内存分配器ptmalloc2、tcmalloc、jemalloc,结构设计、内存分配过程详解
1. 引言
博主之前做过一个高并发内存池的项目实践,在实践中对于内存分配器的内存分配过程理解更加深刻了。在此期间,翻查了不少资料以及博客,发现源码分享的博客不多,能生动完整的讲述ptmalloc2、tcmalloc、jemalloc它们的结构设计以及内存分配过程的博客更是少之又少。那么在这篇文章中博主将总结分享内存分配器ptmalloc2、tcmalloc、jemalloc,欢迎大家留言讨论!
2. 现状
目前大部分服务端程序使用glibc提供的 malloc/free 系列函数,而glibc使用的 ptmalloc2 在性能上远远弱后于google的 tcmalloc 和facebook的 jemalloc。 而且后两者只需要使用LD_PRELOAD环境变量启动程序即可,甚至并不需要重新编译。
3. 业务场景
分配内存时进行系统调用的接口,对 heap 的操作, 操作系统提供了 brk() 系统调用,设置了Heap的上边界; 对 mmap 映射区域的操作,操作系统供了 mmap() 和 munmap() 函数。
因为系统调用的代价很高,不可能每次申请内存都从内核分配空间,尤其是对于小内存分配。 而且因为 mmap 的区域容易被 munmap 释放,所以一般大内存采用 mmap(),小内存使用 brk()。
4. glibc ptmalloc2
最新版本:作为Glibc的默认内存分配器,ptmalloc2的更新与Glibc(目前更新到2.35+)版本绑定。截至当前,其核心设计仍基于最初的ptmalloc2架构, glibc 2.26(2017年)开始引入了线程本地缓存(tcache,Thread Local Caching)。
4.1 内存管理结构
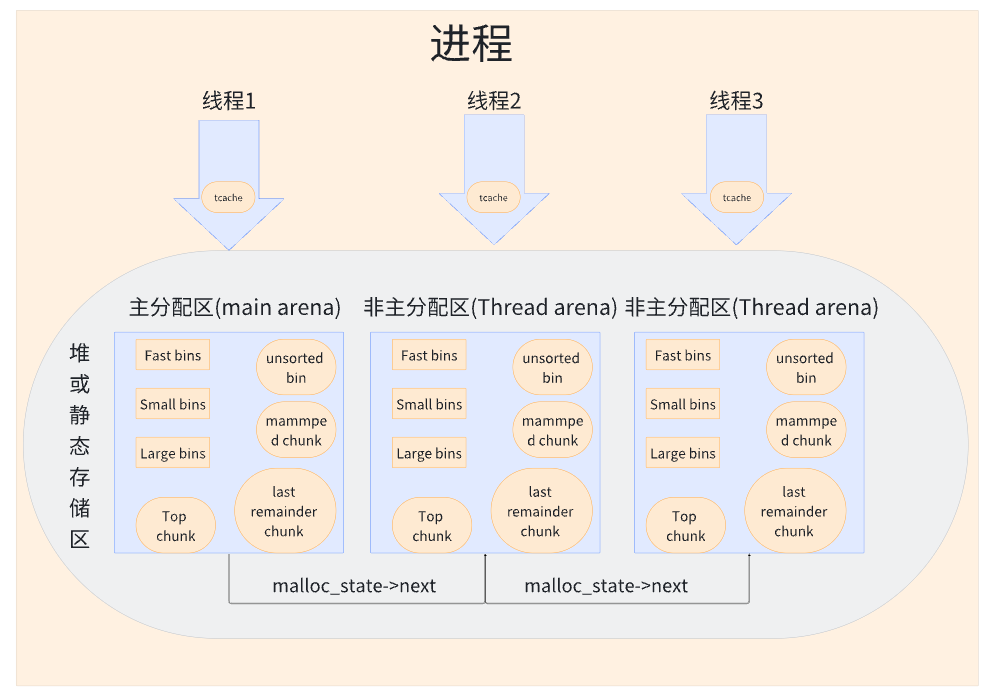
线程本地缓存(tcache)
作用:无锁快速分配小内存(每个线程独立)。
管理范围:默认 ≤ 1032 字节(64 位系统)。
数据结构:
64 个
tcache_bin(单链表,LIFO),每个 bin 对应一种固定大小(8B~1032B)。每个 bin 最多缓存 7 个 chunk(可通过
