并发编程之异步线程池
并发编程之异步线程池
JDK学习思路
积累:有基层知识再到封装的工具类,足够多的“因”才能推理出“果”;
思路:从顶层看使用,从底层看原理;
结语:多线程编程中,不变的是内存模型和线程通信这两个核心的技术点,变换的是各种程序设计想法(算法)
多线程的使用场景
什么时候使用多线程
-
场景1:批量处理任务
- 向大量(100w以上)的用户发送邮件
- 处理大批量文件
- 处理大文件时,文件分段处理
-
场景2:实现异步
- 快速响应用户,进入浏览器请求网页、图片时
- 自动作业处理
-
场景3:增大吞吐量
- tomcat、数据库等服务
多线程应用场景特点
总的执行时间,取决于执行最慢的逻辑;
逻辑之间无依赖关系,可同时执行,则可以应用多线程技术进行优化
异步线程
Callable和Runnable区别
**思考:**Thread执行的时Runnable的接口,Callable的返回值怎么来的?
FutureTask:是一个Runnable的实现,通过构造函数把Callable传递进来,又通过Thread包装启动,调用FutureTask的run方法,在FutureTask的run方法中调用Callable的call方法,同时在FutureTask中处理返回值
区别:
- Callable、Runnable都是任务执行接口;
- Callable的call方法有返回值,Runnable的run方法没有返回值;
- Callable的call方法返回值可以泛型化,创建时指定返回值类型;
- Callable的call方法抛出异常;Runnable的run方法不抛出异常;
- Callable可以获取执行状态,Runnable不可以获取执行状态;
联系:
- Callable的call方法实际的执行在Runnable的run方法中;
- Runnable的实例对象需要Thread包装启动;
- Callable先通过FutureTask(Runnable)包装一下,再丢给Thread执行;
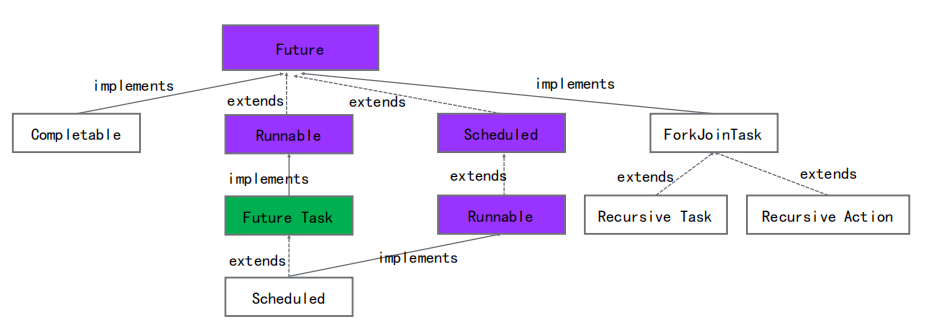
Future
Future介绍
Future表示异步计算的结果,提供了用于检查计算是否完成、等待计算完成以及获取结果的方法
public interface Future<V> {/*** 尝试取消任务,如果任务已经完成、已取消或其他原因无法取消,则失败。* 1、如果任务还没开始执行,则该任务不应该运行* 2、如果任务已经开始执行,由参数mayInterruptIfRunning来决定执行该任务的线程是否应该被中断,这只是终止任务的一种尝试。若mayInterruptIfRunning为true,则会立即中断执行任务的线程并返回true,若mayInterruptIfRunning为false,则会返回true且不会中断任务执行线程。* 3、调用这个方法后,以后对isDone方法调用都返回true。* 4、如果这个方法返回true,以后对isCancelled返回true。*/boolean cancel(boolean mayInterruptIfRunning);/*** 判断任务是否被取消了,如果调用了cance()则返回true*/boolean isCancelled();/*** 如果任务完成,则返回ture* 任务完成包含正常终止、异常、取消任务。在这些情况下都返回true*/boolean isDone();/*** 线程阻塞,直到任务完成,返回结果* 如果任务被取消,则引发CancellationException* 如果当前线程被中断,则引发InterruptedException* 当任务在执行的过程中出现异常,则抛出ExecutionException*/V get() throws InterruptedException, ExecutionException;/*** 线程阻塞一定时间等待任务完成,并返回任务执行结果,如果则超时则抛出TimeoutException*/V get(long timeout, TimeUnit unit)throws InterruptedException, ExecutionException, TimeoutException;
}
future使用
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;public class FutureDemo {public static void main(String[] args) {FutureDemo futureDemo = new FutureDemo();ExecutorService executorService = Executors.newFixedThreadPool(3);List<Callable<String>> callableList = new ArrayList<>();Callable<String> callable1 = new Callable<String>() {@Overridepublic String call() throws Exception {return futureDemo.test1();}};callableList.add(callable1);Callable<String> callable2 = new Callable<String>() {@Overridepublic String call() throws Exception {return futureDemo.test2();}};callableList.add(callable2);Callable<String> callable3 = new Callable<String>() {@Overridepublic String call() throws Exception {return futureDemo.test3();}};callableList.add(callable3);try {List<Future<String>> futures = executorService.invokeAll(callableList);for (Future<String> future : futures) {String s = null;try {s = future.get();future.get();} catch (ExecutionException e) {e.printStackTrace();}System.out.println(s);}} catch (InterruptedException e) {e.printStackTrace();} finally {executorService.shutdown();}executorService.submit(() -> System.out.println("1111"));System.out.println("结束");}public String test1(){try {Thread.sleep(1000L);} catch (InterruptedException e) {e.printStackTrace();} finally {}return "1";}public String test2(){try {Thread.sleep(2000L);} catch (InterruptedException e) {e.printStackTrace();} finally {}return "2";}public String test3(){try {Thread.sleep(3000L);} catch (InterruptedException e) {e.printStackTrace();} finally {}return "3";}
}
FutureTask
FutureTask介绍
Future只是一个接口,不能直接用来创建对象,其实现类是FutureTask,JDK1.8修改了FutureTask的实现,JKD1.8不再依赖AQS来实现,而是通过一个volatile变量state以及CAS操作来实现。FutureTask结构如下所示:
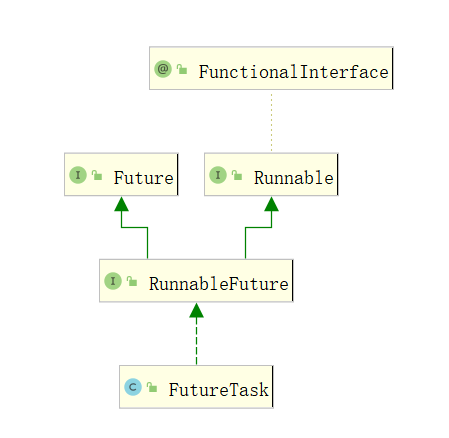
FutureTask的实现:
public class FutureTask<V> implements RunnableFuture<V>{//......
}
模拟FutureTask的MyFutureTask
MyFutureTask
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.Callable;
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.locks.LockSupport;public class MyFutureTask<T> implements Runnable {private Callable<T> target;private T result;private String state = "";private BlockingQueue<Thread> blockingQueue = new LinkedBlockingQueue<>();public MyFutureTask(Callable<T> target) {this.target = target;state = "NEW";}@Overridepublic void run() {try {this.result = target.call();state = "DONE";} catch (Exception e) {e.printStackTrace();} finally {if ("DONE".equals(this.state)) {for (; ; ) {Thread t = blockingQueue.poll();if (t != null) {System.out.println("线程 "+t.getName()+" 将被唤醒");LockSupport.unpark(t);} else {break;}}}}}public T get() {if (!"DONE".equals(this.state)) {System.out.println("将线程 "+Thread.currentThread().getName()+" 加入等待队列");blockingQueue.add(Thread.currentThread());}while (!"DONE".equals(this.state)) {System.out.println("将线程 "+Thread.currentThread().getName()+" park");LockSupport.park();}System.out.println("线程 "+Thread.currentThread().getName()+" 将获取导致");return result;}
}
MyFutureTaskDemo
public class MyFutureTaskDemo {public static void main(String[] args) {MyFutureTask<String> stringMyFutureTask = new MyFutureTask<>(() -> {Thread.sleep(10000L);return "从数据库获取到了数据:{name:张三}";});Thread thread = new Thread(stringMyFutureTask);thread.start();
// String s = stringMyFutureTask.get();
// System.out.println(Thread.currentThread().getName() + " " + s);Thread thread1 = new Thread(() -> {
// LockSupport.parkNanos(1000 * 1000 * 1000 * 1);String s1 = stringMyFutureTask.get();System.out.println(Thread.currentThread().getName() + " " + s1);},"线程1");Thread thread2 = new Thread(() -> {
// LockSupport.parkNanos(1000 * 1000 * 1000 * 2);String s1 = stringMyFutureTask.get();System.out.println(Thread.currentThread().getName() + " " + s1);},"线程2");thread2.start();thread1.start();}
}//输出结果,如下:
将线程 线程2 加入等待队列
将线程 线程1 加入等待队列
将线程 线程2 park
将线程 线程1 park
线程 线程2 将被唤醒
线程 线程1 将被唤醒
线程 线程2 将获取导致
线程 线程1 将获取导致
线程1 从数据库获取到了数据:{name:张三}
线程2 从数据库获取到了数据:{name:张三}
线程池
思考
假设有1000万个文件,需要进行扫描,是不是用多线程并行完成?
