n8n 中文系列教程_23. 【实战篇】如何零成本搭建Deep Research类AI工具
1. 背景与痛点分析
Deep Research类AI产品功能强大,但商业化方案价格昂贵,尤其是自行复刻时成本问题突出:
-
大模型Token成本:虽然不低,但尚可接受
-
搜索API成本:成为主要瓶颈
-
SerpAPI:$75/5000次搜索
-
Google官方API:$35/1000次结果
-
这种成本结构使得自建方案往往比直接订阅ChatGPT Plus或Gemini会员更贵。
2. 开源解决方案:SearXNG介绍
2.1 什么是SearXNG?
SearXNG是一个免费开源的元搜索引擎(metasearch engine),具有以下核心特性:
-
工作原理:
-
不建立自己的索引库
-
代理用户向多个搜索引擎(Google/Bing/DuckDuckGo等)发送查询
-
聚合整理返回结果
-
-
核心优势:
-
隐私保护:不记录用户搜索历史/IP地址
-
避免过滤气泡:提供未经个性化处理的原始结果
-
多源整合:支持同时查询多个搜索引擎
-
2.2 技术架构优势
在n8n 1.89+版本中,SearXNG已被集成为标准节点,这意味着:
-
可直接在n8n工作流中调用
-
无需额外开发API接口
-
完美融入AI Agent工具生态系统
3. 部署指南
SearXNG 的部署比 n8n 还简单,它几乎是一个可以拉取镜像后直接运行的项目。
尤其是在作为 n8n 节点使用时,我们甚至不需要使用它的 Web UI。
你如果会用 Docker,只需要直接拉取镜像,然后运行就行。只有两个地方需要设置:
其一:
端口映射 9147:8080
将宿主机端口 9147 映射到容器端口 8080
其二:
永久化存储
将宿主机目录 /volume1/docker/searxng 映射到容器目录 /etc/searxng。
3.1 基础部署(Docker方案)
docker pull searxng/searxng
docker run -d \--name searxng \-p 127.0.0.1:9147:8080 \-v /volume1/docker/searxng:/etc/searxng \searxng/searxng关键参数说明:
-
端口映射:建议仅限本地访问(127.0.0.1)
-
持久化存储:必须配置以保证设置不丢失
3.2 安全建议
-
网络隔离:
-
与n8n部署在同一主机
-
禁止公网访问(使用127.0.0.1绑定)
-
-
访问控制:
# settings.yml server:secret_key: "生成强密码"limiter: true
4. 关键配置详解
4.1 启用JSON API模式

编辑/volume1/docker/searxng/settings.yml:
search:formats:- html- json # 添加此行注意:YAML文件对缩进敏感,必须使用空格而非Tab
4.2 搜索引擎配置
默认情况下 SearXNG 打开了对 Google、Wikipedia 和 Gogoduck 等国外搜索引擎的支持。如果你想打开百度搜索,你需要在配置文件里搜索 baidu。然后将 disabled: true 修改为 disabled: false。如下图:

engines:- name: googledisabled: false- name: baidudisabled: false # 启用百度搜索- name: wikipediadisabled: false同理,你可以查阅配置文件里其他的搜索引擎的这个设置,关掉那些你不想要的以提升检索速度。
