YOLO格式数据集制作以及训练
摘要:
这篇文档主要是介绍如何自己制作yolo格式的数据集,从图片拍照数据集采集开始,本人以铁轨数据为例,以及yolo的数据格式。如何使用自制数据集进行训练,训练使用的是官方的YOLO11。
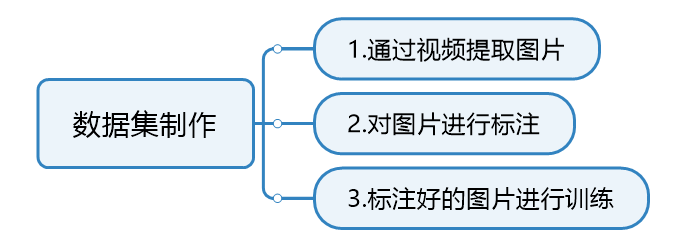
数据集制作分为以上3步,接下来,一步步进行讲解。
1.视频提取图片

以上视频是自己用手机或者其他设备拍摄的视频,导入时名字会是乱序的,一长串例如fawefuwqiehafuwe12312.mp4,所以首先将视频进行排序。

我的视频的帧数为30帧,时长为8秒,你们设备不同会有所差异,这无关紧要。
首先使用这段代码将其命名为video1、2…。记得替换你的视频数据地址。
# 用于数据集视频处理,将视频命名为video1、2...
import os
def video_name():# 定义视频文件夹路径video_folder = r'C:\Users\ASUS\Desktop\数据集\铁轨数据集\数据视频'# 获取文件夹内所有文件files = os.listdir(video_folder)# 筛选出视频文件(假设是以 .mp4, .avi 等常见视频格式结尾的文件)video_files = [f for f in files if f.endswith(('.mp4', '.avi', '.mov'))]# 遍历视频文件并重命名for idx, video_file in enumerate(video_files, start=1):# 获取文件扩展名file_extension = os.path.splitext(video_file)[1]# 生成新的文件名new_name = f'video{idx}{file_extension}'# 构造完整的文件路径old_file_path = os.path.join(video_folder, video_file)new_file_path = os.path.join(video_folder, new_name)# 重命名文件os.rename(old_file_path, new_file_path)print(f'Renamed: {video_file} -> {new_name}')
完成后如上图,for idx, video_file in enumerate(video_files, start=1):这行代码决定你的开始数字标号,可以设置为任意你想的数字,切记当生成了video_1在文件夹中时,再生成会报错。
视频重命名完成后,开始生成图片,视频地址"C:\Users\ASUS\Desktop\数据集\铁轨数据集\数据视频\video1.mp4"可以任意,每隔1秒提取一张图片,保存图片至C:\Users\ ASUS\Desktop\photo,视频路径不要用中文名,图片名字和视频名字一致
# 视频"C:\Users\ASUS\Desktop\数据集\铁轨数据集\数据视频\video1.mp4"
# 每隔1秒提取一张图片,保存图片至C:\\Users\\ASUS\\Desktop\\photo,视频路径不要用中文名
# 图片名字和视频名字一致
#3. video_read_photo_3()----------------------------------------------------------------------------------
#读取视频流video.mp4,每格2秒读取一张图片,将读取出来的图片按照video_1、2...保存至photo4文件夹
import cv2
import osdef video_read_photo_3(secend):# 输入视频文件路径video_file = 'C:\\Users\\ASUS\\Desktop\\数据集\\铁轨数据集\\数据视频\\video6.mp4'# 输出文件夹路径output_folder = 'C:\\Users\\ASUS\\Desktop\\photo'# 确保输出文件夹存在if not os.path.exists(output_folder):os.makedirs(output_folder)# 获取视频文件的文件名(不带扩展名)video_name = os.path.splitext(os.path.basename(video_file))[0]# 打开视频文件cap = cv2.VideoCapture(video_file)# 检查视频是否成功打开if not cap.isOpened():print("无法打开视频文件")exit()# 获取视频的帧率(每秒的帧数)fps = cap.get(cv2.CAP_PROP_FPS)# 初始化帧计数器frame_number = 0# 读取视频流while True:# 设置视频流读取位置为当前帧的秒数位置cap.set(cv2.CAP_PROP_POS_FRAMES, frame_number * fps * secend) # 每隔指定秒数读取一帧# 读取帧ret, frame = cap.read()# 如果没有帧了,结束循环if not ret:break# 保存当前帧为图片,图片命名为视频文件名 + 帧数output_image_path = os.path.join(output_folder, f"{video_name}_{frame_number + 1}.jpg")cv2.imwrite(output_image_path, frame)print(f"保存图像: {output_image_path}")# 增加帧计数器(每次增加1秒)frame_number += 1# 释放视频捕获对象cap.release()
你如果嫌一个个视频输入改地址麻烦,可以一键导入生成代码如下
# 和3一样,但是是直接处理所有视频
def video_read_photo_4(secend):# 输入视频文件夹路径video_folder = 'C:\\Users\\ASUS\\Desktop\\数据集\\铁轨数据集\\数据视频'# 输出文件夹路径output_folder = 'C:\\Users\\ASUS\\Desktop\\photo'# 确保输出文件夹存在if not os.path.exists(output_folder):os.makedirs(output_folder)# 获取视频文件夹中的所有 .mp4 文件video_files = [f for f in os.listdir(video_folder) if f.endswith('.mp4')]for video_file in video_files:# 获取视频文件的完整路径video_path = os.path.join(video_folder, video_file)# 获取视频文件的文件名(不带扩展名)video_name = os.path.splitext(video_file)[0]# 打开视频文件cap = cv2.VideoCapture(video_path)# 检查视频是否成功打开if not cap.isOpened():print(f"无法打开视频文件: {video_path}")continue# 获取视频的帧率(每秒的帧数)fps = cap.get(cv2.CAP_PROP_FPS)# 初始化帧计数器frame_number = 0# 读取视频流while True:# 设置视频流读取位置为当前帧的秒数位置cap.set(cv2.CAP_PROP_POS_FRAMES, frame_number * fps * secend) # 每隔指定秒数读取一帧# 读取帧ret, frame = cap.read()# 如果没有帧了,结束循环if not ret:break# 保存当前帧为图片,图片命名为视频文件名 + 帧数output_image_path = os.path.join(output_folder, f"{video_name}_{frame_number + 1}.jpg")cv2.imwrite(output_image_path, frame)print(f"保存图像: {output_image_path}")# 增加帧计数器(每次增加1秒)frame_number += 1# 释放视频捕获对象cap.release()