线程池,JDK线程池是怎么实现的?线程数据量能否实现自动伸缩?
线程池实现过程?影响的参数配置?
Executors中4个方法的诟病
JDK定时任务两种实现的区别
是不是线程数量越多越好?
不是,那么多少个线程数合适?类似的数据库配置多少个连接合适?
看系统的整体性能
看CPU*2
按业务需要来,需要测试
为什么要用线程池
线程是不是越多越好?
1、线程不仅java中是一个对象,每个线程都有自己的工作内存,
> 线程创建、销毁需要时间,消耗性能。
> 线程过多,会占用很多内存
2、操作系统需要频繁切换线程上下文(大家都想被运行),影响性能。
3、如果创建时间+ 销毁时间 > 执行任务时间 就很不合算
线程池的推出,就是为了方便的控制线程数量
线程池概念
- 线程池管理器:用于创建并管理线程池,包含创建线程池,销毁线程池,添加新任务;
- 工作线程:线程池中的线程,可以循环的执行任务,在没有任务的时候处于等待状态;
- 任务接口:每个任务必须实现的接口,以供工作线程调度任务的执行;
- 任务队列:用于存放没有处理的任务,提供一种缓存机制;
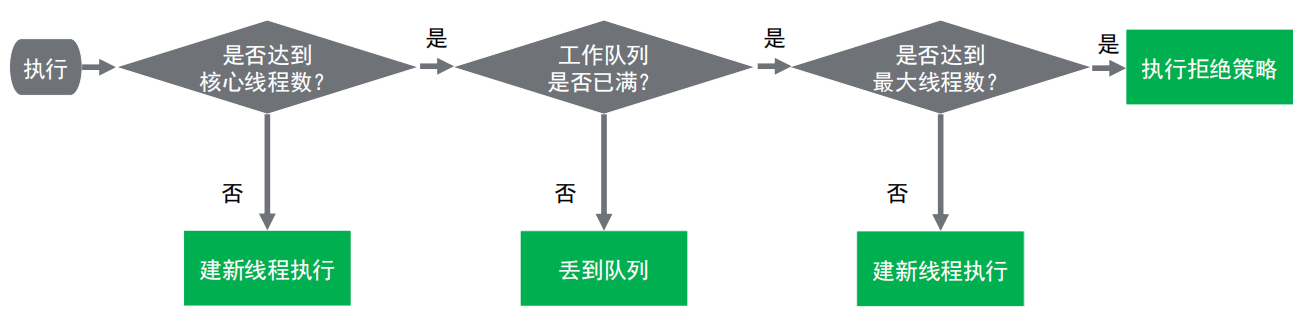
线程池原理
线程池任务执行过程
- 是否达到核心线程数量?没有达到,创建一个工作线程来执行任务。
- 工作队列是否已满?没有满,则将新提交的任务存储在工作队列中。
- 是否达到线程池的最大线程数量?没有达到,则创建一个新的工作线程来执行任务。
- 以达到最大线程数量,执行拒绝策略来处理这个任务。
核心线程是提前准备好的,也就是说是提前创建好的
核心线程数和非核心线程数本质上是没有区别的
任务场景
-
任务要求:大任务有3个小人物,3个小任务按照顺序执行
线程:数量,必须是一个
队列:FIFO,按照顺序来
corePoolSize :1,maxSize :1,null,null,无界队列
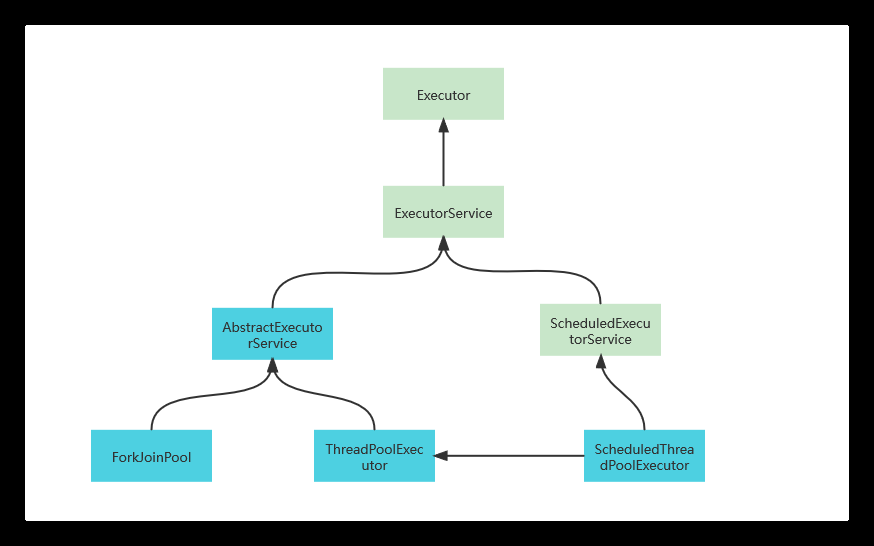
线程池类的层次结构
| 类型 | 名称 | 描述 |
|---|---|---|
| 接口 | Executor | 最上层的接口,只定义了execute方法 |
| 接口 | ExecutorService | 继承了Executor接口,拓展了Callable 、Future、关闭方法 |
| 接口 | ScheduledExecutorService | 继承了ExecutorService接口,增加了定时任务相关的方法 |
| 实现 | ThreadPoolExecutor | 基础、标准的线程池实现类 |
| 实现 | ScheduledThreadPoolExecutor | 继承ThreadPoolExecutor类,实现了ScheduledExecutorService的相关定时任务的方法 |
类之间的关系如下:
线程池API
ExecutorService接口
| 方法 | 备注 |
|---|---|
| shutdown() | 在完成已提交的任务后关闭服务,不再接受新任,优雅关闭 |
| shutdownNow() | 立即关闭 |
| awaitTermination(long timeout, TimeUnit unit) | 等待指定时间关闭 |
| isTerminated() | 测试是否所有任务都执行完毕了 |
| isShutdown() | 测试是否该ExecutorService已被关闭 |
| invokeAll(Collection<? extends Callable> tasks) | 批量执行 |
| invokeAll(Collection<? extends Callable> tasks, long timeout, TimeUnit unit) | 批量执行 |
| invokeAny(Collection<? extends Callable> tasks) | 批量执行 |
| invokeAny(Collection<? extends Callable> tasks, long timeout, TimeUnit unit) | 批量执行 |
| submit(Callable task) | 提交Callable任务到线程池,返回Future对象,调用Future对象get()方法可以获取Callable的返回值; |
| submit(Runnable task) | 提交Runnable任务到线程池,返回Future对象,由于Runnable没有返回值,也就是说调用Future对象get()方法返回null; |
| submit(Runnable task, T result) | 提交Runnable任务到线程池,返回Future对象,调用Future对象get()方法可以获取Runnable的参数值; |
| void execute(Runnable command); |
ThreadPoolExecutor类
线程池核心使用到的类是J.U.C包下的ThreadPoolExecutor,它有4中构造函数,详细如下:
4中构造函数:
- 第一种:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue)
- 第二种:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory)
- 第三种:
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler)
- 第四种