4.3 代理设置(如需)
如果你的 SearXNG 处在一个不能访问 Google 的网络环境,你可能需要设置一下。SearXNG 不读取 Docker 的代理环境变量,需要在配置文件里修改。搜索 proxies: ,按照如下图配置即可:

outgoing:proxies:- http://代理IP:端口- socks5://代理IP:端口至此,你的 SearXNG 就可以作为一个好用的搜索 API 来用了。
值得注意的是,SearXNG 的 WebUI 是默认打开的,并且允许外网访问。如果你不希望别人使用你的 SearXNG,我建议你在 Docker 将端口映射改为 127.0.0.1:9147:8080。这样确保只有本机的 n8n 可以调用 SearXNG,代价是你自己也访问不到 SearXNG 的 WebUI 了。
5. n8n工作流构建
5.1 整体架构
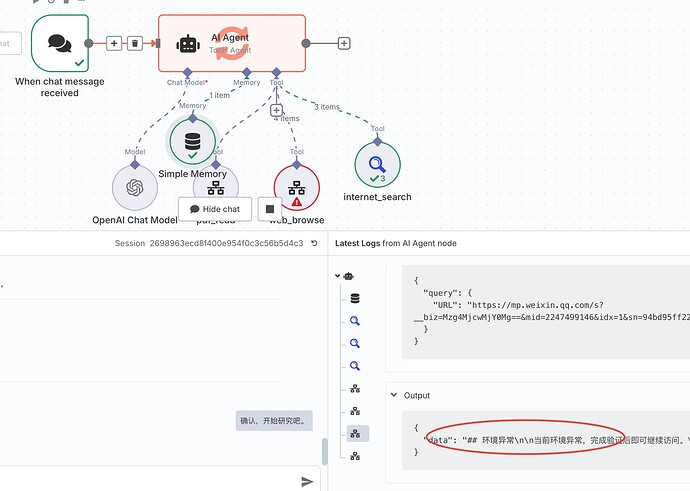
DeepResarch 想要做好有非常多的工程化细节,但我们只做原理复刻的话,就会变得非常简单。整体而言,它的 Workflow 长这样:
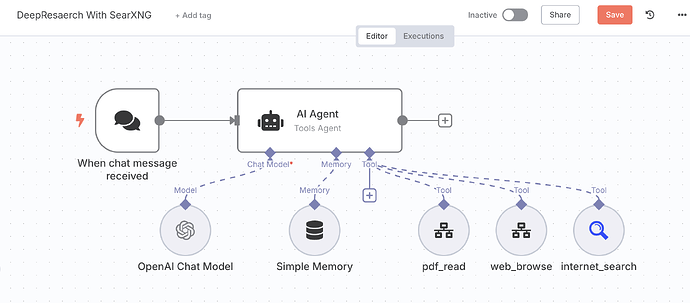
可以看到,我们实际上只是在标准的 AI Agent 工作流(一个聊天触发器、一个记忆节点、一个 AI Agent 节点和一个 AI 模型)上连接了三个工具,分别是 internet_search、pdf_read 和 web_browser。
[聊天触发器] → [记忆节点] → [AI Agent] → [响应输出]↑ ↓[SearXNG搜索] [网页阅读器] [PDF解析器]5.2 核心工具配置
5.2.1 SearXNG搜索节点
配置 internet_search
直接在 AI Agent 的 Tool 槽位上点击加号,选择 SearXNG 节点。
在弹出的节点配置中,我们选择新建一个 SearXNG 凭据(Credential)。然后,将我们刚才配置的 SearXNG 的地址填写进去:
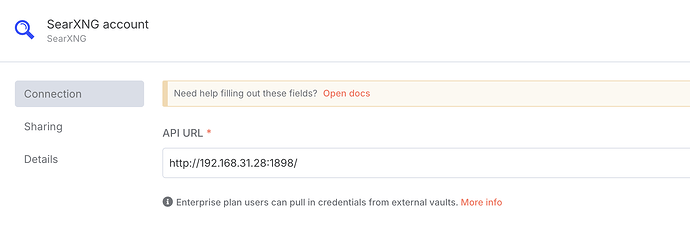
这里要填写的地址,是你的 SearXNG 的本地地址。
至此,我们的搜索工具配置完毕。
但是,我们会发现 SearXNG API 返回的搜索结果,而非结果页内容。也就是它给的其实是某个关键词搜索后 Google 列表的那个页面——标题、网页地址、一小段摘要。
我们为了让 AI 能真正从搜索结果中提取有用信息,必须让 AI 实际读取搜索结果页面才行。这就导致了我们需要配置另外两个工具,一个用来读网页,一个用来读 PDF。
-
在AI Agent的Tools槽位添加SearXNG节点
-
配置凭据:
-
地址:
http://localhost:9147 -
超时:建议30秒
-
5.2.2 网页阅读器子工作流
配置 web_browser
我们当然可以直接把 HTTP Request 节点作为一个工具接到 AI Agent 上,但那样就意味着 AI 在研读网页的时候,会把整个网页的完整 HTML 都放进上下文里。一方面影响 AI 的阅读能力,另一方面会大幅的增加 Tokens 消耗。
为了减少 AI 的阅读负担,我们希望能够将一个网页先转换成 Markdown 再喂给 AI。
然而,在 AI Agent 节点上,我们只能单独使用一个节点作为工具,怎么办呢?