GLIBC_TUNABLES调整)。优化点:
优先从
tcache分配/释放,完全无锁。若
tcache为空,则从fastbins/smallbins批量预加载(加锁)。
Fast Bins(快速通道)
作用:缓存最近释放的小内存(仍保留 chunk 未合并,加速复用)。
管理范围:≤ 160 字节(64 位系统)。
数据结构:7 个单链表(LIFO),每个链表存储相同大小的 chunk。
与 tcache 的关系:
tcache不足时从fastbins补充。
free()时,小 chunk 可能先进入tcache,若tcache满则进入fastbins。
Small Bins(小内存通道)
作用:管理中等大小的内存(固定大小,合并友好)。
管理范围:≤ 1008 字节(64 位系统)。
数据结构:62 个双向链表(FIFO),每个 bin 对应一种固定大小(如 16B, 24B, ..., 1008B)。
与 tcache 的关系:
tcache不足时从smallbins分配。
free()时,若 chunk 大小匹配且tcache满,则进入smallbins。
Large Bins(大内存通道)
作用:管理大内存块(范围区间,按大小排序)。
管理范围:> 1008 字节。
数据结构:63 个双向链表,每个 bin 管理一个大小范围(如 1024B~1088B, 1089B~1152B...)。
分配策略:
查找最小满足大小的 chunk(可能分割)。
若找不到,则进入
unsorted bin或top chunk。
Unsorted Bin(临时缓冲区)
作用:临时存放释放的 chunk,等待重新分类。
数据结构:1 个双向链表(FIFO),存放最近释放的 chunk(不分大小)。
分配流程:
分配时优先检查遍历
unsorted bin,若找到合适 chunk 直接返回,否则将其转移到small/large bins。
Top Chunk(堆顶块)
作用:当前堆的顶部未分配内存,用于动态扩展。
分配逻辑:
当所有 bins 无法满足请求时,从 Top Chunk 切割所需内存。
若 Top Chunk 不足,通过
sbrk(主分配区)或mmap(非主分配区)扩展堆空间。