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit,BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler)
构造函数的参数详解:
int corePoolSize:核心线程数
int maximumPoolSize:最大线程数
long keepAliveTime:多余空闲线程的最大时间,超过核心线程数的线程,超过空闲时间,线程将被销毁
TimeUnit unit:时间单位
BlockingQueue workQueue:任务队列
ThreadFactory threadFactory:线程工厂,修改线程名称等
RejectedExecutionHandler handler:拒绝策略
RejectedExecutionHandler handler:拒绝策略
线程池的拒绝策略是指当线程池无法接受新任务时,如何处理这些被拒绝的任务。ThreadPoolExecutor提供了四种内置的拒绝策略,并且允许用户自定义拒绝策略
AbortPolicy(默认策略)
特点:当任务无法被线程池执行时,会抛出一个RejectedExecutionException异常。
使用场景:适用于对任务丢失敏感的场景,当线程池无法接受新任务时,希望立即知道并处理该异常。
/*** A handler for rejected tasks that throws a* {@code RejectedExecutionException}.*/
public static class AbortPolicy implements RejectedExecutionHandler {/*** Creates an {@code AbortPolicy}.*/public AbortPolicy() { }/*** Always throws RejectedExecutionException.** @param r the runnable task requested to be executed* @param e the executor attempting to execute this task* @throws RejectedExecutionException always*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {throw new RejectedExecutionException("Task " + r.toString() +" rejected from " +e.toString());}
}
CallerRunsPolicy
特点:当任务无法被线程池执行时,会直接在调用者线程中运行这个任务。如果调用者线程正在执行一个任务,则会创建一个新线程来执行被拒绝的任务。
使用场景:适用于可以容忍任务在调用者线程中执行的业务场景,它允许任务继续执行,而不会因为线程池资源不足而被丢弃。
/*** A handler for rejected tasks that runs the rejected task* directly in the calling thread of the {@code execute} method,* unless the executor has been shut down, in which case the task* is discarded.*/
public static class CallerRunsPolicy implements RejectedExecutionHandler {/*** Creates a {@code CallerRunsPolicy}.*/public CallerRunsPolicy() { }/*** Executes task r in the caller's thread, unless the executor* has been shut down, in which case the task is discarded.** @param r the runnable task requested to be executed* @param e the executor attempting to execute this task*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {r.run();}}
}
DiscardPolicy
特点:当任务无法被线程池执行时,任务将被直接丢弃,不抛出异常,也不执行任务。
使用场景:适用于对任务丢失不敏感的场景,当线程池无法接受新任务时,简单地丢弃被拒绝的任务。
/*** A handler for rejected tasks that silently discards the* rejected task.*/
public static class DiscardPolicy implements RejectedExecutionHandler {/*** Creates a {@code DiscardPolicy}.*/public DiscardPolicy() { }/*** Does nothing, which has the effect of discarding task r.** @param r the runnable task requested to be executed* @param e the executor attempting to execute this task*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {}
