我用deepseek做了一个提取压缩文件夹下pdf和word文件工具
由于最近需要把大量的压缩文件的pdf和word文件统一复制到一个文件夹中。
我们一般正常操作方式的是把一个压缩文件一个一个解压,然后在把一个的解压好的文件夹下文件复制到另外一个文件夹中。
这个也需太繁琐了,从以往统计的需要花费两个小时间,自从出了DeepSeek之后,就用DeepSeek帮我写一个工具,能快速地把压缩文件夹提取下
完整的代码:https://pan.quark.cn/s/cf6c0fed7e80

DeepSeepk开始回答
然后根据使用说操作
使用说明:
1、将上述代码保存为一个Python文件,例如extract_pdf_word.py
![]()
2、运行脚本:python extract_pdf_word.py
![]()
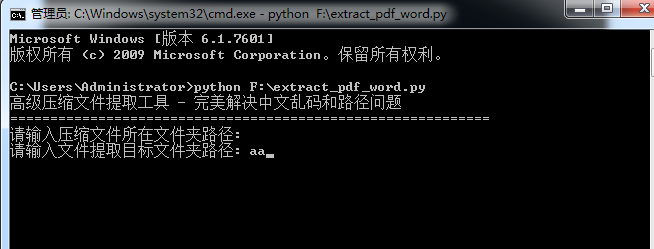
3、 按照提示输入源文件夹路径和输出文件夹路径
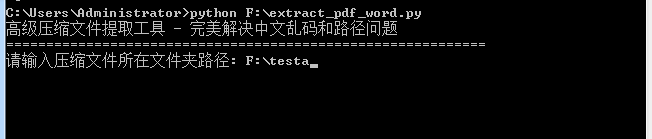
输入源文件夹的路径
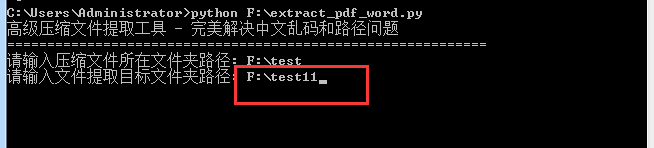
输入输出文件夹路径,然后回写即可
能看到打印日志信息:
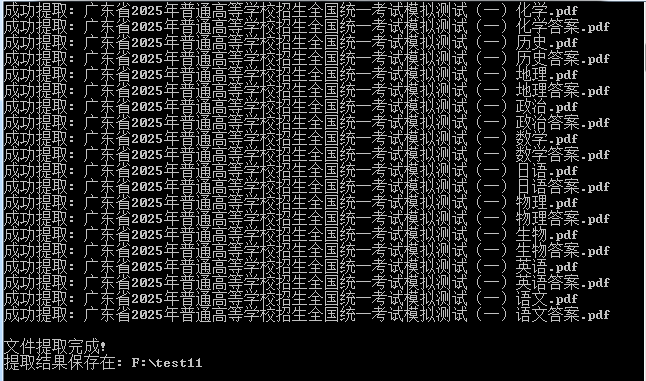
并到对应文件夹,已成功提取的pdf
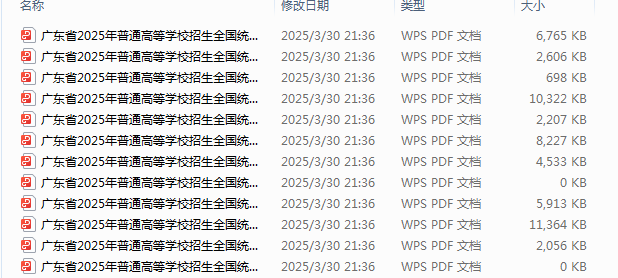
在整个操作中的由原来的几个小时要完成任务,缩短到了只需要5分钟的
功能说明
-
支持从ZIP和RAR压缩文件中提取内容
-
只提取PDF(.pdf)和Word(.doc, .docx)文件
-
自动处理文件名冲突(如果同名文件存在,会自动添加数字后缀)
-
错误处理机制,避免因单个文件问题导致整个程序中断