mmap 通道(超大内存)
管理大小:默认 ≥ 128KB(可通过
M_MMAP_THRESHOLD调整)。特点:
直接通过
mmap分配独立内存段,绕过堆管理。释放时通过
munmap立即归还系统,避免碎片。
last remainder chunk(最后剩余块)
优化连续内存分配:当用户请求的内存略小于某个空闲块时,分割后剩余的碎片会被标记为
last remainder,优先用于后续的连续分配请求。减少外部碎片,提升内存利用率。
4.2 内存分配流程
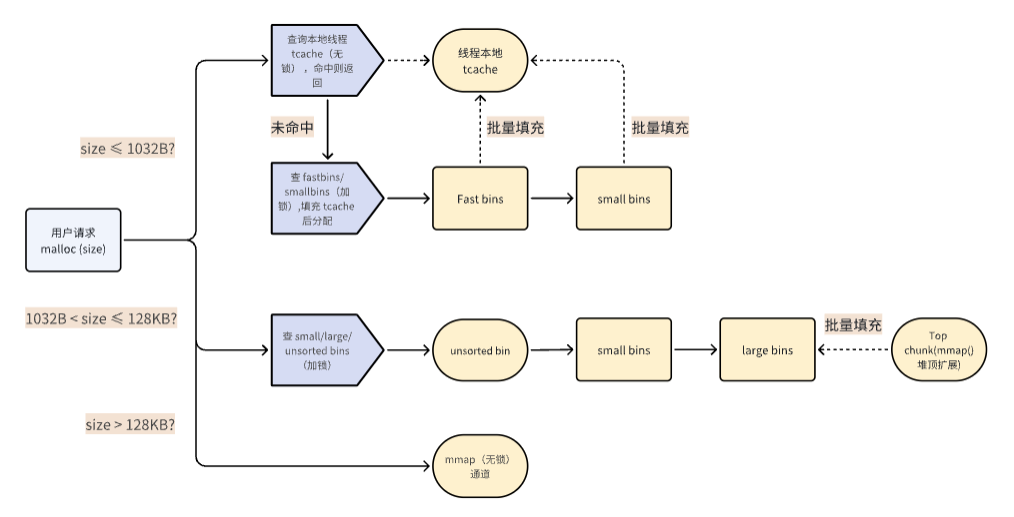
4.3 多线程支持
-
主分配区(Main Arena):主线程默认使用,通过
brk扩展堆。 -
非主分配区(Thread Arena):其他线程按需创建(数量受
MALLOC_ARENA_MAX限制)。 -
锁优化:
-
每个分配区有独立的锁,线程优先访问绑定的分配区。
-
若所有分配区被占用,线程会竞争主分配区。
-
4.4 缺点
- 内存碎片:外部和内部碎片问题突出,尤其长期运行后。
- 锁竞争:尽管有 tcache 和分配区,高并发下仍可能成为瓶颈。
- 释放延迟:fastbins 延迟合并,
brk堆收缩不积极。 - 场景局限:不适合高频小对象分配或实时系统。
5. tcmalloc
最新版本:截至2025年,tcmalloc已迭代至支持per-CPU模式的优化版本(如v2.10+),进一步提升多核性能。场景适用于多核服务器(如 Web 服务、数据库),高频小对象分配(如微秒级响应的 RPC 框架)。
5.1 内存管理结构
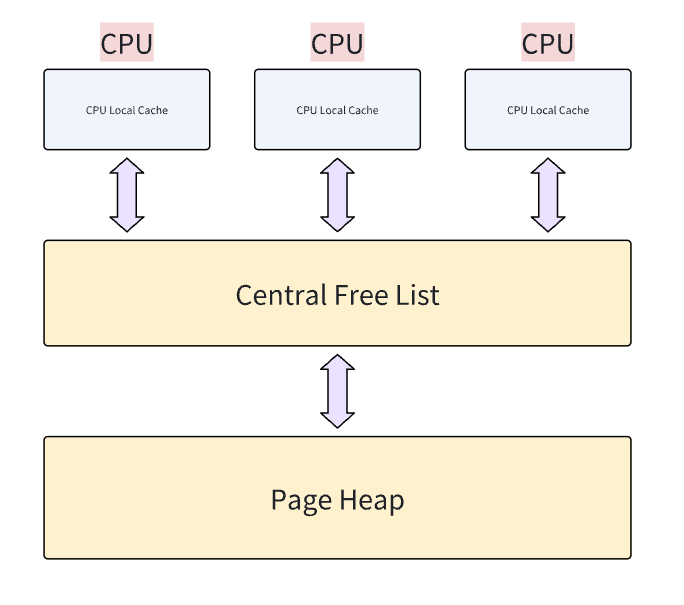
CPU Local Cache(CPU 本地缓存)
申请对象为小内存(通常 ≤256KB)。
使用Size Class 哈希桶,每个 CPU 核心维护一组自由链表(FreeList),按大小分类(如 8B、16B、...、256KB)。
动态批量填充,当本地缓存不足时,从下层批量获取对象(类似慢启动算法)。
这里无锁
Central Free List(中心空闲列表)
这一层全局共享,作为 CPU 本地缓存的后备仓库。