我们可以单独建一个用于读取并转换网页的 Workflow,再把这个 Workflow 作为工具连接在 AI Agent 上。
首先,我们创建一个新的 Workflow,随便取个名字,然后配置上如下节点:
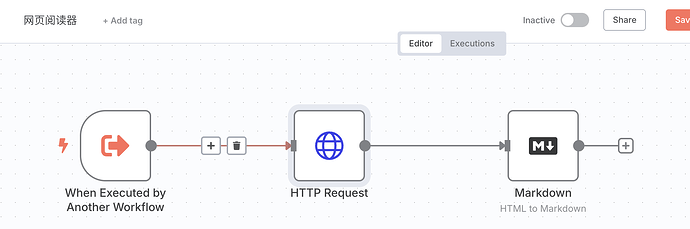
它的触发器是“When Executed by Another Workflow”,这个触发器专门用于编排子 Workflow。它允许你设置这个 Workflow 需要从父 Workflow 索要哪些参数。比如在这里,我们实际上只需要一个参数,那就是 URL,也就是想要阅读哪个网页。我们就这样设置:
接下来,我们添加一个 HTTP Request 用于获取网页,设置如下:
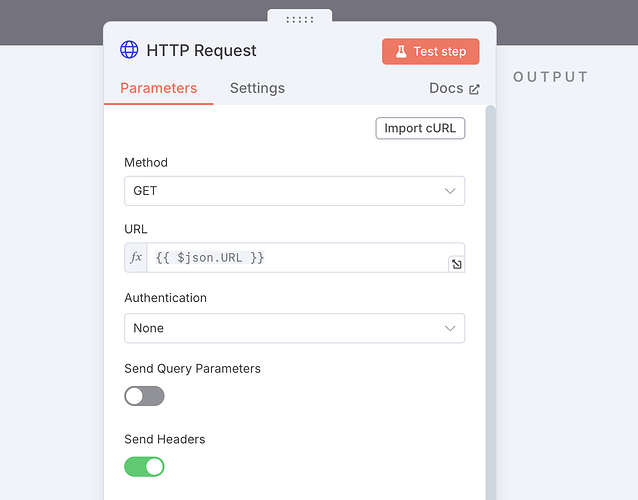
获取完的网页,我们需要用一个 Markdown 节点去剥离它的所有 HTML 代码只保留大部分能直接看的肉眼内容,配置如下:
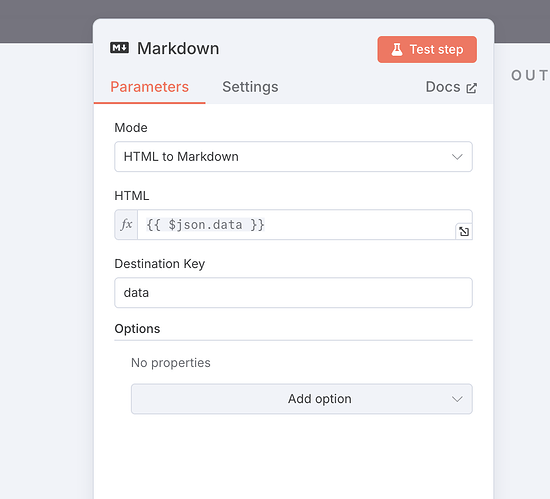
这样,我们一个用于将指定 URL 转换为 Markdown 的子 Workflow 就做好了。
此时,我们回到我们的父 Workflow,在 AI Agent 的 Tools 槽位上增加一个 Call n8n Workflow Tool:
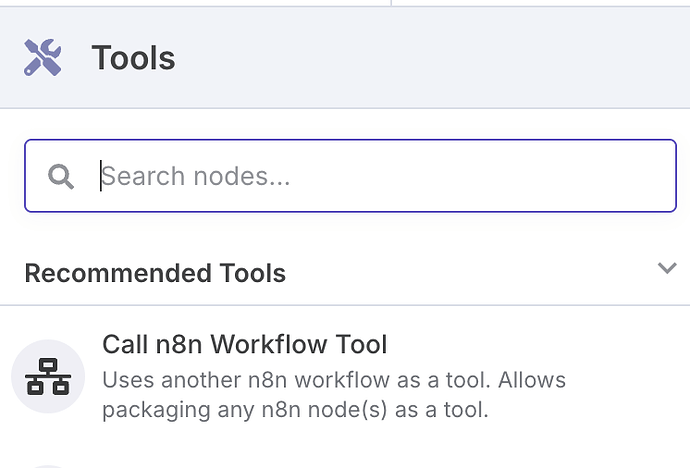
这个时候,我们会发现刚刚被我们定义的参数已经显示在了下面(URL),然后我们勾选 AI 自动填写。
再为这个工具写一个 Description,告诉 AI 这是个什么工具,怎么用。
配置就大功告成了。
[被调用触发器] → [HTTP请求] → [HTML转Markdown] → [返回结果]关键配置:
-
输入参数:URL(必填)
-
HTTP头设置:
{"User-Agent": "Mozilla/5.0" }
5.2.3 PDF解析器子工作流
