JUC入门(六)
12、四大函数式接口
Consumer<T>(消费者接口)
源码

功能
接收一个参数T,不返回任何结果。主要用于消费操作,例如打印日志、更新状态等。
使用场景
-
遍历集合并执行操作。
-
对象的字段赋值。
代码示例
import java.util.Arrays;
import java.util.List;public class ConsumerExample {public static void main(String[] args) {List<String> names = Arrays.asList("Alice", "Bob", "Charlie");// 使用Consumer接口打印每个名字names.forEach(name -> System.out.println(name));}
}Supplier<T>(供给者接口)
源码
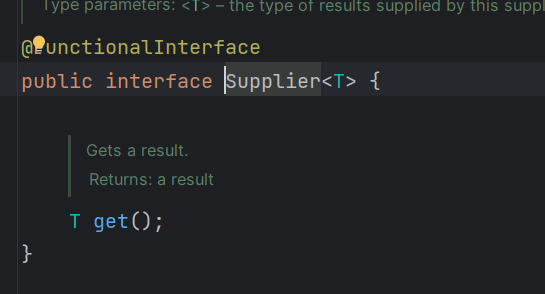
功能
不接收任何参数,返回一个T类型的值。主要用于生成数据。
使用场景
-
生成默认值或随机值。
-
提供数据源。
代码示例
import java.util.Random;public class SupplierExample {public static void main(String[] args) {// 使用Supplier接口生成随机整数Supplier<Integer> randomSupplier = () -> new Random().nextInt(100);// 获取随机整数System.out.println("Random Integer: " + randomSupplier.get());}
}Function<T, R>(函数接口)
源码
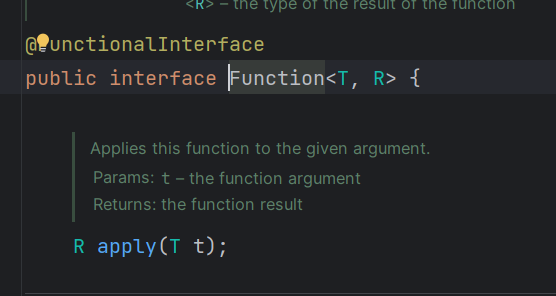
功能
接收一个T类型的参数,返回一个R类型的值。主要用于数据转换。
使用场景
-
数据类型转换。
-
数据处理和映射。
代码示例
package com.yw.FI;import java.util.function.Function;public class FunctionExample {public static void main(String[] args) {Function<String,String> function = (low) ->{return low.toUpperCase();};System.out.println(function.apply("abcdefg"));}
}
Predicate<T>(断言接口)
源码
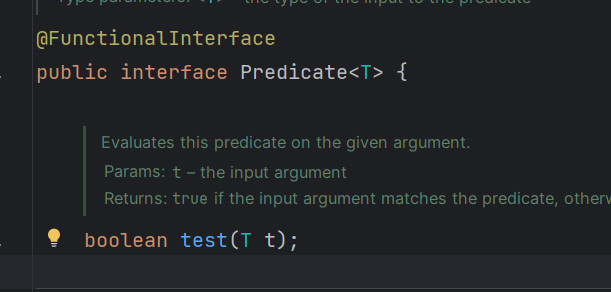
功能
接收一个T类型的参数,返回一个布尔值。主要用于条件判断。
使用场景
-
过滤数据。
-
条件判断。
代码示例
package com.yw.FI;import java.util.function.Predicate;public class PredicateExample {public static void main(String[] args) {Predicate<Integer> predicate = i -> i % 2 ==0;System.out.println(predicate.test(2));}
}
13、stream流式计算
基本操作分类
Stream API的操作主要分为两大类:中间操作和终端操作。中间操作是惰性执行的,它们返回一个新的Stream对象,可以继续进行链式操作;终端操作会触发整个Stream的实际计算,并返回一个结果
中间操作
filter(Predicate<? super T> predicate):根据条件过滤流中的元素。底层使用了Predicate函数式接口,该接口定义了一个test(T t)方法,用于判断一个元素是否满足特定条件。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> evenNumbers = numbers.stream().filter(n -> n % 2 == 0) // 使用Predicate.collect(Collectors.toList());map(Function<? super T, ? extends R> mapper):将流中的每个元素映射成另一种形式。底层使用了Function函数式接口,该接口定义了一个apply(T t)方法,用于将一个类型转换为另一个类型。
List<String> words = Arrays.asList("apple", "banana", "cherry");
List<String> upperWords = words.stream().map(String::toUpperCase) // 使用Function.collect(Collectors.toList());sorted()或sorted(Comparator<? super T> comparator):对流中的元素进行排序。sorted()方法默认使用自然排序,而sorted(Comparator)则允许自定义排序规则。底层使用了Comparator函数式接口,该接口定义了compare(T o1, T o2)方法。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
List<String> sortedNames = names.stream().sorted() // 自然排序.collect(Collectors.toList());distinct():去除流中的重复元素。该操作不直接使用函数式接口,但依赖于元素的equals()和hashCode()方法。
List<Integer> numbers = Arrays.asList(1, 2, 2, 3, 4, 4, 5);
List<Integer> uniqueNumbers = numbers.stream().distinct().collect(Collectors.toList());limit(long maxSize):限制流中元素的数量。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> limitedNumbers = numbers.stream().limit(5).collect(Collectors.toList());skip(long n):跳过流中的前n个元素。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> skippedNumbers = numbers.stream().skip(3).collect(Collectors.toList());终端操作
forEach(Consumer<? super T> action):遍历流中的每个元素,并对其执行操作。底层使用了Consumer函数式接口,该接口定义了一个accept(T t)方法。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.stream().forEach(System.out::println); // 使用Consumerreduce(BinaryOperator<T> accumulator):将流中的元素组合起来,得到一个值。底层使用了BinaryOperator函数式接口,该接口是BiFunction的特化版本,定义了apply(T t1, T t2)方法。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> sum = numbers.stream().reduce((a, b) -> a + b); // 使用BinaryOperator
sum.ifPresent(System.out::println);collect(Collectors.toList())、collect(Collectors.toSet())等:将流中的元素收集到新的集合中。Collectors类提供了多种收集器,用于将流中的元素收集到不同的集合类型中。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
String joinedNames = names.stream().collect(Collectors.joining(", ")); // 收集为字符串
System.out.println(joinedNames);这里的clooect以后我经常使用,其中的收集器种类很多,列举常用收集器
-
Collectors.toList()
Collectors.toList()- 示例:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David");
List<String> filteredNames = names.stream().filter(name -> name.startsWith("A")).collect(Collectors.toList());
System.out.println(filteredNames); // 输出: [Alice] 2. Collectors.toSet()
- 作用:将流中的元素收集到一个新的
Set中,去除重复元素。 - 示例:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "Alice");
Set<String> uniqueNames = names.stream().collect(Collectors.toSet());