结构为哈希桶Span 链表:按大小分类管理内存块(Span),每个 Span 被切分为多个小对象。
轻量级锁:仅当 CPU 缓存需要补充时加锁(锁粒度细化到 Size Class)。
申请内存,当CPU 缓存耗尽时,从 Central Free List 批量拉取对象(如一次获取 32 个 16B 的块)。Central Free List 自身从 PageHeap 申请新的 Span。
PageHeap(页堆)
以页(通常 8KB)为粒度的大内存。
合并相邻空闲页,减少外碎片。
- 基数树(Radix Tree)算法,快速映射内存页到 Span,支持 O(1) 查找。
超过 256KB 的请求直接由 PageHeap 处理(通过
mmap或VirtualAlloc)。
5.2 内存分配流程(Per-CPU 模式)
- 小内存分配(≤256KB)时,线程先获取当前 CPU 的本地缓存(
GetThisCPUCache()),根据请求大小找到对应的 Size Class 自由链表。若链表非空,直接弹出对象返回(无锁),若链表为空,从 Central Free List 批量获取对象(加锁,但频率低)。 -
小内存释放时,将对象放回当前 CPU 的本地缓存自由链表(无锁)。若本地缓存超过阈值(如 1024 个对象),触发批量归还到 Central Free List。
- 大内存分配(>256KB)时,直接由 PageHeap 分配,通过
mmap或VirtualAlloc申请大块内存。 -
大内存释放时,通过 PageHeap 的基数树找到对应 Span,标记为空闲。尝试合并相邻空闲 Span,形成更大的连续内存。
5.4 局限性
它是零锁竞争的,Per-CPU 缓存完全无锁,适合超高并发场景。本地化操作减少 CPU 缓存行失效(Cache Line Ping-Pong),所以它延迟低。支持弹性扩展,CPU 数量增加时,性能线性提升(无全局瓶颈)。
Per-CPU 缓存可能暂存未使用的对象(可通过调优阈值缓解),造成内存浪费。它对CPU比较依赖,若线程频繁迁移 CPU,性能会下降(需绑定线程到核心)。
6. jemalloc
最新版本:jemalloc 5.3.0(发布于2025年5月1日),进一步优化内存碎片管理和多线程扩展性。