}
DiscardOldestPolicy
特点:当任务无法被线程池执行时,线程池会丢弃队列中最旧的未处理任务,然后尝试重新提交当前任务。
使用场景:适用于对新任务优先级较高的场景,当线程池无法接受新任务时,会丢弃一些等待时间较长的旧任务,以便接受新任务。
/*** A handler for rejected tasks that discards the oldest unhandled* request and then retries {@code execute}, unless the executor* is shut down, in which case the task is discarded.*/
public static class DiscardOldestPolicy implements RejectedExecutionHandler {/*** Creates a {@code DiscardOldestPolicy} for the given executor.*/public DiscardOldestPolicy() { }/*** Obtains and ignores the next task that the executor* would otherwise execute, if one is immediately available,* and then retries execution of task r, unless the executor* is shut down, in which case task r is instead discarded.** @param r the runnable task requested to be executed* @param e the executor attempting to execute this task*/public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {if (!e.isShutdown()) {e.getQueue().poll();e.execute(r);}}
}
自定义拒绝策略
除了上述四种内置的拒绝策略外,ThreadPoolExecutor还允许你通过实现RejectedExecutionHandler接口来定义自己的拒绝策略。这提供了极高的灵活性,可以根据具体需求定制拒绝任务的行为。
import java.util.concurrent.*;public class CustomRejectionPolicy implements RejectedExecutionHandler {@Overridepublic void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {// 在这里定义你的自定义处理逻辑System.out.println("Task " + r.toString() + " was rejected");// 可以选择记录日志、抛出异常、使用备用线程池执行等}public static void main(String[] args) {ThreadPoolExecutor executor = new ThreadPoolExecutor(2, 2, 0L, TimeUnit.MILLISECONDS,new LinkedBlockingQueue<>(2),new CustomRejectionPolicy());// 提交任务...}
}基于ThreadPoolExecutor的Executors工具类
JDK给我们提供了一个工具类Executors来创建线程池的工厂类,其内部实现是ThreadPoolExecutor类,具体如下:
-
newFixedThreadPool(int nThreads):创建一个固定大小、任务队列容量无界的线程池。核心线程数=最大线程数。
-
newCachedThreadPool():创建的是一个大小无界的缓冲线程池,它的任务队列是一个同步队列,任务加入到池中,如果池中有空闲线程,则用空闲线程执行,如无则创建新线程执行。池中的线程空闲超过60秒,将被销毁释放。线程数随任务的多少变化。适用于执行耗时较小的异步任务。池的核心线程数=0 ,最大线程数=Integer.MAX_VALUE
-
newSingleThreadScheduledExecutor():只有一个线程来执行无界任务队列的单一线程池。该线程池确保任务按加入的顺序一个一个依次执行。当唯一的线程因任务异常中止时,将创建一个新的线程来继续执行后续的任务。与newFixedThreadPool(1)的区别在于,单一线程池的池大小在newSingleThreadExecutor方法中硬编码,不能再改变的。
-
newScheduledThreadPool(int corePoolSize):能定时执行任务的线程池。该池的核心线程数由参数指定,最大线程数= Integer.MAX_VALUE
ScheduledExecutorService接口
| 方法 | 备注 |
|---|---|
| schedule(Callable callable, long delay, TimeUnit unit) | 创建并执行 一次性定时任务 |
