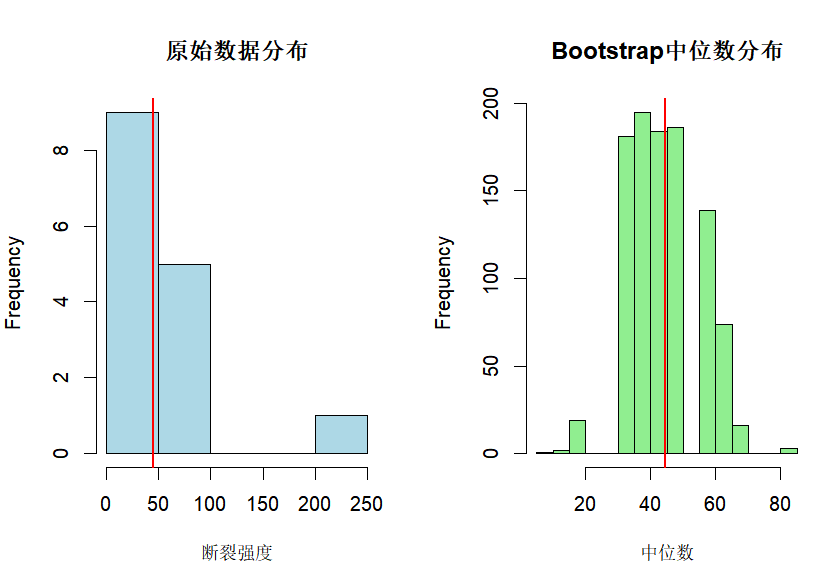
从图中可以看到,如果只是观察数据本身的分布,只能知道一个中位数,而bootstrap的反馈结果则是真是样本的中位数可能低至16.03或高至56.8。
所以说,本质上,当我们不确定原始数据长什么样,是否存在离散值或者分布很奇怪的时候,就可以用bootstrap来确定一些统计指标,这有助于我们更好的认识数据,打破我们一开始对数据的认知局限。