System.out.println(uniqueNames); // 输出: [Alice, Bob, Charlie] 3. Collectors.toCollection(Supplier<C> collectionFactory)
- 作用:将流中的元素收集到指定的集合类型中。
- 示例:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "Alice");
HashSet<String> uniqueNames = names.stream().collect(Collectors.toCollection(HashSet::new));
System.out.println(uniqueNames); // 输出: [Alice, Bob, Charlie] 4. Collectors.joining(CharSequence delimiter)
- 作用:将流中的字符串元素连接成一个单一的字符串,使用指定的分隔符。
- 示例:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
String joinedNames = names.stream().collect(Collectors.joining(", "));
System.out.println(joinedNames); // 输出: Alice, Bob, Charlie 5. Collectors.groupingBy(Function<? super T, ? extends K> classifier)
- 作用:将流中的元素按某个属性或条件分组,返回一个
Map。 - 示例:
List<Person> people = Arrays.asList(new Person("Alice", 25),new Person("Bob", 30),new Person("Charlie", 25)
);
Map<Integer, List<Person>> peopleByAge = people.stream().collect(Collectors.groupingBy(Person::getAge));
System.out.println(peopleByAge); // 输出: {25=[Alice, Charlie], 30=[Bob]}6. Collectors.toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper)
- 作用:将流中的元素收集到一个
Map中,指定键和值的映射方式。 - 示例:
List<Person> people = Arrays.asList(new Person("Alice", 25),new Person("Bob", 30),new Person("Charlie", 25)
);
Map<String, Integer> nameToAge = people.stream().collect(Collectors.toMap(Person::getName, Person::getAge));
System.out.println(nameToAge); // 输出: {Alice=25, Bob=30, Charlie=25}7. Collectors.summingInt(ToIntFunction<? super T> mapper)
- 作用:对流中的元素进行求和操作,返回一个
int值。 - 示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int sum = numbers.stream().collect(Collectors.summingInt(Integer::intValue));
System.out.println(sum); // 输出: 158. Collectors.averagingInt(ToIntFunction<? super T> mapper)
- 作用:对流中的元素进行平均值计算,返回一个
double值。 - 示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
double average = numbers.stream().collect(Collectors.averagingInt(Integer::intValue));
System.out.println(average); // 输出: 3.09. Collectors.maxBy(Comparator<? super T> comparator)
- 作用:找到流中的最大元素,返回一个
Optional<T>。 - 示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> max = numbers.stream().collect(Collectors.maxBy(Integer::compare));
System.out.println(max.get()); // 输出: 510. Collectors.minBy(Comparator<? super T> comparator)
- 作用:找到流中的最小元素,返回一个
Optional<T>。 - 示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> min = numbers.stream().collect(Collectors.minBy(Integer::compare));
System.out.println(min.get()); // 输出: 111. Collectors.counting()
- 作用:计算流中的元素数量,返回一个
long值。 - 示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
long count = numbers.stream().collect(Collectors.counting());
System.out.println(count); // 输出: 512. Collectors.reducing(BinaryOperator<T> operator)
- 作用:对流中的元素进行归并操作,返回一个归并后的结果。
- 示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int sum = numbers.stream().collect(Collectors.reducing(0, Integer::intValue, Integer::sum));
System.out.println(sum); // 输出: 1513. Collectors.partitioningBy(Predicate<? super T> predicate)
- 作用:将流中的元素按某个条件分为两部分,返回一个
Map<Boolean, List<T>>。 - 示例:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Map<Boolean, List<Integer>> partitioned = numbers.stream().collect(Collectors.partitioningBy(n -> n % 2 == 0));
System.out.println(partitioned); // 输出: {false=[1, 3, 5], true=[2, 4]}anyMatch(Predicate<? super T> predicate)、allMatch(Predicate<? super T> predicate)、noneMatch(Predicate<? super T> predicate):检查流中的元素是否满足某个条件。这些操作底层使用了Predicate函数式接口。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
boolean hasEven = numbers.stream().anyMatch(n -> n % 2 == 0); // 使用Predicate
System.out.println(hasEven);findFirst()、findAny():查找流中的元素。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
Optional<String> first = names.stream().findFirst();
first.ifPresent(System.out::println);max(Comparator<? super T> comparator)、min(Comparator<? super T> comparator):找到流中的最大或最小元素。底层使用了Comparator函数式接口。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Optional<Integer> max = numbers.stream().max(Integer::compare); // 使用Comparator
max.ifPresent(System.out::println);count():计算流中的元素数量。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
long count = numbers.stream().count();
System.out.println(count);希望以上Java Stream能够带给大家帮助