[被调用触发器] → [HTTP请求] → [PDF转文本] → [返回结果]处理要点:
-
设置二进制响应类型
-
添加PDF解析库(如pdf-parse)
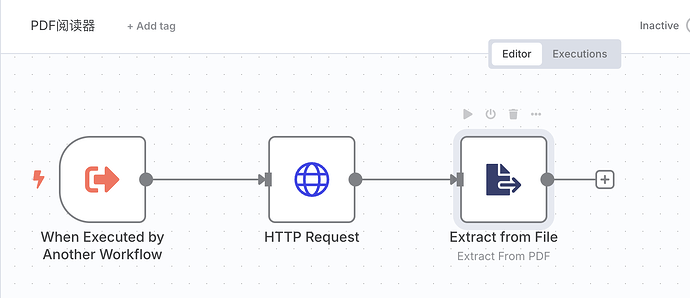
如法炮制,我们建立一个子 Workflow,设置三个节点。主要功能是将指定 URL 的 PDF 下载下来,解析成平文本。
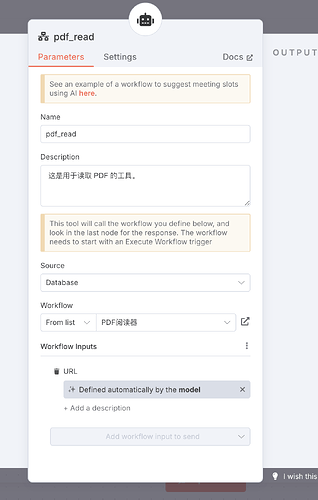
回到主 Workflow,添加子 Workflow 作为工具,配置好说明。
这样,AI 对于搜索结果中的 PDF 也就可以自动处理了。
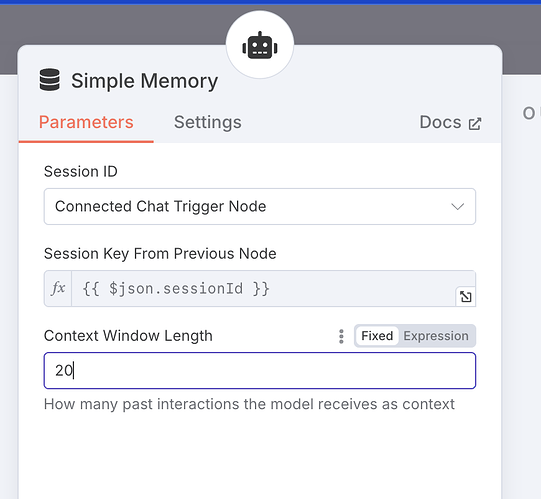
5.3 记忆节点优化
由于 Deep Research 一般一次对话会涉及数十次的反复调用,这其实是 AI 自己在和自己对话。我们为了防止它在执行任务过程中,原始的记忆被丢弃,我们需要将记忆模块的内容窗口长度调大一点,比如这里我们调到 20:
{"contextLength": 20,"temperature": 0.3
}6. 专业级Prompt设计
Deep Research 和一般的聊天不同,它需要 AI 有计划的使用工具,并规划下一步行动。所以我们实际上需要一个 ReAct 框架的 Prompt。这里我让 AI 生成了一份,你可以直接复制粘贴进你的 AI Agent 节点中:
# 深度研究助理工作规范## 三阶段执行框架1. 研究计划阶段- 分解研究问题- 制定搜索策略- 预估所需资源2. 信息收集阶段- 多轮次搜索(max 5次)- 来源可靠性评估:* 权威性* 时效性* 客观性- 交叉验证3. 报告生成阶段- 结构化输出:1. 引言2. 主体分析3. 结论- 规范引用:[1] 来源URL7. 模型选型建议
| 模型 | 优势 | 劣势 |
|---|---|---|
| GPT-4o | 长上下文(128K) | 成本较高 |