6.1 内存管理结构
之前的版本
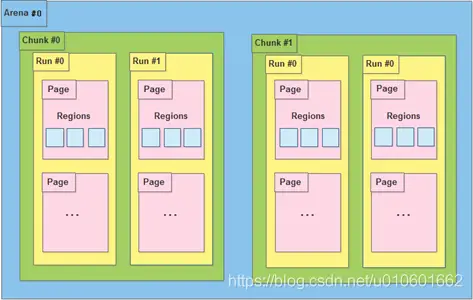
在之前的版本中内存被划分成若干个arena;每个arena被划分成若干个chunk(每个默认为4M);每个chunk被划分成若干个run;每个run由若干个page组成(每个page默认为4K),同一个run中的page又被细分成若干个大小相同的region;
为了减少内存碎片及快速定位到合适大小的内存,jemalloc将run按以下class_size分成44类(同一个run下的region大小相同):
-
small(<4K): [8], [16, 32, 48, …, 128], [192, 256, 320, …, 512], [768, 1024, 1280, …, 3840]
-
large(4K-4M): [4K, 8K, 12K, …, 4072K]
-
huge(>4M): [4M, 8M, 12M, …]
-
对于小于4K内存的申请,jemalloc直接向上取整到最小的class_size,例如申请1-7字节,都会分配一个8字节内存。
新版本
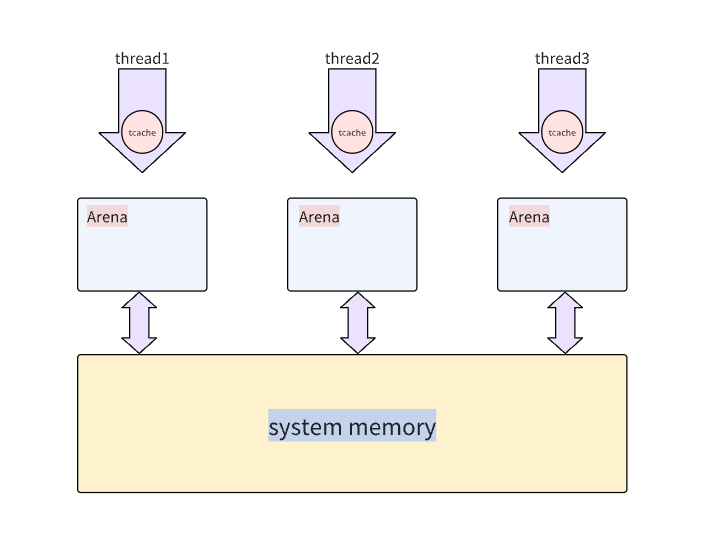
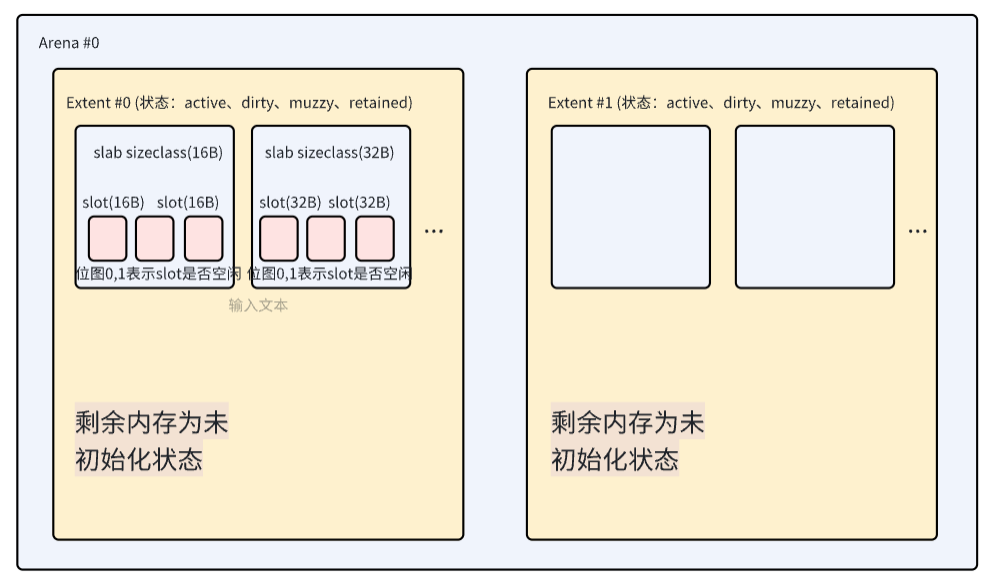
在 jemalloc 5.3.0 中,旧版的 chunk、run 等概念被 Extent 统一取代,其核心设计如下:
1. Extent(扩展块)
-
表示连续的虚拟内存区域(大小灵活,通常为 2MB 或 4MB,可动态调整)。替代旧版的
chunk,支持更细粒度的拆分与合并。 -
状态分级:分为
Active(在用)、Dirty(已释放但未擦除)、Muzzy(部分擦除)、Retained(完全擦除保留)。 -
动态管理:支持按需分割为
Slab或直接分配。
2. Slab(内存板)
-
将
Extent划分为固定大小的槽位(如 32B、64B),通过位图管理分配状态。替代旧版run的功能,但更轻量化。 -
按需分配:仅在使用时初始化
Slab,减少内存占用。 -
延迟释放:空闲
Slab不会立即合并,保留在Dirty/Muzzy状态供快速复用。