| schedule(Runnable command, long delay, TimeUnit unit) | 创建并执行 一次性定时任务 |
| scheduleAtFixedRate(Runnable command, long initialDelay, long period, TimeUnit unit) | 创建并执行一个固定周期的任务 |
| scheduleWithFixedDelay(Runnable command, long initialDelay, long delay, TimeUnit unit) | 创建并执行一个延期固定频率的任务 |
public class Demo1_ScheduledThreadPoolExecutor {static ScheduledThreadPoolExecutor pool =new ScheduledThreadPoolExecutor(5);public static void main(String[] args) throws Exception {//test1();//test2();test3();}// 提交一个 一次性任务private static void test1() throws Exception {//定义一个Runnable对象Runnable cmd = new Runnable() {@Overridepublic void run() {try {Thread.sleep(3000L);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("任务执行了。。。");}};//提交一个一次性任务pool.schedule(cmd, 3, TimeUnit.SECONDS);}//scheduleWithFixedDelay 提交一个重复执行的任务public static void test2(){Runnable cmd = new Runnable() {@Overridepublic void run() {LockSupport.parkNanos(1000 * 1000 * 1000 * 1L); //暂停一秒钟,和Thread.sleep(1000L) 效果类似System.out.println("任务执行,现在时间:" + System.currentTimeMillis());}};//提交定时任务pool.scheduleWithFixedDelay(cmd, 1000, 2000, TimeUnit.MILLISECONDS);}//scheduleAtFixedRate 提交一个重复执行的任务private static void test3() throws Exception {Runnable cmd = new Runnable() {@Overridepublic void run() {LockSupport.parkNanos(1000 * 1000 * 1000 * 1L); //暂停一秒钟,和Thread.sleep(1000L) 效果类似System.out.println("任务执行,现在时间:" + System.currentTimeMillis());}};pool.scheduleAtFixedRate(cmd, 1000, 2000, TimeUnit.MILLISECONDS);}
}
如何确定合适的线程数量
-
计算型任务:推荐 CPU 1- 2倍
Runtime.getRuntime().availableProcessors(); // 获取CPU核数 -
IO型任务:相对比计算型任务,需多一些线程,要根据具体的IO阻塞时长进行考量决定。也可考虑根据需要在一个最小数量和最大数量间自动增减线程数,需要根据实际情况来调整。
如Tomcat中默认的最大线程数为:200
参考:
- 【别再纠结线程池大小/线程数量了,没有固定公式的】https://maimai.cn/article/detail?fid=1652926366&efid=_0si6r7nw2Cq4Jb0KotK2g
Runnable() {
@Override
public void run() {
LockSupport.parkNanos(1000 * 1000 * 1000 * 1L); //暂停一秒钟,和Thread.sleep(1000L) 效果类似
System.out.println(“任务执行,现在时间:” + System.currentTimeMillis());
}
};
pool.scheduleAtFixedRate(cmd, 1000, 2000, TimeUnit.MILLISECONDS);}
}
### 如何确定合适的线程数量- 计算型任务:推荐 CPU 1- 2倍```javaRuntime.getRuntime().availableProcessors(); // 获取CPU核数-
IO型任务:相对比计算型任务,需多一些线程,要根据具体的IO阻塞时长进行考量决定。也可考虑根据需要在一个最小数量和最大数量间自动增减线程数,需要根据实际情况来调整。
如Tomcat中默认的最大线程数为:200
参考:
-
【别再纠结线程池大小/线程数量了,没有固定公式的】https://maimai.cn/article/detail?fid=1652926366&efid=_0si6r7nw2Cq4Jb0KotK2g
-
https://baijiahao.baidu.com/s?id=1781963409920502141&wfr=spider&for=pc