导出效果如图所示。
2.图片已经处理好了,开始对图像进行标注
标注软件我选用的是X-AnyLabeling,因为听说这个软件可以自动标注,后来发现你得有预训练模型去识别框选,就是别人训练好的对这个物体识别的模型,你像识别苹果,香蕉这种COCO数据集里面肯定有人做好了这种YOLO的识别模型。那既然都有开源的那我还做啥数据集呢?因为这方面的数据稀缺,我只能老老实实的自己打标签。
软件github官方路径
https://github.com/CVHub520/X-AnyLabeling/releases
如果你下载不了,用百度网盘也行:
通过网盘分享的文件:X-AnyLabeling-CPU
链接: https://pan.baidu.com/s/1qeMw_nZ9Fnl7b0evygaH1A?pwd=eggu 提取码: eggu
自动标注就不做过多的讲解了。接下来点击文件,然后选择打开文件夹

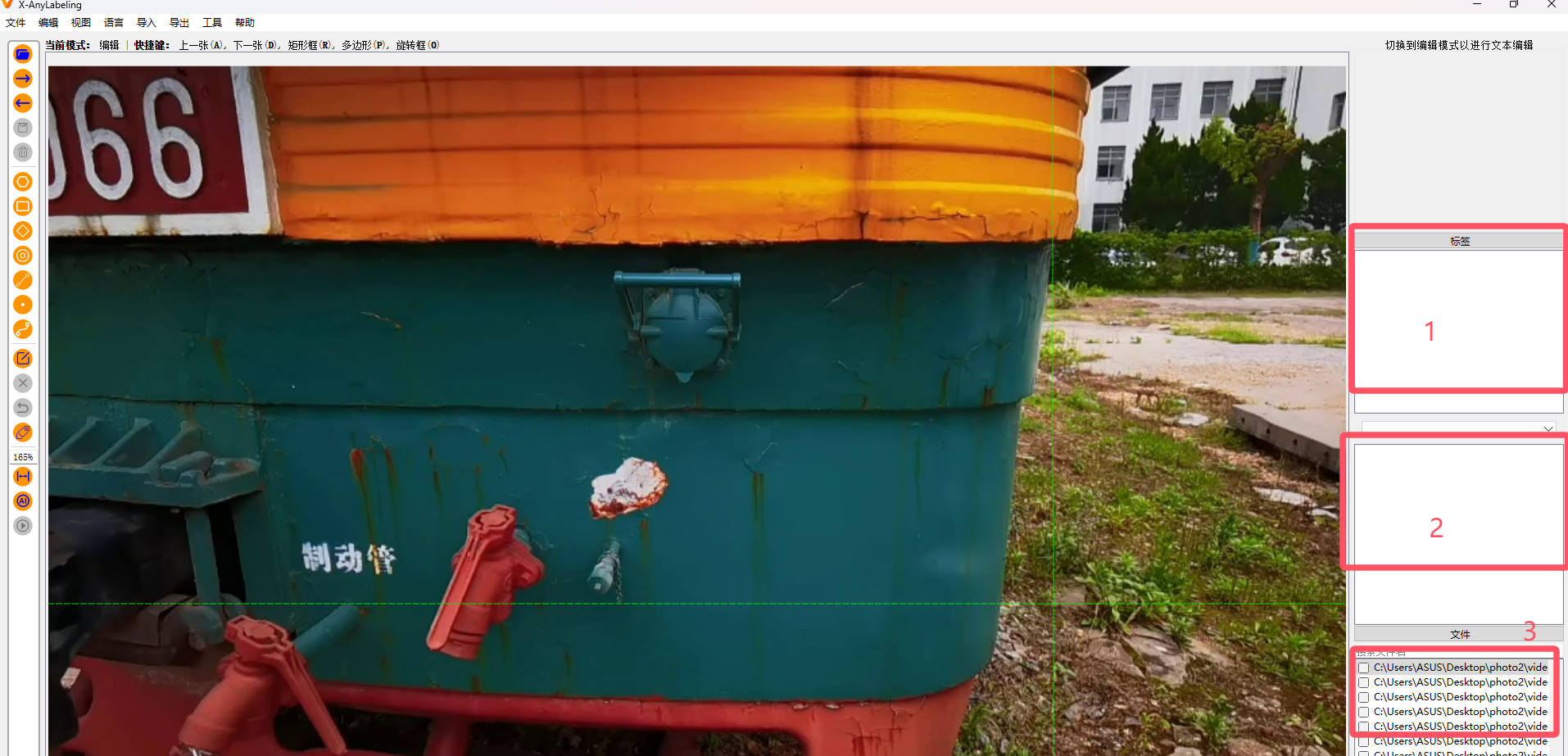
然后就会直接弹出你的图片,第一个红色窗口是你定义的标签类别,第二个窗口是你图片中标了多少个框以及它的类别,第三个框是你的图片以及是否标注好了标注好了会打勾。
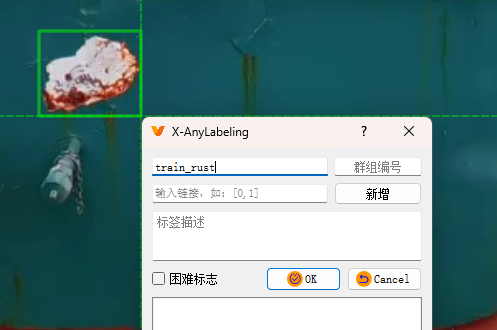
快捷键R框选目标,这个标签定义为train_rust
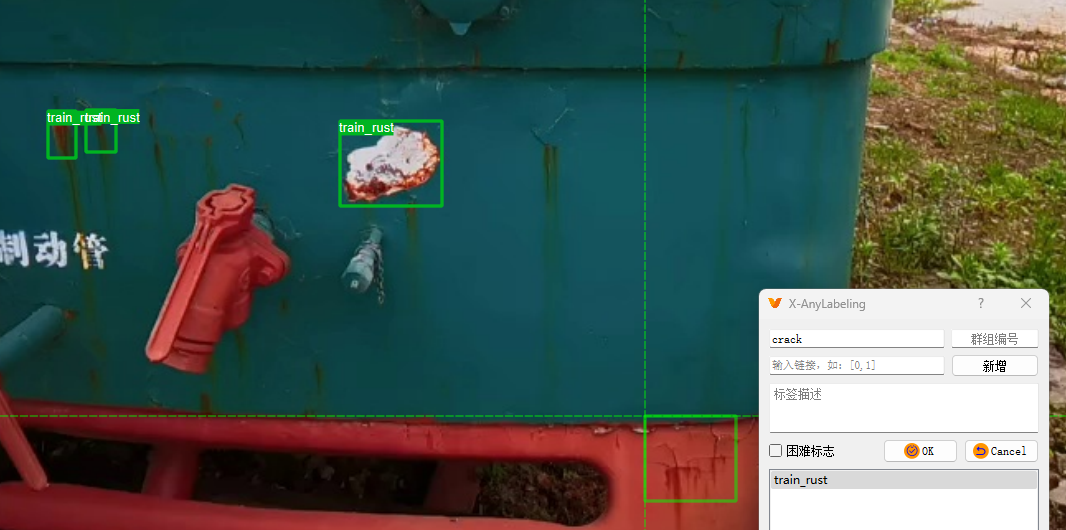
新增标签名输入不同的名字即可。