3. Page(页)
-
保留它的意义,仍作为操作系统内存管理的最小单位(如 4KB),但 jemalloc 内部通过
Extent聚合多页。 -
用户无需关注页级操作,所有分配均通过
Extent和Slab抽象。
4. Region(区域)
-
旧版中模糊的
region概念被Extent和Slab明确取代,不再存在于官方文档。
6.2 内存分配流程
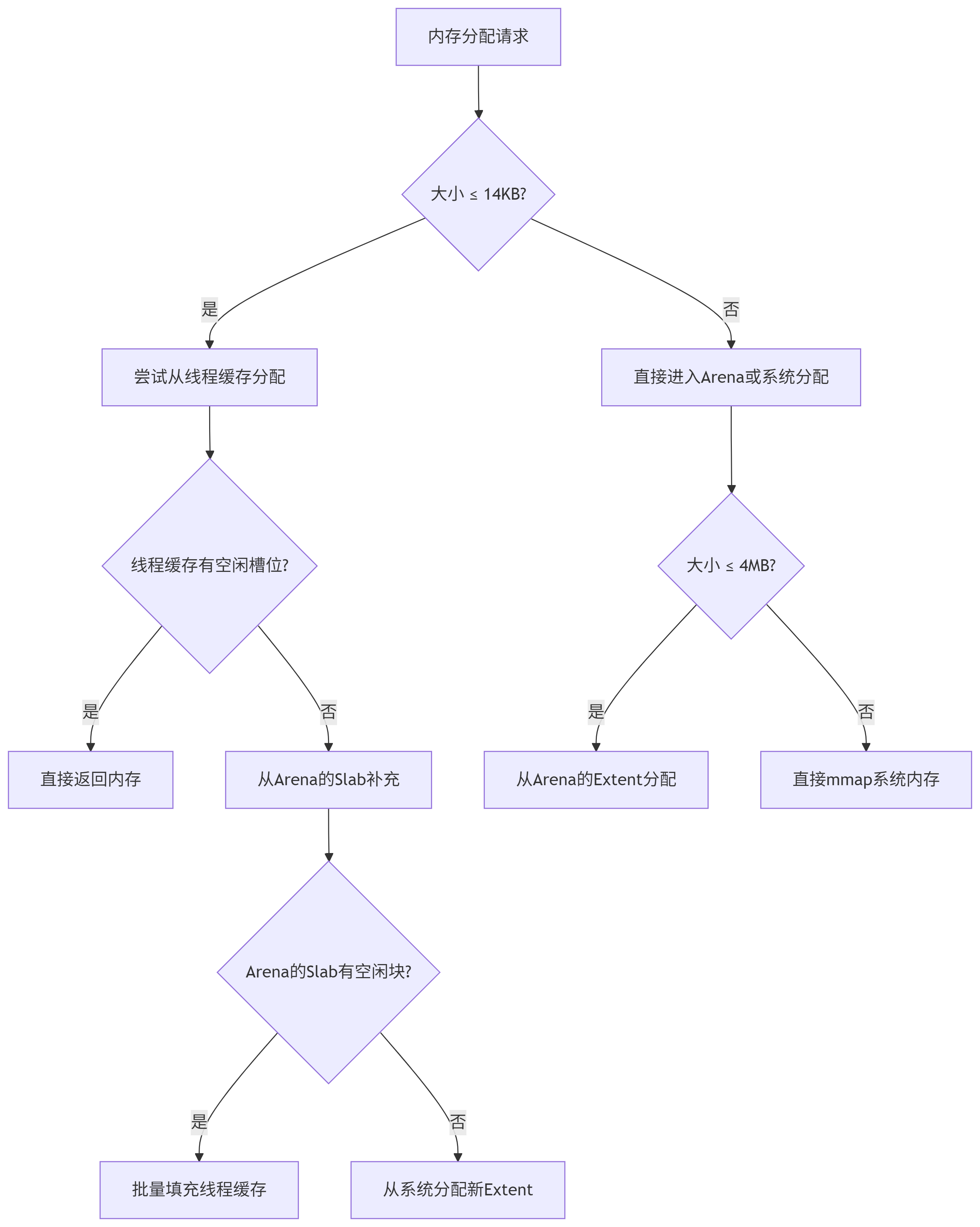
1. 从线程缓存(Thread Cache)分配
-
当请求的内存大小 ≤ 14KB(小对象)。线程本地缓存(TLS)中对应的 Size Class 有空闲槽位。根据请求大小匹配对应的 Size Class(如 32B、64B),从线程本地的 Slab 空闲链表 中弹出第一个空闲槽位,直接返回槽位内存地址(无锁操作)。
-
这个过程是零锁竞争,速度极快(纳秒级)。适合高频小对象分配(如短生命周期对象)。
2. 从 Arena 分配
-
当线程缓存为空,且请求大小 ≤ 4MB(中等对象)。或请求大小 >14KB 但 ≤4MB(跳过线程缓存)。
-
线程绑定到特定 Arena(默认轮询或哈希分配)。若当前 Arena 锁竞争激烈,可能创建新 Arena。从 Arena 的 Extent/Slab 分配,如果是中等对象(14KB < size ≤4MB),直接分配整个 Extent 或从空闲 Extent 链表分割。如果是小对象(≤14KB):从 Arena 的 Slab 中批量获取多个槽位,填充线程缓存后返回一个。
-
锁机制:Arena 内部使用细粒度锁(如每个 Extent 独立锁),减少竞争。
3. 从系统内存(mmap/brk)分配
-
当我们请求大小 >4MB(大对象)或 Arena 的 Extent 不足(需扩展堆空间)时。直接调用 mmap,记录元信息到全局基数树(Radix Tree)。通过
mmap申请独立内存段(默认 ≥4MB)。这时是大对象,不进入线程缓存或 Arena,直接由全局结构跟踪。释放时调用munmap立即归还系统,避免碎片。 -
可以避免污染线程缓存和 Arena。减少大内存的合并开销。
6.3 内存回收机制