| Claude 3 | 分析能力强 | 响应较慢 |
| Gemini 1.5 | 免费额度大 | 中文支持一般 |
8. 已知问题与解决方案
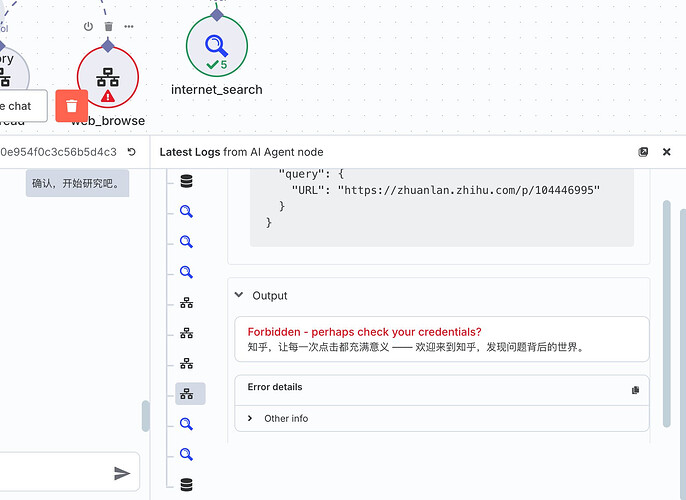
8.1 反爬虫限制
现象:
-
中文平台(知乎/公众号)返回403
-
验证码拦截
解决方案:
-
使用专业爬虫API替代:
-
Jina.ai
-
ScraperAPI
-
-
配置轮换User-Agent
8.2 性能优化
-
结果缓存:
// 代码示例 const cache = new Map(); async function cachedSearch(query) {if(cache.has(query)) return cache.get(query);const results = await searxngSearch(query);cache.set(query, results);return results; } -
并行处理:
-
同时发起多个搜索请求
-
使用n8n的并行执行节点
-
9. 进阶开发方向
-
结果自动评分系统:
-
基于来源权威性
-
内容新鲜度
-
观点多样性
-
-
自动摘要生成:
from transformers import pipeline summarizer = pipeline("summarization") -
知识图谱构建:
-
实体识别
-
关系抽取
-
可视化展示
-
10. 资源清单
-
示例工作流下载:
参考本文中绑定资源 -
推荐学习路径:
-
第1周:掌握基础部署
-
第2周:理解工作流原理
-
第3周:开发定制工具
-
-
社区支持:
-
n8n中文论坛
-
资料推荐
- 🔗 n8n官方文档参考
- ✨中转使用教程
本指南持续更新,建议收藏并定期查看n8n官方文档获取。实践过程中遇到任何技术问题,欢迎在评论区留言讨论。
更多内容可查看本专栏文章,有用的话记得点赞收藏噜!