最终效果如图所示,快捷键D下一张图,A快捷键上一张图。

图片被标注好后会自动生成一个json文件。

打开json文件可以看出他会保存你得版本号,以及label类别,
train_rust坐标
左上角坐标:[397.5757575757576, 286.2424242424242]
右上角坐标:[459.39393939393943, 286.2424242424242]
右下角坐标:[459.39393939393943, 337.75757575757575]
左下角坐标:[397.5757575757576, 337.75757575757575]

txt文件导出选择导出YOLO水平框标签。
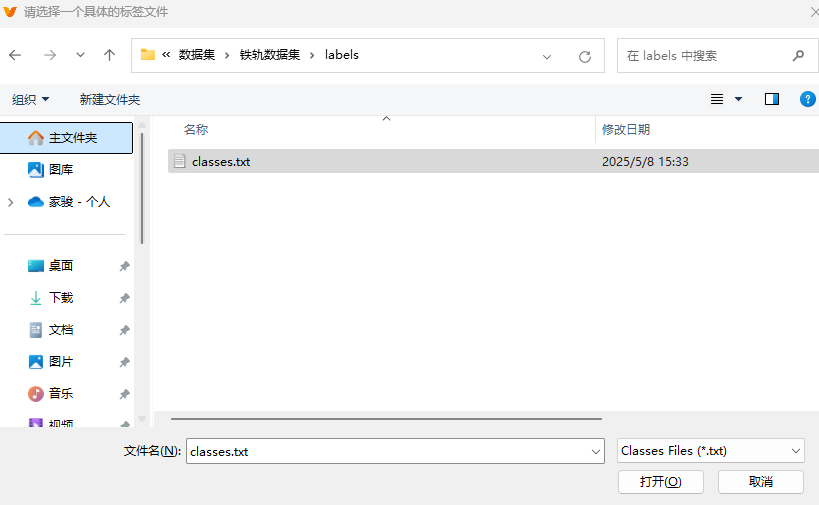
导出时需要你选择一个指定的classes文件做为label的参考文件