1. 线程本地缓存(Thread Cache)的回收
-
用户释放的小对象(≤4KB)首先存入线程本地缓存(Thread Cache)的对应
size class槽位。 -
批量回收每个
size class的 Thread Cache 槽位有最大保留数量(如默认 200 个)。当超出阈值时,jemalloc 将多余的槽位批量归还到全局的 Arena。
2. 全局分配区(Arena)的回收
-
每个 Arena 维护一组
extent(如 4MB 的大块内存),按size class分类。Extent 分割为slab后,jemalloc 跟踪每个 slab 中已分配和空闲的槽位(Slot)。 -
Slab 完全空闲时,即当某个 slab 的所有槽位均被释放时,其所属的 Extent 可能被标记为空闲。jemalloc 定期内存压力检测或根据系统内存压力,合并空闲 Extent 并归还操作系统。
3. Extent 的合并与归还
-
惰性合并(Lazy Coalescing):jemalloc 不会立即合并相邻的空闲 Extent,而是保留它们以便快速响应未来可能的相同大小请求。当连续的空闲 Extent 达到一定数量或系统内存不足时,主动合并以减少外部碎片。
-
操作系统归还:完全空闲的 Extent 可能通过
munmap归还操作系统。jemalloc 默认保留部分空闲 Extent(通过retain:true配置),避免频繁的mmap/munmap系统调用开销。
6.4 局限性
- 内存碎片积累(尤其多 Arena 场景)。
- 线程本地缓存囤积 导致内存利用率下降。
- 超大对象管理开销 和 配置复杂度高。
- 平台兼容性差异 和 调试困难。
参考资料:
内存优化总结:ptmalloc、tcmalloc和jemalloc_ptmalloc jemalloc tcmalloc-CSDN博客
ptmalloc VS tcmalloc VS jemalloc 原理及对比测试
ptmalloc代码浅析2(small bin/large bin结构图)_largebin-CSDN博客
本篇文章对内存分配器ptmalloc2、tcmalloc、jemalloc,结构设计、内存分配过程做了详解!欢迎留言讨论!