切记你的classes.txt文件的内容一定要和标签一一对应。

之后就会跳出导出路径保存的地址。

导出成功这就是你保存的地址。


查看txt文件发现是yolo格式没有问题。
文件中还有一个问题就是jpg图片和json文件混在一起,通过以下代码实现图片和json文件的分离。

import os
import shutil
def photo_json_progress():# 以下是一个Python脚本,可以将指定路径下的图片文件(如.jpg、.png等)和JSON文件自动分类到两个独立文件夹中:# 源文件夹路径(根据你的实际路径修改)source_dir = r'C:\Users\ASUS\Desktop\test'# 目标文件夹路径image_dir = os.path.join(source_dir, 'images')json_dir = os.path.join(source_dir, 'jsons')# 创建目标文件夹(如果不存在)os.makedirs(image_dir, exist_ok=True)os.makedirs(json_dir, exist_ok=True)# 遍历源文件夹for filename in os.listdir(source_dir):file_path = os.path.join(source_dir, filename)# 跳过子文件夹(只处理文件)if os.path.isfile(file_path):# 获取文件扩展名(转换为小写)file_ext = os.path.splitext(filename)[1].lower()# 分类处理if file_ext in ['.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp']:shutil.move(file_path, os.path.join(image_dir, filename))print(f"[移动图片] {filename} -> images文件夹")elif file_ext == '.json':shutil.move(file_path, os.path.join(json_dir, filename))print(f"[移动JSON] {filename} -> jsons文件夹")

然后按照yolo格式要求存放文件如图所示,annotations为存放json文件的地址,images存放jpg图片,labels存放txt标签文件。

构建训练集和测试集。
完成以上步骤后数据集的制作就大致完成了。
3.开始训练
在github上去下载它的代码。
https://github.com/ultralytics/ultralytics.git

也可以从他们官网多了解一下。
https://docs.ultralytics.com/zh/
如果网站打不开,我把文件放到以下链接了:通过网盘分享的文件:yolo11
链接: https://pan.baidu.com/s/1W1SgsvzYZHAzv9d5-0DO2g?pwd=t2xb 提取码: t2xb
训练开始前得先知道几个文件的关键之处,data.yaml这个文件将作为数据集的制作打开地址。yolo11.yaml将作为yolo的模型文件,yolo11的架构关键就在此处。还一个就是train.py训练文件。

data.yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: C:\Users\ASUS\Desktop\dataset # dataset root dir
train: C:\Users\ASUS\Desktop\dataset\train\images # train images (relative to 'path') 6471 images
val: C:\Users\ASUS\Desktop\dataset\test\images # val images (relative to 'path') 548 images
test: C:\Users\ASUS\Desktop\dataset\test\images # test images (optional) 1610 images# Classes
nc: 3 # number of classes
names: ['rail_rust', 'crack', 'train_rust']
我的种类只有3种,验证集和测试集用相同的。
yolo11.yaml
# Parameters
nc: 3 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
train.py训练文件
import warningswarnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('yolo11.yaml') #这是模型的训练文件# 如何切换模型版本, 上面的ymal文件可以改为 yolov11s.yaml就是使用的v11s,# 类似某个改进的yaml文件名称为yolov11-XXX.yaml那么如果想使用其它版本就把上面的名称改为yolov11l-XXX.yaml即可(改的是上面YOLO中间的名字不是配置文件的)!#model.load('yolo11n.pt') # 是否加载预训练权重,科研不建议大家加载否则很难提升精度model.train(data=r"data.yaml", #这是数据集地址文件以及配置文件# 如果大家任务是其它的'ultralytics/cfg/default.yaml'找到这里修改task可以改成detect, segment, classify, posecache=False,imgsz=640,epochs=20,single_cls=False, # 是否是单类别检测batch=16,close_mosaic=0,workers=0,device='0',optimizer='SGD', # using SGD 优化器 默认为auto建议大家使用固定的.# resume=, # 续训的话这里填写True, yaml文件的地方改为lats.pt的地址,需要注意的是如果你设置训练200轮次模型训练了200轮次是没有办法进行续训的.amp=True, # 如果出现训练损失为Nan可以关闭ampproject='runs/train',name='exp',# lr0 = 0.01,# cos_lr=True,)
不要用预训练权重。
如果数据集比较小尽量训练周期多一点。

刚开始训练的时候,box_loss比较大,随着训练周期增加会慢慢收敛的。

我也是从第4个周期开始map才有数值的。

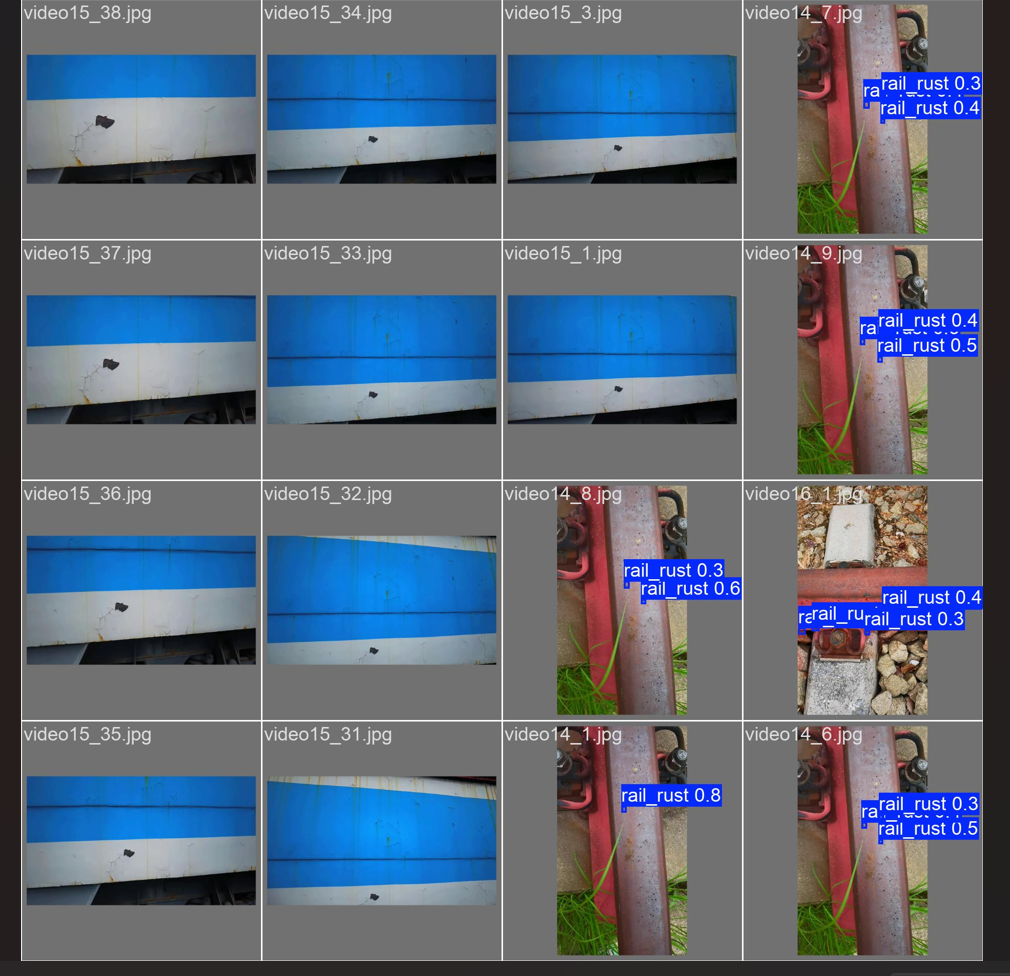
查看val_batch1_pred.jpg发现20个训练周期过后结果还是差劲的,以上就是先练的大致步骤了。